一种基于人工智能识别的影像处理系统
文献发布时间:2023-06-19 10:16:30
技术领域
本发明涉及人脸识别系统,具体涉及一种基于人工智能识别的影像处理系统。
背景技术
目前,对于监控区域内开展视频影像监控,是众多有关视频监控的技术人员仍在不断开发和研究的一项重要技术领域。因为如果完全依赖于人工监控,会有一是效率低下,二是成本增加,三是监控失误率或遗漏率高的现实缺陷。为解决这些缺陷,众多相关技术领域的人员也进行了深入的研发和探索。
而在现阶段,在视频监控中加入人脸识别进行实时监控是被广泛使用的技术手段,但是在一定距离下捕捉人脸又是一项重要的技术问题。由于人脸会在一定近的距离下才会被呈现和捕捉,此时可能目标物距离需防备的被保护物已非常接近,常见的如文物保护、展览保护场景等。而在这些场景下,由于灯光等因素,影像监控对于人体的捕捉亦未必非常及时,也就导致了后续人脸捕捉延迟的问题,这对于在这些场景下的被保护物的实际保护效果会产生较大的风险和负面影响。
发明内容
为了解决上述技术问题,本发明提供了一种基于人工智能识别的影像处理系统,可以实现人脸图像的及时捕捉和识别。
为实现上述目的,本发明采取的技术方案为:
一种基于人工智能识别的影像处理系统,包括:
人体识别模块,用于实现图像深度信息的获取,并基于模糊深度神经网络模型根据图像深度信息实现影像数据中人体信息的识别;
危险行为识别模块,在识别到人体时启动,用于实现人体深度信息以及骨骼信息的获取,并基于无限深度神经网络根据所有骨骼信息实现危险行为的识别;
目标图像挖掘模块,在发现危险行为时启动,用于基于Dssd_Inception_V3 coco模型实现目标人脸图像集的挖掘;
人脸识别模块,用于提取所述人脸图像集的LBPH、SIFT以及人脸骨骼特征,基于决策树实现人脸的识别。
进一步地,还包括:
影像预处理模块,用于根据每个视频帧的坐标信息确定每个视频帧的偏转角度,并按其中一个视频帧的偏转角度进行其他视频帧的重构。
进一步地,所述危险行为识别模块基于kinect深度传感器实现人体深度信息以及骨骼信息获取,基于骨骼信息滤波模块消除锁获得骨骼信息的抖动和噪声干扰。
进一步地,所述Dssd_Inception_V3 coco模型采用Dssd目标检测算法,用coco数据集预训练Inception_V3深度神经网络,然后用先前准备好的数据集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于人脸图像的目标检测模型。
进一步地,所述人体识别模块首先调用视频取帧脚本,每隔一定帧数获取一张图像,然后基于kinect深度传感器实现图像深度信息的获取,并基于模糊深度神经网络模型根据图像深度信息实现影像数据中人体信息的识别。
进一步地,所述人脸识别模块基于CART算法根据人脸图像集的LBPH、SIFT以及人脸骨骼特征实现人脸的识别,其中,CART算法基于安全人脸图像集的LBPH、SIFT以及人脸骨骼特征训练所得。
进一步地,所述人脸识别模块首先基于Dssd_Inception_V3 coco模型实现人脸图像集中遮挡物的识别,若发现遮挡物,则直接预警,若未发现遮挡物,则提取所述人脸图像集的LBPH、SIFT以及人脸骨骼特征,然后基于决策树实现人脸的识别。
进一步地,通过以下步骤完成其他视频帧的重构;
根据每个视频帧的偏转角度计算每个视频帧的补充偏转角度;
根据每个视频帧的补充偏转角度重新绘制每个视频帧。
本发明具有以下有益效果:
1)基于人体识别模块、危险行为识别模块、目标图像挖掘模块的设计可以实现人脸图像集的及时捕捉;
2)基于视频帧偏转角度的调整,可以很好的避免由于视频帧角度的不同所带来的行为、人脸识别误差;
3)采用LBPH、SIFT以及人脸骨骼特征进行人脸识别,可以有效改善单一特征因光照、角度以及尺度变化对识别的影响,提高识别率。
