一种基于FPGA的分层异构类脑计算系统
文献发布时间:2023-06-19 09:54:18
技术领域
本发明涉及类脑计算系统,特别是涉及一种基于FPGA的类脑计算系统。
背景技术
大脑作为神经系统的中枢,是完成人类视觉、听觉、规划、决策等各种问题的关键生物组织,它是由数千亿的神经元组成的复杂非线性系统,正确地认识大脑的结构和功能是推动脑科学发展的关键,也是解决人类脑疾病问题的重要步骤。生理学实验是研究大脑机理的重要方式,但是生物实验能够得到的实验数据是有限的,其实验结果的正确性或偶然性是未知的,另一方面,生理学实验难以揭示神经系统内部的活动过程。因此,高性能的类脑计算技术和大脑仿真技术成为研究脑科学的重要手段,计算神经科学的发展对智能科学领域、认知科学领域、信息处理和人工智能等技术产生了重要的影响。
然而完成人脑的基本功能需要数百万的神经元共同活动,要想更加精准地模拟脑功能需要更大规模的脑仿真系统,现有的大规模脑仿真研究包括以下三个关键问题:第一、传统计算机的冯·诺依曼架构是依靠顺序执行代码完成调用数据和数值处理工作,这与人脑的并行计算方式有着本质区别,无法实现真正意义上的类脑计算。首先,冯·诺依曼架构在计算过程中是将高纬度的信息转换成低纬度的时间信息进行处理,不能解决实时计算的复杂智能问题;其次,冯·诺依曼架构的信息处理过程是通过总线在存储器和处理器间不断调用数据完成的,存储器和中央处理器的物理分离造成了大量的能量损失,使得往复传输速率与信息处理速率不匹配,导致严重的存储墙效应,进一步限制了类脑功能的开发和实现;第二、现有的类脑计算系统由于其在自身计算能力方面的限制,神经元复杂度和神经网络规模之前存在着矛盾问题,大规模的神经元网络难以兼容复杂的非线性神经元模型,并行计算能力的不足导致神经元网络规模难以增大;第三、目前的类脑计算研究忽略了神经元的动力学行为与人脑认知功能之间的联系,将神经元的动力学特征和脑功能隔离开来,造成了理解人脑信息处理机制的从细胞层次到认知层次的研究鸿沟。
人脑智能与其超大规模、复杂互联的神经元网络息息相关,因此,如何克服大规模类脑仿真的上述三个关键问题,提出新型的大规模神经元网络计算架构和计算模式是实现类脑计算的关键。通过研究大规模神经网络的放电机制和动力学现象,能够更进一步理解人脑的复杂功能,实时的大规模类脑计系统也是开发类脑智能和实现类脑应用的重要手段。
目前欧美等国均开展了该领域的深入研究。英国曼彻斯特大学基于ARM芯片构建了大规模脑仿真系统SpiNNaker,该系统借鉴了脉冲神经元的放电模式,用较少的物理连接实现了尖峰脉冲的快速传递。IBM公司开发的新型类脑计算系统采用16颗TrueNorth芯片,TrueNorth芯片借鉴了神经元脉冲放电原理和信息传递机制,实现了计算和存储相融合的非冯·诺依曼计算架构,可以执行低功耗的多目标学习任务和实时视频处理任务。德国海德堡大学提出了BrainScaleS脑仿真系统,主要用于类脑机制研究与高性能计算的实现。国内在大规模类脑仿真的研究上仍处在萌芽期,人工神经网络的计算模式仍然基于人工神经元的频率编码,网络节点不能实现对神经元复杂动力学行为的模拟,因而无法依据神经元脉冲编码的放电模式进行更深层次的类脑智能。
