一种公告文档表格数据识别方法及终端
文献发布时间:2023-06-19 10:05:17
技术领域
本发明涉及数据处理识别技术领域,尤其涉及一种公告文档表格数据识别方法及终端。
背景技术
上市公司的业绩、财报和其他重要事件公告的跟踪与监控是金融机构进行风险评估的重要手段,公司公告一般是以PDF文档的形式发布,其中,一些重要数据往往是以表格的形式展示,因此,从公司公告的PDF文档中自动抽取重要数据表格进行分析将有助于提高金融机构的风险评估效率。
PDF文档是一种跨平台的可携带文档格式,PDF文档格式以输出排版整齐美观为目标,其中的文本数据并非是以段落或文字的形式进行存储,而是以记录页面特定位置信息的字符的形式进行存储,因此,从PDF文档中自动抽取表格是一件很困难的事情。
发明内容
本发明所要解决的技术问题是:提供一种公告文档表格数据识别方法及终端,能实现准确地自动识别表格。
为了解决上述技术问题,本发明采用的技术方案为:
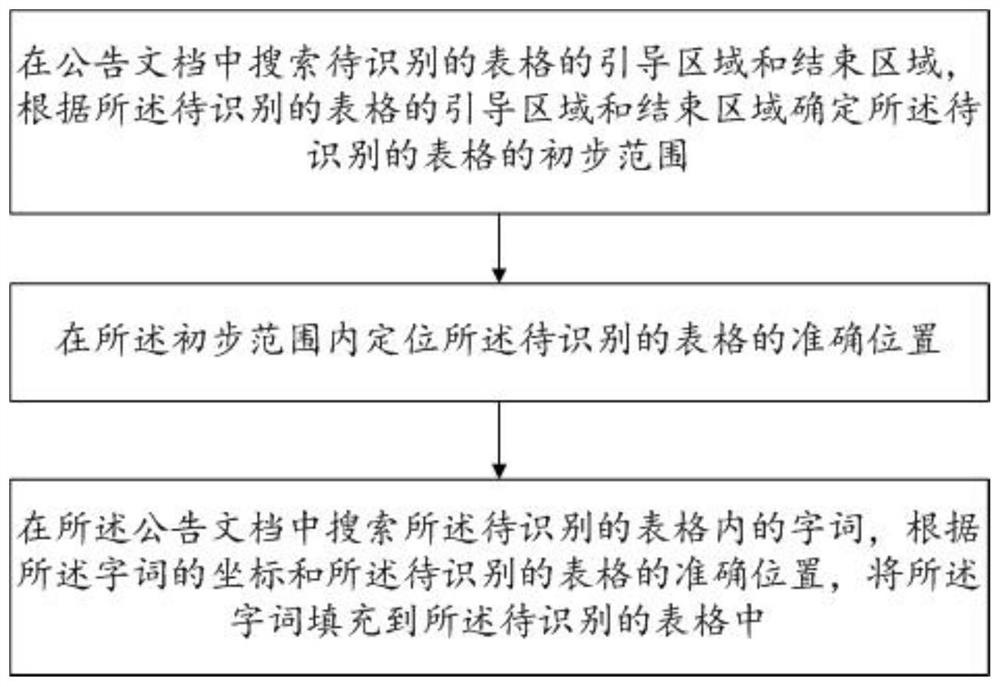
一种公告文档表格数据识别方法,包括步骤:
在公告文档中搜索待识别的表格的引导区域和结束区域,根据所述待识别的表格的引导区域和结束区域确定所述待识别的表格的初步范围;
在所述初步范围内定位所述待识别的表格的准确位置;
在所述公告文档中搜索所述待识别的表格内的字词,根据所述字词的坐标和所述待识别的表格的准确位置,将所述字词填充到所述待识别的表格中。
为了解决上述技术问题,本发明采用的另一种技术方案为:
一种公告文档表格数据识别终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的方法。
本发明的有益效果在于:在公告文档中搜索待识别的表格的引导区域和结束区域,根据待识别表格的引导区域和结束区域确定表格的初步范围,在初步范围内定位表格的准确位置,能够实现找到表格的初步范围后再定位表格的具体位置,从而准确定位表格,在公告文档中搜索待识别表格内的字词,根据字词的坐标和待识别表格的准确位置,将字词填充到待识别表格中;现有技术中通常是直接通过线段和字符的坐标关系识别表格,本发明先对表格的引导区域和结束区域进行定位,再定位表格的位置,能够提高定位表格位置的准确率,通过词的坐标和表格准确位置,对表格进行数据填充,能够准确地解析出表格的内容。
附图说明
图1为本发明实施例的一种公告文档表格数据识别方法的流程图;
图2为本发明实施例的一种公告文档表格数据识别终端的示意图;
标号说明:
1、一种公告文档表格数据识别终端;2、存储器;3、处理器。
具体实施方式
为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
请参照图1,本发明实施例提供了一种公告文档表格数据识别方法,包括步骤:
在公告文档中搜索待识别的表格的引导区域和结束区域,根据所述待识别的表格的引导区域和结束区域确定所述待识别的表格的初步范围;
在所述初步范围内定位所述待识别的表格的准确位置;
在所述公告文档中搜索所述待识别的表格内的字词,根据所述字词的坐标和所述待识别的表格的准确位置,将所述字词填充到所述待识别的表格中。
从上述描述可知,本发明的有益效果在于:在公告文档中搜索待识别表格的引导区域和结束区域,根据待识别表格的引导区域和结束区域确定表格的初步范围,在初步范围内定位表格的准确位置,能够实现找到表格的初步范围后再定位表格的具体位置,从而准确定位表格,在公告文档中搜索待识别表格内的字词,根据字词的坐标和待识别表格的准确位置,将字词填充到待识别表格中;现有技术中通常是直接通过线段和字符的坐标关系识别表格,本发明先对表格的引导区域和结束区域进行定位,再定位表格的位置,能够提高定位表格位置的准确率,通过词的坐标和表格准确位置,对表格进行数据填充,能够准确地解析出表格的内容。
