一种基于网络分类的命名实体识别方法
文献发布时间:2023-06-19 10:11:51
技术领域
本发明涉及自然语言处理技术与命名实体识别领域,尤其涉及一种基于网络分类的命名实体识别方法。
背景技术
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。通常包括两部分:(1)实体边界识别;(2)确定实体类别(人名、地名、机构名或其他)。NER是NLP中一项基础性关键任务。从自然语言处理的流程来看,NER可以看作词法分析中未登录词识别的一种,是未登录词中数量最多、识别难度最大、对分词效果影响最大问题。同时NER也是关系抽取、事件抽取、知识图谱、机器翻译、问答系统等诸多NLP任务的基础。
命名实体识别信息抽取任务的焦点,在实际生产中需求很迫切,但命名实体的数量无穷,构词灵活,类别模糊等特性又使得命名实体识别做起来很难。传统的分类算法仅仅考虑到数据之间的物理特性(如相似性,距离,分布等),没有考虑到数据之间的语义特性(如文本中可能存在上下文语义信息)。
传统分类学习方法,例如SVM和一些其它基于网络的分类算法,在实际实现中需要使用所有训练数据,庞大的数据量中存在的噪音会使得命名实体的识别效率降低。
发明内容
本发明为克服现有技术的不足之处,提出一种基于网络分类的命名实体识别方法,以期能通过选择部分命名实体识别样本构造分类网络并对待测命名实体样本进行识别,从而提高命名实体的识别效率,进而为信息提取、问答系统、句法分析、机器翻译等提供技术支持。
为了达到上述目的,本发明采用的技术方案为:
本发明一种基于网络分类的命名实体识别方法的特点是按如下步骤进行:
步骤一:命名实体分类模型训练:
步骤1.1:获取T个命名实体样本的文本数据,并使用Word2Vec自然语言处理工具将所述文本数据转换为向量数据Ψ=((x
步骤1.2:对所述第t个命名实体样本的属性特征x
步骤1.3:利用式(1)和式(2)分别构建两个目标函数f
min f
式(1)中,V
式(2)中,
步骤1.4:以S个待选择的命名实体样本的向量数据的集合作为初始种群P={p
采用长度为T的二进制编码对所初始种群P进行编码;若个体p
步骤1.5:定义当前迭代次数为n,最大迭代次数为N;并初始化n=1;以初始种群P作为第n次迭代的父代种群P
步骤1.6:通过二元锦标赛从第n次迭代的父代种群P
步骤1.7:将第n次迭代的父代种群P
IMP(p
式(3)中,α为折中因子,Acc(p
Red(p
式(4)中,m为第n次迭代的合并种群中除个体p
式(5)中,Acc(i)表示第i个个体所构建的分类网络的精度,Acc(p
步骤1.8:根据式(3)得到第n次迭代的合并种群中所有个体p
步骤1.9:令n+1赋值给n,并判断n>N是否成立,若成立,则将第N次迭代的父代种群中分类网络精度最高的个体所对应的命名实体样本的向量数据选出并用于构造最优网络分类器,执行步骤二,否则,返回步骤1.6执行;
步骤二:命名实体识别:
步骤2.1:输入待识别的命名实体样本的文本数据,按照步骤1.1和步骤1.2进行处理,并得到待测样本的特征向量;
步骤2.3:利用所述最优网络分类器对待测样本的的特征向量进行分类,所得到的标签表示待测样本所对应的命名实体。
本发明所述的一种基于网络分类的命名实体识别方法的特点是,所述式(6)中的分类网络
对于特征向量
式(6)中,
与已有技术相比,本发明的有益效果体现在:
1、本发明不同于传统的分类方法,提出一种基于网络分类的命名实体识别方法,综合考虑命名实体样本数据的物理和语义特性,通过对其进行筛选训练构造分类网络,剔除噪声点,从而能够更加高效地对命名实体做出识别。
2、本发明定义了一个两目标:选择的命名实体识别样本集合中样本的数目,所选命名实体识别样本集合构造出网络的分类精度的优化问题,通过优化这两点选择了高质量的命名实体样本数据,构造出了分类效果更好的分类网络,从而提高了命名实体识别的性能和准确率。
