一种基于自然语言模型的码床系统
文献发布时间:2023-06-19 10:00:31
技术领域
本发明涉及IT行业的自动代码编写的技术领域,具体来说,涉及一种基于自然语言模型的码床系统。
背景技术
当前主流的编程方法,主要基于常见的Eclipse、Visual Studio、ANSI C/C++等等编程工具,基于特定编程语言(比如:C、C++、Basic、Java、Java Script、HTML、SQL、GO等等)技术标准,通过人的智能设计,进行编码实现。一般情况下包括:需求分析、概要设计、详细设计、代码编写、编译、测试、缺陷修复等等若干个工作步骤,最终形成可运行的软件系统。为了实现上述工作,一般情况下需要配备:项目经理、产品经理、界面交互设计师、架构设计师、数据库设计师、编码工程师、测试工程师、部署工程师等等若干个角色,一个团队角色不齐全基本无法顺利开展工作。
由于软件产品能够提供的价值日益凸显,各个行业对软件产品的需求旺盛,培养出来的专业技术人员成长需要较长的时间,人员缺口较大,供需规律导致行业人才的薪资成本不断上升,已经导致其发展陷入一种瓶颈,已经难以满足爆发式增长的行业需求。同时,整个行业的缺口导致各种专业基础较薄弱的其他专业人才转型进入软件研发行业,整个行业的技术人才的水平良莠不齐,对软件行业的培养、管理形成了巨大的压力,进一步使得软件企业的人力成本成为发展的巨大障碍。
本发明能够有效解决上述问题:(1)通过自然语言为主要输入,通过分词要素分解的方法,建立自然语言、业务语言转化成为程序设计语言的规则体系。(2)基于语法分解,循序渐进,逐层分解,实现业务逻辑的清晰梳理。(3)基于数据模型驱动,有效衔接业务逻辑与自动编码实现的联系。(4)结合单项管理(对象、补充数据)与联合管理(业务管理),极大简化自动编码的逻辑设计难度。(5)基于代码生成器,全面整合前期工序的成果,基于特定编程语言技术标准,自动编写生成相应技术代码,摆脱对编码工程师的依赖。(6)代码生成器自动编写的技术代码,具有极高的准确性,只需要进行核对,无须进行各种复杂测试和缺陷修复。
通过本系统的实现,可以帮助软件企业极大缩减软件团队的规模,并且团队成员的技能可以更多专注在业务方向,从而能够极大提高软件研发实现过程的生产效率,进而提升整个软件行业的作用和价值。
针对相关技术中的问题,目前尚未提出有效的解决方案。
发明内容
针对相关技术中的问题,本发明提出一种基于自然语言模型的码床系统,以克服现有相关技术所存在的上述技术问题。
为此,本发明采用的具体技术方案如下:
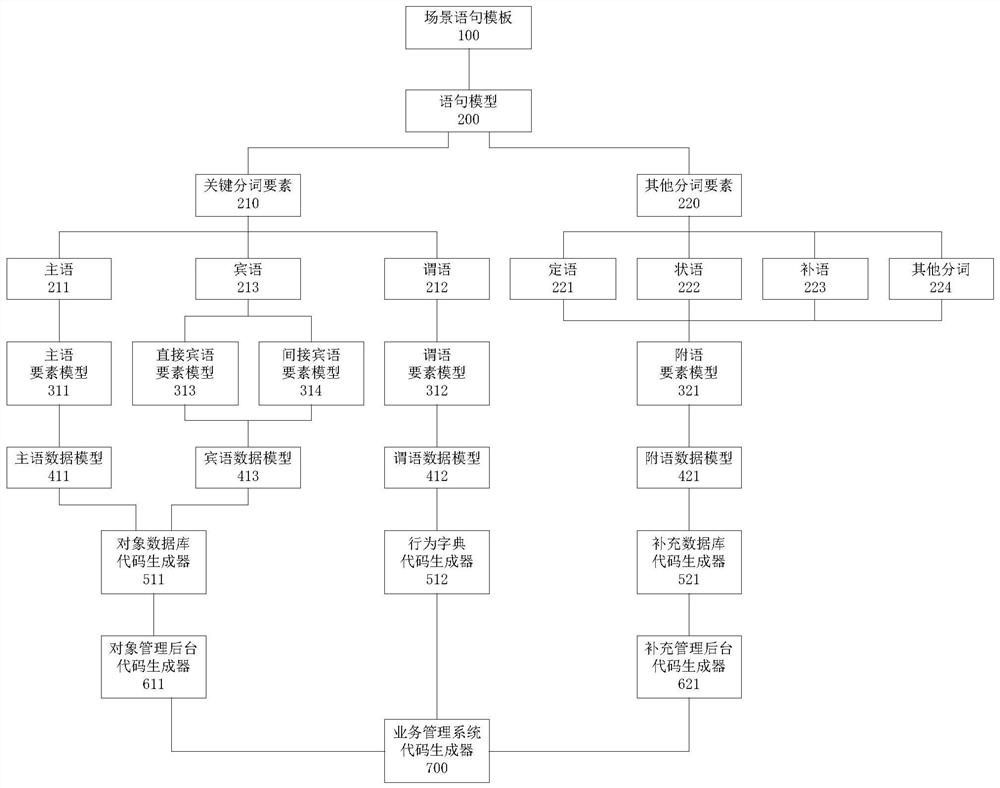
一种基于自然语言模型的码床系统,包括场景语句模板、语句模型、关键分词要素、其他分词要素、主语、谓语、宾语、定语、状语、补语、其他分词、主语要素模型、谓语要素模型、直接宾语要素模型、间接宾语要素模型、附语要素模型、主语数据模型、谓语数据模型、宾语数据模型、附语数据模型、对象数据库代码生成器、行为字典代码生成器、补充数据库代码生成器、对象管理后台代码生成器、补充管理后台代码生成器、业务管理系统代码生成器。
进一步的,所述场景语句模板,以汉语常规格式的语句形式,把一些典型场景的业务语言经过提炼,形成模板,作为可以直接使用的业务场景,或者作为新业务场景参照的样板。所述场景语句模板中的记录,已经在本系统中形成了完整的实现,并通过本系统生成了相应的代码,已经具备可运行的能力。所述场景语句模板中的记录,可以进行扩展和补充,将后期实现的具备参考价值的业务场景的实现,将其“场景语句”作为模板合并到本系统的所述场景语句模板中。每一条场景语句的模板,已经预先完成分词,并可根据其中“主语”、“谓语”、“直接宾语”、“间接宾语”的情况,快速匹配到“典型句型结构”。
进一步的,所述语句模型,由所述关键分词要素和所述其他分词要素组成。所述关键分词要素可以组成“语句主干”,“语句主干”加上“其他分词要素”(附语分词要素)组成完整的语句模型,对于优化语法格式的各个分词,进行结构化的数据组织后,形成优化后的附语语句模型。所述关键分词要素包括所述主语、所述谓语、所述宾语,根据语法的进一步分解,将所述宾语进一步拆分成为含义更加明确的“直接宾语”、“间接宾语”。主语分为:施事主语、受事主语、其他主语;谓语分为:动词谓语、名词谓语、主谓谓语、其他谓语;宾语(直接宾语、间接宾语)分为:名词性宾语、谓词性宾语、其他宾语。所述其他分词要素(附语分词要素)包括所述定语、所述状语、所述补语、所述其他分词。定语分为:描写性定语、限制性定语、其他定语;状语分为:描写性状语、限制性状语、其他状语;补语分为:结果补语、程度补语、状态补语、趋向补语、数量补语、时间/处所补语、可能补语、其他补语。场景语句的主干,具备清晰的必要关键分词要素(主语、谓语、直接宾语、间接宾语)中的部分,以确保后续的代码生成器能够获取足够的前置条件数据。
