检索装置、检索方法、及记录介质
文献发布时间:2023-06-19 10:19:37
技术领域
本发明涉及检索装置、检索方法、及记录介质。
背景技术
一般而言,在电子辞典中登记多个词条,针对各词条的每一个,将包括单词的含义等在内的词义信息建立对应并加以存储。通常,一个词条中存储有至少一个词义信息。再有,根据词条,有时会存储多个词义信息。例如,在普通的英日辞典中,针对词条“run”,与100个以上的词义所对应的词义信息被建立对应并加以存储。
在词条所对应的词义有多个的情况下,用户需要通过参照词义信息所包含的含义的图例或包括词条的单词的用例(例文),从而从作为检索结果被显示的多个词义中判别欲知晓的含义的词义。然而,如前述在有较多词义信息的情况下,确定欲知晓的含义的词义变得困难起来。特别是,为了基于用例来判别词义,必须阅读与多个词义分别对应的用例,否则不能简单地确定欲知晓的含义的词义。
在现有技术中,公知能够确定文章中所使用的单词的词义的自然语言处理装置(例如,参照专利文献1)。自然语言处理装置在从多个词义中确定文章所包含的单词的含义的情况下,显示表征单词所具有多个词义的多个单词或词义,通过与用户的对话式处理来指定与文章最相符的词义。在自然语言处理装置中,虽然可参考所显示的多个单词或词义来指定词义,但必须在确认了多个单词或词义的基础上指定最相符的词义。
[专利文献1]日本特开平4-130577号公报
这样,在现有技术中不能够从词条所对应的多个词义简单地确定欲知晓的含义的词义。
发明内容
本发明是考虑到上述那样的课题而进行的,其目的在于,提供一种能够从与一个词条对应的多个词义信息中简单地确定所需要的特定的词义信息的检索装置、检索方法。
本发明的一方式涉及一种检索装置,具有控制部,所述控制部在单词以及包括所述单词的文章数据已被指定的情况下,基于辞典数据来确定包括所述单词的多个用例,对被确定的所述多个用例各自的语法和所述文章数据的语法进行比较,基于所述语法的比较结果,对所述多个用例所涉及的信息的输出进行控制。
本发明的另一方式涉及一种检索方法,检索装置在单词以及包括所述单词的文章数据已被指定的情况下,基于辞典数据来确定包括所述单词的多个用例,对被确定的所述多个用例各自的语法和所述文章数据的语法进行比较,基于所述语法的比较结果,对所述多个用例所涉及的信息的输出进行控制。
本发明的又一方式涉及一种记录介质,记录了用于使计算机作为控制部发挥功能的程序,所述控制部在单词以及包括所述单词的文章数据已被指定的情况下,基于辞典数据来确定包括所述单词的多个用例,对被确定的所述多个用例各自的语法和所述文章数据的语法进行比较,基于所述语法的比较结果,对所述多个用例所涉及的信息的输出进行控制。
附图说明
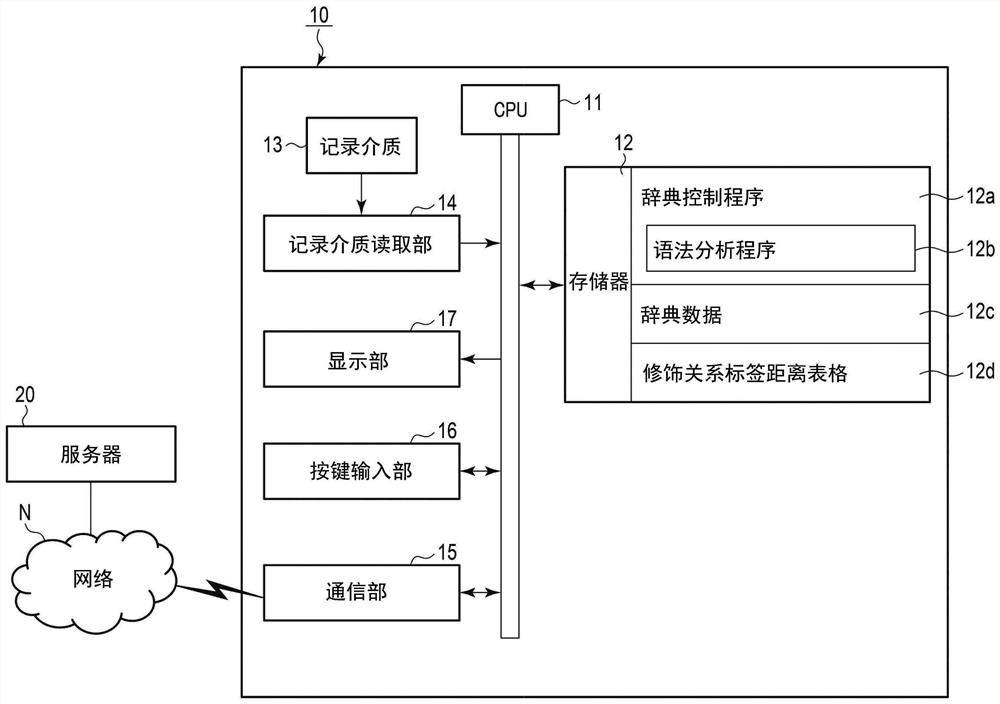
图1是表示本发明的实施方式所涉及的检索装置的电子电路的结构的功能框图。
图2是表示本实施方式中的电子辞典的外观结构的主视图。
图3是表示本实施方式中的被登记于辞典数据的信息的一例的图。
图4是表示本实施方式中的电子辞典进行的辞典控制处理的流程图。
图5是表示本实施方式中的电子辞典进行的辞典控制处理的流程图。
图6是表示检索字输入画面的一例的图。
图7是表示文章显示画面的一例的图。
图8是表示通过语法分析来检测的修饰关系的一例的图。
图9是表示通过语法分析处理而生成的语法树的一例的图。
图10是表示修饰关系标签距离集的一例的图。
图11是表示共用关系标签的一例的图。
图12是表示共用关系标签的合计的一例的图。
图13是表示与输入文章所对应的修饰目标关系标签及修饰源关系标签对应的距离的图。
图14是表示与用例所对应的修饰目标关系标签及修饰源关系标签对应的距离的图。
图15是表示共用关系标签所对应的距离的合计的一例的图。
图16是表示本实施方式中的电子辞典进行的辞典控制处理的变形例的流程图。
图17是表示修饰标签表格的一例的图。
图18是表示共用关系标签的一例的图。
具体实施方式
以下,根据附图对本发明的实施方式进行说明。
图1是表示本发明的实施方式所涉及的检索装置的电子电路的结构的功能框图。
在本实施方式中,表示将检索装置例如构成为电子辞典10的示例。需要说明的是,检索装置除了电子辞典10之外,还能够通过个人计算机、智能手机、平板PC等的各种电子设备来实现。