进一步的,所述在公告文档中搜索待识别的表格的引导区域和结束区域包括:
根据预设的关键词和关键字在所述公告文档中进行正则化匹配,判断是否在所述公告文档中匹配到所述预设的关键词或关键字,若是,根据所述关键词或关键字的位置确定所述待识别的表格的引导区域和结束区域,若否,通过机器学习模型对所述待识别的表格的引导区域和结束区域进行定位。
由上述描述可知,若公告文档中含有关键字词,根据关键字词的位置确定引导区域和结束区域,若公告文档中不含有关键字词,通过机器学习模型确定引导区域和结束区域,使用了两种定位引导区域和结束区域的方法,能够兼容更灵活多变的表述方式,进一步提高表格识别的准确性。
进一步的,所述通过机器学习模型对所述待识别的表格的引导区域和结束区域进行定位包括:
在各类型公告文档中,将待识别表格的引导区域、结束区域和表格区域组成的文本区域标记为正类样本,将非待识别表格的引导区域、结束区域和表格区域的连续三个段落组成的文本区域标记为负类样本;
计算每个样本的特征向量;
根据每个样本的特征向量及其对应的样本类型得到训练数据集;
根据所述训练数据集训练二分类模型,得到训练完成的二分类模型;
获取所述公告文档的待识别特征向量,将所述特征向量输入所述训练完成的二分类模型中分类,确定所述待识别的特征向量对应的区域的类型;
根据确定出的类型及其对应的待识别的特征向量确定所述待识别的表格的引导区域和结束区域。
由上述描述可知,机器学习模型进行定位时包括两个阶段,在训练阶段时,在各类型的公告文档中提取正类样本和负类样本,提取样本的特征向量并得到训练数据集,对训练数据集进行二分类模型训练,在识别阶段时,将公告文档的待识别特征向量输入二分类模型中进行分类,输出待识别公告文档的特征向量类型,通过对各类型的公告文档的训练,能够灵活地识别出表格引导区域和结束区域的范围,定位效果具有鲁棒性。
进一步的,所述计算每个样本的特征向量包括:
提取所述样本对应的引导区域和结束区域的词向量特征,提取表格区域的线段数量和文本分布特征;
将所述词向量特征以及所述线段数量和文本分布特征进行组合形成所述样本对应的特征向量。
由上述描述可知,获取样本引导区域和结束区域的词向量特征,以及表格区域的线段数量和文本分布特征,将词向量特征、线段数量和文本分布特征组成特征向量,能够准确获得样本的特征向量。
进一步的,所述根据所述训练数据集训练二分类模型,得到训练完成的二分类模型包括:
将所述训练数据集输入到胶囊神经网络的学习模块中,根据所述学习模块的学习结果以及对应输入的训练数据集调节所述胶囊神经网络的参数得到最优的胶囊神经网络模型。
由上述描述可知,使用胶囊神经网络对训练数据集的特征向量及其类别进行学习,从而通过小部分的数据就能够得到很好的学习效果。
进一步的,所述在所述初步范围内定位所述待识别的表格的准确位置包括:
在所述待识别的表格的初步范围内,搜索横线和竖线;
根据所述横线和竖线的交叉关系获得交叉点,根据所述交叉点形成单元格,将相邻的单元格进行组合;
根据组合后的单元格确定所述待识别的表格的准确位置。
由上述描述可知,通过横线和竖线的交叉关系获得交叉点,根据交叉点形成单元格,将相邻的单元格进行组合,从而形成完整的表格框架,能够根据识别到的表格准确获取表格位置。
进一步的,所述在所述公告文档中搜索所述待识别的表格内的字词,根据所述字词的坐标和所述待识别的表格的准确位置,将所述字词填充到所述待识别的表格中包括:
对所述公告文档进行解析,获取所述公告文档内字符与线段的位置;
根据所述字符与线段的位置,根据字符之间以及字符和线段之间的位置关系将所述字符组成词和句子;
