基于相似性成对排名的推荐系统物品预测方法
文献发布时间:2023-06-19 10:08:35
技术领域
本发明涉及一种基于相似性成对排名的推荐系统物品排名预测方法,属于推荐系统。
背景技术
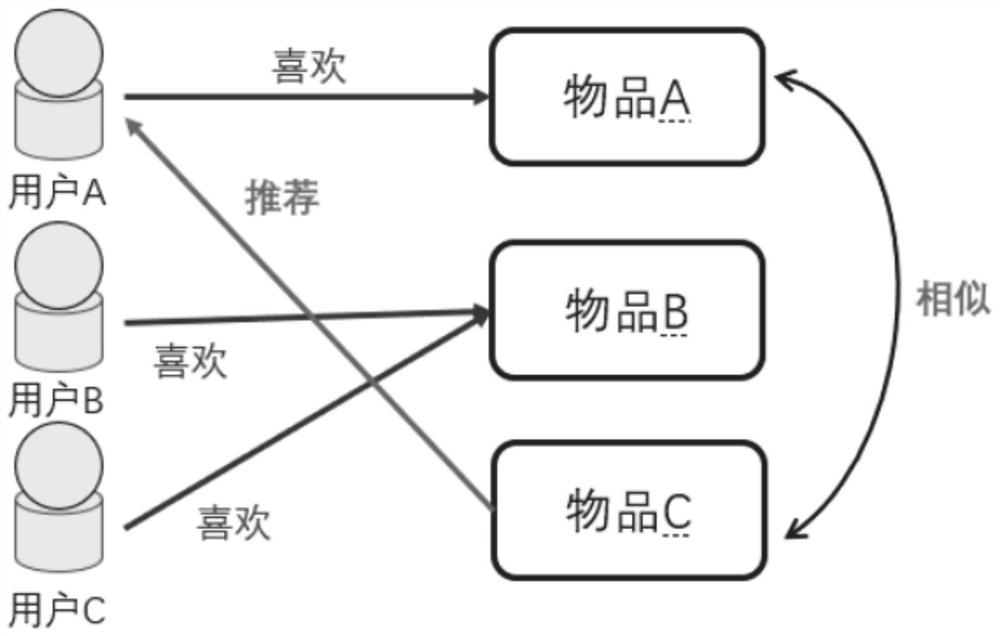
随着互联网行业的发展,人类社会已进入了一个信息爆炸的时代。信息爆炸是互联网赋予当前时代的特征,信息的快速创造和传播不断加剧了信息爆炸的问题,并且带给人类诸多感受:1.各类商品花样繁多;2.新闻信息飞速增加3.广告信息铺天盖地4.科技信息迅猛递增5.个人接收力严重“超载”。推荐系统作为解决这一问题的有效手段已在各个领域广泛使用。推荐系统的任务是预测一组物品的个性化排名。物品可以是网站、电影、商品等。简言之就是根据用户的偏好推荐其最有可能感兴趣的内容。图1表示了一个简单的推荐系统。推荐系统在现实生活中应用广泛。Netflix为电影和电视推荐举行了Netflix Prize大赛,华盛顿邮报在trec中添加了新闻推荐赛道,阿里巴巴研究网上购物行为中利用推荐系统提高用户转化率,以及帮助学者们发现合适论文的推荐系统。Top-N推荐系统能够帮助用户以极小的时间和精力代价下寻找到自己想要的物品,有着充分的研究价值。
推荐系统中用户行为极为稀少,而待推荐的物品数量庞大。其中,待推荐的物品中既包含了用户看过而不喜欢的物品,也包含了用户可能喜欢但是没有看到的物品。与分类问题不同的是,推荐中的用户不与项目进行交互有一些原因。可能是用户真的不喜欢这个项目,或者用户没有看到这个项目。为了更好的建模推荐问题,成对排序方法没有直接预测用户是否喜欢某一个物品,而是从排序学习的角度考虑推荐系统所面临的问题。具体而言,成对排序方法从用户的历史行为中学习物品的偏序信息,并增大正负样本对之间的得分差异,得分高的物品便是用户喜欢的物品。贝叶斯个性化排序是一种建立成对学习模型的有效方法,广泛应用于Top-N推荐中。然而,数据分布的不平衡会严重影响贝叶斯个性化排序有效性。贝叶斯个性化排序往往将流行项目排在个性化项目之前,以至于无法满足用户的个性化需求。
发明内容
本发明用于解决贝叶斯个性化排序有效性受数据分布的不平衡影响的问题,具体提出了一种基于成对物品相似性的推荐系统物品预测方法。该方法在贝叶斯个性化排序的基础上,利用了正样本之间的相似性,改进原有方法的学习效果。
为实现上述目的,本发明采用的技术方案基于成对排名进行改进的相似性成对排名的推荐系统物品预测方法,如图所示,该方法的实现步骤如下:
步骤(1)获取推荐系统数据集;推荐系统数据集表示为(用户、物品、用户对物品的评分),其中用户用u表示,物品分为正样本i和负样本j,用户对物品的评分用r表示,由用户给出评分的物品称为正样本,未由用户给出评分的物品称为负样本;
步骤(2)根据用户,把推荐系统数据集中的物品划分为正负样本集合,其中,使用V
步骤(3)把用户的正样本集合划分为多个相似物品组,具体的,用户的评分范围为1-S,将用户u的正样本继续划分为S个子集合
步骤(4)将推荐系统数据集、相似物品组集合、负样本集合重新组织为相似物品对数据集,其中,相似物品对表示为
步骤(5)构建相似性成对排名模型并初始化;
在推荐系统中,常常使用向量来分别表示用户和物品并进行计算。为了解决贝叶斯个性化排序有效性受数据分布的不平衡影响的问题,相似性成对排名模型建模了两个正样本之间的相似性以及正样本和负样本之间的差异性。相似性成对排名模型要求两个正样本之间的分数差异尽可能的小,这样就可以使被某些用户喜欢的物品可以像流行物品一样拥有较高的分数。同时,模型也要求正样本和负样本之间的分数差异尽可能的大,这样做的好处是模型能够很好的区分用户喜欢的物品和不喜欢的物品。模型还加入了正则化项防止过拟合。所述的相似性成对排名模型用于最优化用户及物品的向量表示,使用户u喜欢的物品的向量表达更加接近,用户u不喜欢的物品的向量表达更加的不同,具体如下:
其中,Ds表示步骤(4)得到的相似物品对数据集,
α为超参数,用于控制物品的相似性对目标函数和结果的影响,
σ为sigmoid函数,