电子辞典10将与设为多个词条的单词分别对应的至少一个词义涉及的信息作为辞典数据来记录。辞典数据中包括用例(例文),其将词义所对应的词条的单词包括在内。电子辞典10具有通过输入指定词条的字符串(单词)而对将词条所对应的词义等包括在内的信息进行检索的检索功能。在电子辞典10所具有的检索功能中,不只是设为指定词条的检索字的字符串(单词),还能够通过输入将字符串(单词)包括在内的文章来执行检索。电子辞典10基于针对将作为检索对象而被输入的单词包括在内的文章的语法分析结果(第一语法分析信息)和针对预先登记的多个词义的每一个所对应的用例的语法分析结果(第二语法分析信息)的类似度,来确定检索字(单词)所对应的词义。
电子辞典10具有读取各种记录介质所记录的程序、或者被传输的程序,并根据该读取的程序来控制动作的计算机的结构,其电子电路中,具备CPU(central processingunit)11。
CPU11作为对电子辞典10的整体进行控制的控制部发挥功能。CPU11根据被预先存储在存储器12内的控制程序、或经由记录介质读取部14从ROM卡等的记录介质13被读入存储器12中的控制程序、或经由包括因特网等的网络N而从服务器20经由通信部15下载并被读入存储器12中的控制程序,对电路各部的动作进行控制。
根据来自按键输入部16的与用户操作相应的输入信号、来自触摸面板式显示部17的与用户操作相应的输入信号、或被外部连接的网络N上的服务器20的通信信号、或与经由记录介质读取部14而被连接的EEPROM(注册商标)、RAM、ROM等的外部记录介质13的连接通信信号,来启动存储器12所存储的控制程序。
在CPU11连接着存储器12、记录介质读取部14、通信部15、按键输入部16、触摸面板式显示部17等。
作为存储器12所存储的控制程序,存储有管理电子辞典10的整体动作的系统程序、用于与被外部连接的网络N上的服务器20、个人计算机等其他的电子设备进行数据通信的通信程序。再者,存储器12中存储辞典控制程序12a,其执行基于所输入的字符串来检索与词条对应的信息并输出的检索功能。辞典控制程序12a中包含针对文章数据执行语法分析的语法分析程序12b。
再有,存储器12中,存储有辞典数据12c、修饰关系标签距离表格12d等。
辞典数据12c中包含例如集录了英日辞典、日英辞典、英英辞典、国语辞典等的多个辞典的数据库。辞典数据12c中,按每个辞典而包含对各词条的每一个所对应的含义(词义)加以说明的词义信息。存在针对一个词条而存储多个词义信息的情况。还有,在词义信息中,设定表示与词条(单词)的词义相应的文章内的使用例的用例(参照图3)。需要说明的是,辞典数据12c也可以不内置于电子辞典10的主体,而是经由网络N从能存取的辞典数据库(例如,服务器20)取得。
修饰关系标签距离表格12d针对被登记在辞典数据12c中的各词条,存储表示针对一个词条的多个词义分别对应的用例的语法分析的结果的语法分析信息(第二语法分析信息)。修饰关系标签距离表格12d的语法分析信息被使用于与针对作为检索对象而与检索字一起被输入的文章的语法分析结果(第一语法分析信息)的类似度的判别。
作为语法分析的结果,例如包括:表示在词义所对应的用例中使用的词条的单词与用例中之外的单词的修饰关系的修饰种类(修饰关系标签);用例中的词条的单词与处于修饰关系的其他单词的距离。关于表示修饰关系的修饰种类(修饰关系标签)与单词间的距离的详细,将后述(参照图8~10)。
本实施方式中的语法分析信息的类似度,例如设为基于通过针对文章的语法分析而被提取的修饰种类(修饰关系标签)的一致数。即,设为越多具有相同的修饰种类(修饰关系标签),类似度就越高。进而,在有修饰种类(修饰关系标签)的一致数相同的多个语法分析信息(用例)的情况下,将处于修饰种类(修饰关系标签)一致的修饰关系的词条与其他单词的距离较小的情况判别为类似度高(需要说明的是,在处于修饰种类(修饰关系标签)一致的修饰关系的其他单词有多个的情况下,基于多个其他单词的每一个所对应的距离的合计进行判别)。
修饰关系标签距离表格12d中,例如针对与所有词条分别对应的各词义的用例,将表示修饰种类(修饰关系标签)及处于修饰关系的单词间的距离的修饰关系数据生成为“修饰关系标签距离集”并加以登记。“修饰关系标签距离集”针对词义所对应的一个用例而生成1个集合。进而,也可以不只是被登记在到辞典数据12c中的用例,也根据其他文章来生成修饰关系标签距离集,并登记于修饰关系标签距离表格12d。
