一种用于矩阵乘法密集型算法的可重构矩阵乘法加速系统
文献发布时间:2023-06-19 09:58:59
技术领域
本发明属于矩阵乘法的硬件加速设计领域,更具体地,涉及一种用于矩阵乘法密集型算法的可重构矩阵乘法加速系统。
背景技术
在如今人工智能大潮下,各式各样的算法都会涉及到大量的矩阵乘法。且对于那些矩阵乘法密集型的算法而言,每个算法内都会涉及到一系列不同的矩阵乘法,且这些矩阵乘法所涉及到的矩阵尺寸往往也都是多种多样且存在一定特殊性的。而可重构硬件加速由于其优秀的计算性能,较高的计算能效和可持续发展的成本优势被广泛地应用于硬件加速设计中。所以本发明专注于可重构矩阵乘法硬件加速设计,并提出用于矩阵乘法密集型算法的可重构矩阵乘法硬件加速系统和方法。
在现有的可重构矩阵乘法硬件加速方法中,大多是针对矩阵的存储规则进行设计或者着重于对数据的控制和调度进行设计,并没有对矩阵乘法的运算部分进行设计和优化,矩阵乘法的运算效率较低。另外,这两种方法也没有针对具体算法中矩阵尺寸的特殊性和多样性来做优化设计,并不能足够高效地加速那些具体算法中的多种多样的矩阵乘法,当服务于具体矩阵乘法密集型算法中时,矩阵乘法硬件加速的效率较低。
发明内容
针对现有技术的以上缺陷或改进需求,本发明提供了一种用于矩阵乘法密集型算法的可重构矩阵乘法加速系统,其目的在于解决现有技术应用于矩阵乘法密集型算法时运算效率较低的技术问题。
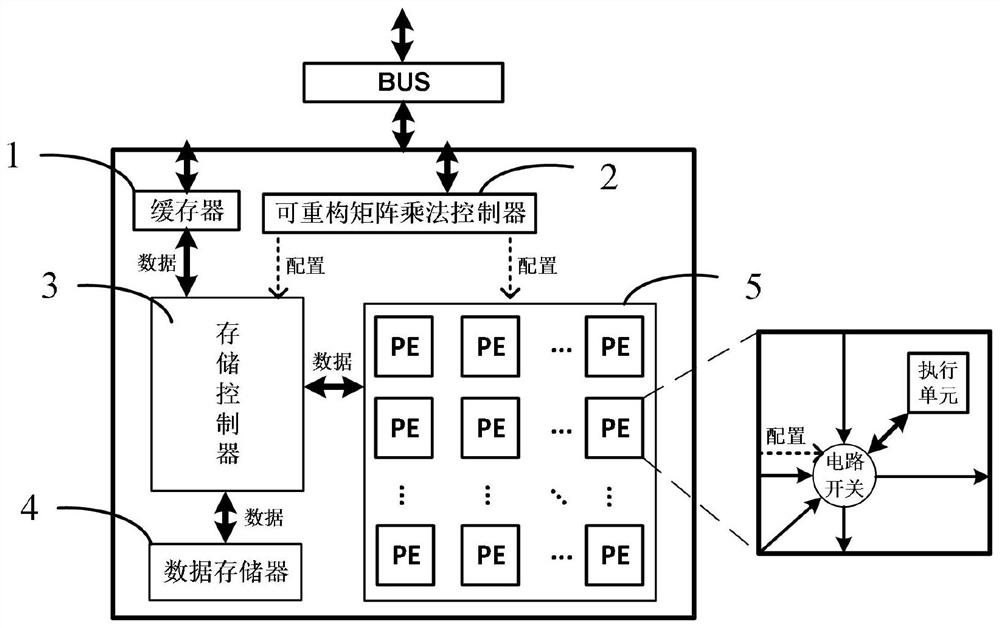
为实现上述目的,本发明提供了一种用于矩阵乘法密集型算法的可重构矩阵乘法加速系统,包括:缓存器、可重构矩阵乘法控制器、存储控制器、数据存储器和可重构运算阵列;其中,可重构运算阵列为多个PE单元互联组成的阵列,其规模由矩阵乘法密集型算法中所有进行矩阵乘法运算的矩阵尺寸、应用场景以及所要求的运算效率确定;
缓存器用于接收并缓存矩阵乘法密集型算法中的当前待计算矩阵乘法的矩阵;
可重构矩阵乘法控制器用于获取缓存器中当前待进行矩阵乘法运算的矩阵尺寸,基于矩阵尺寸判断矩阵乘法的类别以确定可重构运算阵列的当前工作模式,并根据当前工作模式对存储控制器和可重构运算阵列进行配置;
存储控制器用于控制缓存器将其缓存的当前待计算矩阵乘法的矩阵存储到数据存储器中;基于当前配置控制数据存储器将当前待计算矩阵乘法的矩阵按照预设分割模式进行分割后以脉动的方式输入到可重构运算阵列中;
可重构运算阵列用于基于存储控制器的输入控制,实现矩阵的乘法运算,并将计算结果存储至数据存储器中。
进一步优选地,可重构矩阵乘法控制器预先统计矩阵乘法密集型算法中的所有进行矩阵乘法运算A×B的矩阵A、B的尺寸以及矩阵乘法运算量,以矩阵中行数和列数之间的差异为特征,同时根据矩阵乘法中A矩阵的列数和B矩阵的行数必须相等这一规则,将矩阵乘法划分为六大类,具体为:矩阵A为横长条且矩阵B为竖长条,矩阵A为竖长条且矩阵B为横长条,矩阵A为竖长条且矩阵B为方正形,矩阵A为方正形且矩阵B为横长条,矩阵A和B均为方正形以及矩阵A为横长条且矩阵B为方正形;然后根据各类矩阵乘法的计算量占整个算法中所有矩阵乘法总计算量的比例分布,对矩阵乘法进行重组分类,且在重组过程中,避免将矩阵A为横长条和矩阵A为竖长条的矩阵乘法划分为一类,以及避免将矩阵B为横长条和矩阵B为竖长条的矩阵乘法划分为一类,以保证重组分类后的各类矩阵乘法的计算量相差在20%以内。