||X||
初始化:本方法利用向量来表示数据集中的每一个用户和物品,本方法中采用高斯分布随机初始化所有用户向量和物品向量;
步骤(6)相似性成对排名模型训练,得到用户和物品的最优向量表示;
步骤(7)物品分数预测和排序;
根据步骤(6)得到的每一个用户的最优向量表示和每一个物品的最优向量表示,使用打分函数预测用户对每一个物品的喜好分数,然后根据分数对所有物品进行排序,最后根据实际需求生成推荐列表,其中,打分函数如下:
有益效果
本方法在成对排名的基础上,利用了正样本之间的相似性,改进原有方法的学习效果,解决了使用成对排序方法时遇到的头部问题。使用相似性成对排序的推荐系统预测性能比原来的成对排序的推荐系统性能显著提升。
附图说明
图1为推荐系统示意图
图2为本方法流程图
具体实施方式
本发明的目的在于提出一种基于物品相似性的推荐系统物品预测方法,在成对排序的基础上,利用物品之间的相似性产生更加个性化的推荐结果。
为了实现上述目标,本发明采用的技术方案为基于成对排序的基于相似性成对排序的推荐系统物品排序预测方法,如图所示。该方法的实现步骤如下:
步骤(1)获取推荐系统数据集:
推荐系统数据集主要记录了真实世界中用户对物品的评分信息(u,i,r),其中,u表示物品,i表示物品,r表示u对i的评分数值。例如(张三,《我和我的祖国》,5)表示张三给电影《我和我的祖国》打了5分。推荐系统常用的数据集有MovieLens1M数据集。其中记录了6040个用户对3952部电影的共100万条评分。分数范围为1-5分。数据集的格式为{(u,i,r)}。
步骤(2)根据数据集对每个用户划分为正负样本集合:
由于推荐系统数据集中只记录了用户对部分物品的评分信息,而缺少用户对剩余物品的描述,所以,需要针对每一个用户将物品划分为正负样本集合。其中用户的正样本集合使用V
步骤(3)对正样本划分为相似物品组:
在任一用户的正样本集合中,可以根据评分数值S将该集合进一步细分为
步骤(4)将数据集、相似物品组、负样本集合重新组织为相似物品对:
在本步骤中,需要将数据集重新组织成符合相似性成对排名学习的格式。相似性成对排名学习要求相似物品对<u,i,q,j>的形式,其中,u表示用户,i,q,j表示物品,并且u,i来自数据集,q来自相似物品组
步骤(5)相似性成对排名模型初始化
使用一个向量来表示数据集中的分别表示每一个用户和物品,X表示有所有用户向量组成的用户矩阵,X
本发明通过定义相似物品对,引入了物品之间的相似性对成对排序方法进行改进,改进后的优化目标函数为:
步骤(6)相似性成对排名模型训练
使用随机梯度下降算法最小化目标函数,共循环20次,学习率lr=0.007,正则化系数rg=0.05,超参数α=0.09
随机梯度下降参数更新迭代过程:
·在每次循环过程中,遍历每一个相似物品对。
·针对每一个相似物品对,得到相应参数的梯度如下:
ΔX
ΔY
ΔY
ΔY
·根据相应的梯度信息,按照如下更新公式进行更新:
X
Y
Y
Y
·其中,lr表示学习率,在本方法中,我们将学习率设置为0.007。
步骤(7)物品分数预测和排序
在步骤(6)训练后,得到了训练集中每一个用户的向量表示和每一个物品的向量表示。在给一个用户u产生推荐列表时,先使用打分函数预测用户对每一个物品的分数。然后采用降序对所有物品进行排序。最后取排序的前10个作为推荐列表。一个用户u对一个物品i的喜好程度用如下评分函数进行预测:
基于相似性成对排名模型能够产生比现有方法更好的推荐结果,代表用户兴趣爱好的物品能够得到更高的分数,在推荐列表中取得更加靠前的位置。表1绘制了相似性成对排名模型(SPRMF)与现有方法的比较。在归一化折损累计增益NDCG(5,10)中取得了最好的效果,SPRMF比BPRMF分别高出了9.96%和9.38%。相似性成对排名模型解决了使用成对排序方法时遇到的头部问题。使用相似性成对排序的推荐系统预测性能比原来的成对排序的推荐系统性能显著提升。
表1:实验结果
- 基于相似性成对排名的推荐系统物品预测方法
- 一种基于时空相似性的城市级信号推荐系统