需要说明的是,修饰关系标签距离表格12d并不是与辞典数据12c分开生成,也可以作为辞典数据12c的一部分来登记。再有,“修饰关系标签距离集”除了预先登记于辞典数据12c之外,也可以通过对与被登记到辞典数据12c的用例不同的文章执行构造分析处理而生成,并追加登记于修饰关系标签距离表格12d。该情况下,也可以将被登记到辞典数据12c的“修饰关系标签距离集”和被登记到修饰关系标签距离表格12d的“修饰关系标签距离集”合在一起来使用,以执行后述的辞典控制处理。
另外,修饰关系标签距离表格12d也可以不内置于电子辞典10的主体,经由网络N从能存取的辞典数据库(例如,服务器20)取得。
图2是表示电子辞典10的外观结构的主视图。
在图2中的电子辞典10的情况下,在被开闭的装置主体的下段侧内置CPU11、存储器12、记录介质读取部14、通信部15,并且设置按键输入部16,在上段侧设置触摸面板式显示部17。
按键输入部16中具备文字输入按键16a、能够选择各种辞典或各种功能的辞典选择按键16b、[翻译/决定]按键16c、[返回]按键16d、光标按键(上下左右按键)16e、电源按钮、除此以外的各种功能按键等。在触摸面板式显示部17,根据各种功能的执行来显示各种菜单、按钮17a等。
电子辞典10根据用户针对按键输入部16的操作、或针对显示部17所显示的菜单、按钮的触摸操作(基于笔尖或指尖),能够输入基于用户的指示。
对于这样构成的电子辞典10而言,CPU11依据辞典控制程序12a所描述的命令来控制电路各部的动作,软件与硬件配合进行动作,由此实现以下的动作说明所描述的功能。
图3是表示登记于辞典数据12c的信息的一例的图。
图3表示与设为词条的单词“catch”对应的词义信息。在设为词条的单词“catch”,登记有多个词义1、2、...所对应的词义信息。例如,在图3中,表示有将单词“catch”用作为动词时的词义1和用作为名词时的词义2的情况下的示例。另外,在图3中,表示将与词义1、2的每一个建立对应并利用词义的含义而使用了设为词条的单词“catch”的用例1、2被登记于辞典数据12c。
例如,表示作为将单词“catch”用作为动词时的词义1的用例,例如登记“Hecaught it all on video tape”;作为将单词“catch”用作为名词时的词义2的用例,例如登记“There must be a catch somewhere”。
接下来,对本实施方式中的电子辞典10的动作进行说明。
图4及图5是表示本实施方式中的电子辞典10进行的辞典控制处理的流程图。
若电源被接通,则CPU11启动辞典控制程序12a并开始辞典控制处理。CPU11使触摸面板式显示部17显示作为初始画面的主页画面(步骤S1)。主页画面中包含用于选择设为检索对象的辞典的菜单。在菜单中,能够选择设为检索对象的辞典。例如,作为设为检索对象的辞典,能够选择将所有辞典作为检索对象的、特定范围的辞典(例如,英语系辞典等)或特定的辞典(例如,○○英日辞典等)。
CPU11若在菜单中选择作为检索对象的辞典(步骤S2,是),则使触摸面板式显示部17显示设置了用于输入检索字(单词)的输入区域的检索字输入画面(步骤S3)。
图6是表示检索字输入画面D1的一例的图。如图6所示那样在,检索字输入画面D1,设置有用于输入设为检索字的字符串的输入区域AR11、用于输入文章的文章输入区域AR12、用于指示检索处理的执行的检索开始按钮B1。在本实施方式的电子辞典10中,为了检索被登记到辞典的词条(词义信息),不只是输入检索字(单词),还能够输入使用了检索字的文章。
在本实施方式的电子辞典10中,通过不只是输入检索字、还输入文章,从而能够检索与输入的文章相同地使用了检索字(单词)的用例所对应的词义。因此,即便是在一个词条设定有较多词义的情况下,用户也能基于用例容易地提取所需要的词义。需要说明的是,在针对不具有较多词义的检索字来进行辞典检索的情况下,也可以与普通的辞典检索同样地仅输入检索字来执行检索。
若通过文字输入按键16a的操作而输入设为检索字的字符串(单词),通过[翻译/决定]按键16c或检索开始按钮B1的操作而被指示检索的执行(步骤S4,是),则CPU11判别是否有向文章输入区域AR12的文章输入。在此,在并未与检索字一起输入文章的情况下(步骤S5,否),CPU11基于检索字,对设为检索对象的辞典的辞典数据执行检索处理(步骤S6)。即,CPU11从辞典数据12c检索与检索字相应的词条,从辞典数据12c读出与所检索出的词条对应的词义信息,并显示于触摸面板式显示部17中。
