基于改进支持向量机核函数的植物叶片分类方法及系统
文献发布时间:2023-06-19 09:57:26
技术领域
本发明属于叶片分类技术领域,具体涉及一种基于改进支持向量机核函数的植物叶片分类方法及系统。
背景技术
叶片分类是植物自动检索中的一项关键技术,它根据叶片的形状、纹理、颜色等特征进行植物生物物种的自动标注。与颜色和纹理相比,植物叶片的形状更具有代表性,且容易转化为数学模型进行计算。
近年来,在基于植物叶片图像的植物分类等方面的研究不断取得进展,包括叶片图像的特征选取、算法性能和分类器设计等。很多学者对叶片分类课题进行了研究,例如,付波等人为解决由于植物叶片特征的相似性以及叶片旋转导致植物识别率较低的问题,提出一种基于降维局部二值模式(LBP)与叶片形状特征相结合的植物叶片识别方法。马娜等人首先对叶片图像预处理,提取6个特征值,然后再使用基于布谷鸟算法改进的支持向量机算法建立分类模型对植物叶片分类,从而识别植物物种。董红霞等人提出了一种基于形状与纹理特征的分类算法。在进行了去噪等预处理后,通过阈值分割和数学形态学方法获取叶片区域;在分割得到的二值区域图像上提取了形状特征,在灰度图像上提取了纹理特征;在所得特征的基础上,利用BP网络对叶片进行分类。
在叶片分类算法中,一般情况下将叶片图像进行预处理,然后对图形进行边缘检测,获得二值化图像并转化为一条n维的时间序列数据,最后根据时间序列数据建立相应的分类模型。支持向量机(SVM)是Vapnik等人提出了一种建立在统计学习理论的基础上的数据挖掘方法。在众多的机器学习算法中,支持向量机作为一种分类效果和稳定性较好的机器学习算法得到了广泛应用。许多学者将SVM算法运用时间序列数据的分类工作中,张坤华等人针对多变量时间序列定义了每个属性的局部密度和判别距离,根据决策图的分布来筛选属性,最终通过SVM对数据进行分类。张振国等人以子序列为单位,构建时序数据间的相似性向量,快速筛选出具有高分类能力的Shapelets集合,并使用SVM算法进行分类。传统的SVM算法一般应用于时间序列数据分类的最后阶段,即对降维或者转化操作后的时间序列数据进行分类。
发明内容
本发明的目的在于提供一种基于改进支持向量机核函数的植物叶片分类方法及系统,该方法及系统有利于快速、准确地对植物叶片进行分类,进而对植物物种进行识别。
为实现上述目的,本发明采用的技术方案是:一种基于改进支持向量机核函数的植物叶片分类方法,包括以下步骤:
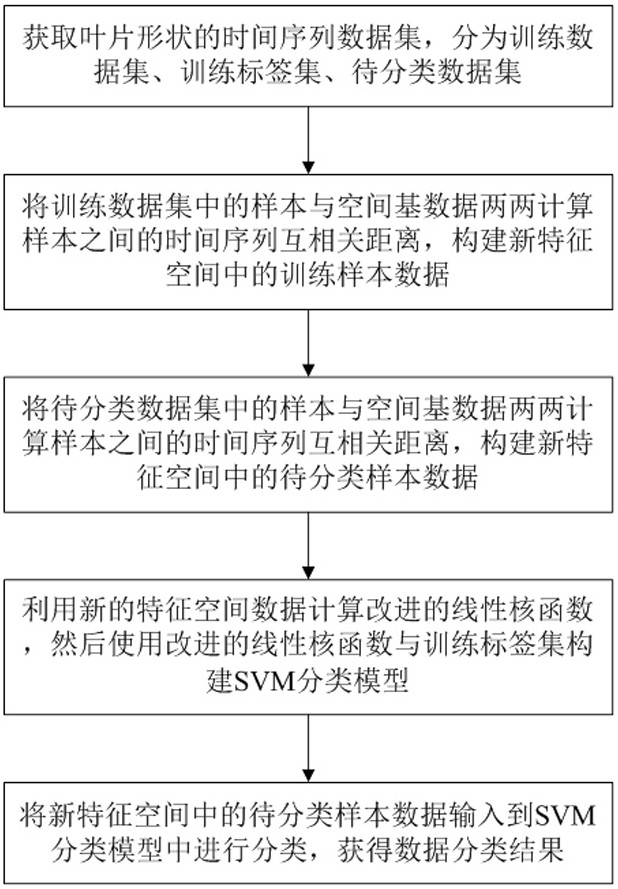
步骤1:对多个植物叶片图片进行处理,获取叶片形状的时间序列数据集,然后将获得的时间序列数据集分为训练数据集D
步骤2:将训练数据集D
步骤3:将待分类数据集D
步骤4:利用新的特征空间数据Dist(D
步骤5:将n×m的新特征空间中的待分类样本数据输入到构建的SVM分类模型中进行分类,获得数据分类结果。
进一步地,所述步骤1中,获取叶片形状的时间序列数据集的具体方法为:
对植物叶片图片进行图像预处理,即对图像进行灰度化、去噪、二值化和边缘提取,然后通过求取叶片形状的中心位置,获得叶片形状边缘到达中心位置的距离,按照一定的时间间隔Δt采集叶片形状边缘到中心点之间的距离数据,最终获得一条维度为v的时间序列数据,所述时间序列数据是一个有序的信息集合,表示为X={x
