一种适于多发多源火箭试验数据的数据融合方法及系统
文献发布时间:2023-06-19 10:19:37
技术领域
本发明涉及一种试验数据的数据处理方法,尤其涉及一种适于多发多源火箭试验数据的数据融合方法及系统,属于数据处理技术领域。
背景技术
数据融合的目的是把来自多个不同的数据库(源)的信息加以校准、联合、相关,合并成统一的表示形式,以获得精确的状态估计和综合评估,从而实现更加准确的识别和判断功能。对于火箭的诸多复杂系统,仅仅依靠单次单发的实验数据不能满足对部件、模块、系统的识别和控制的要求。若对不同次、不同发采集的数据单独、孤立地进行加工,不仅会导致数据处理工作量的剧增,而且割断了各个历史数据之间的有机联系,丢失数据有机组合蕴涵的特征,造成数据资源的浪费。要对多次多发多源的数据进行综合处理即进行数据融合,为数据挖掘提供规范数据,并在数据的特征层面和结果层面进行融合,从而得出更为准确、可靠的结论。
发明内容
本发明的目的在于克服现有技术的上述缺陷,提供一种适于多发多源火箭试验数据的数据融合方法,得到了高品质的有用信息,显著提高数据的可靠性与准确性,缩短了数据处理的时间。
本发明的另外一个目的在于提供一种适于多发多源火箭试验数据的数据融合系统。
本发明的上述目的主要是通过如下技术方案予以实现的:
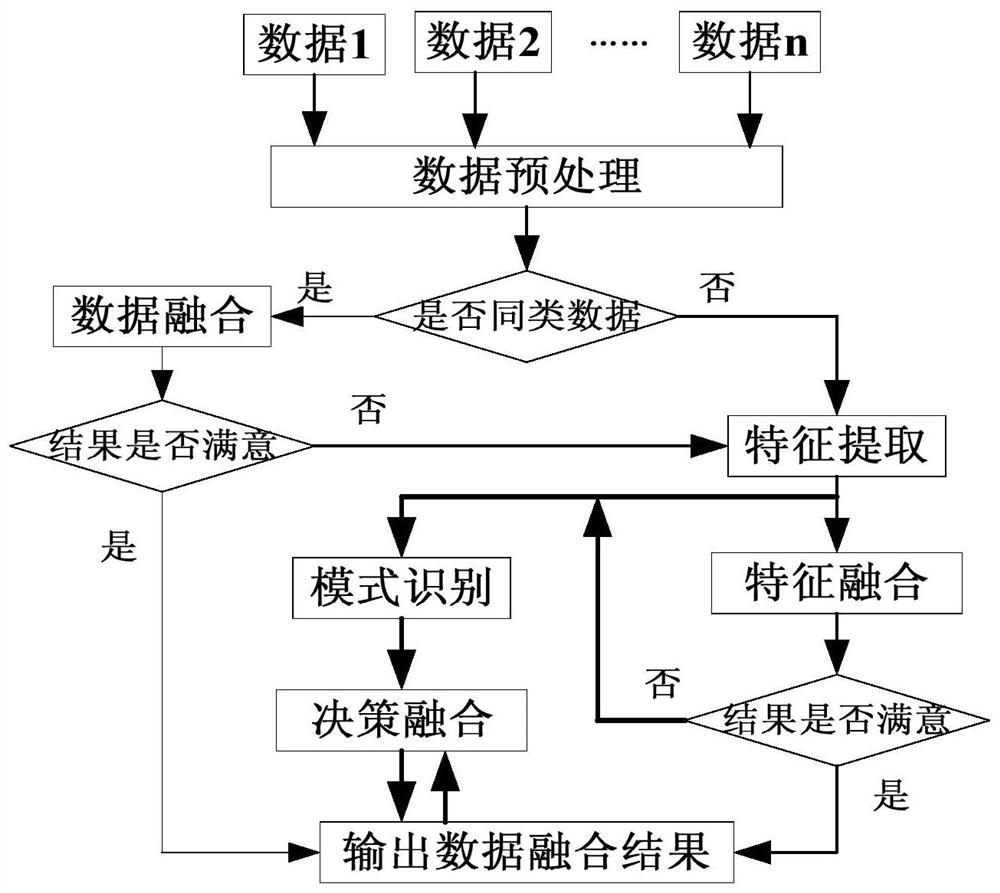
一种适于多发多源火箭试验数据的数据融合方法,包括如下步骤:
(1)、将包含不同部件、模块或系统的多次多发多源的火箭数据进行数据预处理;
(2)、判断预处理后的数据是否属于同类数据,若是,进入步骤(3);否则,进入步骤(4);
(3)、对所述预处理后的数据进行数据层融合,并判断融合结果是否满意,若满意则输出融合结果;否则,进入步骤(4);
(4)、对所述预处理后的数据或者数据层融合后的数据进行特征层融合,并判断融合结果是否满意,若满意则输出融合结果;否则,进入步骤(5);
(5)、对所述特征层融合后的数据进行决策层融合,并判断融合结果是否满意,若满意则输出融合结果;否则,重复步骤(5),直至融合结果满意。
在上述适于多发多源火箭试验数据的数据融合方法中,所述步骤(1)中对多次多发多源的火箭数据进行数据预处理,包括去除数据噪声和异常点,将不完整的数据补充完整或者对数据进行数据规约及规范化、离散化处理。
在上述适于多发多源火箭试验数据的数据融合方法中,所述步骤(2)中判断预处理后的数据是否属于同类数据,即将来自同一传感器的数据或者从不同传感器采集的同一信号的数据作为同类数据。
在上述适于多发多源火箭试验数据的数据融合方法中,所述步骤(3)中采用基于物理模型类的方法对与预处理后的数据进行数据层融合,具体方法如下:
(3.1)、输入需要融合的数据X
(3.2)、对数据进行一致性检验,根据传感器测量精度确定检验门限e,若满足公式|X
(3.3)、递推计算采样时刻k时的协方差函数R
(3.4)、根据所述协方差函数计算采样时刻k时的方差
(3.5)、根据所述方差
(3.6)、根据所述加权因子W