另一方面,在与检索字一起输入文章的情况下(步骤S5,是),CPU11判别所输入的文章是否已经执行完语法分析。例如,在电子辞典10中,针对被输入到文章输入区域AR12的文章而执行了后述的修饰关系分析处理(语法分析)的情况下,使存储器12存储处理完毕的文章与语法分析结果。CPU11判别被输入的文章是否存在于处理完毕的文章中,在判别为并不存在的情况下(步骤S16,否),执行针对被输入的文章的修饰关系分析处理(语法分析)(步骤S17)。另外,在针对被输入的文章执行完语法分析的情况下,CPU11执行使用了通过执行完毕的语法分析而被存储的语法分析结果的辞典检索(步骤S18~)。
需要说明的是,在前述的说明中,在检索字输入画面D1中,输入检索字与文章,但在其他方法中能够输入作为辞典检索的对象的检索字和文章。例如,CPU11在主页画面中指示了文章显示的情况下(步骤S11,是),例如使触摸面板式显示部17显示将与存储器12所存储的文本数据相应的文章包括在内的文章显示画面。
图7是表示文章显示画面D2的一例的图。如图7所示那样,在文章显示画面D2,除了显示文章的文章显示区域之外,还设置有用于指示检索处理的执行的检索开始按钮B2。
例如,在检测到针对文章显示区域的显示了文章的位置的触摸操作(基于笔尖或指尖的)的情况下,CPU11确定触摸位置所显示的单词(步骤S13),判别包括该单词的一篇文章的文本数据(步骤S14)。例如,在图7中,设为与单词“caught”W1相当的位置已被触摸。CPU11根据触摸位置来检测单词“caught”,提取将“caught”包括在内的一篇文章的文本数据“I caught the boy stealing fruit from our orchard.”。CPU11将通过触摸操作而被指定的单词“caught”作为检索字,将包括单词“caught”的文本数据“I caught the boystealing fruit from our orchard.”作为输入文章。由此,仅通过针对所显示的文章的触摸操作,就能够简单地输入检索字与文章并执行辞典检索。
在此,若通过[翻译/决定]按键16c或检索开始按钮B2的操作而被指示检索的执行(步骤S15,是),则CPU11与前述同样地判别被输入的文章是否存在于处理完毕的文章,在被判别为未存在的情况下(步骤S16,否),执行针对所输入的文章的修饰关系分析处理(语法分析)(步骤S17)。另一方面,在针对所输入的文章执行完语法分析的情况下,CPU11执行使用了通过执行完毕的语法分析而被存储的语法分析结果的辞典检索(步骤S18~)。
接下来,对图4所示的步骤S17中的修饰关系分析处理(语法分析)进行说明。
图8的(A)是表示针对输入文章的通过语法分析而被检测的修饰关系(修饰关系标签)的一例的图。图8的(B)、(C)是表示针对用例(图3所示的)的通过语法分析而被检测的修饰关系(修饰关系标签)的一例的图。需要说明的是,在语法分析处理中,作为使用现有的方法的处省略理,详细的说明。
在语法分析处理中,检测文章中的检索字所对应的单词(输入单词)和其他多个单词的修饰关系。修饰关系中存在与比文书中的输入单词靠前的其他单词(修饰目标单词)的关系以及与靠后的其他单词(修饰源单词)的关系,求取表示各个关系的关系标签。
例如,在图8的(A)所示的文章中,相对于输入单词“caught”,其他单词“I”成为修饰目标单词,求取关系标签“nsubj”(表示主语名词)。再者,相对于输入单词“caught”,其他单词“stealing”成为修饰源单词,求取关系标签“xcomp”(表示补足语)。
另外,在修饰关系分析处理中,确定从输入单词到其他单词的文章中的距离。在一篇文章中,单词间的距离较短的情况下,能够视为单词间的相关度较高。例如,图8的(A)所示的从输入单词“caught”到单词“I”的距离为“-1”,到单词“stealing”的距离为“3”。
需要说明的是,如前述,也可以单纯地对从输入单词到其他单词的单词数进行计数,设为距离,也能够利用语法分析结果来确定距。例如,执行语法分析处理,生成表征文章的语句构造的语法树,将语法树的枝数设为单词间的距离。由此,根据与单词间的修饰关系无关的、例如冠词等的单词的有无,虽然在单纯的单词数的计数值中会产生距离的变动,但通过将语法树的枝数设为距离,从而能够确定单词间的修饰关系所对应的距离。