对多个植物叶片图片进行处理,相应得到多条时间序列数据,进而得到叶片形状的时间序列数据集。
进一步地,所述步骤2中,计算样本之间的时间序列互相关距离的具体方法为:
让一个时间序列保持静止,另一个序列在静止序列上滑动,通过平移找到互相关的最大值,即为两个时间序列的相似性;对于时间序列数据x=(x
其中,w∈{-m,-m+1,…,0,…,m-1,m},w≥0时,表示x序列向右移动w个位置,w<0时,表示x序列向左移动w个位置,移动后空余的位置由0替代;
找到一个最优的位移w,使得C(x,y,w)的值最大,也就找到了x相对于y最好的位移;
时间序列互相关距离,即时间序列x与序列y的互相关距离如公式(2)所示:
两个时间序列之间的互相关数值范围限定到[0,2]之间,数值越大,越不相似,数值越小,越相似。
进一步地,利用公式(2)计算训练数据集D
进一步地,将线性核函数与新的特征空间数据结合,计算改进的线性核函数K(X,X)如下:
K(X,X)=Dist(D
本发明还提供了一种基于改进支持向量机核函数的植物叶片分类系统,包括存储器、处理器以及存储于存储器上并能够在处理器上运行的计算机程序,当处理器运行该计算机程序时,实现如权利要求1-5任一项所述的方法步骤。
相较于现有技术,本发明具有以下有益效果:提供了一种基于改进支持向量机核函数的植物叶片分类方法及系统,首先将植物叶片图片进行处理并获取叶片形状的时间序列数据,然后计算叶片形状的时间序列数据样本与空间基数据的时间序列互相关距离,将样本数据映射到新的特征空间中,并根据新特征空间的训练样本数据改进线性核函数,然后根据改进的线性核函数计算SVM分类模型,最后通过分类模型对新特征空间的待分类数据进行分类,获得叶片形状分类结果,从而实现了快速、准确地对植物叶片进行分类,进而确定叶片所属的植物种类。
附图说明
图1是本发明的方法实现流程图。
图2是本发明方法与4种核函数下的SVM算法分类准确率的对比图。
图3是本发明方法与采用不同方法改进支持向量机核函数的算法的对比图。
图4是本发明方法与1-NN算法的对比图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步的详细说明。
如图1所示,本发明提供了一种基于改进支持向量机核函数的植物叶片分类方法,包括以下步骤:
步骤1:对多个植物叶片图片进行处理,获取叶片形状的时间序列数据集,然后将获得的时间序列数据集分为训练数据集D
步骤2:将训练数据集D
步骤3:将待分类数据集D
步骤4:利用新的特征空间数据Dist(D
步骤5:将n×m的新特征空间中的待分类样本数据输入到构建的SVM分类模型中进行分类,获得数据分类结果。
下面对本发明涉及的相关技术内容作进一步说明。
1、植物叶片形状数据
所述步骤1中,获取叶片形状的时间序列数据集的具体方法为:
对植物叶片图片进行图像预处理,即对图像进行灰度化、去噪、二值化和边缘提取,然后通过求取叶片形状的中心位置,获得叶片形状边缘到达中心位置的距离,按照一定的时间间隔Δt采集叶片形状边缘到中心点之间的距离数据,最终获得一条维度为n的时间序列数据。
定义时间序列数据:时间序列数据是一个有序的信息集合,时间序列X={x
定义空间基数据:空间基数据是时间序列数据,主要应用于时间序列数据的特征空间转换。本实施例中,以训练数据集中数据为空间基数据,以对时间序列数据进行特征空间转换。
