高并发数据处理系统及方法
文献发布时间:2023-06-19 10:11:51
技术领域
本发明涉及服务器领域,尤其涉及一种高并发数据处理系统及方法。
背景技术
随着工业互联网的快速发展,工业设备的数量将越来越多,设备数据需要进行上报和存储,数据上报的频率日益增长,对服务器造成了很大的压力,同时,数据上报过程中还伴随着实时业务处理。面对多种设备的高并发上报和处理,如何提高服务器的处理能力,对数据进行实时处理并存储,是首要解决的难题,因此,需要一个具备高并发处理能力的架构。
发明内容
本发明的目的是针对现有技术的输出处理量激增导致服务器压力大的技术问题,本发明提出一种高并发数据处理系统及方法。
本发明实施例中,提供了一种高并发数据处理系统,其包括数据库、负载均衡服务器、多个消息队列服务器、与所述多个消息队列服务器一一对应设置的多个流处理服务器,
所述负载均衡服务器,用于根据预先配置好的IP映射关系和调度算法,将外部的数据请求分发到相应的消息队列服务器;
每个所述消息队列服务器,设置了用于暂存一种类型的数据请求的由消息队列组成的主题通道,用于将所述负载均衡服务器分发过来的数据请求暂存到所述主题通道中;
每个所述流处理服务器,用于采用流处理技术对与其对应设置的消息队列服务器的主题通道中的数据请求进行处理,并将处理的结果存入所述数据库中。
本发明实施例中,所述负载均衡服务器采用Nginx服务器。
本发明实施例中,所述消息队列服务器采用Kafka服务器。
本发明实施例中,所述流处理服务器采用Flink服务器。
本发明实施例中,所述负载均衡服务器在所述预先配置好的IP映射关系及调度算法中,设置了不同类型的数据请求对应的消息队列服务器以及所述消息队列服务器的IP地址。
本发明实施例中,还提供了一种高并发数据处理方法,其包括:
负载均衡服务器根据预先配置好的IP映射关系和调度算法将外部的数据请求分发到相应的消息队列服务器;
消息队列服务器将负载均衡服务器分发过来的数据请求暂存在用于暂存所述数据请求同类型的数据请求的主题通道中;
流处理服务器获取相应消息队列服务器的主题通道中的数据请求并采用流处理技术所述数据请求进行处理,并将处理的结果存入数据库中。
与现有技术相比较,采用本发明的高并发数据处理系统及方法,负载均衡服务器根据预先配置好的IP映射关系和调度算法将外部的数据请求分发到相应的消息队列服务器;消息队列服务器将负载均衡服务器分发过来的数据请求暂存在用于暂存所述数据请求同类型的数据请求的主题通道中;流处理服务器获取相应消息队列服务器的主题通道中的数据请求并采用流处理技术所述数据请求进行处理,并将处理的结果存入数据库中,利用了各个服务器自身的数据处理特性,可以解决大量数据请求对服务器带来的负载过重的问题,提高实时处理的能力。
附图说明
图1是本发明实施例的高并发数据处理系统的结构示意图。
图2是本发明实施例的高并发数据处理系统的数据处理流程的示意图。
具体实施方式
如图1所示,本发明实施例中,提供了一种高并发数据处理系统,其包括数据库、负载均衡服务器、多个消息队列服务器、与所述多个消息队列服务器一一对应设置的多个流处理服务器。下面分别进行说明。
所述数据库,用于存储数据。本发明实施例中,所述数据库采用MySQL数据库。
所述负载均衡服务器,用于根据预先配置好的IP映射关系和调度算法,将外部的数据请求分发到相应的消息队列服务器。
需要说明的是,本发明实施例中,所述负载均衡服务器采用Nginx服务器。Nginx服务器具有速度快、扩展性好、可靠性高的优点。本发明实施例中,采用Nginx服务器作为负载均衡服务器,利用Nginx服务器可靠性高的特定,将其用于对数据请求进行反向代理的分发操作。在所述预先配置好的IP映射关系及调度算法中,设置了不同类型的数据请求对应的消息队列服务器以及所述消息队列服务器的IP地址,以便于所述负载聚合服务器可以根据数据请求的类型将其发送到相应的消息队列服务器。
