一种领域语料库构建方法及系统
文献发布时间:2023-06-19 10:16:30
技术领域
本发明涉及软件方法技术领域,尤其涉及一种领域语料库构建方法及系统。
背景技术
截止至目前,大量的语料库在中国研究中文信息处理的单位建立起来,语料库成为了研究中文信息处理的基本语言资源。没有语料库的支持,中文信息处理的研究将会寸步难行。目前国内语料库建设方面,通常都是面向通用领域。而对于特定业务领域的语料库,目前并没有很好的构建方法。
发明内容
为此,需要提供一种领域语料库构建方法及系统,解决现有特定业务领域的语料库构建问题。
为实现上述目的,本发明提供了一种领域语料库构建方法,包括如下步骤:
术语发现步骤:在自然语料库中提取与领域相关的术语;
概念发现步骤:从与领域相关的公文、单据和报告中,提取与领域有关的术语;
短语发现步骤:从预设的大规模文档中采用监督机器学习算法或半监督机器学习算法获取可以表达概念的短语集合;
概念归类步骤:对短语集合的短语进行归类,将归类后的短语和提取后的术语作为语料库的语料存到数据库中。
进一步地,所述概念归类步骤还包括:根据预设的基于概念归类规则的正则表达式,对短语进行归类。
进一步地,所述语料包括短语和每个短语对应的类别。
进一步地,还包括步骤:读取数据库中的语料,对获取到的文档进行语料匹配,根据匹配到的语料所属的文档领域,对文档进行分类。
进一步地,所述监督机器学习算法为支持向量机算法或者朴素贝叶斯算法。
进一步地,所述半监督机器学习算法为流型学习算法或者协同训练算法。
本发明提供一种领域语料库构建系统,包括存储器、处理器,所述存储器上存储有计算机程序,所述计算机程序被处理器执行时实现如本发明实施例任意一项所述方法的步骤。
区别于现有技术,上述技术方案可以实现对特定业务领域的语料库的构建,解决现有特定业务领域的语料库构建问题。
附图说明
图1为具体实施方式所述的方法流程图。
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
请参阅图1,本实施例提供一种领域语料库构建方法,现有的语料库构建前一般要进行语料的搜集,现代计算机技术和网络资源使得语料库语料的获得变得方便容易。传统的语料库建设,语料输入工作极为浩繁,基本上靠手工键盘输入和扫描输入,费时费力,且容易出现错误,需要校对。如今大量的在线语料资源、光盘资料、因特网资源,包括新闻、邮件列表、电子邮件等,使语料库的建设和扩充变得非常的快捷方便。当然,用于不同业务领域目的的语料库对其语料来源可能要求不同,会影响到语料的采集。
语料库的主要工作包括有a)抽样和b)语料库的加工。在抽样中,语料库在语料抽样范围和文类覆盖方面都要尽可能取得平衡,要考虑每一文类、体裁、语域、主题类型等的抽样比例。
乔姆斯基曾经批评语料库不过是试图用很小的样本代表巨量的甚至无限的实际语言材料,其结果必然存在偏差,缺乏代表性。目前,计算机语料库可以通过控制抽样过程和语料比例关系来缩小偏差,增强语料的代表性。决定语料代表性的主要因素是样本的抽样过程和语料量的大小。语料库一般采用随机抽样方法。一种做法是在抽样前首先确定抽样的范围,再就是确定语料的分层结构,进行分层抽样,如把语料按文类(如小说、新闻报道、科学论文、法律文书、诗歌、散文等)和信道(如书面语和口语)进行分层抽样。在抽取比例上可根据需要采用平均比例均衡抽样或不等比例的塔式抽样。
而在语料库的加工中,文本输入计算机后,一般需要进行一些加工,主要包括语料的标识和语料的赋码。
料库的标识:标识主要分两类:一类是对文本的性质和特征进行标识,另一类是对文本中的符号、格式等进行标识。如CLEC语料库标注了以下主要信息,包括学生类型、性别、累计学习年限、自然年龄、作文完成方式、是否是用词典、作文类型、所在学校、作文得分、作文标题、大学英语四、六级试卷作文编码。第一类标识是必要的,因为它们可以用来对文本进行必要的分类,为灵活提取文本进行各类目的业务需求提供便利,而且它们可以标注在文本开头或者作为另一个文件保存,丝毫不破坏语料的完整性和原始性。至于第二类标识可以视业务领域和应用的目的而定。以上实施例都需要保存一份未标识的原文本。