在上述适于多发多源火箭试验数据的数据融合方法中,所述步骤(4)中对所述预处理后的数据或者数据层融合后的数据进行特征层融合,具体包括采用基于参数类自编码器提取数据的特征,若提取的数据特征空间中存在强相关特征,则采用基于认知类模型的遗传算法进行强相关特征的选择,并利用基于参数类模型的模糊聚类方法生成新的特征,完成特征融合;若提取的数据特征空间中不存在强相关特征,则对提取的数据特征利用基于参数类模型的模糊聚类方法生成新的特征,完成特征融合。
在上述适于多发多源火箭试验数据的数据融合方法中,采用基于参数类自编码器提取数据的特征,即对数据进行压缩的具体方法如下:
(1)、在[0,1]上选取随机值设置权重初始值W
(2)、输入数据x=(x
in
计算隐含层到输出层,即解码过程:
in
得到实际输出结果y=(y
(3)、将步骤(2)中得到的结果与原始数据进行比较,得到损失:
其中:λ用来控制正则化的强度,在(0,1)之间取值,W=[W
(4)、根据步骤(2)中得到的损失不断更新W和b来优化网络,具体更新公式为:
其中α为更新率,取值范围为(0,1);
(5)、反复迭代至设定的迭代次数,所得到的编码结果out
在上述适于多发多源火箭试验数据的数据融合方法中,若提取的数据特征空间中存在强相关特征,则采用基于认知类模型的遗传算法进行强相关特征的选择的具体方法如下:
(1)、随机产生一个拥有n个染色体的种群X={x
(2)、用适应度函数
(3)、循环以下过程:
选择:依据种群中每个个体的适应度,按轮盘赌选择策略从中选择可以作为父本的个体,个体被选中的概率为:
其中:N为种群的个数;
交叉:将任意两个父本个体随机选择一个位置作为交叉点,交换交叉点之后的基因段,形成新的个体;
变异:随机改变某个体的基因值;
适应值计算:按照步骤(2)计算每个个体的适应度;
(4)、当终止条件成立,即达到最大预设的迭代次数或所选的特征子集满足要求,则循环结束;
(5)、选取末代种群中适应度最大的个体采用如下方法进行解码,得到强相关特征子集:
在上述适于多发多源火箭试验数据的数据融合方法中,对提取的数据特征或者选择的强相关特征利用基于参数类模型的模糊聚类方法生成新的特征的具体方法如下:
(1)、指定聚类类别数c(2≤c≤n),n为样本容量;确定模糊指标m;设定迭代停止阈值ε;设置迭代计数最大值1;初始化聚类中心矩阵P
(2)、更新隶属度矩阵U
(3)、根据
(4)、判定阈值,对于给定的阈值ε,如果||P
在迭代流程停止后,得到模糊聚类中心以及模糊划分矩阵参数的估计值,最后模糊聚类算法对样本x
按照聚类类别将数据划分为不同的类,即为生成新的特征的结果。
在上述适于多发多源火箭试验数据的数据融合方法中,所述步骤(1)中模糊指标m的取值为2;迭代停止阈值ε的取值在0.001至0.01之间。
在上述适于多发多源火箭试验数据的数据融合方法中,所述步骤(5)中对特征层融合后的数据进行决策层融合,即对特征提取后的数据进行模式识别,采用基于参数类模型的DS证据理论方法对数据进行处理并形成局部的决策,最后进行组合形成最终决策。
在上述适于多发多源火箭试验数据的数据融合方法中,采用基于参数类模型的DS证据理论方法对数据进行处理并形成局部的决策,最后进行组合形成最终决策的具体方法如下:
(1)、确定识别框架,输入不同传感器数据的识别结果,即各个命题的基本概率分配函数m
(2)、计算各个命题的信任函数
(3)、计算归一化常数
(4)、根据合成规则,按照下式重新计算组合后的概率分配函数、信任函数:
(5)、根据基于信任函数的决策规则,选择组合后信任函数值最大的证据作为判决结果,输出识别结果,即若:
Bel(A
则A
一种适于多发多源火箭试验数据的数据融合系统,包括数据预处理模块、数据层融合模块、特征层融合模块和决策层融合模块,其中:
数据预处理模块:将包含不同部件、模块或系统的多次多发多源的火箭数据进行数据预处理,并判断预处理后的数据是否属于同类数据,若属于同类数据,则将所述预处理后的数据发送至数据层融合模块:若不属于同类数据,则将所述预处理后的数据发送至特征层融合模块;
数据层融合模块:接收预处理模块发送的预处理后的数据,对所述预处理后的数据进行数据层融合,并判断融合结果是否满意,若满意则输出融合结果,若不满意,则将数据层融合后的数据发送至特征层融合模块;
特征层融合模块;对从数据预处理模块接收的预处理后的数据,或者从数据层融合模块接收的融合数据进行特征层融合,并判断融合结果是否满意,若满意则输出融合结果;若不满意,则将特征层融合后的数据再次进行特征层融合,重复直至融合结果满意。
本发明与现有技术相比的有益效果如下:
(1)、本发明针对多次多发多源数据融合中存在的问题,提供一种适于多发多源火箭试验数据的数据融合方法,得到了高品质的有用信息,提高了数据的可靠性与准确性,缩短了数据处理的时间。
(2)、本发明针对包含不同部件、模块和系统的多次多发多源的火箭数据,提出了一种具有三级融合(数据级+特征级+决策级)策略的数据处理方法,为高维复杂的多发火箭测试数据提供高效合理的数据融合策略。
(3)、本发明针对目前多源数据融合处理中易丢失数据有机组合蕴含的特征,提出了一种囊括不同算法模型(物理类、参数类、认识类)的数据融合框架,为火箭数据实现准确的识别与判断奠定了基础。
(4)、本发明针对复杂系统数据,从数据综合到数据加工再到融合输出过程提出了一种“算法+模型”优化组合的多源数据融合流程,为形成高品质的规范数据提供具体实施途径。
附图说明
图1为本发明适于多发多源火箭试验数据的数据融合方法流程图;
图2为本发明的模型与算法关系图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细的描述:
如图1所示为本发明适于多发多源火箭试验数据的数据融合方法流程图,由图可知本发明适于多发多源火箭试验数据的数据融合方法具体包括如下步骤:
步骤(一)、将包含不同部件、模块或系统的多次多发多源的火箭数据进行数据预处理,为了数据便于融合,首先将数据进行预处理。利用现有常用的方法和软件去除数据中的异常点与噪声,对缺失的数据进行补齐,相应数据完成数据规约及规范化、离散化处理。
步骤(二)、判断预处理后的数据是否属于同类数据,若是,进入步骤(3);否则,进入步骤(4);本发明中将来自同一传感器的数据或者从不同传感器采集的同一信号的数据作为同类数据。
步骤(三)、对所述预处理后的数据进行数据层融合,并判断融合结果是否满意,若满意则输出融合结果;否则,进入步骤(四);
本发明一可选实施例中,采用基于物理模型类的方法对与预处理后的数据进行数据层融合,具体方法如下:
(3.1)、输入需要融合的数据X
(3.2)、对数据进行检验,根据测量精度确定检验门限e,若满足公式|X
(3.3)、递推计算采样时刻k时的协方差函数R
(3.4)、根据所述协方差函数计算采样时刻k时的方差