进一步的,所述主语要素模型、所述谓语要素模型、所述直接宾语要素模型、所述间接宾语要素模型、所述附语要素模型。所述主语要素模型是对所述主语这个分词要素所包含信息的模型。通过多个维度的数据,说明主语对象具备的特征,从而帮助用户理解主语对象,并且可以关联多个附语,用于补充说明当前场景中主语对象的补充信息。主语是语句整体陈述的对象,一般以“人”最为常见,在常见的“干什么”、“是什么”、“怎么样”的情景中,主语受谓语陈述。
进一步的,所述主语数据模型、所述谓语数据模型、所述宾语数据模型、所述附语数据模型。“主语数据模型”,是对所述主语要素模型建立数据模型的过程,所述主语数据模型是对所述谓语要素模型建立数据模型的过程,与所述主语数据模型的设计方法相同,同样采用列名、类型、长度、精度、主键、外键、强制非空的设计方式。所述宾语数据模型是对所述直接宾语要素模型、所述间接宾语要素模型建立数据模型的过程,与所述主语数据模型的设计方法相同,同样采用列名、类型、长度、精度、主键、外键、强制非空的设计方式。所述附语数据模型是对所述附语要素模型建立数据模型的过程,与所述主语数据模型的设计方法相同,同样采用列名、类型、长度、精度、主键、外键、强制非空的设计方式。
进一步的,所述对象数据库代码生成器,“对象”是主语和宾语的主体的合并描述,本模块是根据所述主语数据模型或者所述宾语数据模型,按照其共同的设计(列名、类型、长度、精度、主键、外键、强制非空),遵照数据库类型对应的编程语言规范,自动生成建表脚本。具体新建的数据库表的表名、字段(列)名、字段类型、取值长度、取值精度、主键索引、非空等特性,均根据设计进行对应,在建表脚本中进行体现。其中,数据库表的表名——要素模型名称,数据库表的字段名——要素模型的列名,数据库表的字段类型——要素模型的类型,数据库表的取值长度——要素模型的长度,数据库表的取值精度——要素模型的精度,数据库表的主键索引——要素模型的主键,数据库表的非空——要素模型的强制非空;要素模型中的外键,如果按照关系型数据库的设计对应数据库表的外键(强制约束),如果按照非关系型数据库的设计,通过关联逻辑对应到另一个数据模型的主键(不强制约束)。
进一步的,所述行为字典代码生成器,“行为字典”是谓语的行为名称的字典集合,本模块是根据所述谓语数据模型,按照其设计(列名、类型、长度、精度、主键、外键、强制非空),遵照数据库类型对应的编程语言规范,自动生成建表脚本。具体新建的数据库表的表名、字段(列)名、字段类型、取值长度、取值精度、主键索引、非空等特性,均根据设计进行对应,在建表脚本中进行体现。其中,数据库表的表名——要素模型名称,数据库表的字段名——要素模型的列名,数据库表的字段类型——要素模型的类型,数据库表的取值长度——要素模型的长度,数据库表的取值精度——要素模型的精度,数据库表的主键索引——要素模型的主键,数据库表的非空——要素模型的强制非空;要素模型中的外键,如果按照关系型数据库的设计对应数据库表的外键(强制约束),如果按照非关系型数据库的设计,通过关联逻辑对应到另一个数据模型的主键(不强制约束)。因为行为字典中的记录,根据业务可以分析确定,并且在后续业务管理过程中,主要以引用为主,因此本系统在此模块中生成代码的时候,可直接生成创建具体数据记录的代码。
进一步的,所述补充数据库代码生成器,“补充信息”是对“附语”的称谓,本模块是根据所述谓语数据模型,按照其设计(列名、类型、长度、精度、主键、外键、强制非空),遵照数据库类型对应的编程语言规范,自动生成建表脚本。具体新建的数据库表的表名、字段(列)名、字段类型、取值长度、取值精度、主键索引、非空等特性,均根据设计进行对应,在建表脚本中进行体现。其中,数据库表的表名——要素模型名称,数据库表的字段名——要素模型的列名,数据库表的字段类型——要素模型的类型,数据库表的取值长度——要素模型的长度,数据库表的取值精度——要素模型的精度,数据库表的主键索引——要素模型的主键,数据库表的非空——要素模型的强制非空;要素模型中的外键,如果按照关系型数据库的设计对应数据库表的外键(强制约束),如果按照非关系型数据库的设计,通过关联逻辑对应到另一个数据模型的主键(不强制约束)。
进一步的,所述对象管理后台代码生成器、所述补充管理后台代码生成器。所述对象管理后台代码生成器,本模块是根据已经生成的“对象数据库(表)”,自动生成相应的“管理后台”的代码。主要包括以下步骤:(1)模板化界面功能特性选择:可通过模板化的界面功能特性自动生成对象的后台管理系统,也支持操作人员介入调整部分界面功能特性通过半自动方式生成对象的后台管理系统。(2)管理后台代码生成:按照前一步骤选定的功能特性,本系统可以自动生成管理后台的前端界面的代码,并且自动生成“前端界面”、“后端接口服务”,并且前端界面的代码会自动调用相应的后端接口服务,以确保相应的操作能够通过后端接口服务的代码执行,在相应的数据库表的数据操作层面得到正确实现。
