一种自适应多工况钢铁二次能源发生量动态预测方法
文献发布时间:2023-06-19 10:21:15
技术领域
本发明涉及钢铁能源预测技术领域,尤其涉及一种自适应多工况钢铁二次能源发生量动态预测方法。
背景技术
钢铁企业焦炉煤气生产过程复杂,配比好的气煤、肥煤、焦煤和瘦煤由炭化室推入焦炉,在燃烧室燃烧孔的加热和混合空气反应下生成反应物。经过规定的结焦时间,将反应物出焦,送至蓄热室进行熄焦操作,从而生成焦炉煤气这类二次热解产物。产出的焦炉煤气经煤气加压站混合加压后,参与球团、烧结、轧钢混合系统等生产环节外,附加协调热电联产发电过程。
由于焦炉煤气随生产节奏、流程操作、检修工况等实际情况影响瞬时波动大,煤气柜缓冲能力有限难以平衡短期激增或骤减的焦炉煤气发生量。而调度人员干预具有时滞性,科学预测煤气发生量是平稳调度的重要环节,准确预判煤气发生量变化有助于提前采取调度措施。因而,只有科学预测煤气发生量,是辅助调度人员平稳管控和减少放散煤气的重要手段。因此,设计多工况适应性强、预测性能稳定的方法成为企业煤气管理的主要任务。
目前,关于焦炉煤气预测国内外文献和专利的相关研究如下:
韩中洋等(一种钢铁煤气系统长期区间预测及其结构学习方法,申请号:201811060541.8)将高炉煤气、焦炉煤气发生量数据分割等长片段,对煤气系统建立多层次粒度模型,利用并行优化各层粒度模型,用蒙特卡洛方法调整模型参数结构,以提高模型对高炉煤气、焦炉煤气长期预测的精度;
杨靖辉等(基于人工智能的煤气系统优化调度方法,申请号201911299212.3)采用加权移动平均法、启发式与指数滑动相结合的方法对高炉煤气发生量、焦炉煤气发生量和转炉煤气发生量进行预判;
陈国香等(陈国香,张世伟,曾隽芳,等.RBF神经网络预测焦化企业煤气产量[J].化工自动化及仪表,2013,40(3):334-337.)将工艺中装煤量、挥发分、结焦时间作为径向基函数神经网络的主要影响参数,利用数据进行拟合训练,与反向传播神经网络的结果对比,该方法预测性能优于对比方法,对焦炉煤气实际平衡有重要预测价值;
刘继军等(刘继军,罗文进,张安洋.焦炉煤气产气量预测技术的研究与应用[J].冶金能源,2017(S1):48-50.)建立挥发物产量与焦炭产量的模型,将焦炉煤气化学发生过程热解反应近似用动力学模型替代,可根据结焦时间计算焦炉煤气产量,并介绍实际应用带来的显著经济效益;
在上述专利中,建立影响因素数据与煤气发生量正常工况模型的预测方法较多,对多工况的实际生产环境的焦炉煤气预测方法较少;在应用技术中,模型参数自适应及动态预测技术较少,仅模型参数拟合收敛实现长期预测将不能保证各种工况预测性能稳定。因而,模型参数随着动态环境更新有利于预测精度和性能的稳定,需要研发应对不同场景性能稳定的预测技术,为科学煤气调度提供预测数据支持。
发明内容
针对现有钢铁能源预测技术的局限性存在的问题,本发明提供了一种自适应多工况钢铁二次能源发生量动态预测方法,以实现焦炉煤气动态多工况预测应用的稳定、可靠、准确,并可自适应学习预测模型参数,给能源管理人员制定煤气调度计划提供科学数据支持,以降低能源放散,提髙精细化利用,稳定生产供应,降低能源成本。
本发明所采取的技术方案是:
一种自适应多工况钢铁二次能源发生量动态预测方法,包括以下步骤:
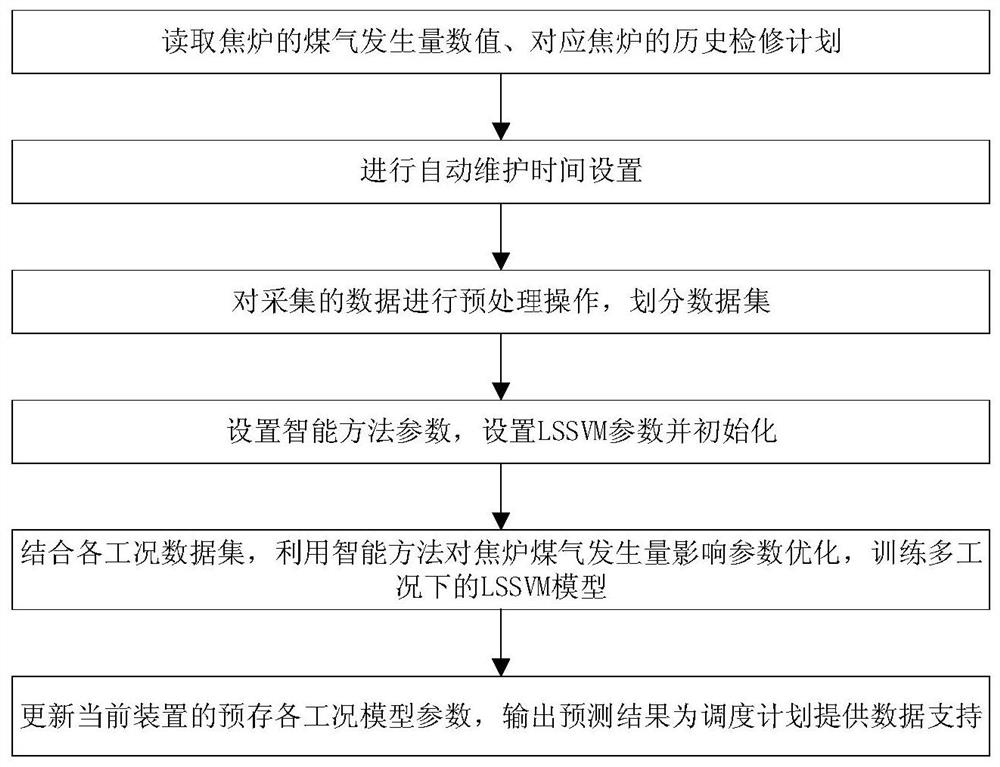