根据所述待识别的表格的准确位置确定其包含的每一个单元格的位置以及位于所述准确位置范围内的词和句子;
根据位于所述准确位置范围内的词和句子的位置和所述待识别的表格的每一个单元格的位置,将位于所述准确位置范围内的词和句子与其对应的单元格进行关联;
将与每一个单元格关联的字和句子填充进所述单元格中。
由上述描述可知,根据字符和线段的坐标位置,将字符组成词和句子,将词和句子与对应的单元格关联,并将每个单元格关联的字词填入单元格中,能够准确地将词填入对应单元格,避免漏填或错填。
进一步的,将所述字词填充到所述待识别的表格中之后还包括步骤:
判断是否存在因合并单元格而引起的表格在不同行上的列数不同,若是,则将合并的单元格划分成多个单元格,若否,则不进行修改;
判断是否存在多个空白格,若是,则通过单元格之间的位置关系对空白格进行合并,若否,则不进行修改;
判断是否存在跨页表格,如果存在,则判断是否存在一行数据被分在两个不同的页面内,若是,则将被拆分的两行数据进行合并,若否,则将跨页的两个表格对齐后直接合并。
由上述描述可知,对填充后的表格进行格式修正,当在因合并单元格而引起的表格在不同行上的列数不同时,将合并的单元格划分成多个单元格,能够为后续数据的提取提供便利;当存在多个空白格时,通过单元格之间的位置关系将空白格合并,能够得到正确的单元格;当存在跨页表格时,对跨页表格进行合并处理,能够提高表格的完整性和正确性。
进一步的,所述判断是否存在跨页表格的方法包括:
判断是否前一页的表格位于页面底部且当前页表格位于页面顶部,若是,则存在跨页表格,若否,则不存在跨页表格;
判断表格是否位于页面底部或页面顶部包括:
判断是否表格到页面顶部或页面底部的距离小于预设距离且表格与页面顶部或页面底部之间不存在正文文本,若是,则表格位于页面的顶部或底部,若否,则表格位于页面的中间区域。
由上述描述可知,通过判断表格到页面顶部或页面底部的距离小于预设距离与页面顶部或页面底部之间是否存在正文文本,能够保证准确地搜索处于页面顶部或底部表格,通过判断是否前一页的表格位于页面底部且当前页表格位于页面顶部,能够保证准确搜索到跨页表格。
请参照图2,本发明另一实施例提供了一种公告文档表格数据识别终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的公告文档表格数据识别方法中的各个步骤。
实施例一
请参照图1,一种公告文档表格数据识别方法,包括步骤:
S1、在公告文档中搜索待识别的表格的引导区域和结束区域,根据所述待识别的表格的引导区域和结束区域确定所述待识别的表格的初步范围;
其中,根据预设的关键词和关键句在所述公告文档中进行正则化匹配,判断是否在所述公告文档中匹配到所述预设的关键词或关键字,若是,根据所述关键词或关键字的位置确定所述待识别的表格的引导区域和结束区域,若否,通过机器学习模型对所述待识别的表格的引导区域和结束区域进行定位;
具体的,在本实施例中,通过人工总结的关键词与关键句进行正则化匹配,当定位到相应的关键词与关键句时,显示定位成功,当未定位到相应的关键词与关键句时,通过机器学习模型进行定位;
其中,通过机器学习模型对所述待识别的表格的引导区域和结束区域进行定位包括:
在各类型公告文档中,将待识别表格的引导区域、结束区域和表格区域组成的文本区域标记为正类样本,将非待识别表格的引导区域、结束区域和表格区域的连续三个段落组成的文本区域标记为负类样本;
计算每个样本的特征向量;
根据每个样本的特征向量及其对应的样本类型得到训练数据集;
根据所述训练数据集训练二分类模型,得到训练完成的二分类模型;
