一种通过代谢工程改造提高蒎烯生物合成的方法
文献发布时间:2023-06-19 10:22:47
技术领域
本发明涉及一种通过代谢工程改造提高蒎烯生物合成的方法,属于微生物技术领域。
背景技术
蒎烯(pinene),分子式C
目前蒎烯主要通过化学法合成,即采用高效精馏塔从脂松节油或粗硫酸盐松节油中进行分离提取。这种方法对设备要求较高,分离提取难度大、成本高,同时造成了大量自然资源的破坏。随着代谢工程和合成生物学的迅速发展,绿色可持续发展的微生物合成技术为先进生物燃料的制造提供了替代策略,即可利用大肠杆菌(Escherichia coli)、酿酒酵母(Saccharomy cescerevisiae)等遗传背景清晰、基因操作体系成熟的模式微生物实现目标产品的高效合成。与大肠杆菌相比,酿酒酵母由于拥有更强大的蛋白表达和翻译后修饰系统以及完整的内膜系统,更适于蒎烯合成代谢过程中关键酶细胞色素P450蛋白的表达。
但是,在酿酒酵母的蒎烯代谢合成过程中,蒎烯的产量不高,并且由于蒎烯对酿酒酵母具有生长抑制的作用,更加的限制了采用酿酒酵母生产蒎烯,发明人课题组前期的研究中,发现在产甘油假丝酵母转化葡萄糖发酵生产蒎烯,产量仅仅为0.38mg/L,远远不能达到工业生产的需要,因此如何得到一种操作简单、转化效率高、生产成本低、工业化应用前景广高产蒎烯的方法成为研究的热点和难点。
发明内容
为了得到一种操作简单、转化效率高、生产成本低、工业化应用前景广的高产蒎烯的方法,本发明提供了一种重组产甘油假丝酵母,同时过表达了ERG10、ERG13、ERG12、ERG8、HMGR、ERG20、IDI或IDI突变体IDI-1基因,并表达了来源于Pinus taeda的蒎烯合酶;
所述IDI-1是在核氨酸序列如SEQ ID NO.1所示的IDI的基础上,将第139位的半胱氨酸进行突变得到的。
在本发明的一种实施方式中,所述IDI-1是在氨基酸序列如SEQ ID NO.1所示的IDI的基础上,将第139位的半胱氨酸突变为色氨酸得到的,命名为C139W。
在本发明的一种实施方式中,所述蒎烯合酶的核苷酸序列如SEQ ID NO.2所示。
在本发明的一种实施方式中,所述HMGR的核苷酸序列如SEQ ID NO.3所示。
在本发明的一种实施方式中,所述ERG20的核苷酸序列如SEQ ID NO.4所示。
在本发明的一种实施方式中,所述IDI-1的核苷酸序列如SEQ ID NO.5所示。
在本发明的一种实施方式中,所述ERG10的核苷酸序列如SEQ ID NO.6所示。
在本发明的一种实施方式中,所述ERG13的核苷酸序列如SEQ ID NO.7所示。
在本发明的一种实施方式中,所述ERG12的核苷酸序列如SEQ ID NO.8所示。
在本发明的一种实施方式中,所述ERG8的核苷酸序列如SEQ ID NO.9所示。
在本发明的一种实施方式中,所述IDI的核苷酸序列如SEQ ID NO.10所示。
在本发明的一种实施方式中,所述来源于E.coli的coaA的NCBI登录号为ID:948479。
在本发明的一种实施方式中,所述来源于A.thaliana的Acl的NCBI登录号为GeneID:816892。
在本发明的一种实施方式中,所述来源于E.coli的IDI的NCBI登录号为Gene ID:949020,命名为IDI-2。
在本发明的一种实施方式中,所述来源于S.cerevisiae的IDI的NCBI登录号为Gene ID:855986,命名为IDI-3。
在本发明的一种实施方式中,所述来源于C.glycerinogenes的IDI的NCBI登录号为GeneID:40386068,命名为IDI-4。
在本发明的一种实施方式中,以产甘油假丝酵母(Candida glycerinogenes)CCTCC M 93018为宿主。
在本发明的一种实施方式中,以pURGAP为表达载体。
本发明还提供了一种构建上述重组产甘油假丝酵母的方法,包括以下步骤:
(1)化学合成蒎烯合酶基因,并将蒎烯合酶基因连接到质粒上,得到重组质粒;
