一种基于深度学习的增强CT图像质量和分辨率的方法
文献发布时间:2023-06-19 10:03:37
技术领域
本发明涉及图像处理技术领域,具体地涉及一种基于深度学习的增强CT图像质量和分辨率的方法。
背景技术
计算机断层扫描(CT)是现代医院和诊所最重要的成像和诊断方式之一。为了在扫描过程中直接获取高质量、高分辨率的CT影像,就需要提高扫描设备的成本以及增大扫描过程中的辐射剂量。然而,根据相关研究,CT扫描过程中的X射线可能导致遗传损伤,并在与辐射剂量相关的概率上诱发癌症。因此,为在提高CT影像质量和分辨率的同时避免或减少患者在进行扫描过程中损害健康的风险,需要通过将含有大量噪声和低分辨率的临床CT数据通过重建获得低噪、高分辨率的高质量影像。
关于CT去噪图像增强的方法一般分为三类:(A)重建前的正弦图过滤,(B)重建后的迭代重建和(C)重建后的图像后处理。然而,(A)方法中的正弦图数据极少直接提供给用户,而且该方法可能会受到分辨率损失和边缘模糊的影响。虽然(B)方法极大提高了图像质量,但它们需要很高的计算成本,而且其结果仍然可能失去一些细节并受到剩余伪影的影响。在基于深度学习的图像后处理之前,曾有很多后处理方法被提出,如针对CT去噪的NLM和K-SVD方法,以及BM3D算法,但是由于CT噪声分布不均匀的特点,它们都会出现过度平滑的缺陷。最近深度卷积网络在CT去噪的探索颇有成果,但由于仅使用像素级别的MSE损失进行端到端的训练,其结果不可避免地会忽略了对人类感知至关重要的微妙图像纹理从而导致过平滑的边缘和细节的丢失。
CT超分辨的方法一般分为两类:(A)基于模型重建的方法,(B)基于学习的方法。其中,第一类方法显式建模图像退化过程并进行正则化,根据投影的特点进行重建数据,其效果依赖于所假设模型的准确性。而基于学习的方法同样也会面临损失图像细节和产生块状瑕疵的问题。
在上述的CT增强以及超分辨任务中,其深度学习的方法常使用仿真数据集进行训练和评估,往往无法体现应用于真实临床数据的性能,特别是对于超分辨任务,临床数据的超分辨倍数具有不固定的特点,区别于深度学习数据集中的固定倍数。可见,目前CT图像进行去噪的图像增强任务和超分辨任务还不能获得高质量及真实细节的图像。
发明内容
本发明目的是为了解决现有技术对图像去噪及实现超分辨处理后图像细节损失的问题,提出一种基于深度学习的增强CT图像质量和分辨率的方法。
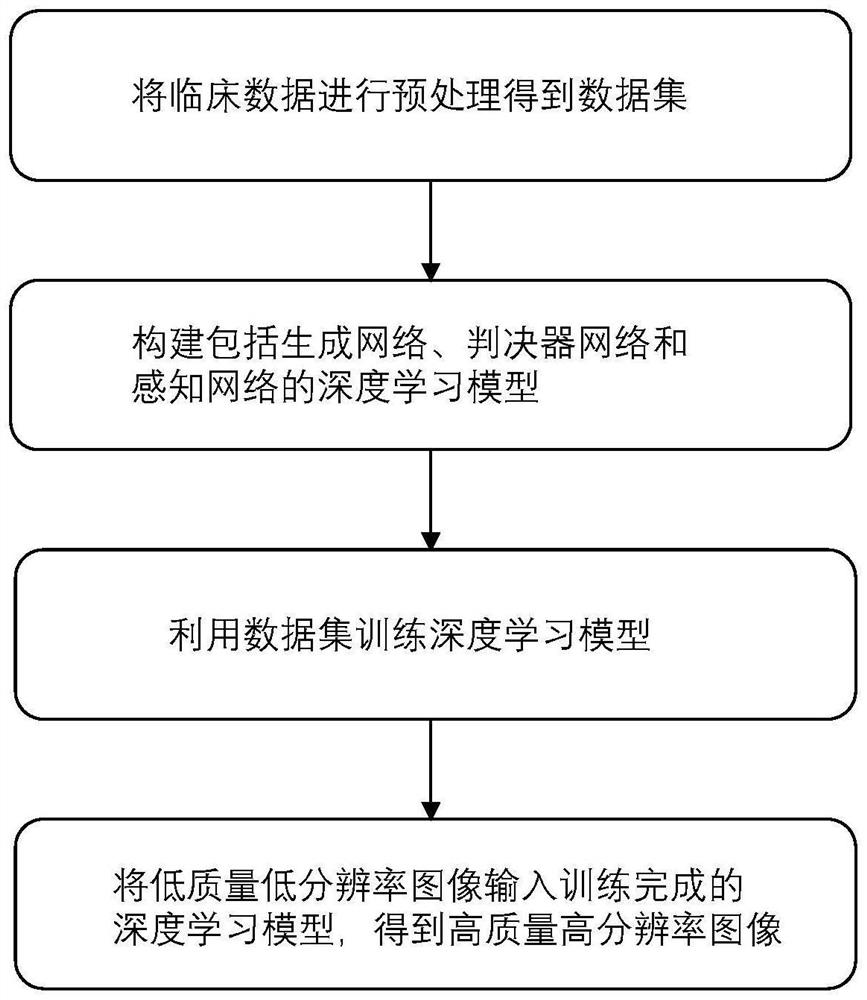
本发明提出的一种基于深度学习的增强CT图像质量和分辨率的方法,包括以下步骤:S1、将采集的临床数据进行预处理得到数据集;S2、构建包括生成网络、判决器网络和感知网络的深度学习模型;S3、构建损失函数;S4、利用数据集和损失函数更新迭代生成网络的参数,得到训练完成的深度学习模型;S5、将低质量低分辨率图像输入训练完成的深度学习模型,得到高质量高分辨率图像。
优选地,步骤S1中对临床数据进行预处理的过程包括以下步骤:S11、获取低辐射剂量低分辨率下的低质量CT图像和正常辐射剂量高分辨率下的高质量CT图像;S12、根据医学图像的元数据对低质量CT图像进行裁剪,使裁剪后的低质量CT图像与高质量CT图像的物理空间信息对应,得到相同物理空间信息的数据对;S13、将所述数据对裁剪为小块数据对,并进行阈值判定,保留满足阈值判定条件的小块数据对;S14、对保留的小块数据对进行像素截取和归一化处理;S15、对步骤S14中处理后的小块数据对进行数据扩充得到用于训练所述深度学习模型的数据集。
优选地,步骤S13中将所述数据块裁剪为小块数据对的方法包括以下内容:数据块中高质量CT图像每隔固定像素点/层数进行裁剪,低质量CT图像将与高质量CT图像对应个数的像素点/层数进行放缩以与高质量CT图像物理空间的信息对应。