进一步优选地,上述预设分割模式为:对于当前待计算矩阵乘法运算A×B的矩阵A、B,若矩阵A为横长条形或方正形、且矩阵A的列数大于可重构运算阵列的行数L,则将矩阵A每隔L列进行一次分割;此时,若矩阵B的行数大于L,则将矩阵B每隔L行进行一次分割;与此同时,若矩阵B的列数大于可重构运算阵列的列数S,则将矩阵B每隔S列进行一次分割;
若矩阵A为竖长条、且矩阵A的列数大于S,则将矩阵A每隔S列进行一次分割;此时,若矩阵B的行数大于S,则将矩阵B每隔S行进行一次分割;与此同时,若矩阵B的列数大于L,则将矩阵B每隔L列进行一次分割。
进一步优选地,上述PE单元包括电路开关和执行单元;可重构运算阵列包含多种工作模式,矩阵乘法密集型算法中的每种矩阵乘法类型均对应一种工作模式,在不同的工作模式下,上述PE单元的电路开关被配置成不同的连接方式,以使得运算过程中能够实现尽量高的硬件利用率和运算效率。
进一步优选地,上述矩阵乘法密集型算法为EKF算法,此时,矩阵乘法密集型算法中的矩阵乘法被划分为两类;其中,矩阵A的尺寸为(r+Sn)×S且矩阵B的尺寸为S×(r+Sn)的矩阵乘法为第一类,其余的矩阵乘法为第二类;上述可重构运算阵列的规模为L行S列;其中,L为根据EKF算法的应用场景以及所要求的运算效率所预设的行数,S为EKF算法中特征点的位置向量维数,r为EKF算法中传感器的位置向量维数,n为EKF算法中特征点的数量。
进一步优选地,可重构运算阵列中,横向和纵向上相邻的PE单元相连,相邻的PE单元之间可以进行通信,通信的方向为横向和纵向。
进一步优选地,可重构运算阵列包括两种工作模式,分别记为主工作模式和辅工作模式;
主工作模式用于处理第一类矩阵乘法运算,此时,PE单元在纵向传递输入数据,在横向传递部分和;
辅工作模式用于处理第二类矩阵乘法运算,此时,PE单元在纵向传递部分和,在横向传递输入数据;
其中,部分和为将当前PE单元的计算结果与上一个PE单元的计算结果进行累加后的结果。
进一步优选地,当前工作模式为主工作模式时,存储控制器在控制进行矩阵乘法运算的矩阵A、B输入到可重构运算阵列的过程中,将矩阵B每隔L列进行一次分割,使矩阵A分别与各矩阵B的子矩阵进行乘法运算,得到矩阵A和B的乘法运算结果。
进一步优选地,在存储控制器的控制下按照数据脉动的方式将矩阵A按列分别输入到可重构运算阵列中;与此同时,按照数据脉动的方式将矩阵B的子矩阵按行输入到可重构运算阵列中;矩阵B的子矩阵中的数据进入PE单元后和对应的矩阵A中的数据进行乘法运算,将乘法结果横向传递,并在每传递到下一个PE单元与下一个PE单元的乘法结果进行相加,得到输出结果,并在存储控制器的控制下储存到数据存储器中。
进一步优选地,当前工作模式为辅工作模式时,存储控制器控制进行矩阵乘法运算的矩阵A、B输入到可重构运算阵列的过程中,将矩阵A每隔L列进行一次分割,得到A=[A
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