(2)将核苷酸序列如SEQ ID NO.6所示的ERG10的基因、核苷酸序列如SEQ ID NO.7所示的ERG13的基因、核苷酸序列如SEQ ID NO.8所示的ERG12的基因、核苷酸序列如SEQ IDNO.9所示的ERG8的基因、编码核苷酸序列如SEQ ID NO.3所示的HMGR的基因、编码核苷酸序列如SEQ ID NO.4所示的ERG20的基因、编码核苷酸序列如SEQ ID NO.5所示的IDI-1的基因或或编码核苷酸序列如SEQ ID NO.10所示IDI的基因通过同源重组的方法整合到产甘油假丝酵母多拷贝整合位点BamH I(GGATCC),得到表达宿主;
(3)将步骤(1)得到重组质粒转入步骤(2)得到的表达宿主中,构建得到重组产甘油假丝酵母。
在本发明的一种实施方式中,所述蒎烯合酶的核氨酸序列如SEQ ID NO.2所示。
在本发明的一种实施方式中,包括以下步骤:
(1)化学合成核氨酸序列如SEQ ID NO.2所示的蒎烯合酶基因,将蒎烯合酶基因采用BamH I和Kpn I酶切之后连接到pURGAP质粒上,构建重组质粒,采用Sac I线性化重组质粒;
(2)将核苷酸序列如SEQ ID NO.6所示的ERG10的基因、核苷酸序列如SEQ ID NO.7所示的ERG13的基因、核苷酸序列如SEQ ID NO.8所示的ERG12的基因、核苷酸序列如SEQ IDNO.9所示的ERG8的基因、编码核苷酸序列如SEQ ID NO.3所示的HMGR的基因、编码核苷酸序列如SEQ ID NO.4所示的ERG20的基因、编码核苷酸序列如SEQ ID NO.5所示的IDI-1的基因或编码核苷酸序列如SEQ ID NO.10所示IDI的基因分别通过同源重组的方法整合到产甘油假丝酵母(Candida glycerinogenes)CCTCC M 93018多拷贝整合位点BamH I(GGATCC),得到表达宿主;
(3)采用醋酸锂转化法将线性化重组质粒转化到产甘油假丝酵母(Candidaglycerinogenes)CCTCC M 93018基因组中,构建高浓度蒎烯耐受性产蒎烯工程菌。
在本发明的一种实施方式中,所述质粒pURGAP公开于公开号为CN103173483B的专利文本当中。
本发明还提供了一种合成蒎烯的方法,所述方法为,将上述重组产甘油假丝酵母添加至种子培养基中培养,得到种子液,将种子液接种至发酵培养基中,发酵制备蒎烯。
在本发明的一种实施方式中,所述方法包括以下步骤:
(1)挑取转化成功的上述重组菌单菌落接种到种子培养基中,在30℃,200rpm下培养12h,得到种子液;
(2)将步骤(1)得到的种子液以5%(v/v)的接种量,接种至发酵培养基中,在30~37℃,转速为150~200r/min,待OD
在本发明的一种实施方式中,所述种子培养基、发酵培养基均为YPD培养基。
本发明还提供了上述重组酿酒酵母,或上述方法在制备含有蒎烯的产品中的应用。
有益效果
(1)采用本发明提供的技术方案,能够得到一种操作简单、转化效率高的生产蒎烯的方法,本发明采用产甘油假丝酵母(Candida glycerinogenes)CCTCC M 93018为宿主,对蒎烯的耐受性高,可达1g/L,克服了蒎烯在发酵过程中对菌株的毒害作用,有利于该菌株在蒎烯工业生产、国防军事、药物制备中的应用。
(2)本发明构建的重组产甘油假丝酵母菌株,通过代谢工程改造可以明显提高蒎烯产量具有蒎烯产量高,使蒎烯产量由原来的0.38mg/L提高到40mg/L,使产量提高了100多倍。
附图说明
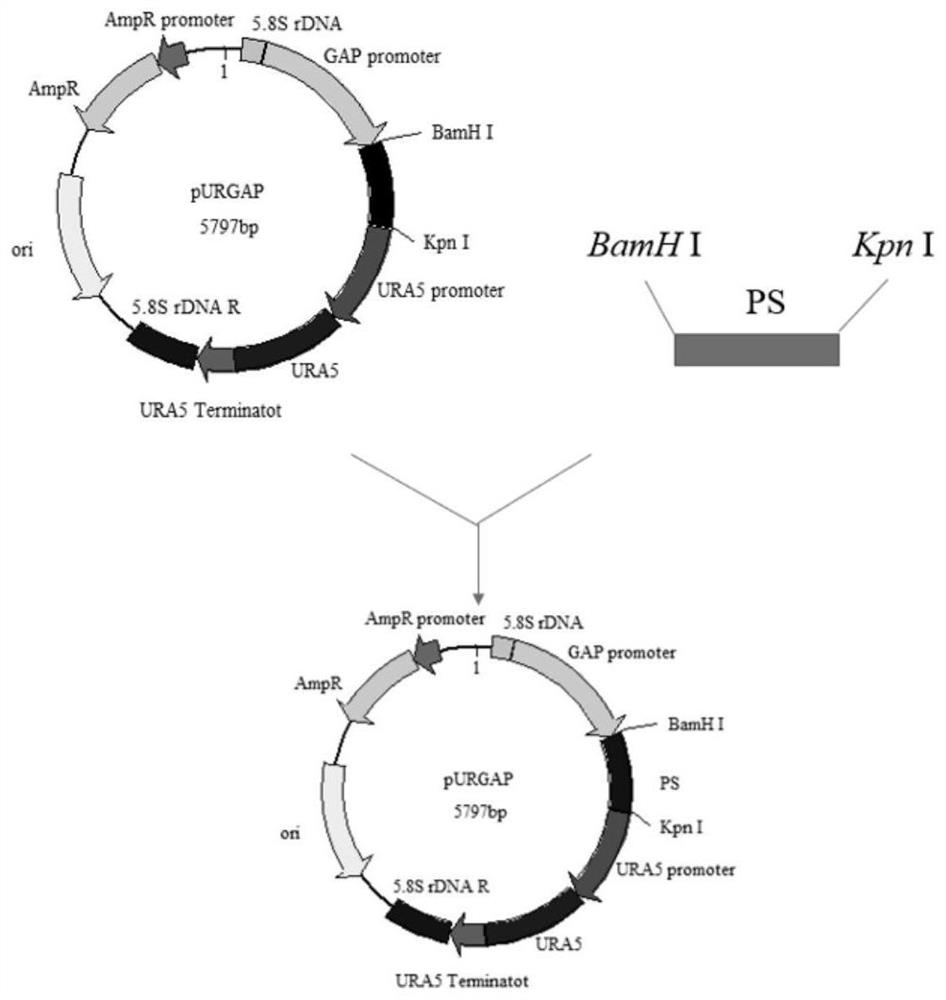
图1:含蒎烯合酶(Ps)基因的整合表达载体构建过程图。
图2:含HMGR、ERG20、IDI1基因的整合表达质粒图谱及酶切验证图。
图3:代谢工程改造及qRT-PCR分析HMGR、ERG20、IDI1转录表达水平。
图4:代谢改造工程菌蒎烯产量测定结果。
图5:前体物质的积累对蒎烯合成的影响。