(3.5)、根据所述方差
(3.6)、根据所述加权因子W
步骤(四)、对所述预处理后的数据或者数据层融合后的数据进行特征层融合,并判断融合结果是否满意,若满意则输出融合结果;否则,进入步骤(五);
本发明一可选实施例中对所述预处理后的数据或者数据层融合后的数据进行特征层融合,具体包括采用基于参数类自编码器提取数据的特征,若提取的数据特征空间中存在强相关特征,则采用基于认知类模型的遗传算法进行强相关特征的选择,并利用基于参数类模型的模糊聚类方法生成新的特征,完成特征融合;若提取的数据特征空间中不存在强相关特征,则对提取的数据特征利用基于参数类模型的模糊聚类方法生成新的特征,完成特征融合。
(4.1)、其中采用基于参数类自编码器提取数据的特征,即对数据进行压缩的具体方法如下:
(1)、在[0,1]上选取随机值设置权重初始值W
(2)、输入数据x=(x
in
计算隐含层到输出层,即解码过程:
in
得到实际输出结果y=(y
(3)、将步骤(2)中得到的结果与原始数据进行比较,得到损失:
其中:λ用来控制正则化的强度,在(0,1)之间取值,W=[W
(4)、根据步骤(2)中得到的损失不断更新W和b来优化网络,具体更新公式为:
其中α为更新率,取值范围为(0,1);
(5)、反复迭代至设定的迭代次数,所得到的编码结果out
(4.2)、若提取的数据特征空间中存在强相关特征,则采用基于认知类模型的遗传算法进行强相关特征的选择的具体方法如下:
(1)、按照数据融合所需解决问题的特点随机产生一个拥有n个染色体的种群X={x
(2)、用适应度函数
(3)、循环以下过程:
选择:依据种群中每个个体的适应度,按轮盘赌选择策略从中选择可以作为父本的个体,个体被选中的概率为
其中
交叉:将任意两个父本个体按照一定的概率随机选择一个位置作为交叉点,交换交叉点之后的基因段,形成新的个体;
变异:按一定的概率随机改变某个体的基因值;
适应值计算:按照(2)计算每个个体的适应度;
(4)、当终止条件成立,即达到最大预设的迭代次数或所选的特征子集满足要求,则循环结束;
(5)、选取末代种群中适应度最大的个体采用基于参数类自编码器方法中步骤(2)的解码过程进行解码,得到强相关特征子集。即如下公式进行解码:
(4.3)、对提取的数据特征或者选择的强相关特征利用基于参数类模型的模糊聚类方法生成新的特征的具体方法如下:
(1)、指定聚类类别数c(2≤c≤n),n为样本容量;确定模糊指标m,取值为2;设定迭代停止阈值ε,ε在0.001至0.01之间取值;设置迭代计数最大值1;初始化聚类中心矩阵P
(2)、更新隶属度矩阵U
(3)、根据
(4)、判定阈值,对于给定的阈值ε,如果||P
在迭代流程停止后,可以得到模糊聚类中心以及模糊划分矩阵参数的估计值,最后模糊聚类算法对样本x
按照聚类类别将数据划分为不同的类,即为生成新的特征的结果。
步骤(五)、对所述特征层融合后的数据进行决策层融合,并判断融合结果是否满意,若满意则输出融合结果;否则,重复步骤(五),直至融合结果满意。
本发明一可选实施例中,对特征层融合后的数据进行决策层融合,即对特征提取后的数据进行模式识别,采用基于参数类模型的DS证据理论方法对数据进行处理并形成局部的决策,最后进行组合形成最终决策。