1、本发明提供了一种用于矩阵乘法密集型算法的可重构矩阵乘法加速系统,预先统计矩阵乘法密集型算法中的所有进行矩阵乘法运算的矩阵A、B的尺寸以及矩阵乘法运算量,对矩阵乘法密集型算法中的各矩阵乘法进行分类,并确定可重构运算阵列的规模以及所具有的工作模式。当将待计算矩阵乘法输入系统中时,基于矩阵尺寸判断矩阵乘法的类别以确定可重构运算阵列的当前工作模式,并根据该工作模式对应配置存储控制器对矩阵进行分割,同时配置可重构运算阵列中运算单元的互联及可重构运算阵列中的数据流来完成矩阵乘法运算;减少了可重构矩阵乘法硬件加速设计的重构模式,进一步地压缩了可重构矩阵乘法硬件加速设计的控制复杂度,减少了控制部分的硬件开销。同时实现了更符合该具体矩阵乘法密集型算法特点的高效的可重构运算阵列数据流设计,提升了矩阵乘法密集型算法中矩阵乘法的运算效率。
2、本发明所提供的用于矩阵乘法密集型算法的可重构矩阵乘法加速系统,通过依据矩阵的尺寸对矩阵乘法进行分类,充分考虑了某一具体算法内的矩阵尺寸的多样性和特殊性。且由于矩阵乘法运算规则的特殊性,依据特定尺寸设计数据流,可以实现更高的运算效率。除此之外,通过依据矩阵尺寸的分类规则,可以简化现有矩阵乘法硬件加速器中的存储控制复杂度。
3、本发明所提供的用于矩阵乘法密集型算法的可重构矩阵乘法加速系统,所提出的矩阵分割方案,是在配合所提出的可重构运算阵列的规模基础上所设计的,所以相对现有的工作而言,可以更好地匹配数据流,从而提高运算效率,除此之外,还可以在保证运算效率的前提下,保证内部缓存开销尽量的少。
附图说明
图1是本发明所提供的用于矩阵乘法密集型算法的可重构矩阵乘法加速系统的结构示意图;
图2是本发明所提供的依据EKF算法中各矩阵乘式的运算量和矩阵尺存特点进行划分后的结果示意图;
图3是本发明实施例所提供的针对EKF算法中的矩阵乘法所设计的可重构运算阵列示意图;
图4是本发明实施例所提供的针对EKF算法中的两大类矩阵乘法所设计的可重构运算阵列的两种工作模式的示意图;
图5是本发明实施例所提供的第一类矩阵乘法运算中矩阵的分割方案示意图;
图6是本发明实施例所提供的第二类矩阵乘法运算中矩阵的分割方案示意图;
图7是本发明实施例所提供的主工作模式下可重构运算阵列数据流;
图8是本发明实施例所提供的主工作模式下计算矩阵乘法时的部分数据流动时空图;
图9是本发明实施例所提供的辅工作模式下可重构运算阵列数据流;
图10是本发明实施例所提供的辅工作模式下计算矩阵乘法时的第一阶段的部分数据流动时空图;
图11是本发明实施例所提供的辅工作模式下计算矩阵乘法时的第二阶段的部分数据流动时空图;
图12是本发明实施例所提供的针对矩阵乘法密集型算法的可重构矩阵乘法硬件加速系统的设计方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
为了实现上述目的,本发明通过充分考虑具体矩阵乘法密集型算法内矩阵尺寸的多样性和特殊性,来压缩可重构矩阵乘法硬件加速设计的控制复杂度,减少控制部分的硬件开销,同时实现更符合该具体算法特点的高效的可重构运算阵列数据流设计,提升整体矩阵乘法的运算效率。具体的,本发明所提供的一种针对矩阵乘法密集型算法的可重构矩阵乘法硬件加速系统的设计方法,如图12所示,包括以下步骤:S1、对矩阵乘法密集型算法中的所有矩阵乘法,根据矩阵尺寸和矩阵乘法运算量进行分类;S2、根据矩阵乘法密集型算法中所有进行矩阵乘法运算的矩阵尺寸、应用场景以及所要求的运算效率确定可重构运算阵列的规模,具体针对运算量最大的一类或几类矩阵乘式来进行可重构运算阵列的规模设计;S3、根据可重构运算阵列的规模分别对矩阵乘法中的矩阵进行分割;S4、根据矩阵乘法的类别,确定可重构运算阵列的工作模式,进而对可重构运算阵列中的PE单元的互联方案进行设计,其中每一种工作模式均对应一种矩阵乘法类别;S5、基于设计好的可重构运算阵列中PE单元的互联方案,针对不同类别的矩阵乘式进行可重构运算阵列数据流的设计。