例如,在文章“I have a pen.”中,从输入单词“have”到其他单词“pen”的单词数变成“2”。另一方面,在文本“I have pens.”中,从输入单词“have”到其他单词“pens”的单词数为“1”。即,无论是否为单词的用法相同的文章,根据相关语候补是单数形“pen”还是复数形“pens”的差异,会产生冠词的有无的差异。因此,在单纯地将到单词为止的单词数设为距离的情况下,即便单词间的修饰关系相同,距离也会发生变化。
图9是表示通过语法分析处理而生成的语法树的一例的图。图9的(A)表示前述的文章“I have a pen.”所对应的语法树,图9的(B)表示前述的文章“I have pens.”的语法树。
如图9的(A)所示那样,文章“I have a pen.”的输入单词“have”K2与其他单词“pen”T2之间的枝数为“5”。再者,如图9的(B)所示那样,文章“I have pens.”的输入单词“have”K3与其他单词“pens”T3之间的枝数为“5”。即,与文章中的冠词的有无无关,在相同构造的文章中,对于输入单词与其他单词的修饰关系相同的输入单词和其他单词而言,可确定为相同的距离。
如此,执行针对包括输入单词的文章的语法分析,将语法树的枝数设为单词间的距离,由此即便存在冠词等的有无的差异导致的文章的变动,也能够正确地确定单词间的位置关系(距离)。
接下来,对使用了语法分析结果的辞典检索进行说明。
CPU11基于检索字,对设为检索对象的辞典的辞典数据执行检索处理(步骤S18)。即,CPU11从辞典数据12c检索与检索字的单词的原形相应的词条,并提取被检索出的词条所对应的所有词义信息的用例(步骤S19)。
CPU11选择设为判别与输入文章的类似度的处理的对象且与词条对应的用例(步骤S20)。在此,在存在设为处理对象的用例的情况下(步骤S21,是),由于针对所有用例的处理并未结束,故CPU11移至针对选出的用例的处理。CPU11判别对选出的用例而言语法分析处理是否完毕。即,判别与用例对应的“修饰关系标签距离集”是否被登记于修饰关系标签距离表格12d。
CPU11在针对用例而言语法分析处理并未完毕的情况下(步骤S22,否),从辞典数据12c提取用例的文本数据(文章),执行修饰关系分析处理(语法分析)(步骤S24)。
修饰关系分析处理(语法分析)是与针对前述所输入的文章的修饰关系分析处理(语法分析)(步骤S17)同样地被执行。例如,在图3所示的用例1“He caught it all onvideo tape”的情况下,如图8的(B)所示那样,判别相当于词条“catch”的单词与其他单词的修饰关系和距离。同样地,在图3所示的用例2“There must be a catch somewhere”的情况下,如图8的(C)所示那样,判别修饰关系和距离。
在此,针对已被执行的语法分析的结果(“修饰关系标签距离集”),与词条的词义信息(用例)建立对应,并追加存储到修饰关系标签距离表格12d。由此,在相同的用例成为处理对象的情况下,利用处理完毕的“修饰关系标签距离集”,能够省略语法分析处理。
这样,在相对于用例而言语法分析处理并未完毕的情况下,由于在该时间点能执行修饰关系分析处理,故例如采取了对辞典数据12c能追加与词义对应的用例的结构的情况下,针对新被追加的用例也能够设为处理对象。
另一方面,在对于用例来说语法分析处理完毕的情况下(步骤S22,是),CPU11从修饰关系标签距离表格12d读出表示与用例对应的语法分析结果(第二语法分析信息)的修饰关系数据(“修饰关系标签距离集”),进行与所输入的文章的语法分析结果(第一语法分析信息)的类似度的判别。
图10是表示在修饰关系标签距离表格12d登记的“修饰关系标签距离集”的一例的图。在图10中,在与在辞典数据12c登记的一个词条对应的多个词义1、2、3...的每一个所对应的用例表示“修饰关系标签距离集”。在图10中,分别表示关于词义1、3而针对一个词义设定多个用例、关于词义2而设定一个用例的情况。因此,关于词义1、3,登记与多个用例的每一个对应的多个“修饰关系标签距离集”。
例如,在词义1中有多个用例1、2、3...,与多个用例1、2、3...建立对应而分别存储“修饰关系标签距离集”。
在词义1的与用例1对应的“修饰关系标签距离集”中,包含:表示同用例1中的词条的单词与修饰目标单词的修饰关系的关系标签“advmod”“aux”“nsubj”“dobj”分别对应的距离“-3”“-2”“-1”“1”;及同表示与修饰源单词的修饰关系的关系标签“root”对应的距离“0”。