对多个植物叶片图片进行处理,相应得到多条时间序列数据,进而得到叶片形状的时间序列数据集。
2、时间序列互相关距离
所述步骤2中,计算样本之间的时间序列互相关距离的具体方法为:
在信号处理的流程中,常常用互相关函数来计算两个不同的波的相似性,本发明将其应用于时间序列数据之间的相似性度量。
让一个时间序列保持静止,另一个序列在静止序列上滑动,通过平移找到互相关的最大值,即为两个时间序列的相似性;对于时间序列数据x=(x
其中,w∈{-m,-m+1,…,0,…,m-1,m},w≥0时,表示x序列向右移动w个位置,w<0时,表示x序列向左移动w个位置,移动后空余的位置由0替代。
找到一个最优的位移w,使得C(x,y,w)的值最大,也就找到了x相对于y最好的位移。
为了衡量两个时间序列数据在形态上的一致性,计算时间序列互相关距离,即时间序列x与序列y的互相关距离如公式(2)所示:
两个时间序列之间的互相关数值范围限定到[0,2]之间,数值越大,越不相似,数值越小,越相似。
3、支持向量机(SVM)
支持向量机是基于统计学习理论(SLT)的新型机器学习方法
给定仅有两个类别的训练数据集Train={(x
引入Lagrange函数来解决以上优化问题,如公式(4):
其中λ≥0为拉格朗日乘子,通过对w和b求偏导,设置偏导为0,即可求解最优权值向量w
b
由此可以获得最优的决策函数如公式(7):
对于实际上难以线性分类的问题,可以将待分类数据射到某个高维的特征空间,并在该特征空间中构造最优分类面,从而转化成线性可分类问题。以高维空间的样本Φ(x)代替原样本数据x,则可以得到最优分类函数如公式(8)所示:
在高维特征空间构造最优超平面时,仅使用特征空间中的内积实现。可以通过一个核函数K(X,X
则在特高维征空间建立超平面时无需考虑变换Φ的形式,简化映射空间中的内积运算。SVM的常用核函数有:Linear(线性)核函数、Polynomial(多项式)核函数、RBF(径向基)核函数和Sigmoid型核函数。
4、改进的线性核函数
SVM引入核函数的目的是将高维特征空间中大量的内积计算转换成低维空间简单的运算实现模型构建。不同的核函数蕴藏的几何度量特征各异,选择不同的核函数导致SVM泛化能力存在差异。针对时间序列数据的分类,需要符合其特征的核函数对数据进行空间转换。
线性核函数作为SVM中的最简单的核函数,它并未对原始的数据元素进行空间转换。数据X=(x
由于线性核函数中的几何度量特征不能有效的衡量时间序列数据的关系。为此,引入时间序列互相关距离,将时间序列数据映射到新的特征空间中,消除原始特征空间中数据的时间序列特性。通过空间基数据T=(t
利用公式(2)计算训练数据集D
新的特征空间的数据不再具有原始时间序列特性,因此可使用线性核函数获得较好的SVM分类效果。将线性核函数与新的特征空间数据结合,计算改进的线性核函数K(X,X)如公式(12)所示:
K(X,X)=Dist(D
本发明还提供了一种基于改进支持向量机核函数的植物叶片分类系统,包括存储器、处理器以及存储于存储器上并能够在处理器上运行的计算机程序,当处理器运行该计算机程序时,实现上述方法步骤。
下面以具体的实验对本发明的性能进行比较验证。
实验采用编程语言为Python3.7,实验程序代码基于LibSVM软件包基础上完成的。实验采用25组UCR数据集验证算法的有效性,UCR数据集是目前时间序列分类研究中普遍使用的数据集。