3、本发明在迭代过程中,采用基于精度偏好的产生解策略,通过对低精度的命名实体识别样本集合进行精度指导以得到更优秀的子代,有效的提高了的待构造分类网络的质量,从而使得最终用于命名实体识别的分类器分类效果更好,识别准确率更高。
4、本发明在选择下一代命名实体识别样本集合的过程中,采用了基于重要性的选解策略,通过对所有命名实体识别样本集合进行重要性排序选择更加优秀的进入下一代,保证了迭代过程中的不断优化,使得最终用于命名实体识别的分类器分类效果更好,性能更优秀。
附图说明
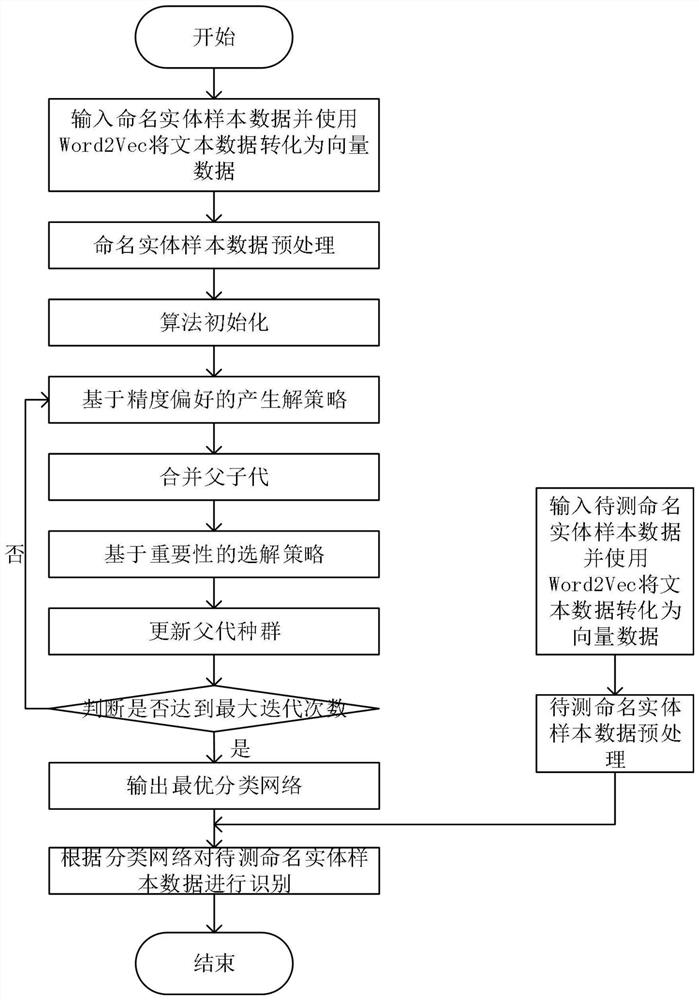
图1是本发明方法的流程图。
具体实施方式
本实施例中,一种基于网络分类的命名实体识别方法,包括命名实体分类模型训练步骤和命名实体识别步骤,具体的说,如图1所示,是按如下步骤进行:
步骤一:命名实体分类模型训练:
步骤1.1:以人名的命名实体识别为例,获取T个命名实体样本的文本数据,并使用Word2Vec自然语言处理工具将文本数据转换为向量数据Ψ=((x
步骤1.2:对第t个命名实体样本的属性特征x
步骤1.3:利用式(1)和式(2)分别构建两个目标函数f
min f
式(1)中,V
式(2)中,
步骤1.4:以S个待选择的命名实体样本的向量数据的集合作为初始种群P={p
采用长度为T的二进制编码对所初始种群P进行编码;若个体p
步骤1.5:定义当前迭代次数为n,最大迭代次数为N;并初始化n=1;以初始种群P作为第n次迭代的父代种群P
步骤1.6:通过二元锦标赛从第n次迭代的父代种群P
步骤1.7:将第n次迭代的父代种群P
IMP(p
式(3)中,α为折中因子,常取0.8,Acc(p
Red(p
式(4)中,m为第n次迭代的合并种群中除个体p
式(5)中,Acc(i)表示第i个个体所构建的分类网络的精度,Acc(p
步骤1.8:根据式(3)得到第n次迭代的合并种群中所有个体p
步骤1.9:令n+1赋值给n,并判断n>N是否成立,若成立,则将第N次迭代的父代种群中分类网络精度最高的个体所对应的命名实体样本的向量数据选出并用于构造最优网络分类器,执行步骤二,否则,返回步骤1.6执行;
步骤二:命名实体识别,利用步骤一得到的最有网络分类器对待测样本进行分类:
步骤2.1:输入待识别的命名实体样本的文本数据,按照步骤1.1和步骤1.2进行处理,并得到待测样本的特征向量,常见的特征有出生时间,籍贯,身高,体重,昵称,主要贡献等;
步骤2.3:利用最优网络分类器对待测样本的的特征向量进行分类,所得到的标签表示待测样本所对应的命名实体。
2、根据权利要求1的一种基于网络分类的命名实体识别方法,其特征是,式(6)中的分类网络
对于特征向量
式(6)中,
采用客观采集的数据对本方法进行测试与验证。
1)、采集与人名有关的命名实体样本的文本数据,即获取文献中与人名相关的语句或者段落,然后利用Word2Vec工具将真实世界的文本数据转化为计算机可以处理的向量数据,然后将处理好的数据集划分为训练样本和测试样本,通过十折交叉验证选取出最佳的训练样本构造分类网络并对测试样本进行命名实体识别。
2)、评价指标;
采用分类精度作为本实例的评价指标,用来评测对于命名实体识别的性能。精度越高,表示分类效果越好,识别准确率也就越高。
3)、在数据集上进行实验;
通过在数据集上的实验结果验证本发明的有效性。在信息高度多元化的今天,准确高效地从文本中识别出命名实体,对其进行分析显得尤为重要。实验表明,本发明能快速有效从海量的文本中提取命名实体的关键属性并识别出该实体的类别,提高了命名实体识别的效率并为信息提取、问答系统、句法分析、机器翻译等提供基础。
- 一种基于网络分类的命名实体识别方法
- 一种基于神经网络概率消歧的网络文本命名实体识别方法