进一步的,所述业务管理系统代码生成器根据已经生成的所述主语数据模型、所述谓语数据模型、所述宾语数据模型、所述附语数据模型对应的“数据库(表)”,结合所述语句模型对应的语句关键分词要素模型中说明的各个分词之间的关联关系,自动生成业务操作层面的代码。主要包括以下步骤:(1)数据库表自动筛选:根据语句关键分词要素模型,结合前期各个步骤对各个分词要素模型、分词数据模型生成的数据库代码,获得对应各个分词的数据库表的对应关系,然后依次选中各个数据库表,作为下一个步骤的输入数据;(2)模板化界面功能特性选择:可通过模板化的界面功能特性自动生成后台管理系统,也支持操作人员介入调整部分界面功能特性通过半自动方式生成后台管理系统。(3)业务行为数据库代码生成:根据模板化界面功能特性选择的结果,自动生成业务管理行为数据库代码,创建业务管理行为数据库表;(4)业务管理系统代码生成:按照前一步骤选定的功能特性,本系统可以自动生成业务管理系统的前端界面的代码,并且自动生成“前端界面”、“后端接口服务”,并且前端界面的代码会自动调用相应的后端接口服务,以确保相应的操作能够通过后端接口服务的代码执行,在相应的数据库表的数据操作层面得到正确实现。
本发明的有益效果为:
1、通过自然语言为主要输入,确定软件系统的业务场景需求,并确定相关语句模板、语句模型、分词要素模型、数据模型。
2、通过语句模板、语句模型、关键分词要素、其他分词要素、语句主干数据模型等等体系化设计,将场景描述语言自动分解、梳理成为可被机器系统理解的数据模型。
3、基于数据模型,通过数据库代码生成器,生成数据库代码,进一步创建数据库表并完成相关数据记录的初始化。
4、通过单项管理后台代码生成器(对象管理后台代码生成器、补充管理后台代码生成器),完成对单一项目(对应单一分词要素)的单项管理的软件系统代码的自动生成。
5、以单项管理后台代码生成器(对象管理后台代码生成器、补充管理后台代码生成器)为基础,通过联合管理代码生成器(业务管理系统代码生成器),完成上层业务应用的软件系统代码的自动生成。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1:自然语言码床系统结构图;
图2:典型场景语句模板;
图3:典型句型结构;
图4:银行柜台存款、取款单一业务行为场景语句分词;
图5:银行柜台业务优化场景语句模板;
图6:银行柜台业务优化场景语句模型;
图7:银行柜台业务优化场景附语语句模型;
图8:银行柜台业务场景语句主干数据模型;
图9:银行柜台业务场景语句关键分词要素模型;
图10:银行柜台业务主语要素模型
图11:银行柜台业务谓语要素模型
图12:银行柜台业务直接宾语要素模型
图13:银行柜台业务间接宾语要素模型
图14:银行柜台业务附语要素模型
图15:银行柜台业务附语要素模型
图16:银行柜台业务附语要素模型
图17:银行柜台业务附语要素模型
图18:主语数据模型
图19:谓语数据模型
图20:宾语数据模型
图21:宾语数据模型
图22:附语数据模型
图23:附语数据模型
图24:附语数据模型
图25:附语数据模型
图26:对象数据库代码;
图27:行为字典数据库代码;
图28:补充数据库代码;
图29:模板化界面功能特性选择;
图30:单项管理后台代码生成前端界面;
图31:业务管理系统模板化界面功能特性选择;
图32:业务行为数据库代码生成;
图33:业务管理系统新增操作界面;
图34:业务管理系统代码生成前端界面。
图中:
100、场景语句模板;200、语句模型;210、关键分词要素;220、其他分词要素;211、主语;212、谓语;213、宾语;221、定语;222、状语;223、补语;224、其他分词;311、主语要素模型;312、谓语要素模型;313、直接宾语要素模型;314、间接宾语要素模型;321、附语要素模型;411、主语数据模型;412、谓语数据模型;413、宾语数据模型;421、附语数据模型;511、对象数据库代码生成器;512、行为字典代码生成器;521、补充数据库代码生成器;611、对象管理后台代码生成器;621、补充管理后台代码生成器;700、业务管理系统代码生成器。
具体实施方式
为进一步说明各实施例,本发明提供有附图,这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理,配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点,图中的组件并未按比例绘制,而类似的组件符号通常用来表示类似的组件。
根据本发明的实施例,提供了一种基于自然语言模型的码床系统。
实施例一:
如图1-34所示,根据本发明实施例的基于自然语言模型的码床系统,包括场景语句模板100、语句模型200、关键分词要素210、其他分词要素220、主语211、谓语212、宾语213、定语221、状语222、补语223、其他分词224、主语要素模型311、谓语要素模型312、直接宾语要素模型313、间接宾语要素模型314、附语要素模型321、主语数据模型411、谓语数据模型412、宾语数据模型413、附语数据模型421、对象数据库代码生成器511、行为字典代码生成器512、补充数据库代码生成器521、对象管理后台代码生成器611、补充管理后台代码生成器621、业务管理系统代码生成器700。
在一个实施例中,所述场景语句模板100,以汉语常规格式的语句形式,把一些典型场景的业务语言经过提炼,形成模板,作为可以直接使用的业务场景,或者作为新业务场景参照的样板。所述场景语句模板100中的记录,已经在本系统中形成了完整的实现,并通过本系统生成了相应的代码,已经具备可运行的能力。所述场景语句模板100中的记录,可以进行扩展和补充,将后期实现的具备参考价值的业务场景的实现,将其“场景语句”作为模板合并到本系统的所述场景语句模板100中。每一条场景语句的模板,已经预先完成分词,并可根据其中“主语”、“谓语”、“直接宾语”、“间接宾语”的情况,快速匹配到“典型句型结构”,其数据记录主要通过主语、谓语、宾语(直接宾语、间接宾语)、定语、状语、补语、其他分词等语法要素组成。场景语句模板的数据记录,主要包括两个部分:(1)对业务场景进行描述的汉语常规格式的语句,并将其按照顺序进行分词切割。(2)对业务场景描述语句的分词,进行定性说明,尤其是其他分词要素(定语、状语、补语、其他分词)要关联到关键分词要素(主语、谓语、直接宾语、间接宾语)。具体可参考图2(典型场景语句模板),场景语句的主干,具备清晰的必要关键分词要素(主语、谓语、直接宾语、间接宾语)中的部分,以确保后续的代码生成器能够获取足够的前置条件数据。场景语句的主干,常用的典型句型结构包括:(1)“主谓”句型:<主语><谓语>;(2)“主谓宾”句型:<主语><谓语><直接宾语>;(3)“主谓直间”句型:<主语><谓语><直接宾语><间接宾语>;(4)“主谓间直”句型:<主语><谓语><间接宾语><直接宾语>。具体可参考图3(典型句型结构),场景语句模板的语句分词的排序,主要采用以下两种排序方式:(1)常规语法格式;(2)优化语法格式。常规语法格式请参见图4(银行柜台存款、取款单一业务行为场景语句分词),优化语法格式请参见图5(银行柜台业务优化场景语句模板)。常规语法格式对于机器(系统)的识别和理解存在较大难度,为了便于本系统的机器智能的理解和分析,转化成为优化语法格式后,用于本系统的后续工作环节。
在一个实施例中,所述语句模型200,由所述关键分词要素210和所述其他分词要素220组成。所述关键分词要素210可以组成“语句主干”,“语句主干”加上“其他分词要素”(附语分词要素)组成完整的语句模型,对于优化语法格式的各个分词,进行结构化的数据组织后,形成优化后的附语语句模型。所述关键分词要素210包括所述主语211、所述谓语212、所述宾语213,根据语法的进一步分解,将所述宾语213进一步拆分成为含义更加明确的“直接宾语”、“间接宾语”。主语分为:施事主语、受事主语、其他主语;谓语分为:动词谓语、名词谓语、主谓谓语、其他谓语;宾语(直接宾语、间接宾语)分为:名词性宾语、谓词性宾语、其他宾语。所述其他分词要素220(附语分词要素)包括所述定语221、所述状语222、所述补语223、所述其他分词224。定语分为:描写性定语、限制性定语、其他定语;状语分为:描写性状语、限制性状语、其他状语;补语分为:结果补语、程度补语、状态补语、趋向补语、数量补语、时间/处所补语、可能补语、其他补语。场景语句的主干,具备清晰的必要关键分词要素(主语、谓语、直接宾语、间接宾语)中的部分,以确保后续的代码生成器能够获取足够的前置条件数据。
在一个实施例中,“语句模型200”的“语句主干”,为了便于本系统的后续工作环节顺利进行,本系统将其转化成为“语句主干数据模型”。具体参见图8(银行柜台业务场景语句主干数据模型)。“语句主干数据模型”采用结构化的逻辑,描述了特定语句模型的语句主干,包含:语句主干记录ID、语句主干名称、主语要素模型(本系统内唯一名称)、谓语要素模型(本系统内唯一名称)、直接宾语要素模型(本系统内唯一名称)、间接宾语要素模型(本系统内唯一名称)等关键信息。其中的主语要素模型(本系统内唯一名称)、谓语要素模型(本系统内唯一名称)、直接宾语要素模型(本系统内唯一名称)、间接宾语要素模型(本系统内唯一名称)均指向相应的分词要素模型,在本系统内唯一确定。“语句模型200”的“语句模型”,通过“语句主干”确定了其中的关键分词要素模型的关联关系,对于“语句模型”的完整模型的描述,还需要通过“语句关键分词要素模型”进行详细描述,具体可参考图9(银行柜台业务场景语句关键分词要素模型)。“语句关键分词要素模型”采用结构化的逻辑,描述了当前语句模型的各个关键分词要素(主语、谓语、直接宾语、间接宾语)关联的各个附语(含顺序)的信息,包含:附语关联记录ID、关键分词要素类型、要素模型名称(本系统内唯一名称)、关联附语要素模型1(本系统内唯一名称)、关联附语要素模型2(本系统内唯一名称)。