图6:IDI1饱和突变对蒎烯合成的影响。
具体实施方式
下面通过实施例对本发明进一步详细描述。
下述实施例中所涉及的培养基如下:
YPD培养基:酵母粉10g/L,蛋白胨20g/L,葡萄糖20g/L,定容到1L。
MM固体培养基:YNB(无氨基酵母氮源)6.7g/L,酵母粉10g/L,蛋白胨20g/L,葡萄糖20g/L,定容到1L。
下述实施例中所涉及的检测方法如下:
蒎烯含量的检测:
取上层正十二烷层进行气相色谱检测。检测条件为:气相色谱仪(GC-2014,Japan),色谱柱HP-5ms(30m×0.25μm×0.25mm)硅胶毛细管色谱柱,进样量1μL,载气为氮气,流速0.8mL/min,进样口温度为260℃,柱温箱起始温度为60℃,保留2min,以5℃/min程序升温至160℃,再以120℃/min升到260℃,氢焰检测器温度为300℃。
下述实施例中所涉及的引物序列如表1所示:
表1引物序列
实施例1产蒎烯工程菌M 93018/pURGAPU-ps的构建
具体步骤如下:
1、线性化载体准备:化学合成核氨酸序列如SEQ ID NO.2所示的蒎烯合酶ps;
蒎烯合酶通过BamH I和KpnI酶切连接到pURGAPU质粒上,构建得到重组质粒pURGAPU-ps(如图1所示),采用Sac I将重组质粒单酶切为线性化DNA片段。
2、(1)取实验室冷冻保存的产甘油假丝酵母(Candida glycerinogenes)CCTCC M93018接种于10mL YPD培养基中30℃过夜培养,得到种子液;将种子液按1%(v/v)的接种量接种至50mL YPD培养基,在30℃,200rpm条件下进行培养,将培养至OD 600为1时的发酵液在6000r/min条件下离心3min,收集菌体;
(2)向得到的菌体中加入1mL无菌水轻柔悬浮洗涤,离心弃去上清液,重复两次后加入44μL无菌水轻柔悬浮菌体,再分别加入240μl 50%聚乙二醇溶液(PEG),36μl 1M醋酸锂(LiAc),20μl ssDNA(鲑鱼精DNA,预先沸水浴10min,然后冰上冷却1min),500ng线性化DNA片段。充分轻柔地吹吸混匀,置于42℃水浴锅中热激1h。在10000r/min条件下离心XXmin,收集菌体,弃去上清液,向菌体中加入1mL YPD培养基,在30℃培养2h,得到发酵液;将培养后的发酵液在6000r/min条件下离心2min,收集菌体,将收集到的菌体用无菌水洗涤两次后涂布于MM固体培养基上,在30℃培养3d,获得产蒎烯工程菌M 93018/pURGAPU-ps。
(3)将蒎烯合成途径(甲羟戊酸途径)分为上游模块和下游模块进行分别强化,上游模块主要过表达来源于S.cerevisiae的ERG10和ERG13基因,下游模块过表达来源于S.cerevisiae的ERG12和ERG8,按照以上方法进行整合表达,构建上游模块和下游模块强化工程菌。
(4)在构建好的上下游模块强化工程菌中继续过表达coaA(E.coli)、Acl(A.thaliana)、IDI(E.coli)、IDI1(S.cerevisiae)、IDI1(C.glycerinogenes)等基因来提高前体物乙酰辅酶A积累量以及平衡IPP和DMAPP含量促进蒎烯合成前体物质GPP的合成。
(5)为了进一步提高蒎烯合成前体物质GPP含量,根据Swiss-model和Uniprot在线工具分析,对外源IDI1(S.cerevisiae)基因关键位点(139)进行了饱和突变处理,来考察不同突变其对GPP合成的影响。
实施例2:高产蒎烯工程菌的构建
具体步骤如下:
1、(1)化学合成编码核苷酸序列如SEQ ID NO.4所示的HMGR的基因,编码核苷酸序列如SEQ ID NO.6所示的ERG20的基因及编码核苷酸序列如SEQ ID NO.1所示的IDI的基因。
(2)将步骤(1)得到的基因利用HMGRf/r、ERG20f/r、IDI f/r引物,分别整合到实施例1得到的重组菌M 93018/pURGAPU-ps中,分别获得产蒎烯工程菌:M 93018-HMGR/pURGAPU-ps、M 93018-ERG20/pURGAPU-ps和M 93018-IDI/pURGAPU-ps;