步骤1:获取多工况下焦炉煤气发生量历史数据;读取焦炉煤气发生量历史数据、焦炉的检修时间历史数据,保证时间步对齐的情况下,对焦炉煤气发生量数据进行工况标注,存入计算机的数据库;
步骤2:设定焦炉煤气发生量数据预处理时间间隔,读取系统时钟数据,达到时间间隔则进入下一步骤;
步骤3:对采集的焦炉煤气发生量数据进行预处理操作,并划分多工况数据集;
步骤3.1:对采集的焦炉煤气发生量数据进行数据去噪、清洗操作;
步骤3.2:对预处理过的数据进行归一化和标准化处理,并按照检修时间将数据集划分为正常工况数据集和检修数据集;
步骤3.3:按照炼焦过程的生产时序特点,对煤气发生量数据利用滑动窗口重建时序映射关系,构造出时序特征发生量数据,作为焦炉煤气发生量预测模型的输入变量的训练集;
步骤4:设置粒子群优化方法参数以及最小二乘支持向量机(Least squaressupport vector machine,LSSVM)参数,并对参数进行初始化;
所述粒子群优化方法参数包括焦炉煤气发生量预测模型参数优化的最大迭代次数N,最大允许连续未改进代数N
所述最小二乘支持向量机(Least squares support vector machine,LSSVM)参数,包括惩罚参数分量上下界γ
步骤5:使用多工况数据集,利用智能方法拟合时序数据中焦炉煤气发生量预测模型参数,所述预测模型参数包括LSSVM的惩罚系数和径向基函数(Radial basis function,RBF)中的核宽度,对参数进行并行优化,训练多工况下的LSSVM的模型参数,更新预测模型各工况参数;
步骤5.1:对粒子群算法的模型参数解集、个体最优参数解、全局最优参数解、精英参数解集初始化;
步骤5.1.1:对粒子群算法种群中模型参数解集、以及表征参数解的速度值随机生成可行解;
其中,按照参数解上下界,利用均匀分布产生随机数,生成初始参数可行解,按照参数解中惩罚系数和核宽度的上下界,同样按照均匀分布生成随机可行解。
步骤5.1.2:计算种群中模型各参数解对应的LSSVM模型,以及参数解的适应值;
步骤5.1.2.1:种群中的各参数解为一个可行解,根据参数解的数值,按照LSSVM如下的矩阵方程,利用高斯消去法算出实数列向量
式中
步骤5.1.2.2:针对系数矩阵的奇异性,做如下的规则设定:
如果系数矩阵奇异,无解,则参数解的适应值为1000000000;
如果系数矩阵非奇异,则参数解的适应值为预测拟合的均方误差;
步骤5.1.3:找出种群中模型参数解集的个体最优参数解,初始化全局最优参数解,初始化精英参数解集合;
其中,利用参数解集的适应值找出种群中的个体最好参数解,这里首次运算默认当前种群就是个体最好参数解集合pbest,将个体最好参数解设为全局最优参数解gbest。将种群中参数解集的适应值由从小到大排序,选取P
步骤5.2:根据设定的迭代训练条件,完成算法的迭代训练;
算法的迭代过程为优化LSSVM参数,实现种群朝向参数解适应值较小的方向进化,从而给出拟合的LSSVM参数,提高LSSVM预测结果的精度。
其中,设定的迭代训练判断条件如下:
如果单次迭代的运行时间大于设定的T
步骤5.2.1:按照实际煤气发生过程的预测特点和预测改进思路,将惯性权重w更新策略作如下调整;
其中,惯性权重的更新策略设置如下:
步骤5.2.2:按照改进的方法,更新种群中模型参数解集的速度值,引入精英参数解的学习,具体如下公式所示:
v
精英参数解的学习系数表示为c