在一个实施例中,关联的附语要素模型的数量,可以根据当前的语句模板、语句模型的实际情况,进行动态扩展,可以实现0~N个附语的关联。“主语要素模型311”,是对“主语211”这个分词要素所包含信息的模型。通过多个维度的数据,说明主语对象具备的特征,从而帮助用户理解主语对象,并且可以关联多个附语,用于补充说明当前场景中主语对象的补充信息。主语是语句整体陈述的对象,一般以“人”最为常见,在常见的“干什么”、“是什么”、“怎么样”的情景中,主语受谓语陈述。根据主语和谓语的关系,主语常见的类型有三种:“施事主语”、“受事主语”、“中性主语”。大多数情况下,主语由名词、代词充当。在软件设计中,主语一般都可转换为具备名词词性的数据对象。具体可参考图10(银行柜台业务主语要素模型
在一个实施例中,以典型的银行柜台存款、银行柜台取款这两个业务进行分析,根据图4(银行柜台存款、取款单一业务行为场景语句分词),对这两种业务的表述中的关键分词要素的原始顺序分别是:存款(主间谓直)、取款(主谓直间)。存款的句型结构进行简单调整,更加匹配典型句型结构的“主谓间直”(可以调整顺序成为“主谓直间”),取款的句型结构匹配典型句型结构的“主谓直间”。
在一个实施例中,图5(银行柜台业务优化场景语句模板)的信息,可以非常容易转换成为图6(银行柜台业务优化场景语句模型)。按照转换后的语句模型,已经比较契合面向对象的设计理念。语句模型中,以“主语”、“谓语”、“直接宾语”、“间接宾语”组成主干,以“附语”(“定语”、“状语”、“补语”)作为补充信息,关联到主干的关键分词要素上。
在一个实施例中,按照“附语”的概念,当前语句模型进一步转换成为图7(银行柜台业务优化场景附语语句模型)所示。
在一个实施例中,对图7的附语语句模型,形成语句主干数据模型(特定类型的数据对象),具体参见图8(银行柜台业务场景语句主干数据模型)。此过程中的关键分词要素的数据对象的名称,可以由本系统自动生成,也可以根据引导由人工进行输入指定。对图7的附语语句模型,形成对其中关键分词要素的附语关联的模型,具体参见图9(银行柜台业务场景语句关键分词要素模型)。此过程中将根据前一步骤的关键分词要素的指定,对每一个关键分词要素生成相应的分词要素模型,在该模型中指定了每个关键分词要素需要关联的附语,附语的数据对象的名称可以由本系统自动生成,也可以根据引导由人工进行输入指定。对关键分词要素(主语:
在一个实施例中,“主语数据模型411”,是对主语要素模型311建立数据模型的过程。具体可参见图18(主语数据模型
列名:描述信息的维度。
类型:该维度的信息的类型(程序设计上的类型),主要为数据库设计中的列的取值类型,常见的包括:文本、数字、整数、日期时间等等。
长度:该维度的信息的约束长度(不得超出)。
精度:主要针对数字小数点之后的精度。
主键:是否作为唯一识别码。
外键:是否作为外部引用的唯一识别码。
强制非空:是否是必填项,必须具备有意义的数据。
“谓语数据模型412”,是对谓语要素模型312建立数据模型的过程,与“主语数据模型411”的设计方法相同,同样采用列名、类型、长度、精度、主键、外键、强制非空的设计方式。具体可参见图19(谓语数据模型
在一个实施例中,对分词要素
在一个实施例中,“对象数据库代码生成器511”,“对象”是主语和宾语的主体的合并描述,本模块是根据主语数据模型411或者宾语数据模型413,按照其共同的设计(列名、类型、长度、精度、主键、外键、强制非空),遵照数据库类型对应的编程语言规范,自动生成建表脚本。具体新建的数据库表的表名、字段(列)名、字段类型、取值长度、取值精度、主键索引、非空等特性,均根据设计进行对应,在建表脚本中进行体现。其中,数据库表的表名——要素模型名称,数据库表的字段名——要素模型的列名,数据库表的字段类型——要素模型的类型,数据库表的取值长度——要素模型的长度,数据库表的取值精度——要素模型的精度,数据库表的主键索引——要素模型的主键,数据库表的非空——要素模型的强制非空;要素模型中的外键,如果按照关系型数据库的设计对应数据库表的外键(强制约束),如果按照非关系型数据库的设计,通过关联逻辑对应到另一个数据模型的主键(不强制约束)。具体可参见图26(对象数据库代码)。“行为字典代码生成器512”,“行为字典”是谓语的行为名称的字典集合,本模块是根据谓语数据模型412,按照其设计(列名、类型、长度、精度、主键、外键、强制非空),遵照数据库类型对应的编程语言规范,自动生成建表脚本。