优选地,步骤S13中所述阈值判定条件为:小块数据对中的高质量CT图像和放缩后的低质量CT图像的相似度指标高于阈值。
优选地,步骤S15中进行数据扩充的方法为对图像进行翻转和旋转。
优选地,所述损失函数为平均绝对误差损失、感知损失和生成对抗损失的组合损失函数。
优选地,所述感知损失为生成网络输出结果和真实的高质量CT图像分别输入感知网络后并将输出结果进行MSE损失的计算结果。
优选地,所述生成对抗损失为GAN损失,WGAN损失、WGAN-GP损失或rGAN损失中的一种。
优选地,所述生成网络包括特征提取模块和上采样模块,所述特征提取模块包括一个卷积层、级联卷积块、之后再经过一个卷积层,最终由低质量CT图像获得低分辨率特征图;所述级联卷积块中每个卷积块包括两个3*3*64的卷积层和中间的ReLU层;所述上采样模块包括一个全连接网络和一个卷积层,将输入的高质量CT图像的每个像素位置信息输入全连接网络,将输出结果作用到低分辨率特征图,得到高质量高分辨率图。
优选地,采用Adam优化器对生成网络和判决器网络进行优化。
本发明的有益效果包括:本发明基于深度学习构建深度学习模型,将临床数据进行预处理获得数据集,可以减少不同时间采集的数据由于病人位移或其他原因在空间中产生错位的影响;通过结合损失函数的深度学习模型可实现提升CT图像质量和超分辨两个任务端到端处理直接得到最终结果。进一步的有益效果还包括利用生成网络中的上采样模块,实现了任意尺度的上采样任务。
附图说明
图1是本发明一种基于深度学习的增强CT图像质量和分辨率的方法的主要步骤流程图。
图2是本发明实施例中临床数据进行预处理的流程图。
图3是本发明实施例中深度学习模型中生成网络的结构示意图。
具体实施方式
下面结合具体实施方式并对照附图对本发明作进一步详细说明。应该强调的是,下述说明仅仅是示例性的,而不是为了限制本发明的范围及其应用。
参照以下附图,将描述非限制性和非排他性的实施例,其中相同的附图标记表示相同的部件,除非另外特别说明。
实施例1
如图1所示,本实施例提出一种基于深度学习的增强CT图像质量和分辨率的方法,主要包括以下步骤:
S1、将采集的临床数据进行预处理得到数据集。
S2、构建包括生成网络、判决器网络和感知网络的深度学习模型。
S3、构建损失函数。
S4、利用数据集和损失函数更新迭代生成网络的参数,得到训练完成的深度学习模型。
S5、将低质量低分辨率图像输入训练完成的深度学习模型,得到高质量高分辨率图像。
具体地,步骤S1中对临床数据进行预处理的过程包括以下内容:
S11、获取低辐射剂量低分辨率下的低质量CT图像和正常辐射剂量高分辨率下的高质量CT图像。
短时间内接连获取低辐射剂量、低分辨率的全局CT图像(简称为低质量CT图像)和正常辐射剂量、高分辨率CT图像(简称为高质量CT图像),即设置不同扫描参数快速扫描两次。为了减少病人受到辐射的时间,高质量CT图像无须为全局图像,可以是物理内容包含于低质量CT图像的局部影像。(例如:低质量的全肺CT图像和高质量的局部肺部CT图像)。为了保证可以看到明显的分辨率差异,可将分辨率倍数要求在三倍以上。
S12、根据医学图像的元数据对低质量CT图像进行裁剪,使裁剪后的低质量CT图像与高质量CT图像的物理空间信息对应,得到相同物理空间的数据对。
根据医学CT图像(通常为DICOM类型)的包含空间物理量信息的元数据对低质量CT图像进行裁剪,使其与(局部)高质量CT图像的物理空间信息对应,得到相同物理空间信息的数据对。其中,元数据包括PixelSpacing(像素间距),SpacingBetweenSlices(切片间距),ImagePositionPatients(病人坐标位置),ImageOrientationPatients(病人坐标朝向)等指标。