赋码:当前,语料库的赋码主要有两类:一类是词类码,又称语法码;另一类是句法码。
词类赋码就是对文本中每一个词标注词类属性,这项工作通常是在传统语法对词类的划分的基础上进行的,只是分类适应要求做得更细。如在LOB语料库中以NN代表普通名词的单数形式,以NNP代表以大写字母开头的普通名词的单数形式,如Englishman,以NNS代表普通名词的复数形式,如desks,以VB代表动词的基本形式,如write、see,以VBD代表动词的过去式,如wrote、saw,以VBG代表动词的现在分词形式,如reading、eating,以VBN代表动词的过去分词形式,如written、seen,等等。目前自动词类赋码技术已经基本成熟,对英语基本上可以通过计算机自动赋码,且赋码正确率在96%—97%左右。
句法赋码就是对文本中的每一个句子进行句法标注。以UCREL概率句法赋码系统为例,其句法赋码系统分三个步骤:第一步,对文本中每一个词赋以可能的句法码。该步骤主要依赖于一部标明每一可能词类码对子的句法符的词典。第二步,寻找一些特殊的语法码形式和句法片断,对句法结构作必要的修改。最后,完成每一可能的句法分析,并逐一赋值,从中选出可能性最大,即值最大的句法分析作为每句的分析结果。
本实施例提供一种领域语料库构建方法,如图1所示,包括如下步骤:术语发现步骤:在自然语料库中提取与领域相关的术语;自然语料库为现有的大语料库,如清华大学中文语料库,里面包含有语料分类,可以提取包含有业务领域关键字的分类的语料,这样可以降低语料库的大小。而后是概念发现步骤:从与领域相关的公文、单据和报告中,提取与领域有关的术语;与领域相关的公文、单据和报告可以从与领域有关的公司的办公系统内获取相关的材料。单据等可以通过OCR扫描识别的方式转换为文字而后再获取与领域有关的术语。与领域有关的术语可以是通过分词后,在不同文档(公文、单据或报告)多次出现的词汇,次数可以预先设定。
短语发现步骤:从预设的大规模文档(可以是上述的与领域相关的公文、单据和报告,也可以是与领域有关的其他材料,如报道、新闻等)中采用监督机器学习算法或半监督机器学习算法获取可以表达概念的短语集合,短语集合包含有短语。概念归类步骤:对短语集合的短语进行归类,将归类后的短语和提取后的术语作为语料库的语料存到数据库中。
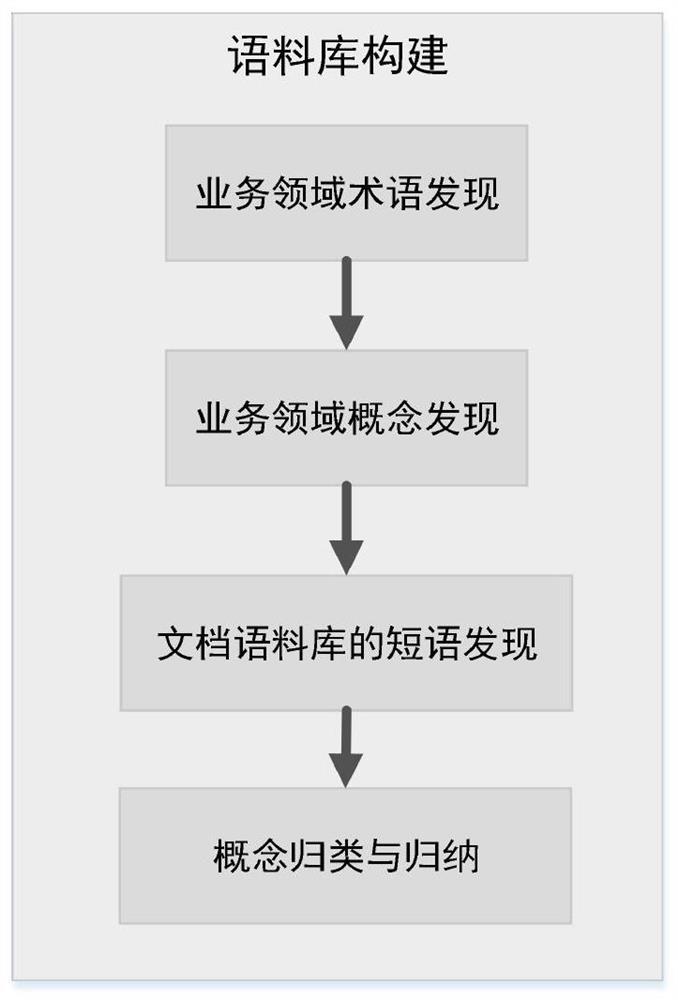
以业务领域为电力业务领域进行举例说明,本发明可以构建面向电力业务领域的语料库,包括电力领域的术语发现、面向电力领域的概念发现、电力领域文档语料库的短语发现及概念的归类和归纳四个步骤。
1)电力领域的术语发现步骤
术语是指在特定专业领域中一般概念的指称。面向电力这个垂直领域中,不经过处理的原始语料进行词一级的分析时,未登录词是一个很大的问题。其中未登录词大多是该领域的术语,因此术语发现是一个需要迫切解决的问题。术语首先必须作为一个完整的语言单位出现,它必须具有出现频繁、结合紧密和使用自由的特点。其次术语作为专业领域中的一般概念,本身还应该有很强的领域性。术语提取的主要任务就是通过综合考察术语的上述特征,从待处理语料中提取出术语来。术语提取是自然语言处理的主要内容之一,在信息检索、信息提取、数据挖掘等领域都有广泛的应用。
术语提取的过程主要可以分为两个步骤:第一是判断一个符号串是否一个完整的语言单位;第二是判断这个语言单位是否特定领域的一般概念,即是否术语。我们可以将第一个步骤称为单元度的计算,第二个步骤称为领域度的计算。
在单元度的计算方面,一般是通过统计或者规则的方法来实现单元度的计算。基本思路是首先选取N元语法模型,以N为单位对原始语料进行统计,得到语料串的位置、频率和共现信息,再利用互信息、最大似然估计、X2等方法来对统计得到的信息进行计算,并进行排序得到初步的术语候选。在此基础之上,加入适当的知识和规则,对处理结果进行过滤,最终得到作为完整语法单位出现的术语候选。
术语提取的第一阶段单元度计算的可以采用现有的单元度计算方式,现有的单元度计算方式无论是在算法的效果还是效率等方面,都已经取得了较为令人满意的结果。然而单元度是从语言完整性的角度来判定一个字符串是否完整的语言单位,还不能作为衡量是否术语的唯一指标。在电力领域语料中,一个完整的语言单位不一定是一个领域术语。因此在满足单元度的基础上,我们需要从领域度的角度进一步考察。