具体新建的数据库表的表名、字段(列)名、字段类型、取值长度、取值精度、主键索引、非空等特性,均根据设计进行对应,在建表脚本中进行体现。其中,数据库表的表名——要素模型名称,数据库表的字段名——要素模型的列名,数据库表的字段类型——要素模型的类型,数据库表的取值长度——要素模型的长度,数据库表的取值精度——要素模型的精度,数据库表的主键索引——要素模型的主键,数据库表的非空——要素模型的强制非空;要素模型中的外键,如果按照关系型数据库的设计对应数据库表的外键(强制约束),如果按照非关系型数据库的设计,通过关联逻辑对应到另一个数据模型的主键(不强制约束)。因为行为字典中的记录,根据业务可以分析确定,并且在后续业务管理过程中,主要以引用为主,因此本系统在此模块中生成代码的时候,可直接生成创建具体数据记录的代码。具体可参见图27(行为字典数据库代码)。“补充数据库代码生成器521”,“补充信息”是对“附语”的称谓,本模块是根据谓语数据模型412,按照其设计(列名、类型、长度、精度、主键、外键、强制非空),遵照数据库类型对应的编程语言规范,自动生成建表脚本。具体新建的数据库表的表名、字段(列)名、字段类型、取值长度、取值精度、主键索引、非空等特性,均根据设计进行对应,在建表脚本中进行体现。其中,数据库表的表名——要素模型名称,数据库表的字段名——要素模型的列名,数据库表的字段类型——要素模型的类型,数据库表的取值长度——要素模型的长度,数据库表的取值精度——要素模型的精度,数据库表的主键索引——要素模型的主键,数据库表的非空——要素模型的强制非空;要素模型中的外键,如果按照关系型数据库的设计对应数据库表的外键(强制约束),如果按照非关系型数据库的设计,通过关联逻辑对应到另一个数据模型的主键(不强制约束)。具体可参见图28(补充数据库代码)。
在一个实施例中,在分词要素数据模型(表结构)的关键信息都已经很明确的情况下,可以通过“对象数据库代码生成器511”自动生成数据库代码的建表脚本,对于主语、宾语对应的
在一个实施例中,“对象管理后台代码生成器611”,本模块是根据已经生成的“对象数据库(表)”,自动生成相应的“管理后台”的代码。主要包括以下步骤:(1)模板化界面功能特性选择:可通过模板化的界面功能特性自动生成对象的后台管理系统,也支持操作人员介入调整部分界面功能特性通过半自动方式生成对象的后台管理系统。(2)管理后台代码生成:按照前一步骤选定的功能特性,本系统可以自动生成管理后台的前端界面的代码,并且自动生成“前端界面”、“后端接口服务”,并且前端界面的代码会自动调用相应的后端接口服务,以确保相应的操作能够通过后端接口服务的代码执行,在相应的数据库表的数据操作层面得到正确实现。管理后台主要供用户完成以下功能:新增(输入新纪录的数据并提交)、删除(根据指定条件删除符合条件的记录)、修改(调阅指定记录并更新相关信息)、查询(根据制定条件查询调阅符合条件的记录)。具体可参考图29(模板化界面功能特性选择)、图30(单项管理后台代码生成前端界面)。模板化界面功能特性选择,主要包括:(1)数据项(列、字段)名称:界面交互中的名称、提示语;(2)必填(非空必填):界面交互中新建数据记录是,是否必须输入有效内容;(3)类型:界面交互中对应当前数据项(列、字段)的输入信息的类型;(4)组件:界面交互中对应当前数据项(列、字段)的输入信息的组件(比如:文本框、下拉框等等);(5)长度:组件:界面交互中对应当前数据项(列、字段)的输入、输出的组件应当支持的信息长度;(6)排序:调整界面交互中对应当前数据项(列、字段)的先后顺序;(7)显示:界面交互中对应当前数据项(列、字段)显示还是隐藏;(8)搜索条件:界面交互中的复合搜索是否包含当前数据项(列、字段)作为搜索条件;管理后台代码生成:生成的界面代码,具备对于单个目标(对象数据库表、行为字典数据库表、附语数据库表)的完整管理能力,包括“增删改查”等功能。查(查询):操作人员可以输入复合搜索的条件,从目标(数据库表)查询复合条件的数据记录,并在界面的数据表单中进行展示,如果操作人员不输入任何条件,系统将把目标(数据库表)的所有记录都作为查询结果进行展示。增(新建):操作人员可以按照界面,选择、输入系统要求的所有数据项,系统自动对所有数据的合法性进行检查确认,操作人员提交后,当前输入的数据将作为一条新增的数据记录,提交到目标数据库表中;改(修改):操作人员可选择特定数据记录,对其中的数据信息进行修改,系统自动对所有数据的合法性进行检查确认,操作人员提交后,目标(数据库表)中的相应数据记录将被新数据所覆盖更新;删(删除):操作人员选择特定数据记录,系统自动对该数据记录的关联依赖进行检查确认,操作人员确认删除提交后,目标(数据库表)中的相应数据记录将被删除。