S13、将所述数据对裁剪为小块数据对,并进行阈值判定,保留满足阈值判定条件的小块数据对。
同步地遍历每对具有相同物理空间信息的数据对,对每对数据对进行裁剪获得小块数据对(对于高分辨率数据来说,可每隔固定像素点/层数进行裁剪,比如48像素/2层裁剪一个96*96*3的小块,低分辨率数据需要将对应的像素数或层数放缩以寻求与高分辨率数据物理空间的对应)。对裁剪出的小块数据对(patch)进行阈值判定,判定条件为:若小块数据对中的高质量图像小块和放缩后的低质量图像小块的相似度指标(PSNR以及SSIM)高于某一数值(阈值),则将符合阈值的小块数据对保留,否则将其丢弃,该阈值根据超分辨倍数以及辐射量差异具体确定。
S14、对保留的小块数据对进行像素截取和归一化处理。
对保留下来的小块数据对进行像素数值截取和归一化处理,像素值截取是为了避免小块像素分布过于稀疏,归一化是为了方便后级神经网络训练(例如,若像素数值代表的是CT值,且图像为肺部CT图像,可将阈值设定为1500;归一化即为将[-1024,1500]的像素数值线性映射到[-1,1]之间)。
S15、对步骤S14中处理后的小块数据对进行数据扩充得到用于训练所述深度学习模型的数据集。可通过图像翻转和旋转等方式进行数据扩充。
本发明的构思为,在训练深度学习模型时,深度学习模型的输入为低质量图像小块数据组成的成批数据,期望得到的输出要尽量与高质量图像小块数据组成的成批数据相同。在训练结束后,获得的深度学习模型可将输入的低质量、低分辨率的CT图像输出为高质量、高分辨率的CT图像。
在本实施例中,深度学习模型包括生成网络、判决器网络和感知网络。其中,生成网络包括以下内容:
(a)特征提取模块:由一个卷积层进行初步的特征提取(本实施例采用64个3*3大小,步长为1的卷积核得到64层特征),再由级联的基础卷积块以及最后的一层卷积层组成主要计算单元(本实施例中设置为16个基础卷积块级联,每个基础块包括两个3*3*64的卷积层和中间的ReLU层),最终由低质量CT图像获得低分辨率特征图,主要计算单元的结果与初步特征提取的结果相加形成残差结构,上述即为生成网络的特征提取模块。
(b)上采样模块:为了实现对任意尺寸的超分辨,上采样模块可以学习对应不同因子上采样的卷积核数量及权重参重:上采样模块由一个全连接网络(可由256节点全连接层+ReLU+256节点全连接层组成)和一个对应卷积层组成,其中全连接网络的输入是高分辨率图像的像素位置信息(高分辨率图像的像素位置信息指:高分辨率图像中每个像素坐标对应的低分辨率图像相应像素坐标的取整值和每个像素坐标对应的低分辨率图像相应像素坐标的实际值之间的相对偏移量)和尺度因子,输出与高分辨率图像素数量相同数量的滤波器核。上采样模块的实现流程为:对于高分辨率图像中的每个像素,将其位置信息输入到上述全连接网络中得到滤波器核,之后将输出的每个滤波器核作用到低分辨率特征图(计算单元的结果)的对应位置后(对应位置为:高分辨率图像像素位置映射到低分辨率特征图的相应位置),可以得到高分辨率图像中相应的像素数值,通过遍历高分辨图像中的所有像素位置,即可获得高分辨率图像。
判决器网络用于和生成网络部分构成GAN结构以提高训练质量,使得生成网络输出的结果细节更丰富真实。判决器网络其部分可使用多种二分类网络结构。实验中可设置如下结构:由卷积核,批归一化层和ReLU层构成基本单元,将七个基本单元级联构成特征提取部分。其中,每隔一个基本单元,之后的基本单元中的卷积步长调整为2,卷积核数量增加一倍。特征提取部分结束后为分类模块,该模块由1024节点的全连接层+ReLU+全连接层得到一个数值结果,其表征对输入图像为高质量、高分辨图像的概率大小。感知网络部分可采用VGG16网络或VGG19网络。