具体的,本发明基于上述可重构矩阵乘法硬件加速系统的设计方法,提出了一种用于矩阵乘法密集型算法的可重构矩阵乘法加速系统,如图1所示,包括:缓存器1、可重构矩阵乘法控制器2、存储控制器3、数据存储器4和可重构运算阵列5;其中,可重构运算阵列5为多个PE单元互联组成的阵列,其规模由矩阵乘法密集型算法中所有进行矩阵乘法运算的矩阵尺寸、应用场景以及所要求的运算效率确定,记为L×S;
缓存器1用于接收并缓存通过BUS总线输入的矩阵乘法密集型算法中的当前待计算矩阵乘法的矩阵;
可重构矩阵乘法控制器2用于获取缓存器1中当前待进行矩阵乘法运算的矩阵尺寸,基于矩阵尺寸判断矩阵乘法的类别以确定可重构运算阵列的当前工作模式,并根据当前工作模式对存储控制器3和可重构运算阵列5进行配置;需要说明的是,在系统的初始状态下,可重构矩阵乘法控制器2预先统计矩阵乘法密集型算法中的所有进行矩阵乘法运算A×B的矩阵A、B的尺寸以及矩阵乘法运算量,以矩阵中行数和列数之间的差异为特征,同时根据矩阵乘法中A矩阵的列数和B矩阵的行数必须相等这一规则,将矩阵乘法划分为六大类,具体为:矩阵A为横长条且矩阵B为竖长条,矩阵A为竖长条且矩阵B为横长条,矩阵A为竖长条且矩阵B为方正形,矩阵A为方正形且矩阵B为横长条,矩阵A和B均为方正形以及矩阵A为横长条且矩阵B为方正形;然后根据各类矩阵乘法的计算量占整个算法中所有矩阵乘法总计算量的比例分布,对矩阵乘法进行重组分类,且在重组的过程中,避免将矩阵A为横长条和矩阵A为竖长条的矩阵乘法划分为一类,以及避免将矩阵B为横长条和矩阵B为竖长条的矩阵乘法划分为一类,以保证重组分类后的各类矩阵乘法的计算量相差在20%以内;优选地,重组分类后的各类矩阵乘法的计算量相差在10%以内。需要说明的是,这里某一类矩阵乘法的计算量为该类中各矩阵乘法计算量的总和。
存储控制器3用于控制缓存器1将其缓存的当前待计算矩阵乘法的矩阵存储到数据存储器4中;基于当前配置控制数据存储器4将当前待计算矩阵乘法的矩阵按照预设分割模式进行分割后以脉动的方式输入到可重构运算阵列中(控制分割后的对应的两个输入矩阵以脉动的方式进行数据流动,一个按行输入数据,一个按列输入数据);具体的,在数据输入的过程中,根据可重构运算阵列5的规模L×S对当前待计算矩阵乘法运算的矩阵进行分割。具体的,上述预设分割模式为:对于当前待计算矩阵乘法运算A×B的矩阵A、B,若矩阵A为横长条形或方正形、且矩阵A的列数大于L,则将矩阵A每隔L列进行一次分割,直至不能分割为止;此时,若矩阵B的行数大于L,则将矩阵B每隔L行进行一次分割,直至不能分割为止;与此同时,若矩阵B的列数大于S,则将矩阵B每隔S列进行一次分割;若矩阵A为竖长条、且矩阵A的列数大于S,则将矩阵A每隔S列进行一次分割,直至不能分割为止;此时,若矩阵B的行数大于S,则将矩阵B每隔S行进行一次分割,直至不能分割为止;与此同时,若矩阵B的列数大于L,则将矩阵B每隔L列进行一次分割,直至不能分割为止。
可重构运算阵列5用于基于存储控制器的输入控制,实现矩阵的乘法运算,并将计算结果存储至数据存储器中。
