一种基于自注意力蒸馏的弱监督文字检测方法
文献发布时间:2023-06-19 10:00:31
技术领域
本发明涉及计算机文字识别技术,具体涉及一种基于自注意力蒸馏的弱监督文字检测方法。
背景技术
场景文字识别(Scene Text Recognition,STR)的应用非常广泛,包括图片文字实时翻译、自动表格数据读取、盲人辅助导航、自助旅游翻译、地理位置信息服务、智能交通系统、无人驾驶汽车、工业自动化等。完整的STR流程通常包括文字检测与文字识别两个步骤,文字检测的任务是找出图片中文字区域并标记相应边界框。从某种意义上说,文字检测比文字识别更重要,如果对文字定位有偏差,就无法从场景图片中正确识别文本。
目前,基于深度学习的方法正成为场景文字检测的主流,而大量精确标注的样本是此类方法取得成功的关键。由于对大规模真实文字场景数据集进行标注是一项极其费时费力的工作,绝大多数检测方法使用人工合成数据集进行模型预训练。然而,该数据集主要将大量的单词实例经过简单变换后嵌入到自然场景图片中,不足以代表自然场景中纷繁多变的文字,训练出来的模型泛化性能有待提高。
也有研究人员提出使用弱监督学习进行文字检测,利用现有标准数据集中大量的单词级标签来生成字符级伪标签,然后训练字符分割模型以及字符间区域分割模型,最后得到文字区域。然而,这类方法需要复杂的后处理过程,并存在文字漏检的情况。
目前弱监督学习在通用目标检测应用中应用较多,只需使用图像级标注样本而无需包含物体的矩形框标签便可训练检测器来定位图像中的目标。然而与一般的物体相比,文字具有许多独有特点,比如呈现出较大宽高比、无明显闭合边缘轮廓、字符之间有间隔等,基于弱监督学习的通用检测网络并不能直接用于定位文字。
因此综上所述,如何在较小的标注成本情况下进行有效的文字检测是当前亟需解决的技术难题。
发明内容
发明目的:本发明的目的在于解决现有技术中存在的不足,提供一种基于自注意力蒸馏的弱监督文字检测方法,本发明在只给定有无文字(含文字计数,相当于图像级监督信息)的图片样本情况下,利用弱监督学习训练文字检测器,同时利用自注意力蒸馏SAD来提高弱监督条件下文字检测的精确度。
技术方案:本发明的一种基于自注意力蒸馏的弱监督文字检测方法,包括图片分类和图片检测,具体如下:
获取图片样本,并将图片样本中的含文字图片和不含文字图片分别标记为正负样本;对于获取后的正负样本采用VGGNet网络作为主干网络训练为基于弱监督的文字分类网络;
通过训练好的文字分类网络对待检测图片的输出信息进行筛选,筛选出包含有文字的文字候选区,然后根据文字候选区生成伪标注来训练文字检测网络,并通过自注意力蒸馏法SAD提高文字检测网络检测文字精度,减少背景噪声。
本发明使用基于激活函数的注意力特征图,即把长、宽、通道三维特征转换为长、宽两维特征,通过考虑各通道上激活后的特征值,来确定空间上特征的分布状况。其中通过注意力生成模块AGM先把网络中的指定特征输入AGM得到注意力热图,再上采样到目标大小,最后通过softmax处理。整个过程中,自注意力蒸馏法SAD只在训练阶段使用,不会给具体检测过程带来计算成本。
进一步的,训练文字分类网络时,在VGGNet网络结构中的高层卷积层使用层次Inception模块(支持不同长度的感受野,实现对文字大小的鲁棒性),使其前后层的特征图分别进行下采样和上采样然后相结合生成F
进一步的,使用训练好的文字分类网络对待检测图片进行分类,即进行像素级判别,判断图片中是否含有文字(如果含有文字,就给出文字的概率和位置修正信息),并生成包含文字部分像素的概率热图;正样本中包括有文字计数。
进一步的,对待检测图片进行文字检测时,包括以下步骤:
(1)使用Edge Boxes法为输入的待检测图片生成一组候选区,将所有候选区输入到训练好的分类网络中计算其对比度分值CS,并根据对比度分值CS的大小进行排序:
其中,
生成掩膜图像
(2)使用CNN提取候选区特征来训练新的文字检测网络,该文字检测网络有两个输出分支;一个输出分支计算输入的待检测图片为文字图像的概率,另一个分支输出对文字窗口回归的坐标偏移;
在多任务检测器训练过程中,使用多任务损失函数,定义为L
其中L
训练文字检测网络时在各迭代时间点均可以通过注意力生成模块AGM使用自注意力蒸馏SAD进行迭代求精,使低层注意力热图可以从高层注意力热图获取有用的上下文信息;
上述迭代过程中,对应损失如下:
其中,M
使用自注意力蒸馏SAD后,训练文字检测网络的总损失函数为:
L=L
L
进一步的,所述注意力生成模块AGM可适配分类和检测网络特征差异,其具体过程为:
令输入注意力生成模块AGM的特征图为
首先,对F沿通道使用平均池化,设F
然后,对M
最后,将非线性热图与M
进一步的,训练文字检测网络时将文字计数信息作为图像级监督信息中的一种,并在训练时先选择若干较大分数值的候选框,然后执行基于计数的区域选择算法CRS来得出最合适的候选框作为正训练样本调节文字检测网络。
有益效果:与现有技术相比,本发明的优势在于:使用“有无文字+文字计数 (如有文字)”的图像级标注样本,这种方式极大地提高了标注时间,同时弱监督信息很容易用来训练检测器。使用自注意力蒸馏,减小二步检测器中候选区内背景噪声以及图像中与文字具有相似模式对检测的影响,提高文字定位精度。图 6给出了使用CRS以及SAD机制进行文字检测的效果。
附图说明
图1为本发明实施例中弱监督分类网络判定示意图;
图2为本发明实施例中分类网络计算CS值流程图;
图3为本发明实施例中训练文字检测网络示意图;
图4为本发明实施例中注意力生成模块AGM输入输出示意图;
图5为本发明实施例中确定文字过程示意图;
图6为本发明实施例中文字检测对比示意图;
图7为本发明的整体流程示意图;
其中,图6(a)为无CRS和SAD机制结果,图6(b)为CRS+SAD迭代30K结果,图6(c)为CRS+SAD迭代40K结果,图6(d)为CRS+SAD迭代50K结果。
具体实施方式
下面对本发明技术方案进行详细说明,但是本发明的保护范围不局限于所述实施例。
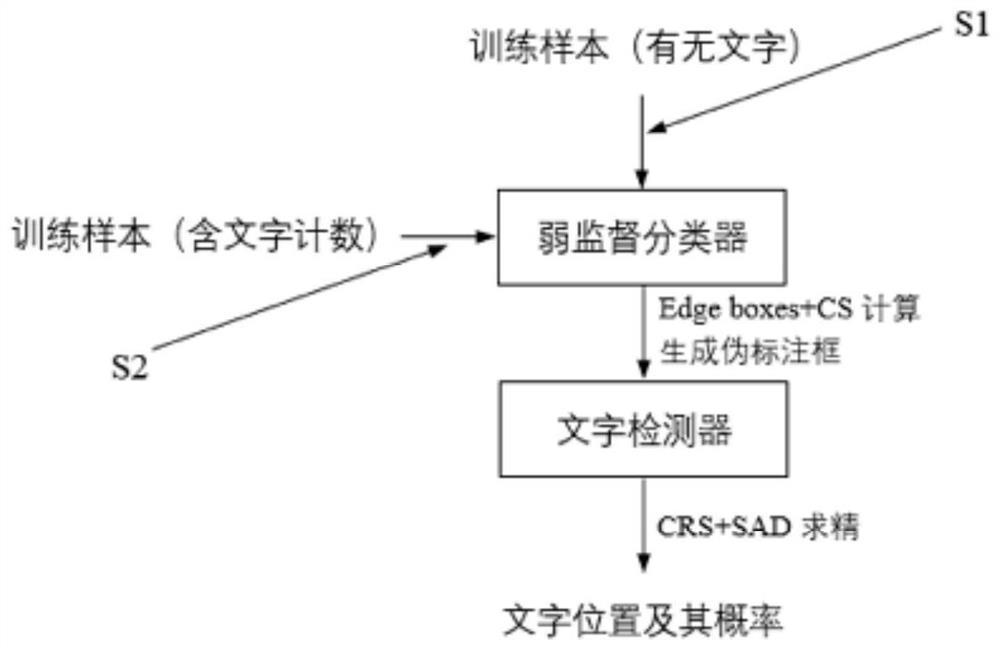
如图7所示,本实施例的一种基于自注意力蒸馏的弱监督文字检测方法,包括图片分类和图片检测,具体步骤如下:
步骤S1:获取图片样本,并将图片样本中的含文字图片和不含文字图片分别标记为正负样本;对于获取后的正负样本采用VGGNet网络作为主干网络训练为基于弱监督的文字分类网络。
训练文字分类网络时,在VGGNet网络结构中的高层卷积层使用层次Inception 模块,使其前后层的特征图分别进行下采样和上采样然后相结合生成F
使用训练好后文字分类网络对待检测图片进行分类,即进行像素级判别,判断图片中是否含有文字,并生成包含文字部分像素的概率热图;正样本中包括有文字计数。
步骤S2:通过训练好的文字分类网络对待检测图片的输出信息进行筛选,筛选出包含有文字的文字候选区,然后根据文字候选区生成伪标注来训练文字检测网络,并通过自注意力蒸馏法提高文字检测网络检测文字精度。具体包括以下步骤:
(1)使用Edge Boxes法为输入的待检测图片生成一组候选区,将所有候选区输入到训练好的分类网络中计算其对比度分值CS,并根据对比度分值CS的大小进行排序:
其中,
生成掩膜图像
(2)使用CNN提取候选区特征来训练新的文字检测网络,该文字检测网络有两个输出分支;一个输出分支计算输入的待检测图片为文字图像的概率,另一个分支输出对文字窗口回归的坐标偏移。