在一个实施例中,“补充管理后台代码生成器621”,本模块是根据已经生成的“附语数据模型321”的“数据库(表)”,自动生成相应的“管理后台”的代码。本模块的实现,与“对象管理后台代码生成器611”的实现相同。主要包括以下步骤:(1)模板化界面功能特性选择:可通过模板化的界面功能特性自动生成后台管理系统,也支持操作人员介入调整部分界面功能特性通过半自动方式生成后台管理系统。(2)管理后台代码生成:按照前一步骤选定的功能特性,本系统可以自动生成管理后台的前端界面的代码,并且自动生成“前端界面”、“后端接口服务”,并且前端界面的代码会自动调用相应的后端接口服务,以确保相应的操作能够通过后端接口服务的代码执行,在相应的数据库表的数据操作层面得到正确实现。管理后台主要供用户完成以下功能:新增(输入新纪录的数据并提交)、删除(根据指定条件删除符合条件的记录)、修改(调阅指定记录并更新相关信息)、查询(根据制定条件查询调阅符合条件的记录)。具体可参考图29(模板化界面功能特性选择)、图30(单项管理后台代码生成前端界面)。
在一个实施例中,基于生成的数据库代码,在本系统连接到数据库执行相应数据库代码后,相应的数据库表即可创建完成。“对象管理后台代码生成器611”通过数据库自动查询,对符合条件的目标库表(主语、直接宾语、间接宾语的相关数据库表),自动罗列相应的字段信息,供操作人员确认或者对界面功能进行调整,下面以主语
模板设置:可以对主语
项名称:可以对主语
必填:可以对主语
类型:可以对主语
组件:可以对主语
长度:可以对主语
排序:可以对主语
显示:可以对主语
搜索条件:可以对主语
操作:可以对主语
在一个实施例中,经过前一步骤的模板设置的操作后,选择“确定”后,本系统可以自动生成管理后台的前端界面的代码,并且自动生成“前端界面”、“后端接口服务”,并且前端界面的代码会自动调用相应的后端接口服务,以确保相应的操作能够通过后端接口服务的代码执行,在相应的数据库表的数据操作层面得到正确实现。具体请参考图30(单项管理后台代码生成前端界面)。基于生成的数据库代码,鉴于谓语
在一个实施例中,“业务管理系统代码生成器700”,本模块是根据已经生成的“主语数据模型411”、“谓语数据模型412”、“宾语数据模型413”、“附语数据模型421”对应的“数据库(表)”,结合“语句模型200”对应的语句关键分词要素模型(具体请参考图9:银行柜台业务场景语句关键分词要素模型)中说明的各个分词之间的关联关系,自动生成业务操作层面的代码。主要包括以下步骤:(1)数据库表自动筛选:根据语句关键分词要素模型,结合前期各个步骤对各个分词要素模型、分词数据模型生成的数据库代码,获得对应各个分词的数据库表的对应关系,然后依次选中各个数据库表,作为下一个步骤的输入数据;(2)模板化界面交互功能特性选择:可通过模板化的界面交互功能特性自动生成后台管理系统,也支持操作人员介入调整部分界面交互功能特性通过半自动方式生成后台管理系统。(3)业务行为数据库代码生成:根据模板化界面交互功能特性选择的结果,自动生成业务管理行为数据库代码,创建业务管理行为数据库表;(4)业务管理系统代码生成:按照前一步骤选定的功能特性,本系统可以自动生成业务管理系统的前端界面的代码,并且自动生成“前端界面”、“后端接口服务”,并且前端界面的代码会自动调用相应的后端接口服务,以确保相应的操作能够通过后端接口服务的代码执行,在相应的数据库表的数据操作层面得到正确实现。管理后台主要供用户完成以下功能:新增(输入新纪录的数据并提交)、删除(根据指定条件删除符合条件的记录)、修改(调阅指定记录并更新相关信息)、查询(根据制定条件查询调阅符合条件的记录)。具体可参考图31(业务管理系统模板化界面交互功能特性选择)、图32(业务行为数据库代码生成)、图33(业务管理系统新增操作界面)、图34(业务管理系统代码生成前端界面)。数据库表自动筛选:根据当前语句模型200涉及到的各个分词要素的数据模型,自动对应到各个数据库表,并结合附语语句模型、语句关键分词要素模型,按照顺序自动选择数据库表:TZhu_Ren、TWei_CunQu、TFu_ShiJian、TFu_DiDian、TZhiBin_XianJin、TFu_ShuLiang、TJianBin_ZhangHu、TFu_FangXiang。