进一步地,PE单元包括电路开关和执行单元;可重构运算阵列包含多种工作模式,具体为一种主工作模式和多种辅工作模式。矩阵乘法密集型算法中的每种矩阵乘法类型均对应一种工作模式,在不同的工作模式下,PE单元的电路开关被配置成不同的连接方式,以使得运算过程中能够实现尽量高的硬件利用率和运算效率。具体的,连接方式的设计规则为:以加速主工作模式为主,且辅工作模式的连接方式不会破坏或者影响主工作模式的工作效率。
下面结合具体的矩阵乘法密集型算法进行详细介绍,需要说明的是,矩阵乘法密集型算法可以为EKF算法,但不限于EKF算法。下面以矩阵乘法密集型算法为EKF算法为例进行详述;具体的,在系统的初始状态下,可重构矩阵乘法控制器预先统计EKF算法中的所有进行矩阵乘法运算的矩阵A、B的尺寸以及矩阵乘法运算量;具体的,对矩阵乘法运算A×B,一共存在7种不同尺寸的矩阵乘法,如表1所示,其中,r为传感器的位置向量维数,S为特征点的位置向量维数,n为特征点的数量,c为EKF算法中对特征点信息的调用次数(一般与n相等),均为EKF算法中的相关参数。
表1
首先,依据矩阵的尺寸对矩阵乘法进行初步分类:如果矩阵的行数和列数的差距相对较大(为3-5倍及以上倍数),则将该矩阵划分为长条形矩阵,如果矩阵的行数和列数相差不多或者较小(为相等或差距在3-5倍以内),则将该矩阵划分为方正形矩阵(例如,若s=2,r=3,c=n=40,则表1中的矩阵乘法(5)中矩阵A的行数为83,列数为2,则矩阵A为长条形矩阵,进一步地可以叫做竖长条形矩阵)。具体的,对于矩阵乘法A×B,依据矩阵A和矩阵B的尺寸情况,将矩阵乘法初步划分为:1、矩阵A为横长条且矩阵B为竖长条,对应于表1中的(7);2、矩阵A为竖长条且矩阵B为横长条,对应于表1中的(5);3、矩阵A为竖长条且矩阵B为方正形,对应于表1中的(3)、(4)、(6);4、矩阵A为方正形且矩阵B为横长条,对应于表1中的(2);5、矩阵A和B均为方正形,对应于表1中的(1);然后,分别计算各类矩阵乘法的计算量,根据各类矩阵乘法的计算量占所有矩阵乘法的总计算量(包括矩阵的尺寸大小和矩阵乘法的运算次数)的比例分布,将矩阵乘法进一步划分为运算量相当的几类,在且在划分的过程中,避免将矩阵A为横长条和矩阵A为竖长条的矩阵乘法划分为一类,以及避免将矩阵B为横长条和矩阵B为竖长条的矩阵乘法划分为一类,使得进一步划分后的各类矩阵乘法的计算量相差在10%以内,得到如图2所示的划分结果,其中,最终的第一类矩阵乘法为表1中的(5),其计算量占所有矩阵乘法的总计算量的60%以上;第二类矩阵乘法由其余的矩阵乘法构成。基于上述分类可以看出,表1中的(5)的计算量占所有矩阵乘法的总计算量的60%以上,且EKF算法中(5)的矩阵尺寸的行数和列数相差非常大的,这一尺寸特点和其它六种尺寸的矩阵乘式并不存在共同点,故需要重点进行加速计算。对应的,本实施例中,上述可重构运算阵列包括两种工作模式,分别记为主工作模式和辅工作模式;EKF算法中的每种矩阵乘法类型均对应一种工作模式,在可重构运算阵列中,横向和纵向上相邻的PE单元相连,相邻的PE单元之间可以进行通信,通信的方向为横向和纵向;主工作模式用于处理第一类矩阵乘法运算,此时,PE单元在纵向传递输入数据,在横向传递部分和;辅工作模式用于处理第二类矩阵乘法运算,此时,PE单元在纵向传递部分和,在横向传递输入数据;其中,部分和为将当前PE单元的计算结果与上一个PE单元的计算结果进行累加后的结果。