步骤5.2.3:根据更新原则更新模型参数解集在可行域中的位置;
所述更新原则如下所示:
1)如果当前参数解的数值分量与速度值相加结果小于数值分量下界,并且速度值v
x
其中,x
2)如果当前参数解的数值分量与速度值相加结果小于数值分量下界,速度值小于0,再按照如下条件,进行数值分量的更新:
3)如果当前参数解的数值分量与速度值相加结果大于数值分量上界,速度值小于0,进行数值分量的更新:
x
4)如果当前参数解的数值分量与速度值相加结果大于数值分量上界,速度值大于0,再按照如下条件,进行数值分量的更新:
5)如果当前参数解的数值分量与速度值相加结果在数值分量的上下界范围内,则按照如下公式更新:
x
步骤5.2.4:计算模型参数解集中个体的适应值函数并更新个体最优参数解;
步骤5.2.5:找出当前所有模型参数最优参数解,更新模型参数全局最优参数解;
步骤5.2.6:用个体最优参数解更新模型参数精英参数解集合;
步骤5.2.7:对种群中达到设定更新次数的未改进参数解进行替换;
其中,从精英参数解集中随机取三个参数解中的数值求和取四分位数,代替未改进参数解的数值,对应参数解的速度值在速度上下界的范围内随机生成。
步骤5.3:训练过程结束,输出LSSVM的多工况模型,更新当前方法的预存各工况模型参数;
步骤6:识别工况完成焦炉煤气发生量预测,根据当前炼焦生产设备的检修信号,选择对应工况模型进行预测,将时序预测结果输出,为调度人员提供数据支持。
采用上述技术方案所产生的有益效果在于:
本发明提出一种自适应多工况钢铁二次能源发生量动态预测方法,采用多工况时序数据拟合影响焦炉煤气发生量的参数,训练发生量数据的LSSVM模型,结合方法的定时维护机制,实现快速精确、性能稳定、自适应多工况预测焦炉煤气发生量;针对经验设定参数的局限性,采用智能方法优化相关参数信息,得到更接近生产过程的LSSVM参数模型,提高整个方法的动态预测精度,缩短模型计算时间,保证动态预测技术的时效要求;为提高预测技术的稳定性,设计多工况的焦炉煤气预测模型;针对焦炉工况变化或检修带来的数据质量变动,导致普遍预测方法多工况应用的泛化误差大,本方法设置自适应更新机制,定时利用现有的数据完成各工况下模型参数的更新,确保模型参数的更新与当前生产工况同步。本方法满足焦炉煤气多工况预测的泛化、时效和精度要求,指导焦炉煤气供应,降低焦炉煤气的能源成本。
附图说明
图1为本发明一种自适应多工况焦炉煤气发生量的动态预测方法的流程图;
图2为本发明一种实施例的具体改进粒子群算法优化LSSVM参数的流程图;
图3为本发明一种检修工况实施例的预测结果对比图;
图4位本发明一种正常工况实施例的预测结果对比图。
具体实施方式
下面结合附图对本发明具体实施方式加以详细的说明。
一种自适应多工况钢铁二次能源发生量动态预测方法,如图1所示,包括以下步骤:
步骤1:获取多工况下焦炉煤气发生量历史数据;读取焦炉煤气发生量历史数据、焦炉的检修时间历史数据,保证时间步对齐的情况下,对焦炉煤气发生量数据进行工况标注,存入计算机的数据库;
步骤2:设定焦炉煤气发生量数据预处理时间间隔,读取系统时钟数据,达到时间间隔则进入下一步骤;
步骤3:对采集的焦炉煤气发生量数据进行预处理操作,并划分多工况数据集;
步骤3.1:对采集的焦炉煤气发生量数据进行数据去噪、清洗操作,规则如下:
1)如果在实时数据库默认采集间隔焦炉煤气发生量数据缺失,则使用前后数据的平均值替代;