获取所述公告文档的待识别特征向量,将所述特征向量输入所述训练完成的二分类模型中分类,确定所述待识别的特征向量对应的区域的类型;
根据确定出的类型及其对应的待识别的特征向量确定所述待识别的表格的引导区域和结束区域;
具体的,在本实施例中,引导区域指的是表格之前的若干行文本区,结束区域是表格之后的若干行文本区;机器学习方法在进行区域定位时包括训练阶段和识别阶段,在训练阶段,通过人工标注出引导区域、结束区域和表格区域,将待识别表格的这三个区域组成的文本区域标记为正类样本,计算其特征向量,再选择非待识别表格的这三个区域的连续三个段落组成的文本区域标记为负类样本,确定对应的特征向量,因为只关注包含表格的区域,所以选择的负类样本的中间段落需要包含若干条线段,即该区域可能包含表格,根据每一个样本的特征向量及其对应的样本类型得到训练数据集,再用所述训练数据集训练二分类模型;在识别阶段,先搜索文档中具有若干线段的区域,每个这样的区域和它的前后段落一起作为一个待识别的候选区域,将这个候选区域以在训练阶段的一样的方法获取待识别的特征向量,将待识别的特征向量输入到训练阶段的二分类模型中进行分类,通过二分类模型输出待识别特征向量的类型,其中,训练阶段是离线进行的;
在一个可选的实施方式中,可以将所述训练数据集输入到胶囊神经网络的学习模块中,根据所述学习模块的学习结果以及对应输入的训练数据集调节所述胶囊神经网络的参数得到最优的胶囊神经网络模型;
具体的,本实施例中,将训练数据集中的特征向量及其类别标签输入到tensorflow的胶囊神经网络的学习模块中,通过调节参数选择最优的胶囊神经网络模型;
S2、在所述初步范围内定位所述待识别的表格的准确位置;
其中,在所述待识别的表格的初步范围内,搜索横线和竖线;
根据所述横线和竖线的交叉关系获得交叉点,根据所述交叉点形成单元格,将相邻的单元格进行组合;
根据组合后的单元格确定所述待识别的表格的准确位置;
具体的,在本实施例中,先将搜索到的线段进行清理,合并过近的线段并且清除过短的线;根据线段间的位置关系获得交叉点,再由交叉点间的位置关系形成单元格;将相邻单元格组合,根据组合单元格形成完整的表格,确定表格的坐标范围;
S3、在所述公告文档中搜索所述待识别的表格内的字词,根据所述字词的坐标和所述待识别的表格的准确位置,将所述字词填充到所述待识别的表格中;
其中,对所述公告文档进行解析,获取所述公告文档内字符与线段的位置;
根据所述字符与线段的位置,根据字符之间以及字符和线段之间的位置关系将所述字符组成词和句子;
根据所述待识别的表格的准确位置确定其包含的每一个单元格的位置以及位于所述准确位置范围内的词和句子;
根据位于所述准确位置范围内的词和句子的位置和所述待识别的表格的每一个单元格的位置,将位于所述准确位置范围内的词和句子与其对应的单元格进行关联;
将与每一个单元格关联的字和句子填充进所述单元格中;
具体的,在本实施例中,使用解析工具pdfbox或者pdfminer开源软件对公告文档进行解析,获取字符与线段的位置,当两个字符之间的距离小于某个阈值时,将被合并为一个词,这个阈值在本实施例中设定为字符字体大小的一半;当词或句子的坐标落在某个单元格范围内时,便将该词或句子与此单元格关联,然后按照坐标顺序将与单元格关联的词或句子组合起来,作为此单元格的内容;
表格中的单元格内容填充完成后,将表格内容按照行列结构形成json格式的文本输出。
实施例二
本实施例与实施例一的不同在于,进一步限定了根据正类样本确定其对应的特征向量具体为:
在正类样本中,对引导区域和结束区域进行中文分词,统计每个词出现的次数,将这些次数拼接成一个数值向量,并将每个值归一化到0和1之间,这个数值向量的每一维代表了每个词在这个区域出现的频率,且该数值向量为该正类样本引导区域和结束区域的词向量特征;对于表格区域,表格边框是一个非常重要的特征,通过统计线段的交叉点数量来表示这个区域存在表格的可能性,为提高稳定性,根据交叉点的数量分成三种情况:稀少、一般和丰富,分别用0、0.5和1表示,得到线段数量和文本分布特征,然后将这个值拼接在之前的词向量特征末尾,形成该正类样本的特征向量。
实施例三
本实施例与实施例一和实施例二的不同在于,进一步限定了将字词填充到待识别的表格中后,对特殊情形的单元格进行修正,具体为:
其中,判断是否存在因合并单元格而引起的表格在不同行上的列数不同,若是,则将合并的单元格划分成多个单元格,若否,则不进行修改;
具体的,在生成的表格中不同行的列数不同,且列数不同是由于合并单元格引起的,将该单元格拆分为多个小单元格,并且每个单元格的内容与拆分前单元格的内容相同;
判断是否存在多个空白格,若是,则通过单元格之间的位置关系对空白格进行合并,若否,则不进行修改;
具体的,当存在单元格被错误地划分成多个格子时,这些格子里往往包含若干个细小的空白格,通过单元格之间的位置关系对这些格子进行合并,得到正确的单元格;
判断是否存在跨页表格,如果存在,则判断是否存在一行数据被分在两个不同的页面内,若是,则将被拆分的两行数据进行合并,若否,则将跨页的两个表格对齐后直接合并;
具体的,对于跨页的表格,先判断前一页的表格是否位于页面底部以及当前页表格是否位于页面顶部,判断的依据是表格与页面边缘的距离,以及表格与页面边缘之间是否存在正文文本;当同时满足前一页的表格位于页面底部和当前页表格位于页面顶部的条件时,将两表格合并;由于两个页面中表格的坐标位置可能会有差异,需要先进行对齐,根据两个表格的对应的最左坐标和最右坐标之间的差值对各单元格进行坐标修正;合并表格时,先判断是否存在一行被分在了不同页面里,如果存在,则将相应的行进行合并,否则,只需将两个表格拼接在一起即可。
实施例四
请参照图2,一种公告文档表格数据识别终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现实施例一至实施例三中任一项中的公告文档表格数据识别方法中的各个步骤。
综上所述,本发明提供的一种公告文档表格数据识别方法与终端,在公告文档中搜索待识别表格的引导区域和结束区域,若公告文档中含有关键字词,根据关键字词的位置确定引导区域和结束区域,若公告文档中不含有关键字词,通过机器学习模型确定引导区域和结束区域,能够兼容更灵活多变的表述方式;机器学习模型进行定位需要训练公告文档正负类样本,能够灵活地识别出表格引导区域和结束区域的范围,定位效果具有鲁棒性;使用胶囊神经网络对训练数据集的特征向量及其类别进行学习,从而通过小部分数据就能够得到很好的学习效果;根据待识别表格的引导区域和结束区域确定表格的初步范围,在初步范围内定位表格的准确位置,能够实现找到表格的初步范围后再定位表格的具体位置,从而准确定位表格,在公告文档中搜索待识别表格内的字词,根据字词的坐标和待识别表格的准确位置,将字词填充到待识别表格中,避免数据的漏填或错填;对表格的错误格式和特殊单元格进行修正,合并跨页表格,能够提高表格的完整性和正确性;现有技术中通常是直接通过线段和字符的坐标关系识别表格,本发明先对表格的引导区域和结束区域进行定位,再定位表格的位置,能够提高定位表格位置的准确率,通过词的坐标和表格准确位置,对表格进行数据填充,能够准确地解析出表格的内容,并且提高表格的完整性和正确性。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。
- 一种公告文档表格数据识别方法及终端
- 一种公告文档表格数据识别方法及终端