模板化界面交互功能特性选择:主要包括:(1)数据项(列、字段)名称:界面交互中的名称、提示语;(2)必填(非空必填):界面交互中新建数据记录是,是否必须输入有效内容;(3)类型:界面交互中对应当前数据项(列、字段)的输入信息的类型;(4)组件:界面交互中对应当前数据项(列、字段)的输入信息的组件(比如:文本框、下拉框等等);(5)长度:组件:界面交互中对应当前数据项(列、字段)的输入、输出的组件应当支持的信息长度;(6)排序:调整界面交互中对应当前数据项(列、字段)的先后顺序;(7)显示:界面交互中对应当前数据项(列、字段)显示还是隐藏;(8)搜索条件:界面交互中的复合搜索是否包含当前数据项(列、字段)作为搜索条件;业务行为数据库代码生成:业务行为数据库表的数据结构,包括自身记录ID,主语信息(主语数据库表名称,主语记录ID),主语关联附语信息(主语关联附语数据库表名称,主语关联附语记录ID),谓语关联信息(谓语数据库表名称,谓语记录ID),谓语关联附语信息(谓语关联附语数据库表名称,谓语关联附语记录ID),直接宾语信息(直接宾语数据库表名称,直接宾语记录ID),直接宾语关联附语信息(直接宾语关联附语数据库表名称,直接宾语关联附语记录ID),间接宾语信息(间接宾语数据库表名称,间接宾语记录ID),间接宾语关联附语信息(间接宾语关联附语数据库表名称,间接宾语关联附语记录ID)。业务管理系统代码生成:生成的界面代码,以业务行为数据库表为主要数据对象,通过引用、关联进一步延伸,从而具备对于整组目标(主语数据库表、谓语数据库表、直接宾语数据库表、间接宾语数据表、附语数据库表)的完整管理能力,包括“增删改查”等功能。查(查询):操作人员可以输入复合搜索的条件,从目标(数据库表)查询复合条件的业务行为数据记录,并在界面的数据表单中进行展示,如果操作人员不输入任何条件,系统将把业务行为数据库表的所有记录都作为查询结果进行展示。增(新建):操作人员可以按照界面,选择、输入系统要求的所有数据项,系统自动对所有数据的合法性进行检查确认,操作人员提交后,当前输入的数据将作为一条新增的数据记录,提交到业务行为数据库表中,并根据关联的情况,自动对需要新增的延伸数据库表(主语数据库表、谓语数据库表、直接宾语数据库表、间接宾语数据表、附语数据库表)插入新增的数据信息并建立正确的关联关系;改(修改):操作人员可选择特定数据记录,对其中的数据信息进行修改,系统自动对所有数据的合法性进行检查确认,操作人员提交后,目标(数据库表)中的相应数据记录将被新数据所覆盖更新;删(删除):操作人员选择特定数据记录,系统自动对该数据记录的关联依赖进行检查确认,操作人员确认删除提交后,目标(业务行为数据库表)中的相应数据记录将被删除,延伸数据库表(主语数据库表、谓语数据库表、直接宾语数据库表、间接宾语数据表、附语数据库表)中的数据记录,原则上不做删除,因为存在多个业务行为记录引用同一条延伸数据库记录的情况。
在一个实施例中,“业务管理系统”的主要操作行为包括“增删改查”(新增、删除、修改、查询),通过这些操作,即可完成所有业务管理行为。基于生成的主语、直接宾语、间接宾语、附语的数据库表,通过“对象管理后台”、“补充管理后台”对于需要预先录入的数据记录进行管理,从而供“业务管理系统”在运行的时候,可以通过引用的方式使用其中的数据记录。在本实施例中,
在一个实施例中,“业务管理系统代码生成器700”将根据当前已经形成的语句主干、关键分词、其他分词的数据模型,以及“对象数据库代码生成器”、“对象管理后台代码生成器”、“行为字典代码生成器”、“补充数据库代码生成器”、“补充管理后台代码生成器”生成的代码,自动生成“业务管理系统”的代码,实现业务管理中的增删改查(新增、删除、修改、查询)的管理行为。具体可参考图31(业务管理系统模板化界面交互功能特性选择)、图32(业务行为数据库代码生成)、图33(业务管理系统新增操作界面)、图34(业务管理系统代码生成前端界面)。“新增”操作一般在“业务管理系统查询表单界面”(可参考:图34业务管理系统代码生成前端界面)中,点击“新建”按钮进行操作。基于生成的附语的数据库表,
综上所述,借助于本发明的上述技术方案:
1、通过自然语言为主要输入,确定软件系统的业务场景需求,并确定相关语句模板、语句模型、分词要素模型、数据模型。
2、通过语句模板、语句模型、关键分词要素、其他分词要素、语句主干数据模型等等体系化设计,将场景描述语言自动分解、梳理成为可被机器系统理解的数据模型。
3、基于数据模型,通过数据库代码生成器,生成数据库代码,进一步创建数据库表并完成相关数据记录的初始化。
4、通过单项管理后台代码生成器(对象管理后台代码生成器、补充管理后台代码生成器),完成对单一项目(对应单一分词要素)的单项管理的软件系统代码的自动生成。
5、以单项管理后台代码生成器(对象管理后台代码生成器、补充管理后台代码生成器)为基础,通过联合管理代码生成器(业务管理系统代码生成器),完成上层业务应用的软件系统代码的自动生成。
在本发明中,除非另有明确的规定和限定,术语“安装”、“设置”、“连接”、“固定”、“旋接”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于自然语言模型的码床系统
- 一种基于自然语言模型与目标检测算法结合的输电线路特定故障识别系统