2、将步骤1中得到的三株工程菌,转接摇瓶培养,至OD
(1)操作台使用RNA酶清除剂(现配现用,RNA清除剂:无菌水=1:10)擦拭,实验器皿预先用1:1000的RNA酶清除剂浸泡5min并121°下高压灭菌30min,重复灭菌两次以清除RNA酶;
(2)酵母样品转移至研钵,加入液氮快速研磨,多次重复至样品变成亮白色细粉状。取少量研磨破碎后的菌体至处理过的离心管中,加入Trizon 1mL充分吹吸悬浮,在涡旋混合器上1800r·min
(3)以12000r·min
(4)在4℃条件下将步骤(3)得到的产物在12000r·min
(5)将步骤(4)得到的产物高速离心后取上清液转移至新的离心管,加入0.5mL异丙醇,缓慢颠倒混匀数次,冰上静置30min使DNA析出,12000r·min
(6)将步骤(5)得到的沉淀用含RNA酶清除剂的70%乙醇洗涤后静置干燥去除残余乙醇,RNA沉淀用50μL含RNA酶清除剂的超纯水溶解。
3、将步骤2提取的RNA进行反转录获得cDNA,以得到的cDNA为模板进行qRT-PCR分析转录水平。由图2和图3可以看出通过过异源表达来源于S.cerevisiae代谢途径关键基因HMGR、ERG20、IDI1,可以使C.glycerinogenes代谢途径关键基因出现转录水平上调,最高上调水平为2.3,说明代谢途径中关键基因的过表达有利于提高代谢通路基因表达水平。
实施例3:高产蒎烯工程菌的构建
具体步骤如下:
(1)化学合成核苷酸序列如SEQ ID NO.6所示的ERG10基因;核苷酸序列如SEQ IDNO.7所示的ERG13基因;核苷酸序列如SEQ ID NO.8所示的的ERG12基因;核苷酸序列如SEQID NO.9所示的ERG8基因;NCBI登录号为ID:948479的coaA基因;NCBI登录号为Gene ID:816892的Acl基因;NCBI登录号为Gene ID:949020的IDI-2基因;NCBI登录号为GeneID:855986的IDI-3基因;NCBI登录号为GeneID:40386068的IDI-4基因。
(2)分别将ERG10、ERG13、ERG12、ERG8、HMGR、IDI、ERG20、coaA、Acl、IDI-2、IDI-3、IDI-4基因利用表1引物,按照表2和表3的过表达基因的方式,分别整合到实施例1得到的重组菌M 93018/pURGAPU-ps中,分别获得产蒎烯工程菌。
表2菌株的构建
表3菌株的构建
实施例4:发酵生产蒎烯
将实施例3构建的高产蒎烯工程菌分别接种至YPD培养基中,在30℃,200rpm培养12h,得到种子液,将种子液按照1%(v/v)的接种量接种至YPD培养基中进行摇瓶发酵,发酵条件为温度:30~37℃,转速:150~200r/min,待OD600值达到1时,加入5mL正十二烷,发酵时间为72h,产量如表4所示;由表4、图4和图5可以看出菌株J的产量最高根据蒎烯浓度标准曲线计算可得蒎烯最高产量为35mg/L,说明本发明的技术方案所采用的模块化强化对增强蒎烯合成效果明显,并且合成前体物质的基因过表达有利于蒎烯的合成。
表4菌株产量
实施例5:进一步提高蒎烯产量
具体实施方式同实施例4的菌株J,区别在于,调整IDI基因为核苷酸序列如SEQ IDNO.7所示的突变体C139W。
结果显示(如图6所示),对蒎烯合成由较明显提高,蒎烯产量提高1.5倍。将上下游强化模块与C139W进行共表达,其最高产量为40mg/L,较初始产量0.38mg/L,提高了100多倍。
虽然本发明已以较佳实施例公开如上,但其并非用以限定本发明,任何熟悉此技术的人,在不脱离本发明的精神和范围内,都可做各种的改动与修饰,因此本发明的保护范围应该以权利要求书所界定的为准。
SEQUENCE LISTING
<110> 江南大学
<120> 一种通过代谢工程改造提高蒎烯生物合成的方法