2)如果在实时数据库默认采集间隔焦炉煤气历史发生量数据出现突然零值或者异常的噪声数据,则认为该异常数据为测量仪表飘零数据,并使用前后数据的平均值平滑替代;
3)按照预测的时间粒度要求,将历史数据做同等时间粒度处理;
步骤3.2:对预处理过的数据进行归一化和标准化处理,并按照检修时间将数据集划分为正常工况数据集和检修数据集;
1)如果在实时数据库默认采集间隔焦炉煤气发生量数据缺失,则使用前后数据的平均值替代;
2)如果在实时数据库默认采集间隔焦炉煤气历史发生量数据出现突然零值或者异常的噪声数据,则认为该异常数据为测量仪表飘零数据,并使用前后数据的平均值平滑替代;
3)按照预测的时间粒度要求,将历史数据做同等时间粒度处理;
步骤3.3:按照炼焦过程的生产时序特点,对煤气发生量数据利用滑动窗口重建时序映射关系,构造出时序特征发生量数据,作为焦炉煤气发生量预测模型的输入变量的训练集;
其中:
1)按照企业生产实际周期和延迟时限,设定生产时序数据对应的滑动窗口大小为M。考虑到预测的数据关联性,选取M的值为2-5倍的预测周期;
2)下述过程为滑动窗口的实例说明。根据生产中焦炉加热时间和经验推算,m列数据与第m+1列数据存在隐含的特征关系,将m列时序数据作为LSSVM中煤气发生量的输入特征向量,将第m+1列作为输出预测向量。
步骤4:设置粒子群优化方法参数以及最小二乘支持向量机(Least squaressupport vector machine,LSSVM)参数,并对参数进行初始化;
所述粒子群优化方法参数包括焦炉煤气发生量预测模型参数优化的最大迭代次数N,最大允许连续未改进代数N
所述最小二乘支持向量机(Least squares support vector machine,LSSVM)参数,包括惩罚参数分量上下界γ
步骤5:使用多工况数据集,利用智能方法拟合时序数据中焦炉煤气发生量预测模型参数,所述预测模型参数包括LSSVM的惩罚系数和径向基函数(Radial basis function,RBF)中的核宽度,对参数进行并行优化,训练多工况下的LSSVM的模型参数,更新预测模型各工况参数;
步骤5.1:对粒子群算法的模型参数解集、个体最优参数解、全局最优参数解、精英参数解集初始化;
步骤5.1.1:对粒子群算法种群中模型参数解集、以及表征参数解的速度值随机生成可行解;
其中,按照参数解上下界,利用均匀分布产生随机数,生成初始参数可行解,按照参数解中惩罚系数和核宽度的上下界,同样按照均匀分布生成随机可行解。
步骤5.1.2:计算种群中模型各参数解对应的LSSVM模型,以及参数解的适应值;
步骤5.1.2.1:种群中的各参数解为一个可行解,根据参数解的数值,按照LSSVM如下的矩阵方程,利用高斯消去法算出实数列向量
式中
步骤5.1.2.2:针对系数矩阵的奇异性,做如下的规则设定:
如果系数矩阵奇异,无解,则参数解的适应值为1000000000;
如果系数矩阵非奇异,则参数解的适应值为预测拟合的均方误差;
步骤5.1.3:找出种群中模型参数解集的个体最优参数解,初始化全局最优参数解,初始化精英参数解集合;
其中,利用参数解集的适应值找出种群中的个体最好参数解,这里首次运算默认当前种群就是个体最好参数解集合pbest,将个体最好参数解设为全局最优参数解gbest。将种群中参数解集的适应值由从小到大排序,选取P
步骤5.2:根据设定的迭代训练条件,完成算法的迭代训练;