这里由于EKF算法对运算速度要求不高,所以所设计的可重构运算阵列之间的连接方式为简单的相邻单元间互联,以避免复杂的互联资源带来不必要的硬件开销。基于这一互联资源,针对主工作模式,为尽量实现高的硬件效率,即在得到一个乘法结果的时候,前级累加的结果也刚好计算完成,从而实现数据不存在等待,运算资源不存在等待的情况,最终达到运算效率高且硬件利用率高的效果。辅工作模式的PE单元间互联方案的设计核心思想与主工作模式的核心思想一致,但应遵循辅工作模式的连接方式不应破坏或者影响主工作模式的工作效率。具体的,如图3所示,本实施例所提出的可重构运算阵列在第一行PE单元的上方设置有数据输入端口dina_north,在第一列的PE单元的左边设置有数据输入端口dina_west,同时每个PE单元都设置有数据输入端口dinb_west,可重构运算阵列的最右边一列PE单元的右边设置有数据输出端口dout_east,可重构运算阵列的最下面一行PE单元的下面也设置有数据输输出端口dout_south。进一步地,如图4所示,主工作模式用来计算第一类矩阵乘法,在主工作模式下,可重构运算阵列被配置为:PE单元在纵向传递输入数据,在横向传递部分和。辅工作模式用来计算第二类矩阵乘法,在辅工作模式下,可重构运算阵列被配置为:PE单元在纵向传递部分和,在横向传递输入数据。故当进行矩阵乘法运算时,可重构矩阵乘法控制器可以将当前待进行矩阵乘法运算的矩阵尺寸与上述的划分结果进行匹配,得到当前矩阵乘法的类别以确定可重构运算阵列的当前工作模式,并根据当前工作模式对存储控制器和可重构运算阵列进行配置。
存储控制器基于当前配置控制数据存储器将当前待计算矩阵乘法的矩阵中的数据按照一定的规则输入到可重构运算阵列中;具体的,在将矩阵输入到可重构运算阵列的过程中,根据可重构运算阵列的规模L×S对当前待计算矩阵乘法运算的矩阵进行分割。需要说明的是,可重构运算阵列的规模由矩阵乘法密集型算法中所有进行矩阵乘法运算的矩阵尺寸、应用场景以及所要求的运算效率确定;本实施例充分考虑EKF算法中7种尺寸的矩阵乘式所涉及到的矩阵尺寸,提出的可重构运算阵列设计为L行S列,其中,L为根据EKF算法的应用场景以及所要求的运算效率所预设的行数,S为EKF算法中特征点的位置向量维数。本实施例中通过在不同的L下,建立数学模型对不同的矩阵乘法运算速度进行评估,在保证满足应用场景以及所要求的运算效率的前提下,选择尽量小的L。
具体的,图5展示了对EKF算法中第一类矩阵乘法中的矩阵分割方式。对于矩阵尺寸为S*(r+Sn)的第二个输入矩阵B,在本实施例中将其按照每L列进行分割,即将502分割成若干个505。图6展示了EKF算法中第二类矩阵乘法中的矩阵分割方式。由于本实施例中的可重构运算阵列的规模设计为L×S,所以在进行矩阵分割时应该将矩阵分割成L*S或者S*L的子矩阵。例如,在计算第(1)种矩阵乘法时,先将矩阵尺寸为r*r的第二个输入矩阵B按照S列进行分割(即将602分解成若干个606),再将矩阵尺寸为r*r的第一个输入矩阵A按照L列进行分割(即将605分解成若干个609),同时对已经分割好的B的每个子矩阵按照每L行进行分割(即将606分解成若干个610)。上述分割过程通过存储控制器控制数据存储器将当前待计算矩阵乘法的矩阵中的数据输入到可重构运算阵列中来实现,即通过可重构运算阵列数据流的控制来实现。