这样,如果预先在修饰关系标签距离表格12d登记与用例对应的语法分析结果(“修饰关系标签距离集”),那么没有必要每当输入检索字与文章数据就执行针对用例的修饰关系分析处理,因此能够实现检索时间的缩短和精度的提高。
CPU11若取得关于设为处理对象的用例的“修饰关系标签距离集”,则针对输入文章与用例的修饰目标关系标签和修饰源关系标签的每一个,判别共用的关系标签(共用关系标签),求取共用关系标签的合计(步骤S25)。
在图11表示共用关系标签的一例。图11的(A)表示与输入文章对应的修饰目标关系标签和修饰源关系标签,图11的(B1)表示与图3所示的用例1对应的修饰目标关系标签和修饰源关系标签,图11的(C1)表示与图3所示的用例2对应的修饰目标关系标签和修饰源关系标签。
如图11的(B2)所示那样,对于输入文章与用例1的修饰目标关系标签而言,共用两个关系标签“nsubj”“dobj”,对于输入文章与用例1的修饰源关系标签而言共用1个“root”,分别被判别为共用关系标签。因此,关于用例1,如图12所示那样,共用关系标签的合计被求取为“3”。
另一方面,如图11的(C2)所示那样,在输入文章与用例2的修饰目标关系标签和修饰源关系标签中并不存在共用关系标签。即,相对于词条的单词被用作为动词的输入文章而言,在与动词的词义对应的用例1中存在共用关系标签,但在与名词的词义对应的用例2中并不存在共用关系标签。如此,根据词条的词义来利用用例的语法构造不同的状况,基于共用关系标签,能够提高类似度高的用例1的优先级而降低用例2的优先级(或从检索对象中除去)。
接下来,CPU11分别求取修饰目标关系标签的共用关系标签所对应的距离和修饰源关系标签的共用关系标签所对应的距离之差的合计,将修饰目标关系标签与修饰源关系标签所分别对应的合计值合计(步骤S26)。
图13中表示与输入文章所对应的修饰目标关系标签和修饰源关系标签的每一个对应的距离,图14表示与图3所示的用例1对应的修饰目标关系标签和修饰源关系标签的每一个所对应的距离。输入文章与用例1的共用关系标签,如前述,对于修饰目标关系标签来说共用关系标签“nsubj”“dobj”,对于修饰源关系标签而言共用“root”。
输入文章的共用关系标签“nsubj”所对应的距离为“-1”,用例1的共用关系标签“nsubj”所对应的距离为“-1”,因此关于共用关系标签“nsubj”的距离之差,为“-1-(-1)=0”。同样地,关于共用关系标签“dobj”的距离之差,为“2-1=1”。同样地,共用关系标签“root”所对应的距离为“2-2=0”。因此,如图15所示那样,针对用例1的修饰目标关系标签与修饰源关系标签分别对应的合计值为“1”。
CPU11使共用关系标签的个数的合计与距离的合计和设为处理对象的用例建立对应并存储于存储器12(步骤S27)。
以下,同样地,CPU11选择词条所对应的接下来设为处理对象的1个用例(步骤S20),执行前述的处理,求取共用关系标签的个数的合计与距离的合计,与用例建立对应后存储于存储器12(步骤S21~S27)。
若关于所有用例的处理结束(步骤S21,否),则CPU11执行判别针对输入文章的语法分析的结果(第一语法分析信息)和包括通过针对各用例的语法分析而被存储的共用关系标签的个数的合计与距离的合计的语法分析的结果(第二语法分析信息)的类似度的处理(步骤S40)。
首先,CPU11选择共用关系标签的个数的合计最多的用例(词义)(步骤S28)。即,确定语法分析信息的类似度最高的、输入文章与语法构造最一致的用例。
需要说明的是,在共用关系标签的个数的合计相同的用例有多个的情况下(步骤S29,是),CPU11将共用关系标签的距离的合计最小的用例判别为类似度高的用例并加以选择(步骤S30)。处于与共用关系标签相应的修饰关系的其他单词和词条所对应的单词的相关度越高,则共用关系标签的距离的合计越变小。由此,通过选择共用关系标签的距离的合计最小的用例,从而处于修饰关系的词条的单词与其他单词的使用方式,容易确定与输入文章更近的用例。
若判别输入文章与各用例的类似度,则CPU11基于类似的判别结果,针对各用例或者与各用例对应的词义决定优先级并控制输出。即,CPU11使类似度最高的用例最优先(上位),关于除此以外的用例,基于共用关系标签的个数的合计而将用例(词义)降序排序(步骤S31)。即,按照与输入文章的类似度高的顺序将多个用例排序,决定优先级。
再有,在共用关系标签的个数的合计相同的用例有多个的情况下,CPU11与前述同样地,分别求取各用例的共用关系标签所对应的距离的合计,基于距离的合计按升序排序(步骤S32)。由此,能够基于用例中的词条的单词与其他单词的相关度(距离),决定优先级。