现场可编程门阵列(FPGA)是一种半导体设备,他含有大量的可编辑元件,是当前应用最为广泛的可编程处理器件之一,具有片上资源丰富、成本低、运算速度快、结构灵活、可重复配置等优点,近些年FPGA在神经科学领域越来越多的应用为神经元仿真提供了新的思路。与通过串行方式运算的通用计算机不同,FPGA能够通过硬件描述来实现并行的多进程运算,能够大大提高计算效率。因此,在神经元模型的仿真方面FPGA有着独特的优势。
人脑众多功能的完成需要成万上亿的神经元相互配合完成,如何实现大规模的神经元网络是进行类脑研究的关键,目前大规模神经网络仿真系统主要存在无法实现实时计算,规模不足和神经元网络放电模式简单的问题。
发明内容
针对上述其技术不足之处,本发明的目的是提供一种基于FPGA的分层异构类脑计算系统。实现成万上亿的神经元相互配合完成的人脑众多功能,通过融合多层次类脑计算方法,采用多片具备并行计算功能的FPGA构建了基于神经计算架构的大规模神经元网络仿真系统BiCoSS,实现了四百万数量级神经元的大规模脑仿真与实时计算,从而更好地理解人脑工作机制与疾病机制,进一步实现更深层次的类脑计算和类脑智能。
为了解决上述技术问题,本发明采用的技术方案是:一种基于FPGA的分层异构类脑计算系统,包括若干个FPGA子系统,每个FPGA子系统为一个节点,所述FPGA子系统在节点处排列和连接形成树形拓扑结构的片上网络,且每个FPGA子系统通过PCB底板上的引脚直接连接并将引脚制成外部接口实现扩展功能,所述树形拓扑结构为每个节点的两个子节点互联的改进树形结构;每个FPGA子系统包括四个神经元网络单元和一个路由单元,所述神经元网络单元为基本计算单元,每个计算单元包含若干神经元基本计算核。
所述改进树形结构的非顶层节点通过路由单元与一个上一级节点和两个下一级节点相连;顶层节点与下一级2个节点通过路由单元相连;1个底层节点只与上一级1个节点通过路由单元相连。
所述FPGA子系统设有7个,形成改进树形结构的每个节点均采用四个计算单元通过混合互联。
所述改进树形结构的非顶层节点中每个计算单元与其余15个计算单元通过1个路由单元进行直接通信,底层节点中每个计算单元与7个节点计算单元进行直接通信,顶层节点中每个计算单元与11个节点计算单元进行直接通信。
所述计算单元包括神经元计算模块、突触计算模块、配置单元模块、路由模块,所述神经元计算模块一方面输出突触变量到路由模块,从而将突触变量信息传输到其他神经元网络单元中,另一方面输出膜电位变量到突触计算模块中进行突触计算;配置单元模块用于配置路由模块的参数,路由模块从片上网络临近节点接收外部AER脉冲数据包,并且根据配置单元中的可编程路由表决定数据传输方向。
所述路由单元采用神经放电信息路由方式,神经放电事件被封装成神经放电包以后,路由逻辑模块基于路由算法对神经放电包进行处理,实现FPGA芯片之间的数据传输和通讯功能。
所述计算单元上包含一片FPGA、两片SDRAM和一个用于程序存储的串行配置芯片EPCS128,所述SDRAM用于存储网络计算的中间变量与网络参数,所述串行配置芯片EPCS128用于在电源关闭时存储程序。