具体的,在本实施例中,结合EKF算法使用在SLAM算法中的经验参数来举例说明主工作模式下可重构运算阵列的数据流。图7以L=3,S=2为例来介绍主工作模式下可重构运算阵列的数据流。其中,数据存储器包括两个输入矩阵缓冲存储器(701和703)、一个输出矩阵缓冲存储器(714)和两个FIFO(分别记为FIFO1和FIFO2,即708和713);存储控制器包括开关网络Switch network(702)和两个多路选择器MUX(704和709)。具体的,两个输入矩阵缓冲存储器(701和703)和一个输出矩阵缓冲存储器714都设计有L=3条bank。可重构运算阵列配置为主工作模式的互联方式,同时配置有S=2个FIFO(708和713)连接在可重构运算阵列的最下面一行PE单元(即707和712)的下面。一个输入矩阵缓冲存储器703中的数据通过和FIFO中的数据经过多路选择器MUX(即704和709)后进入可重构运算阵列的上方。另一个输入矩阵缓冲存储器701通过开关网络702分别连接到可重构运算阵列的每个PE单元,在PE单元内计算完成后,通过纵向的输入数据传递以及横向的部分和传递后,可重构运算阵列的右边一列PE单元的右边端口(即710-712)输出矩阵运算的结果,存进输出矩阵缓冲器714。进一步地,图8为以第一个输入矩阵A(尺寸为9*2)和第二个输入矩阵B(尺寸为2*9)为例,展示计算第一类矩阵乘法时矩阵分割以及矩阵输出的情况。首先,存储控制器在控制进行矩阵乘法运算的矩阵A、B输入到可重构运算阵列的过程中,将矩阵B按列分割为多个子矩阵,每个子矩阵的列数为L=3,使矩阵A分别与各矩阵B的子矩阵进行乘法运算,得到矩阵A和B的乘法运算结果。本实施例将B矩阵按照L=3分成三个子矩阵,矩阵A依次和每个子矩阵进行矩阵乘法即可得到对应列的输出矩阵C。然后,在存储控制器的控制下按照数据脉动的方式将矩阵A按列分别输入到可重构运算阵列中;与此同时,按照数据脉动的方式将矩阵B的子矩阵按行输入到可重构运算阵列中;矩阵B的子矩阵中的数据进入PE单元后和对应的矩阵A中的数据进行乘法运算,将乘法结果横向传递,并在每传递到下一个PE单元与下一个PE单元的乘法结果进行相加,得到输出结果,并在存储控制器的控制下储存到数据存储器中。图8以矩阵A和矩阵B的第三个子矩阵相乘为例,展示了本发明所提出可重构矩阵乘法硬件加速系统主工作模式下的数据流时空图。对于矩阵A而言,A中的数据按列分别从可重构运算阵列的上方S=2个端口进入,每个时钟周期进入一组数据,同时B的子矩阵中的数据按行分别进入可重构运算阵列的每个PE单元,每个时钟周期进入一组数据。矩阵A中的数据纵向传递,最后进入FIFO1和FIFO2中缓存,用来准备计算下一次的矩阵A和B的其它子矩阵乘法。矩阵B的数据进入PE单元后和对应的矩阵A的数据进行乘法后,将这一结果横向传递,并在每传递到下一个PE单元后,都与该PE单元的乘法结果进行相加,从而得到输出结果,即输出矩阵C的子矩阵,并从可重构运算阵列的右边端口输出。