<130> BAA201303A
<160> 10
<170> PatentIn version 3.3
<210> 1
<211> 288
<212> PRT
<213> 人工序列
<400> 1
Met Thr Ala Asp Asn Asn Ser Met Pro His Gly Ala Val Ser Ser Tyr
1 5 10 15
Ala Lys Leu Val Gln Asn Gln Thr Pro Glu Asp Ile Leu Glu Glu Phe
20 25 30
Pro Glu Ile Ile Pro Leu Gln Gln Arg Pro Asn Thr Arg Ser Ser Glu
35 40 45
Thr Ser Asn Asp Glu Ser Gly Glu Thr Cys Phe Ser Gly His Asp Glu
50 55 60
Glu Gln Ile Lys Leu Met Asn Glu Asn Cys Ile Val Leu Asp Trp Asp
65 70 75 80
Asp Asn Ala Ile Gly Ala Gly Thr Lys Lys Val Cys His Leu Met Glu
85 90 95
Asn Ile Glu Lys Gly Leu Leu His Arg Ala Phe Ser Val Phe Ile Phe
100 105 110
Asn Glu Gln Gly Glu Leu Leu Leu Gln Gln Arg Ala Thr Glu Lys Ile
115 120 125
Thr Phe Pro Asp Leu Trp Thr Asn Thr Cys Trp Ser His Pro Leu Cys
130 135 140
Ile Asp Asp Glu Leu Gly Leu Lys Gly Lys Leu Asp Asp Lys Ile Lys
145 150 155 160
Gly Ala Ile Thr Ala Ala Val Arg Lys Leu Asp His Glu Leu Gly Ile
165 170 175
Pro Glu Asp Glu Thr Lys Thr Arg Gly Lys Phe His Phe Leu Asn Arg
180 185 190
Ile His Tyr Met Ala Pro Ser Asn Glu Pro Trp Gly Glu His Glu Ile
195 200 205
Asp Tyr Ile Leu Phe Tyr Lys Ile Asn Ala Lys Glu Asn Leu Thr Val
210 215 220
Asn Pro Asn Val Asn Glu Val Arg Asp Phe Lys Trp Val Ser Pro Asn
225 230 235 240
Asp Leu Lys Thr Met Phe Ala Asp Pro Ser Tyr Lys Phe Thr Pro Trp
245 250 255
Phe Lys Ile Ile Cys Glu Asn Tyr Leu Phe Asn Trp Trp Glu Gln Leu
260 265 270
Asp Asp Leu Ser Glu Val Glu Asn Asp Arg Gln Ile His Arg Met Leu
275 280 285
<210> 2
<211> 1887
<212> DNA
<213> 人工序列
<400> 2
atggctttgg tttctgctgt cccacttaat agtaaattgt gtttgaggag gacccttttt 60
ggattttctc acgaattgaa ggccatccac agtaccgtcc caaatcttgg tatgtgtaga 120
ggaggtaagt ctatcgcccc ttctatgtct atgtctagta ccaccagtgt cagtaatgag 180