七个子系统通过PCB底板实现引脚之间的直接连接。每个子系统上还留有额外的引脚并制成外部接口,以便实现数模转换、视觉设备、机器人控制、系统扩展等功能。
路由单元采用神经放电信息路由方式,神经放电事件被封装成神经放电包以后,路由逻辑模块基于路由算法对神经放电包进行处理,实现FPGA芯片之间的数据传输和通讯功能。
本发明具有以下几点有益效果:
1、本发明实现的分层异构类脑计算系统采用并行计算方式,可以实现实时的类脑计算。
2、本发明可模拟的神经元网络规模大,能够实现百万级的神经元网络模拟,能够实现脑核团的模拟,更进一步揭示大脑的工作机制。
3、本发明实现的采用数字电路可实现包括基于电导的HH神经元模型在内的任意模型,以及基于生物启发的STDP机制的学习算法,不受到神经元模型复杂度的限制。
4、本发明的子系统连接结构为改进的树形结构,可以根据需要实现进一步的扩展连接,可扩展性强。同时每个节点均采用四个计算单元通过混合互联结构实现,避免了单纯使用树形拓扑结构造成的频繁的计算单元跨层级通信,减少了不必要的传播延迟和资源消耗。
5、本发明的子系统留有外部接口,通过GPIO通信端口可实现外接摄像头、机械臂、数模转换模块、模数转换模块等输入输出设备与外界进行数据交互,可完成类脑感知与决策等实时应用开发。
6、本发明采用的基于地址表达的路由方式从本质上避免了信息传递的冗余,减少了传递的神经元放电数据量,减少了系统开销与功耗,提升了系统计算效率。
附图说明
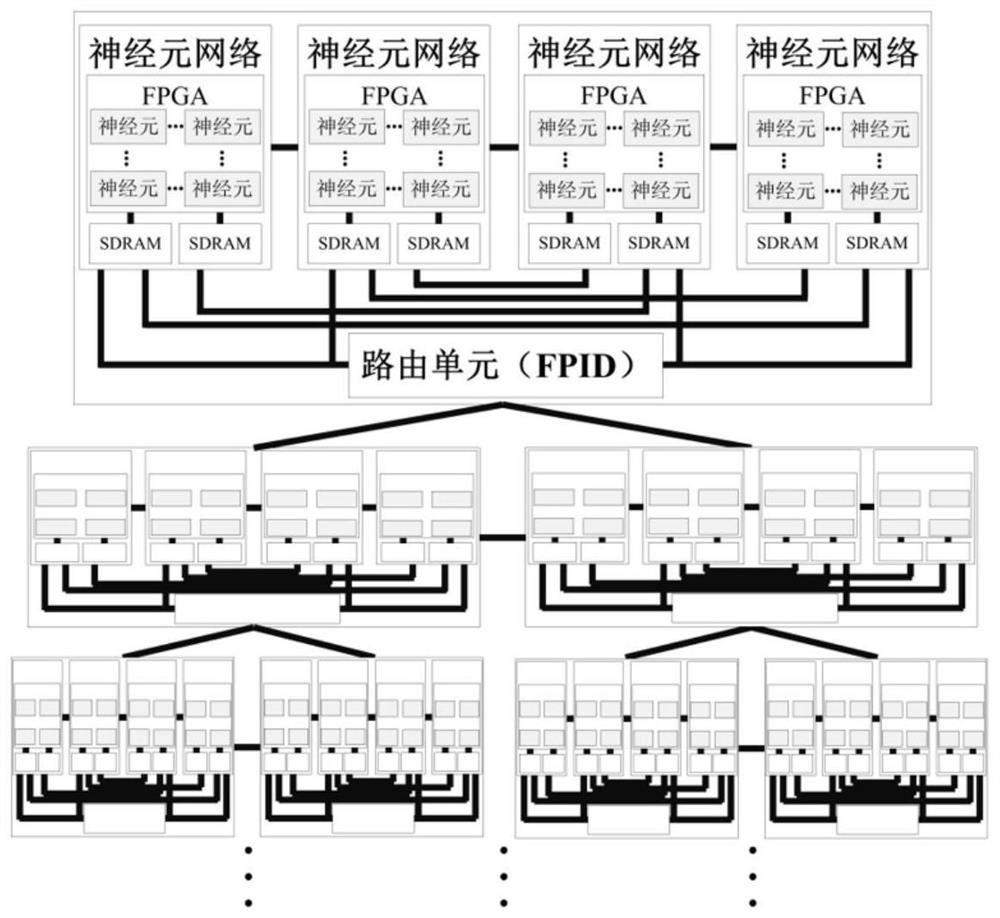
图1是系统架构示意图;
图2是神经元网络计算单元架构;
图3是神经元网络计算过程示意图;
图4是突触计算单元架构示意图;
图5是系统模拟的STN和GPi核团的放电栅图;
图6是小脑启发的类脑运动控制网络结构;
图7是基于类脑计算的机械臂控制轨迹图;
图8是神经元网络放电可靠性变化示意图。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细说明:
如图1所示,图1为基于FPGA的分层异构类脑计算系统架构图,本系统分为7个子系统,采用片上网络结构的改进树形结构连接,每个子系统包含四个神经元网络单元和一个路由单元,各个单元均由FPGA实现。神经元网络为基本计算单元,改进树形结构的每个节点均采用四个计算单元通过混合互联结构实现,四个计算单元通过路由单元与改进树形结构中其他节点相连,非顶层节点中每个计算单元可以与其余15个计算单元通过1个路由单元进行直接通信,顶层与底层节点中每个计算单元可以与其他7个计算单元进行直接通信。
所述神经元网络计算单元如图2所示,图2为神经元网络计算单元架构,其中包括神经元计算模块、突触计算模块、配置单元模块、路由模块,神经元计算模块输出突触变量到路由模块,从而将突触变量信息传输到其他神经元网络单元中;输出膜电位变量到突触计算模块中进行突触计算,配置单元模块用于配置路由模块的参数,路由模块从片上网络临近节点接收外部AER脉冲数据包,并且根据配置单元中的可编程路由表决定数据传输方向。