进一步地,在本实施例中,结合EKF算法使用在SLAM算法中的经验参数来举例说明辅工作模式可重构运算阵列的数据流。图9以L=3,S=2为例来介绍辅工作模式下可重构运算阵列的数据流。其中,数据存储器包括两个输入矩阵缓冲存储器(901和903)、一个输出矩阵缓冲存储器(914)和两个FIFO(分别记为FIFO1和FIFO2,即907和911);存储控制器包括开关网络Switch network(902)和两个多路选择器MUX(912和913)。两个输入矩阵缓冲存储器901、903和一个输出矩阵缓冲存储器914都设计有L=3条bank。可重构运算阵列配置为辅工作模式的互联方式,同时配置有S=2个FIFO(907和911)连接在可重构运算阵列的最下面一行PE单元的下面。一个矩阵缓冲存储器901通过开关网络分别连接到可重构运算阵列的每个PE单元,另一个矩阵缓冲存储器903连接到可重构运算阵列的左边一列PE单元904-906上,在PE单元内计算完成后,通过纵向的部分和传递和横向的输入数据传递后,可重构运算阵列的下面一行PE单元的下方端口输出矩阵运算的结果,存进输出矩阵缓冲器914。进一步地,图10以第一个输入矩阵A(尺寸为6*6),第二个输入矩阵B(尺寸为6*6)为例,展示计算第二类矩阵乘法时矩阵分割以及矩阵输出的情况。首先,存储控制器控制进行矩阵乘法运算的矩阵A、B输入到可重构运算阵列的过程中,将矩阵A每隔L列进行一次分割,得到A=[A
具体的,在第一阶段,对于矩阵A的前L=3列子矩阵而言,在存储控制器的控制下按照数据脉动的方式按列分别从可重构PE阵列的左边一列PE单元的L=3个端口进入,每个时钟周期进入一组数据;同时在存储控制器的控制下按照数据脉动的方式将矩阵B的前S=2列大子矩阵的前L=3行的子矩阵按行分别进入可重构PE阵列的每个PE单元,每个时钟周期进入一组数据。矩阵A的子矩阵数据横向传递,矩阵B的数据进入PE单元后和对应的矩阵A的数据进行乘法后,将这一结果纵向地传递,并每在传递到下一个PE单元后,都与该PE单元的乘法结果进行相加,再传递到下一个PE单元重复这一操作,最终得到输出结果,从可重构PE阵列最下面一行的端口输出,分别按列进入FIFO1和FIFO2中缓存,至此第一阶段结束。
在第二阶段,矩阵A的后L=3列子矩阵在存储控制器的控制下按照数据脉动的方式按列分别从可重构PE阵列的左边一列PE单元的L=3个端口进入,每个时钟周期进入一组数据;同时在存储控制器的控制下按照数据脉动的方式将矩阵B的前S=2列大子矩阵的后L=3行小子矩阵按行分别进入可重构PE阵列的每个PE单元,每个时钟周期进入一组数据。同时在阶段一中存进FIFO1和FIFO2中的中间数据将从可重构PE阵列的最上面一行PE单元进入,且这一数据将纵向传递,并在传递到下一个PE单元后,都与该PE单元的乘法结果进行相加,再传递到下一个PE单元并重复这一操作。最终,输出结果从可重构PE阵列最下面一行的端口输出,得到输出矩阵C的子矩阵,并存进输出矩阵缓冲器中,至此第二阶段结束。
基于上述规则,将待计算的矩阵输入到可重构矩阵乘法加速系统后,可重构矩阵乘法控制器先获取所输入矩阵的尺寸信息,再根据该尺寸信息判断所需要进行的矩阵乘法属于第几类,以确定可重构运算阵列的当前工作模式,并根据当前工作模式对存储控制器和可重构运算阵列进行配置。随后,存储控制器在控制数据存储器将当前待计算矩阵乘法的矩阵中的数据输入到可重构运算阵列中时,对矩阵预设分割模式进行分割,分割成适应于当前工作模式下的子矩阵,随后将分割好的子矩阵依次送进可重构运算阵列进行计算,最终求得矩阵乘法的输出矩阵。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种用于矩阵乘法密集型算法的可重构矩阵乘法加速系统
- 一种应用于三角矩阵与矩阵乘法的加速方法及其加速装置