基于数据特征分池的分布式数据存储方法及装置
文献发布时间:2023-06-19 09:55:50
技术领域
本发明涉及一种数据存储方法及装置,属于数据存储领域,具体是涉及一种基于数据特征分池的分布式数据存储方法及装置。
背景技术
分布式存储是一种数据存储技术,简单来说,就是将数据分散存储到多个存储服务器上,并将这些分散的存储资源构成一个虚拟的存储设备,实际上数据分散地存储在服务器的各个角落。
传统的网络存储系统,采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点。分布式存储系统利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,有效提高了系统的可靠性、可用性和存取效率。
目前分布式存储系统已经在全球范围内得到广泛认可,相比与传统存储系统,其应用优势如下:
高性能:分布式存储可以高效地管理读缓存和写缓存,并且支持自动的分级存储,通过将热点区域内的数据映射到高速存储中,以提高系统响应速度。
多副本技术:分布式存储采用多副本备份机制,并使用镜像、条带、分布式校验等方式满足用户对于可靠性不同的需求。
容灾与备份:分布式存储支持多时间点快照备份,可同时提取多个时间点样本同时恢复,降低了故障定位的难度,结合周期增量备份机制,确保数据安全高可用。
弹性扩展:得益于合理的分布式架构,还可预估容量并弹性扩展计算、存储容量和性能,扩展后旧数据会自动迁移至新节点,实现负载均衡,避免单点过热。
Ceph作为现有技术中的一种统一分布式存储系统,其有别于其他分布式系统就在于它采用Crush(Controlled Replication Under ScalableHashing)算法使得数据的存储位置都是计算出来的而不是去查询专门的元数据服务器得来的。
Crush在一致性哈希算法的基础上很好的考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。同时,Crush算法支持副本和EC两种数据冗余方式。
Crush算法是Ceph最初的核心之一,是Ceph最引以为豪的地方。Crush在一致性哈希基础上很好的考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。同时,Crush算法支持副本和EC两种数据冗余方式,并且提供了以主机、服务器机架及数据中心的故障域隔离方式,可根据存储服务器的物理结构合理规划故障域,充分考虑实际生产过程中硬件的迭代式部署和缩容扩容,尽可能使Crush算法具有相当好的可扩展性,在数千OSD的情况下仍然能保证良好的负载均衡和可靠可用性。但这更多是理论层面的,目前还没有人给出在数PB规模的生产环境中的测试结果。总的来看,Crush算法仍然是目前经过实践检验的最好的数据分布算法之一。
Ceph摒弃了传统的集中式存储元数据寻址的方式,基于管理员自行定义的数据副本数量,通过Crush算法指定副本的物理存储位置以分隔故障域,数据分布均衡,并行度高,支持数据强一致性。Ceph可以忍受多种故障场景,考虑了容灾域的隔离,能够实现各类负载的副本放置规则,并在故障发生后自动尝试并行修复。
Ceph按设备的性能进行分池,将高速设备和低速设备分池,建立以高速设备组成的高性能池和以低速设备组成的低性能池,对性能要求高的业务可以将数据放在高性能池中,对性能要求低的业务可以将数据放到低性能池中。因为Ceph是分布式存储系统,其数据冗余机制和数据分布算法Crush都是按Pool进行设定的,如果一个Pool是由高速设备和低速设备混合组成的,那么Ceph的数据分布算法Crush限定要求了数据分布或者故障的最低层级必须是磁盘级别,那么不论采用何种数据冗余技术,都需要保证数据的高可靠性,即数据分布至少会分布到2个及以上的磁盘,这就有可能导致木桶效应,即一份数据必须等所有的冗余数据都写入完成才能返回,性能受限于慢速设备。因此,按设备性能进行分池可以很好的解决性能木桶效应。但是:高速设备的价格要远远高过低速设备,因此高性能池的容量必然受限。另一方面,低速设备相对高速设备来说有性能差距,但是如果不做优化,是无法发挥低速设备在面对不同类型数据的极限性能。