神经元网络计算的过程如图3所示,图3为神经元网络计算过程示意图,对于神经元模型的变量"V"、"Xi"(i=1,2,...,n),构建相应的神经元模型流水线计算模块以及随机存取存储器(Random access memory,RAM)存储阵列,流水线计算模块实时更新神经元状态,RAM阵列对神经元计算中间变量进行存储,从而对神经元网络进行时分复用操作,在本系统中对神经元计算模块进行9000次时分复用处理。STDP计算单元将突触权重实时更新输出给突触计算单元中,突触计算单元接收AER脉冲数据包与膜电位变量V进行计算,神经元计算单元最终计算输出膜电位变量与突触变量。
本发明采用英特尔公司的Cyclone IV系列FPGA芯片EP4CE115F29C7N,每个芯片与两个SDRAM以及一个串行配置设备EPCS128相连,被扩展为六层PCB的核心系统。
人脑的信息处理过程中,神经元网络模型描述了不同神经元和突触如何相互连接以及相互作用。神经元网络通过每个神经元的时间序列进行信息的传递与处理工作,从而构成人脑的认知行为。在本发明中,所述神经元计算模块采用以LIF神经元模型为例的小脑神经元模型,为了兼顾硬件资源消耗与精度,选用欧拉法对神经元模型进行离散化,所得到的差分方程如下:
式中,ΔT是离散化采样时间,V(n)是当前时刻的变量迭代值,C为神经元电导。参数gleak、gex:AMPA、gex:NMDA、ginh、gahp分别为漏电导、兴奋性AMPA突触电导、兴奋性NMDA突触电导、抑制性突触电导、后超极化突触电导,Eleak、Eex、Einh、Eahp分别为漏电势、兴奋性电势、抑制性电势以及后超极化电势,I为神经元外部施加电流。
所述突触计算单元采用具有高度生物合理性的突触可塑性(Spike-timing-dependent Plasticity,STDP)的学习规则,当突触前神经元的放电活动先于突触后神经元时,突触耦合强度增加;反之,当突触前神经元后于突触后神经元放电时,突触耦合强度减弱。突触计算单元如图4所示,图4为突触计算单元的详细计算架构示意图,其中包括n个平行突触计算子模块,rea表示缓存器的读地址。AER脉冲数据包输入到复用器中,通过常规计数器进行顺序选择。解码器解码出AER脉冲数据包的突触变量信息si和时间标记信息,时间标记信息用作缓存器的写地址wri。在每个平行突触计算模块中,网络连接矩阵被存储在只读存储器(Read-only memory,ROM)中,并行加法器将n个平行突触计算模块的输出相加,并将更新后的结果输出到神经元计算模块中进行计算。
所述路由单元包含六个输入端口与其他路由节点或神经计算单元相连接,每个输入端口包含一个配有六个FIFO的虚通道。这些虚通道由虚通道仲裁器控制,使用一个计数器去顺序选择每个虚通道内的FIFO。神经元在产生动作电位后,输出放电信号,放电信号触发地址编码电路编码事件发生地址,通过神经放电的峰-峰间期或放电频率来定义神经信号属性,由放电事件主动触发,未产生放电事件的神经元无输出。
实施例:
大规模神经元网络的计算有助于将神经网络动力学特性与人脑高层认知行为联系起来,接近人脑的计算规模具有更强的生理可信性。本系统可以实时计算大规模人脑具有认知功能的神经元网络,一方面增加的网络规模可以更加接近人脑认知行为的计算规模,从而准确地揭示人脑的大规模认知机制,另一方面本系统的实时计算性能可以用于与真实生物体的接口或人工智能设备中。
大脑决策是一个极为复杂的神经活动过程,皮层-基底核-丘脑回路是人脑认知决策的重要网络,不同的多巴胺水平会影响人脑在决策的时候采用不同的策略,包括保守、冒险与随机。通过本系统建立了负责人脑决策的大规模基底核神经元网络。该网络由纹状体(Striatum,Str)、GPe、苍白球内侧部(Globus Pallidus internal,GPi)、STN四种核团组成,其中Str被分为D1和D2两部分,后三种核团各自为一部分,每部分均由呈网格状排列的一百万个神经元构成。除纹状体以泊松序列模拟放电信息外,其他核团的神经元均为带有离子通道电流的Izhikevich模型。在高多巴胺水平的条件下,对本系统构成大大规模神经元网络输入两个不同的刺激信号,两个刺激信号分别为频率4Hz和8Hz的泊松序列,并从一百万个STN和GPi神经元中各取两千个神经元绘制放电栅图,观测到STN和GPi核团的放电栅图如图5所示,可以看出,在高多巴胺水平下,基底核网络做出了相应的选择策略,更强的8Hz泊松序列刺激使得网络活动更快达到阈值,因此基底核网络选择了8Hz刺激作为最佳决策。
小脑在人脑的运动控制功能中起着重要的作用,包括维持躯体平衡、调节肌张力及协调运动等。通过本系统建立大规模的小脑神经元网络,可以用于人脑运动控制机制的探索。搭建了由四百万个神经元构成的小脑模型,其中包括一百万个颗粒细胞(Granulecell,GR),一百万个高尔基细胞(Golgi cell,GO),五十万个浦肯野细胞(Purkinje cell,PC),五十万个篮状细胞(Basket cell,BS),五十万个下橄榄核细胞(Inferior olive,IO)和五十万个前庭核细胞(Vestibular nucleus,VN)。GR和GO神经元均呈网格状排列。所有的神经元细胞均为带有离子通道的LIF模型。前庭动眼反射实验反映了当头部位置改变时,视网膜成像保持稳定的神经响应过程。在头部运动的过程中,前庭会产生刺激并引起眼球的反射运动,使得眼球不会随头部位置的改变而改变,从而保证视网膜稳定成像。通过本系统建立图6所示的小脑启发的类脑运动控制网络结构,绘制得到图7所示的基于类脑计算的机械臂控制轨迹图,显示了基于本系统的类脑计算可以实现小脑的运动控制认知功能。
本系统的另一个重要应用是人脑精神疾病机制的仿真与分析。为了探索运动障碍性疾病的发病机制,基于BiCoSS系统实现了大规模皮层-基底核-丘脑皮层神经元网络,在此基础上探索运动障碍性疾病的发病与皮层-基底核-丘脑皮层神经元网络耦合强度的关系。如图8所示,随着网络耦合强度的增加,神经元放电的可靠性在一定范围内保持不变,网络耦合强度的进一步增加导致网络放电可靠性迅速下降。因此,皮层-基底核-丘脑皮层神经元网络中突触耦合强度的增加是运动障碍性疾病致病的重要因素之一。
- 一种基于FPGA的分层异构类脑计算系统
- 一种基于FPGA的小型异构分布式计算系统