CPU11根据优先级对基于共用关系标签决定了优先级的多个用例所对应的词义信息(用例、或者与用例对应的词义)进行排列,并使触摸面板式显示部17进行显示(步骤S33)。需要说明的是,关于没有共用关系标签的用例所对应的词义,也可以从显示对象刨除。
这样一来,在本实施方式中的电子辞典10中,不只是设为指定词条的检索字的字符串(单词),也输入包括字符串(单词)的文章,由此能够使设定了与输入文章接近的用例的词义信息优先并作为检索结果来显示。即,即便设相对于一个词条而存在多个词义,也能基于输入文章与词义所对应的用例的语法分析结果的类似度来决定优先级,因此能够简单有效地获取用户欲知晓的词义。
需要说明的是,在前述的说明中,关于由用户输入的文章及用例,在电子辞典10中执行语法分析(修饰关系分析处理),但也可以对经由网络N而被连接的服务器20(云)发送并执行设为处理对象的数据。
(变形例)
接下来,对判别针对输入文章的语法分析的结果(第一语法分析信息)和针对各用例的语法分析的结果(第二语法分析信息)的类似度的处理的变形例进行说明。在前述的说明中,基于共用关系标签的个数的合计和距离的合计来判别类似度,但在变形例中,按每个共用关系标签(修饰关系标签)求取权重值,基于共用关系标签的权重值的合计来判别类似度。
在前述的使用共用关系标签的个数的合计的方法中,等效地对待所有种类的修饰关系标签,单纯地将一个修饰关系标签的个数设为1来进行合计。可是,根据词条、词条所包含的词义的不同,用例中所使用的修饰关系标签的出现频率的倾向也会不同。即,在使用了词条的文章中,根据词条,存在易于产生的修饰关系标签和难以产生的修饰关系标签。因而,按每个词条并基于修饰关系标签的出现频率,使用越是易于产生的修饰关系标签、值就越变大的权重值,由此即便在输入文章中易于产生的修饰关系标签和难以产生的修饰关系标签的数目相同,也可令使用易于产生的修饰关系标签的一方的词义优先而进行显示,实现精度的提高。
以下,对使用了基于权重值的合计来判别类似度的处理的辞典控制处理进行说明。需要说明的是,在该辞典控制处理中,执行图4所示的步骤S1~S19的处理和图5所示的步骤S20~S33所对应的图16所示的流程图的处理。在图16所示的流程图中,对执行图5所示的流程图同样的处理的部分赋予相同的附图标记。关于与使用了图4及图5的说明共用的部分将说明省略。
在基于共用关系标签的权重值的合计来判别类似度的情况下,针对修饰关系标签距离表格12d的所有词条的每一个,针对在词条所对应的各词义的用例中使用的修饰关系标签设定权重值。修饰关系标签的权重值如下这样计算。
图17表示登记有例如在词条“catch”所对应的各词义的用例中使用的修饰关系标签的修饰标签表格的一例。
在修饰标签表格中,设定在词条“catch”所对应的所有用例中使用的所有修饰关系标签,计算各修饰关系标签的频率。在本实施方式中,将在相同词条内的所有用例中使用的修饰关系标签之中最高的频率设为fmax。在图17所示的例子中,由于修饰关系标签“dobj”的频率“17”最高,故将修饰关系标签“dobj”的频率“17”设为fmax。而且,各修饰关系标签的权重值是将各个频率除以fmax(“17”)所得的值。
在图16所示的步骤S20中,CPU11选择设为判别与输入文章的类似度的处理的对象的、词条所对应的1个用例。在此,在有设为处理对象的用例的情况下(步骤S21,是),由于针对所有用例的处理并未结束,故CPU11移至针对选出的用例的处理。
在使用了图5的说明中,在选出的用例语法分析处理未完毕的情况下,虽然各个地执行修饰关系分析处理(语法分析),但在此针对语法分析处理未完毕的所有用例执行修饰关系分析处理,并将其处理结果反映到修饰标签表格,计算所有修饰关系标签的频率、权重值并进行设定。
若取得关于设为处理对象的用例的“修饰关系标签距离集”,在CPU11针对输入文章与用例的修饰目标关系标签及修饰源关系标签的每一个,判别共用的关系标签(共用关系标签),求取共用关系标签的权重值的合计(步骤S45)。
图18中表示前述图11所示的例子中的共用关系标签、各共用关系标签的权重值和合计值。即,表示在输入文章与用例1中有两个共用关系标签“nsubj”“dobj”,共用关系标签“nsubj”的权重值为“0.941176”,共用关系标签“dobj”的权重值为“1”。因此,关于用例1,共用关系标签的权重值的合计被求取为“1.941176”。