其中,采用基于参数类模型的DS证据理论方法对数据进行处理并形成局部的决策,最后进行组合形成最终决策的具体方法如下:
(1)、确定识别框架,输入不同传感器数据的识别结果,即各个命题的基本概率分配函数m
(2)、计算各个命题的信任函数
(3)、计算归一化常数
(4)、根据合成规则,按照下式重新计算组合后的概率分配函数、信任函数。
(5)、根据基于信任函数的决策规则,选择组合后信任函数值最大的证据作为判决结果,输出识别结果,即若
Bel(A
则A
如图2所示为本发明的模型与算法关系图。
本发明一种适于多发多源火箭试验数据的数据融合系统,包括数据预处理模块、数据层融合模块、特征层融合模块和决策层融合模块,其中各个模块的功能如下:
数据预处理模块:将包含不同部件、模块或系统的多次多发多源的火箭数据进行数据预处理,并判断预处理后的数据是否属于同类数据,若属于同类数据,则将所述预处理后的数据发送至数据层融合模块:若不属于同类数据,则将所述预处理后的数据发送至特征层融合模块;
数据层融合模块:接收预处理模块发送的预处理后的数据,对所述预处理后的数据进行数据层融合,并判断融合结果是否满意,若满意则输出融合结果,若不满意,则将数据层融合后的数据发送至特征层融合模块;
特征层融合模块;对从数据预处理模块接收的预处理后的数据,或者从数据层融合模块接收的数据层融合后的数据进行特征层融合,并判断融合结果是否满意,若满意则输出融合结果;若不满意,则将特征层融合后的数据再次进行特征层融合,重复直至融合结果满意。
各个模块中具体实现方法参见上述对方法的描述,在此不再赘述。
本发明适于多发多源火箭试验数据的数据融合方法是由三个数据融合结构及相应结构下的数据融合算法组成的一套数据处理策略;
三个数据融合结构分别为数据层融合、特征层融合和决策层融合,其中数据层融合仅针对同类数据融合,对来自于传感器的原始数据或数据预处理之后的同类数据进行低水平层次的融合,融合后的数据尽可能的保存原始数据的特性;特征层融合主要从数据源中提取特征信息,进行综合处理和分析,它是一个中间层次的融合过程,为决策层融合提供决策依据;决策层融合主要针对具体决策目标,对特征提取后的数据进行识别与判断,是最高层次的融合。
数据层融合接收数据预处理后的同类数据,采用基于物理模型类的方法对数据进行融合,融合后的数据按照不同的特征进行提取,然后针对存在或关注的问题对有关联的特征进行识别,给出识别结果。
特征层融合接收数据预处理后的异类数据或数据层融合后的数据,按照不同的特征分别进行提取,采用基于参数类模型或认知类模型的方法对数据进行分析和处理以完成特征融合,然后针对存在或关注的问题对融合后的特征进行识别,给出识别结果。
决策层融合接收特征提取后的数据,针对存在或关注的问题识别出相关联的特征,得到初步的简单判断,然后采用基于参数类模型或认知类模型的方法对数据进行分析和处理,给出局部的初步决策结果,所有局部决策结果在某种规则下进行组合,以获得最终的联合决策结果。
以上所述,仅为本发明最佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
本发明说明书中未作详细描述的内容属于本领域专业技术人员的公知技术。
- 一种适于多发多源火箭试验数据的数据融合方法及系统
- 一种多源异构数据融合和量测数据多源互校验方法及系统