具体地,在步骤S4中训练深度学习模型,训练时使用的损失函数为平均绝对误差损失、感知损失和生成对抗损失的组合损失函数。其中,感知损失为生成网络输出结果和真实的高质量CT图像分别输入感知网络后并将输出结果进行MSE损失计算的结果。生成对抗损失为GAN损失,WGAN损失,WGAN-GP损失或rGAN损失中的一种。优化器采用Adam优化器对生成网络和判决器网络进行优化。
更为详细地深度学习模型训练过程为:
(1)将同一批次数据集中的低质量图像小块数据送入生成网络部分,其中设定一批次为16个小块数据对。
(2)将(1)得到的超分辨结果与同一批次数据集中的高质量图像小块数据进行对比,计算得到平均绝对误差损失。
(3)将(1)得到的超分辨结果与同一批次数据集中的高质量图像小块数据送入感知网络,得到感知网络相应的输出特征图,通过对特征图计算平均绝对误差损失,得到感知损失。
(4)将(1)得到的超分辨结果与同一批次数据集中的高质量图像小块数据送入判决器网络,得到判决器网络相应的输出值(该输出数值代表的含义是:判决其网络认定该输入为高质量图像的概率),通过计算相应的GAN损失(GAN损失可以是基础GAN损失或是WGAN-GP损失或是rGAN损失等)中的生成器损失,得到生成对抗损失。
(5)固定判决器网络和感知网络的参数,根据平均绝对误差损失、感知损失和GAN损失(即生成对抗损失)中的生成损失部分,通过Adam优化器对生成网络中的参数进行更新;
(6)将(1)得到的超分辨结果与同一批次数据集中的高质量图像小块数据送入判决器网络中,得到判决器网络相应的输出值,通过计算得到相应的GAN损失(GAN损失可以是基础GAN损失或是WGAN-GP损失或是rGAN损失等)中的判决器损失。固定生成器网络和感知网络的参数,使用判决器损失,通过Adam优化器对判决器网络进行优化。
(7)重复(1)—(6)直到平均绝对误差损失和感知损失收敛,完成训练。
实施例2
与实施例1不同的是,本实施例将采集的临床数据进行预处理得到数据集的预处理方式为,将低质量CT图像采用三维插值法获得与高质量CT图像相同的尺寸,裁剪后得到小块数据对。
生成网络可以但不限于采用U-Net结构,判决器可以为但不限于Patch GAN,采用Patch GAN可兼顾图像不同部分的影响,解决了一个输入仅有一个对应的输出所带来的输出图像不精确的问题。
不同于现有技术中使用仿真训练集,本发明通过对真实临床数据进行预处理得到真实的训练数据集,使得深度学习模型可以应用到临床实践中。本发明深度学习模型通过使用生成对抗网络的框架,结合感知损失与像素级别的损失可以端到端的实现将不具备临床使用价值的低辐射低分辨率的医学图像优化为高质量、高分辨率的医学图像,同时使得低辐射CT图像去噪和低分辨率CT图像超分辨任务可以同时实现,使得生成的高质量图像具有真实的细节内容。本发明提出的深度学习模型通过更换数据集也可用于其他图像增强任务,如自然图像的去噪或超分辨。更优的实施例中,通过引入任意尺度因子的上采样模块,实现了对任意尺度因子的超分辨实现。
本领域技术人员将认识到,对以上描述做出众多变通是可能的,所以实施例和附图仅是用来描述一个或多个特定实施方式。
尽管已经描述和叙述了被看作本发明的示范实施例,本领域技术人员将会明白,可以对其做出各种改变和替换,而不会脱离本发明的精神。另外,可以做出许多修改以将特定情况适配到本发明的教义,而不会脱离在此描述的本发明中心概念。所以,本发明不受限于在此披露的特定实施例,但本发明可能还包括属于本发明范围的所有实施例及其等同物。
- 一种基于深度学习的增强CT图像质量和分辨率的方法
- 一种基于KLT技术的超分辨率重建图像质量评价方法