实施例1:本实施例中采用搜索引擎(如百度,腾讯,谷歌,Wikipedia,Flickr 等)中的图片作为数据源。
一、文字分类
先将数据源中的样本图片为:含文字图片与不含文字图片(文本和非文本),并将这两种图片分别标记为正样本和负样本。然后,采用VGG网络作为主干网络训练对应的基于弱监督的文字分类网络(如图1所示)。本实施例中,采用 VGG16网络。
由于传统CNN低层特征图表示图像的局部细节,高层特征图刻画图像的语义信息。因此本实施例中训练文字分类网络时,在高层卷积层使使用Inception模块,同时利用多层特征图有利于表现不同大小的文字特性。本实施例的卷积层,分别使用1×1卷积,3×3空洞卷积,3×3最大池化以及5×5空洞卷积操作生成 Inception特征;以某层特征图为标准,将其前后层的特征图分别进行下采样和上采样然后相结合生成F
二、文字检测
对于给定输入图像先在已训练好的文字分类网络上选定一系列文字候选区,然后根据对应候选区来生成伪标记以训练文字检测器,使用文字检测器进行检测推断时,首先计算所有候选区的文字分数,然后对其排序,使用NMS消除重复检测的文字。本阶段分为以下两个步骤:
(1)本实施例使用Edge Boxes法为输入图像生成一组文字候选区,将所有文字候选区输入到训练好的文字分类网络中计算其对比度分值CS,定义为
其中,
上述过程如图2所示,其中如果
本实施例中,除对每个训练的图片样本标注是否含有文字以外,将含有文字的图片样本中的文字计数信息也作为图像级的监督信息来训练检测器,能够极大提高文字检测精度。如图5所示,在训练时先选择若干最大分的候选框,然后执行基于计数的区域选择算法(Count-based region selection,CRS)来得出最合适的候选框作为正训练样本调节网络。这样能够有效避免遇到靠得很近的多个文字图片而被误识别为一个文字的风险。
(2)本实施例使用对应CNN来提取候选区特征进而训练文字检测网络。
该文字检测网络有两个输出分支。一个输出分支计算输入图像是文字图像的概率,另一个输出分支输出对文字窗口回归的坐标偏移。
在多任务检测器训练过程中,使用多任务损失函数,定义为L
本实施例在上述文字检测网络结合自注意力蒸馏SAD,使得低层注意力热图可从高层注意力热图获取有用的上下文信息,从而使得低层特征不再局限于捕捉文字局部特性。在整个训练过程的不同时间点引入SAD,可以不断改善注意力热图的表征能力,减小候选区内背景噪声以及图像中与文字具有相似模式对检测的影响,一旦训练收敛,文字检测网络可生成更具表现力的注意力热图,从而完成更精确的文字定位。
如图6所示,本实施例中在最终做文字检测时,图6(a)为不使用CRS和 SAD法的现有常规技术的检测结果,图6(b)至图6(d)依次为使用本发明方法(结合CRS和SAD)但迭代次数不同情况下的检测结果。通过该对比图可以明显看出,本发明的文字检测精度更高,并且本发明的层间自注意力蒸馏法能够通过迭代训练来提高文字检测器精度。
如图3所示,本实施例选择若干CS较大的候选框及对应负样本作为伪标签训练文字检测网络,通过SAD进行迭代求精。图3中上方的虚线框中内为自注意力蒸馏SAD,其对应损失定义如下:
其中M
训练文字检测网络的总损失函数为:L=L
如图3所示,为使训练过程中能够精确定位文字区域,图中下方虚线框内使用有注意力生成模块AGM。
注意力生成模块AGM的具体原理如图4所示,令输入注意力生成模块AGM 的特征图为
首先,对F沿通道使用平均池化,设F
上述注意力生成模块AGM能够方便接入到任何卷积层,然后利用上采样和下采样将相邻层不同大小的M
- 一种基于自注意力蒸馏的弱监督文字检测方法
- 一种基于弱监督学习的字符级场景文字检测方法和装置