算法的迭代过程为优化LSSVM参数,如图2所述,实现种群朝向参数解适应值较小的方向进化,从而给出拟合的LSSVM参数,提高LSSVM预测结果的精度。
其中,设定的迭代训练判断条件如下:
如果单次迭代的运行时间大于设定的T
步骤5.2.1:按照实际煤气发生过程的预测特点和预测改进思路,将惯性权重w更新策略作如下调整;
其中,惯性权重的更新策略设置如下:
步骤5.2.2:按照改进的方法,更新种群中模型参数解集的速度值,引入精英参数解的学习,具体如下公式所示:
v
精英参数解的学习系数表示为c
步骤5.2.3:根据更新原则更新模型参数解集在可行域中的位置;
所述更新原则如下所示:
1)如果当前参数解的数值分量与速度值相加结果小于数值分量下界,并且速度值v
x
其中,x
2)如果当前参数解的数值分量与速度值相加结果小于数值分量下界,速度值小于0,再按照如下条件,进行数值分量的更新:
3)如果当前参数解的数值分量与速度值相加结果大于数值分量上界,速度值小于0,进行数值分量的更新:
x
4)如果当前参数解的数值分量与速度值相加结果大于数值分量上界,速度值大于0,再按照如下条件,进行数值分量的更新:
5)如果当前参数解的数值分量与速度值相加结果在数值分量的上下界范围内,则按照如下公式更新:
x
步骤5.2.4:计算模型参数解集中个体的适应值函数并更新个体最优参数解;
步骤5.2.5:找出当前所有模型参数最优参数解,更新模型参数全局最优参数解;
步骤5.2.6:用个体最优参数解更新模型参数精英参数解集合;
其中,本发明实施例按照如下的规则更新精英参数解集合:
1)检查精英参数解集中是否包含当前个体最优参数解;
2)如果精英参数解集不包含种群个体最优参数解,计算精英参数解集中最差参数解与其他参数解的平均欧式距离,计算该种群个体最优参数解与其他精英参数解的平均欧式距离;
3)如果个体最优参数解的平均欧式距离大于最差精英参数解的平均欧式距离,则用该个体参数解替换最差精英参数解。
步骤5.2.7:对种群中达到设定更新次数的未改进参数解进行替换;
其中,从精英参数解集中随机取三个参数解中的数值求和取四分位数,代替未改进参数解的数值,对应参数解的速度值在速度上下界的范围内随机生成。
步骤5.3:训练过程结束,输出LSSVM的多工况模型,更新当前方法的预存各工况模型参数;
步骤6:识别工况完成焦炉煤气发生量预测,根据当前炼焦生产设备的检修信号,选择对应工况模型进行预测,将时序预测结果输出,为调度人员提供数据支持。
本发明实施例以某大型钢铁企业某座焦炉的实际数据为例,对检修工况和正常工况各进行30分钟的实时预测,该方法运行时间在50秒以内(包含训练参数时间),预测输出值如表1、表2所示,可见对于不同的工况,预测精度都达到99%以上。
表1正常工况下的预测输出值
表2检修工况下的预测输出值
在实际检修工况和正常工况的应用中,记录算法预测数据与实际数据的趋势对比,结果见图3检修工况的预测结果对比图和图4正常工况的预测结果对比图。从图3和图4可以发现,本发明方法能准确学习出各工况的生产动态工况信息,并稳定、快速、精确的预测各工况条件下焦炉煤气发生量和变动趋势,给能源管理人员提供数据支持。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
- 一种自适应多工况钢铁二次能源发生量动态预测方法
- 一种多工况动态基准化的机械设备剩余寿命预测方法