接下来,CPU11分别求取修饰目标关系标签的共用关系标签所对应的距离和修饰源关系标签的共用关系标签所对应的距离之差的合计,对修饰目标关系标签与修饰源关系标签所分别对应的合计值进行合计(步骤S26)。
CPU11将共用关系标签的权重值的合计与距离的合计同设为处理对象的用例建立对应并存储于存储器12(步骤S47)。
以下,同样地,CPU11选择词条所对应的接下来设为处理对象的1个用例(步骤S20),执行前述的处理,求取共用关系标签的权重值的合计和距离的合计,与用例建立对应并存储于存储器12(步骤S21~S47)。
若针对所有用例的处理结束(步骤S21,否),在CPU11执行对针对输入文章的语法分析的结果(第一语法分析信息)和将通过针对各用例的语法分析而被存储的共用关系标签的权重值的合计与距离的合计包括在内的语法分析的结果(第二语法分析信息)的类似度加以判别的处理(步骤S40)。
首先,CPU11选择共用关系标签的权重值的合计最大的用例(词义)(步骤S48)。即,确定语法分析信息的类似度最高且语法构造与输入文章最一致的用例。
需要说明的是,在共用关系标签的权重值的合计相同的用例有多个的情况下(步骤S29,是),CPU11将共用关系标签的距离的合计最小的用例判别为类似高的用例来选择(步骤S30)。
若判别输入文章与各用例的类似度,则CPU11基于类似的判别结果,针对各用例或者与各用例对应的词义决定优先级并控制输出。即,CPU11使类似度最高的用例最优先(上位),针对除此以外的用例,基于共用关系标签的权重值的合计将用例(词义)按降序排序(步骤S51)。即,按照与输入文章的类似度高的顺序对多个用例进行排序,来决定优先级。
另外,在共用关系标签的权重值的合计相同的用例有多个的情况下,CPU11与前述同样地,分别求取各用例的共用关系标签所对应的距离的合计,基于距离的合计按升序排序(步骤S52)。由此,能够基于用例中的词条的单词与其他单词的相关度(距离),来决定优先级。
CPU11根据优先级将基于共用关系标签而决定了优先级的多个用例所对应的词义信息(用例,或者与用例对应的词义)加以排列,并使触摸面板式显示部17进行显示(步骤S33)。需要说明的是,也可以针对没有共用关系标签的用例所对应的词义,从显示对象中刨除。
这样一来,通过使用按每个词条并基于修饰关系标签的出现频率而计算出的、修饰关系标签的权重值,从而能够优先显示使用易于产生的修饰关系标签的词义。
需要说明的是,在前述的说明中,将各修饰关系标签的权重值设为各修饰关系标签的频率除以在相同词条内的所有用例中使用的修饰关系标签之中最高的频率fmax所得的值,只要越是易于产生的修饰关系标签就越变大的值,也可以通过其他方法来计算权重值。
再者,在使用图16的说明中,在共用关系标签的权重值的合计相同的用例(词义)有多个的情况下,基于共用关系标签的距离来决定优先度,但也能够将前述的使用了共用关系标签的个数、距离、权重值的判别任意地并加以实施。
还有,例如在共用关系标签的个数的合计相同的情况下,也可以让用户可选择进一步基于距离或权重值的哪一个来判别优先度。
需要说明的是,在前述的实施方式中,以英语系的辞典为例进行说明,但也能够将其他语系的辞典作为对象来实施。
另外,实施方式中记载的手法、即流程图所示的处理等的各手法,能够作为能使计算机执行的程序,储存于存储卡(ROM卡,RAM卡等)、磁盘(软盘,硬盘等)、光盘(CD-ROM,DVD等)、半导体存储器等的记录介质并进行发布。而且,计算机读入外部记录介质所记录的程序,利用该程序来控制动作,由此能够实现与实施方式中说明过的功能同样的处理。
此外,用于实现各手法的程序的数据,能够作为程序代码的方式在网络(因特网)上传输,也可以从被连接至该网络(因特网)的计算机(服务器装置等)获取程序数据,以实现与前述实施方式同样的功能。
需要说明的是,本申请发明未被限定于实施方式,能够在实施阶段在不脱离其主旨的范围内各种各样地进行变形。进而,实施方式中包含各种阶段的发明,通过所公开的多个结构要件中的适当组合能够提取各种发明。例如,在即便从实施方式所示的全部结构要件中将若干个结构要件删除,或将若干个的结构要件组合,也能解决“发明要解决的课题”一栏所描述的课题,能获得“发明效果”一栏所描述的效果的情况下,能够将该结构要件被删除或被组合的结构作为发明来提取。
- 信息检索装置、信息检索方法、信息检索程序及记录了信息检索程序的记录介质
- 信息检索装置、信息检索方法、信息检索系统、记录介质