现有技术中还存在按逻辑分池,这种分池方案主要根据业务的逻辑来分池,带来的好处就是分池逻辑比较简单,不需要其他因素对存储池性能的影响。逻辑分池方案虽然比较简单,但是这种方案没有能力适配业务对于性能的要求,无法感知业务的数据特征,意味者这种方案无法对不同业务做出最合理的优化,比如有些业务对延迟有一定的要求,但是并非要求非常高,按这种分池方案的话,就必须将该业务放入高性能池,加大整体存储的建设成本。
发明内容
本发明主要是解决现有技术所存在的上述的技术问题,提供了一种基于数据特征分池的分布式数据存储算法及系统。
本发明的上述技术问题主要是通过下述技术方案得以解决的:
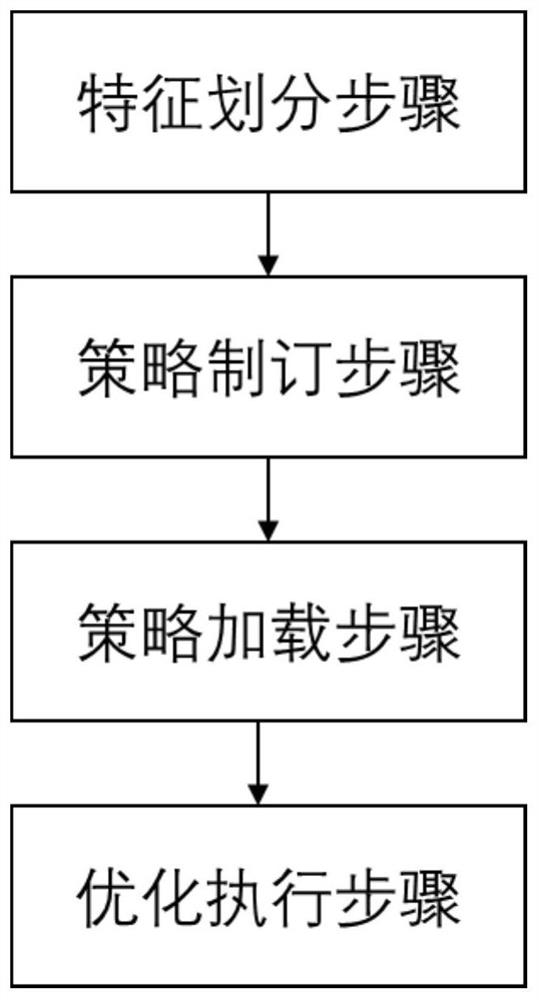
一种基于数据特征分池的分布式数据存储方法,包括:
特征划分步骤,自动按照业务数据的特征预先规划故障域算法,将数据划分为不同的特征类型;
策略制订步骤,针对不同业务的特征类型制订分布式存储数据优化策略;
策略加载步骤,对象存储设备根据分池的数据特征类型加载与之对应的数据存储优化策略;
优化执行步骤,对象存储设备按照数据存储优化策略定义的相关动作执行优化操作。
优选的,上述的一种基于数据特征分池的分布式数据存储方法,所述特征划分步骤中,
自动按照业务io类型将数据分为顺序特征和随机特征。
优选的,上述的一种基于数据特征分池的分布式数据存储方法,所述策略制订步骤中在OSD层面结合硬件的电气特性、服务器的硬件性能以及操作系统制定出针对顺序特征和随机特征的两套数据特征优化策略。
优选的,上述的一种基于数据特征分池的分布式数据存储方法,所述随机特征优化策略算法包括以下操作中的一种或多种:自动根据物理CPU个数调整IO并发处理线程;在客户端层、软件抽象层、内核驱动层聚合连续的小IO;自动计算缓存buffer;启动数据缓存模块;将数据写入高速设备;缩短IO路径;并减少系统中断。
优选的,上述的一种基于数据特征分池的分布式数据存储方法,还包括:数据监视步骤,在分布式存储监视器守护进程中扩展出针对数据特征分池的持久化记录,自动根据具体的顺序和随机特征扩展数据存放组的属性,将分池特性通过创建数据存放组下发给对应的存储设备。
优选的,上述的一种基于数据特征分池的分布式数据存储方法,所述特征划分步骤中,可在命令行或者客户端创建Pool的时候,指定数据特征类型参数。
一种基于数据特征分池的分布式数据存储系统,包括:
特征划分模块,按照业务数据的特征预先规划故障域算法,将数据划分为不同的特征类型;
策略制订模块,针对不同的特征类型制订分布式存储数据优化策略;
策略加载模块,对象存储设备根据分池的数据特征类型加载与之对应的数据存储优化策略;
优化执行模块,存储设备按照数据存储优化策略定义的相关动作自动执行优化操作。
优选的,上述的一种基于数据特征分池的分布式数据存储系统,还包括:
所述特征划分模块中,按照业务类型将数据分为顺序特征和随机特征,所述顺序特征包括流媒体数据,所述随机特征包括数据库类、系统盘数据。
优选的,上述的一种基于数据特征分池的分布式数据存储系统,所述策略制订模块中在OSD层面结合硬件的电器特性、服务器的硬件性能以及操作系统制定出针对顺序特征和随机特征的两套数据特征优化策略。
因此,本发明具有如下优点:顺序特征池所在的节点磁盘的顺写性能基本在满带宽,而随机特征池所在的磁盘也基本达到极限的随机性能,显著的提高了分布式存储的数据操作效率。
附图说明
附图1是本发明的一种流程图;
附图2是本发明的一种系统图;
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
实施例:
如图1所示,为本实施例的基于数据特征分池的分布式数据存储方法,其包括以下步骤:
特征划分步骤,自动按照业务数据的特征预先规划故障域算法,将数据划分为不同的特征类型;本步骤中,可在命令行或者客户端创建Pool的时候,指定数据特征类型参数。
策略制订步骤,针对不同的特征类型制订分布式存储数据优化策略;本实施例在OSD层面结合硬件的电气特性、服务器的硬件性能以及操作系统制定出针对顺序特征和随机特征的两套数据特征优化策略。
策略加载步骤,对象存储设备根据分池的数据特征类型加载与之对应的数据存储优化策略;
优化执行步骤,对象存储设备按照数据存储优化策略定义的相关动作执行优化操作。
作为一种优选方式,本实施例还包括数据监视步骤,在分布式存储监视守护进程中扩展出针对数据特征分池的持久化记录,根据具体的顺序和随机特征扩展数据存放组的属性,将分池特性通过数据存放组创建下发给对应的对象存储设备。
本实施例中,按照业务类型将数据分为顺序特征和随机特征,所述顺序特征包括流媒体数据,所述随机特征包括数据库类、系统盘数据。
所述顺序特征优化策略包括以下操作中的一种或多种:算法自动调整内存缓存,调整内存分配管理单元,调整各个buffer大小。
所述随机特征优化策略包括以下操作中的一种或多种:算法根据业务下发的io大小,将随机的小io分发至高速磁盘上,减少延迟,提升iops。将5s内连续的小io进行合并,下发至低速磁盘,减少低速磁盘的寻道时间,尽可能加大低速磁盘的写带宽。
采用上述方法后,本实施例在OSD层面结合硬件的电气特性、服务器的硬件性能以及操作系统等因素制定出针对顺序特征和随机特征的两套数据特征优化策略。
不同的优化策略将各自的数据特征的性能发挥到极限;
本实施例的Monitor层需要扩展出针对数据特征分池的持久化记录,防止Monitor异常导致数据特征分池失效,Monitor需要根据具体的顺序和随机特征扩展PG的属性,将分池特性通过创建数据分布组下发给对应的OSD;
本实施例中,用户需要根据业务数据的特征预先规划Crushmap,比如视频、音频等静态数据可以归结为顺序特征,数据库类、系统盘等业务可以归结随机特征;通过命令行或者客户端创建Pool的时候,需要指定数据特征类型参数;
本实施例中,Monitor收到Pool创建指令的时候,先进行Pool元数据的创建,之后进入创建PG层的相关操作,最后通知所属的OSD进行PG实例的创建;
本实施例中,OSD收到创建PG指令的时候,会根据PG携带的数据特征类型加载数据特征优化策略,并按照策略定义的相关动作执行相关优化动作。
如图2所示,为本实施例提供的一种基于数据特征分池的分布式数据存储系统,包括:
特征划分模块,按照业务数据的特征预先规划故障域算法,将数据划分为不同的特征类型;
策略制订模块,针对不同的特征类型制订分布式存储数据优化策略;
策略加载模块,对象存储设备根据分池的数据特征类型加载与之对应的数据存储优化策略;
优化执行模块,对象存储设备按照数据存储优化策略定义的相关动作执行优化操作。
本实施例中,所述特征划分模块中,按照业务类型将数据分为顺序特征和随机特征,所述顺序特征包括流媒体数据,所述随机特征包括数据库类、系统盘数据。
本实施例中,所述策略制订算法模块中在OSD层面结合硬件的电气特性、服务器的硬件性能以及操作系统制定出针对顺序特征和随机特征的两套数据特征优化策略。
其中,顺序特征优化策略是:算法自动识别5秒内连续的小io,自动进行合并,将连续io写入低速设置,提升io写入带宽;
其中,随机特征优化策略是:算法自动识别随机小io并写入高速磁盘,明显降低写入延迟,并对写入的io进行缓存,当出现随机读时,命中的数据直接从随机特征池读写,减少读取时间,降低延迟。
采用上述方案后,本实施例的技术方案带来的直接的效果就是顺序特征池所在的节点,磁盘的顺写性能基本在满带宽,而随写特征池所在的磁盘也基本达到极限的随机性能。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 基于数据特征分池的分布式数据存储方法及装置
- 基于数据特征分池的分布式数据存储方法及装置