与术语领域度计算相关的工作主要有利用信息检索领域广泛采用的TF-IDF方法以及香港城市大学揭春雨博士提出的rank相减方法等。TF-IDF的基本原则是一个词语是否术语的可能性正比于它出现的频率,反比于它出现的文档数。针对每一个语言单位,统计其出现的频率和出现的文档数,作为衡量是否术语的要素。而揭博士提出的rank相减的基本思想则是词汇在不同领域语料中的rank值相差越大,说明词汇的领域性越强。对于在不同领域中出现的相同词汇,计算待处理语料和背景语料中的rank之差,并进行排序则得到候选术语列表。本发明通过综合利用领域部件信息和领域语料库的分类信息,借助机器学习方法探索了领域度的计算方法。最终实现单元度和领域度相结合的术语自动提取。
2)面向电力领域的概念发现步骤
在项目实施中,本发明首先从公司协同办公系统中的大量公文,调度和运检业务中的工单票据及巡检报告等类型的电力文,收集整理,并选用一定的格式对文档不同粒度的文本表示加上适当的标签,这个语料我们称为领域文档语料库。由于领域概念通常在文本中以短语形式出现,根据该领域论文库发现概念短语以及短语间的关系,存储在电力领域知识库中。
3)电力领域文档语料库的短语发现步骤
短语是概念的表现形式,关键在于如何准确地从领域语料库中获取能表达概念的短语。借鉴信息提取中的实体、事件和关系等概念,本发明主要基于发现表达实体和事件的名词短语和动词短语。目前已有一些短语获取的基础,如组块分析技术、关键词识别技术。结合科技文献的特点,从大规模文档中获取各种结构和语言特征,采用监督机器学习(如SVM(支持向量机算法)、
4)概念的归类和归纳步骤
获得概念短语之后,本发明实现对短语进行归纳分类,希望把每个短语归入某种概念类型,其中给出的可能概念类型,如Method,Data,Event,Process等,这些类型需要和领域专家进一步进行确定。面对新的领域,目前没有一套成型的概念结构定义,本发明采用聚类技术对概念短语进行聚类,并加以人工干预对概念类型进行命名。实体概念和事件概念直接出现在文本中,而实体与实体之间的关系隐含在文本之后,关系也可以看做一种概念,本发明在实体和事件概念归类之后,制定一些利用概念类型的规则,对关系概念进行归类,再加以人工调整。获得实体、事件、关系类型框架之后,对于新的语料进行信息提取时,只需要按照分类任务进行,可以参考传统信息抽取的命名实体识别、事件识别和关系识别的方法和技术。具体地,所述概念归类步骤还包括:根据预设的基于概念归类规则的正则表达式,对短语进行归类。首先预设好不同类别的不同的正则表达式,对于符合该表达式的短语,则将其归到该类别。则所述语料包括短语和每个短语对应的类别。
通过语料库的语料,可以用于文档的分类。如上述的公文、单据和报告。由于对应的不同的文档具有不同的短语以及短语类别,则对于一个输入的文档,如果具有多个语料,而后根据语料中短语的类别(文档领域),就可以对文档进行分类。实现高效的文档分类。而后分类后的文档可以进一步提取其中的短语和类别,扩充领域语料,又可以自动提高扩充的效率和准确程度。
本发明还提供领域语料库构建系统,包括存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。本实施例的存储介质可以是设置在电子设备中的存储介质,电子设备可以读取存储介质的内容并实现本发明的效果。存储介质还可以是单独的存储介质,将该存储介质与电子设备连接,电子设备就可以读取存储介质里的内容并实现本发明的方法步骤。
需要说明的是,尽管在本文中已经对上述各实施例进行了描述,但并非因此限制本发明的专利保护范围。因此,基于本发明的创新理念,对本文所述实施例进行的变更和修改,或利用本发明说明书及附图内容所作的等效结构或等效流程变换,直接或间接地将以上技术方案运用在其他相关的技术领域,均包括在本发明的专利保护范围之内。
- 用于根据通用领域语料库来创建领域特异性训练语料库的方法和系统
- 一种基于实体迭代的领域实体标注语料库构建方法