4)采用无限深度神经网络根据所有骨骼信息实现危险行为的识别,可以实现动态危险行为的快速识别,实时性好。
附图说明
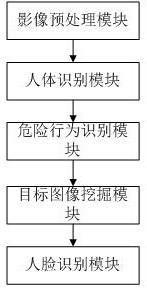
图1为本发明实施例一种基于人工智能识别的影像处理系统的系统框图。
图2为本发明实施例一种基于人工智能识别的影像处理系统的工作流程图。
具体实施方式
为了使本发明的目的及优点更加清楚明白,以下结合实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例1
如图1所示,本发明实施例提供了一种基于人工智能识别的影像处理系统,包括:
影像预处理模块,用于根据每个视频帧的坐标信息确定每个视频帧的偏转角度,并按其中一个视频帧的偏转角度进行其他视频帧的重构;
人体识别模块,用于实现图像深度信息的获取,并基于模糊深度神经网络模型根据图像深度信息实现影像数据中人体信息的识别;
危险行为识别模块,在识别到人体时启动,用于实现人体深度信息以及骨骼信息的获取,并基于无限深度神经网络根据所有骨骼信息实现危险行为的识别;
目标图像挖掘模块,在发现危险行为时启动,用于基于Dssd_Inception_V3 coco模型实现目标人脸图像集的挖掘;
人脸识别模块,用于提取所述人脸图像集的LBPH、SIFT以及人脸骨骼特征,基于决策树实现人脸的识别。
本实施例中,所述危险行为识别模块基于kinect深度传感器实现人体深度信息以及骨骼信息获取,基于骨骼信息滤波模块消除锁获得骨骼信息的抖动和噪声干扰。
本实施例中,所述Dssd_Inception_V3 coco模型采用Dssd目标检测算法,用coco数据集预训练Inception_V3深度神经网络,然后用先前准备好的数据集训练该模型,微调深度神经网络中的各项参数,最后得到合适的用于人脸图像的目标检测模型。
本实施例中,所述人体识别模块首先调用视频取帧脚本,每隔一定帧数获取一张图像,然后基于kinect深度传感器实现图像深度信息的获取,并基于模糊深度神经网络模型根据图像深度信息实现影像数据中人体信息的识别。
本实施例中,所述人脸识别模块基于CART算法根据人脸图像集的LBPH、SIFT以及人脸骨骼特征实现人脸的识别,其中,CART算法基于安全人脸图像集的LBPH、SIFT以及人脸骨骼特征训练所得。
本实施例中,所述人脸识别模块首先基于Dssd_Inception_V3 coco模型实现人脸图像集中遮挡物的识别,若发现遮挡物,则直接预警,若未发现遮挡物,则提取所述人脸图像集的LBPH、SIFT以及人脸骨骼特征,然后基于决策树实现人脸的识别。
本实施例中,通过以下步骤完成其他视频帧的重构;
根据每个视频帧的偏转角度计算每个视频帧的补充偏转角度;
根据每个视频帧的补充偏转角度重新绘制每个视频帧。
如图2所示,本具体实施使用时,包括如下步骤:
S1、根据每个视频帧的坐标信息确定每个视频帧的偏转角度,并按其中一个视频帧的偏转角度进行其他视频帧的重构;
S2、实现图像深度信息的获取,并基于模糊深度神经网络模型根据图像深度信息实现影像数据中人体信息的识别;
S3、在识别到人体时启动,进行人体深度信息以及骨骼信息的获取,并基于无限深度神经网络根据所有骨骼信息实现危险行为的识别;
S4、在发现危险行为时启动,基于Dssd_Inception_V3 coco模型实现目标人脸图像集的挖掘;
S5、提取所述人脸图像集的LBPH、SIFT以及人脸骨骼特征,基于决策树实现人脸的识别。具体的:所述人脸识别模块基于CART算法根据人脸图像集的LBPH、SIFT以及人脸骨骼特征实现人脸的识别,其中,CART算法基于安全人脸图像集的LBPH、SIFT以及人脸骨骼特征训练所得。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种基于人工智能识别的影像处理系统
- 一种基于人工智能的医学影像分类处理系统