每个所述消息队列服务器,设置了用于暂存一种类型的数据请求的由消息队列组成的主题通道,用于将所述负载均衡服务器分发过来的数据请求暂存到所述主题通道中。
需要说明的是,由于所述高并发数据处理系统需要处理大量的高并发的数据请求,因此,需要设置多个消息队列服务器。本发明实施例中,所述消息队列服务器采用Kafka服务器。Kafka服务器是一个高吞吐量、分布式、基于发布订阅模式的消息系统。本发明实施例中,通过设置Kafka服务器集群来处理高并发的数据请求。Kafka服务器作为生产者建立主题(topic)通道,每个主题通道用于暂存一种类型的数据请求,用于将所述负载均衡服务器分发过来的数据请求暂存到所述主题通道中。
每个所述流处理服务器,用于采用流处理技术对与其对应设置的消息队列服务器的主题通道中的数据请求进行处理,并将处理的结果存入所述数据库中。
需要说明的是,本发明实施例中,所述流处理服务器采用Flink服务器。多个Flink服务器形成Flink服务器集群。Flink服务器不仅能够应对高并发的请求,同时可以降低程序间的耦合度,能对所消费的数据进行独立的业务处理,Flink服务器集群中的每个Flink服务器作为消费者,指定消费Kafka服务器中相应的主体通道的数据请求,根据业务需求进行高并发的逻辑处理,并将将处理后的结果存入MySQL数据库,提供后续的API需求。
上述高并发数据处理系统的配置过程如下:
第一步:搭建Kafka服务器集群,选择若干台计算机安装Kafka服务器软件,并配置好每台Kafka服务器的IP;
第二步:搭建Nginx服务器,选择一台机器安装Nginx服务器软件,并修改配置文件,根据各Kafka服务器的IP来配置映射关系,当Nginx服务器获得设备发送的请求时,依据映射关系和调度算法将请求分发到相应的Kafka服务器上;
第三步:搭建Flink服务器集群,选择若干台计算机搭建Flink服务器,并配置好每个Flink服务器中的流处理服务,每个流处理服务都指向一个Kafka服务器中相应的主题通道;
步骤四,安装MySQL数据库,将每个Flink服务器与MySQL数据库进行关联,实现数据的传输。
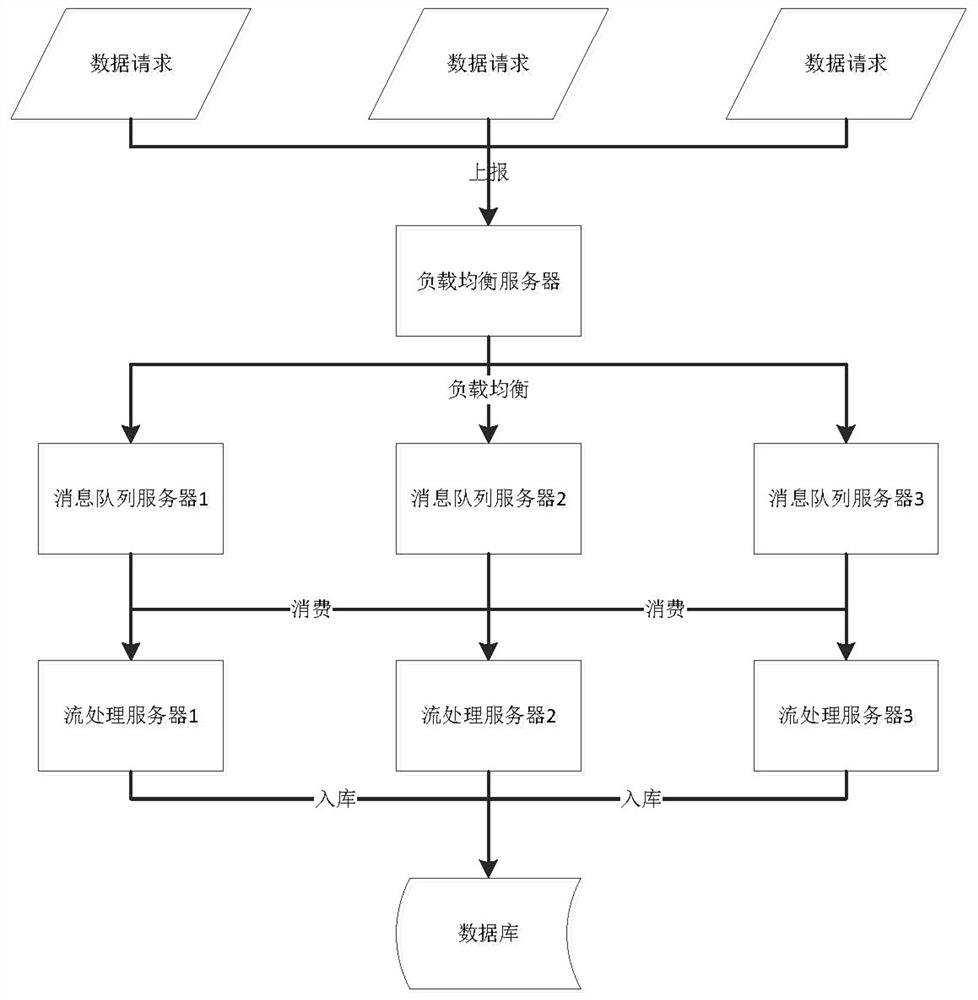
如图2所示,上述高并发数据处理系统的数据处理过程包括:
负载均衡服务器获取外部的数据请求;
负载均衡服务器根据预先配置好的IP映射关系和调度算法将外部的数据请求分发到相应的消息队列服务器;
消息队列服务器将负载均衡服务器分发过来的数据请求暂存在用于暂存所述数据请求同类型的数据请求的主题通道中;
流处理服务器获取相应消息队列服务器的主题通道中的数据请求并采用流处理技术所述数据请求进行处理,并将处理的结果存入数据库中。
综上所述,采用本发明的高并发数据处理系统及方法,负载均衡服务器根据预先配置好的IP映射关系和调度算法将外部的数据请求分发到相应的消息队列服务器;消息队列服务器将负载均衡服务器分发过来的数据请求暂存在用于暂存所述数据请求同类型的数据请求的主题通道中;流处理服务器获取相应消息队列服务器的主题通道中的数据请求并采用流处理技术所述数据请求进行处理,并将处理的结果存入数据库中,利用了各个服务器自身的数据处理特性,可以解决大量数据请求对服务器带来的负载过重的问题,提高实时处理的能力。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 高并发数据处理系统及方法
- 一种共享停车位防止高并发的数据处理系统及其方法