从表1可以看出,实验数据类型多样。类别从2类到60类,数据维度也是大小不一,最小60维,最长2000维;训练数据与测试数据的样本数量的差异也较大,因此可以更全面的衡量本发明的性能。为了便于测试,实验数据集采用默认的训练数据和测试数据划分,以准确率作为分类结果评价指标。准确率定义如下:
准确率=正确分类的样本数/总样本数
表1 25组UCR数据集
1、本发明方法与传统SVM算法比较
实验中的对比算法采用基于Linear核函数、Polynomial核函数、RBF核函数、Sigmoid型核函数下的SVM算法,实验中它们的简写分别为SVM_L、SVM_P、SVM_R和SVM_S。以上4种核函数的参数设置均采用libsvm中的默认参数,基于这些核函数的SVM算法分别对训练数据进行构建分类模型,最后通过构建的分类模型分别对测试数据分类,计算不同核函数下的准确率。本发明方法(SVM_IK)对训练数据集构建分类模型,通过测试数据与训练数据的时间序列互相关距离构建的测试数据进行分类,计算最终的分类准确率。本发明方法与4种不同核函数下的传统SVM算法的实验对比如图2和表2所示。
表2与4种核函数下的SVM算法平均分类准确率对比
由图2可知,基于RBF核函数、Sigmoid型核函数的传统SVM算法对时间序列数据的分类效果较差,基于Linear核函数、Polynomial核函数的SVM算法则效果相当。本发明方法仅8组数据的分类效果略低于这四种算法,其他17组数据的分类效果持平或者高于4种核函数下的SVM算法。
从表2中可以发现,本发明方法的平均准确率均高于4种核函数下的SVM算法。由于传统的SVM算法采用的几何距离来衡量样本与超平面之间的距离,本发明方法考虑到时间序列的形状上的相似度。
2、本发明方法与采用不同方法改进支持向量机核函数的算法对比
本发明方法采用时间序列互相关距离与采用DTW距离和欧氏距离改进支持向量机核函数的分类效果,实验中采用简写为SVM_IK(R)、SVM_IK(ED)和SVM_IK(DTW),它们的分类结果图3和表3所示。
表3与采用不同方法改进支持向量机核函数的算法平均分类准确率对比
从图3中可以发现,采用时间序列互相关距离时,18组数据的分类效果均好于其他两种方法,7组数据的分类效果略低于或持平于其他两种方法。同时表3中也可以发现采用时间序列互相关距离时,对于25组数据的平均分类准确率优于其他两种方法。也说明了本发明方法采用的时间序列互相关距离在分类过程中起到了积极的效果。
3、本发明方法与1-NN算法对比
本实验对比本发明方法(SVM_IK)与1-NN算法的分类结果,采用欧式距离度量的1-NN(ED)和采用DTW距离的1-NN(DTW),对比结果如图4和表4所示。
表4与1-NN算法平均分类准确率对比
从图4中可以发现,与两种度量方式下的1-NN算法相比,本发明方法有9组数据的分类效果略低于这他们两者,有2组数据的分类效果与其中一者持平,有14组数据的分类效果都高于这两者。通过表4可以发现本发明方法的平均值均高于这两种度量下的1-NN算法。因此,本发明方法对时间序列数据分类能够有较好的分类准确率。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 基于改进支持向量机核函数的植物叶片分类方法及系统
- 一种混合傅里叶核函数支持向量机文本分类方法