gacggagttc caaggagaat cgccggtcac cattctaacc tttgggacga cgattctatc 240
gccagtctta gtacctctta cgaggcccca agttatagga agagggccga caagttgatc 300
ggtgaggtca agaacatctt cgaccttatg tctgtcgagg atggagtctt caccagtcca 360
cttagtgacc ttcaccatag gttgtggatg gttgatagtg tcgaaaggct tggaatcgat 420
agacatttta aagacgagat caattctgcc cttgaccacg tctacagtta ttggaccgag 480
aagggaatcg gaaggggtag ggaatctggt gttaccgact tgaacagtac tgcccttgga 540
ttgaggaccc ttaggttgca cggatacacc gtctctagtc acgtcttgga ccacttcaag 600
aacgagaagg gtcagttcac ttgttctgct atccaaaccg aaggtgagat tagagacgtc 660
ttgaacttgt ttagagcttc tcttatcgcc ttccccggtg agaagattat ggaggccgcc 720
gagatcttca gtactatgta cttgaaggac gcccttcaaa agatccctcc ttctggtttg 780
agtcaagaaa ttgaatacct tttggagttt ggttggcata ccaaccttcc tagaatggag 840
actagaatgt atattgatgt cttcggagaa gacaccacct tcgagactcc atatttgatt 900
agagaaaaat tgcttgagct tgctaagttg gaatttaaca tcttccatag tttggtcaaa 960
agagaattgc aaagtctttc tagatggtgg aaggactacg gattcccaga gattaccttc 1020
agtaggcata gacacgttga gtactacacc ttggctgctt gtatcgccaa cgaccctaag 1080
cactctgcct ttaggttggg attcggaaaa atcagtcaca tgattaccat tcttgatgat 1140
atttacgaca ctttcggtac tatggaggaa cttaaattgc ttactgccgc cttcaagagg 1200
tgggacccat ctagtatcga gtgccttcca gattacatga agggtgtcta catggccgtc 1260
tacgacaaca ttaacgagat ggctagagag gctcagaaga tccaaggttg ggacaccgtc 1320
tcttacgcta gaaaatcttg ggaggccttt atcggtgcct acatccaaga agccaagtgg 1380
atcagtagtg gttatttgcc aacttttgac gaatacttgg aaaatggaaa agtcagtttc 1440
ggaagtagga tcaccacttt ggagccaatg ttgaccttgg gtttcccatt gcctccaagg 1500
atcttgcaag aaattgattt cccatctaaa tttaacgacc ttatctgtgc catcttgaga 1560
cttaagggag acacccagtg ctacaaggcc gacagagcta gaggtgagga ggcttctgcc 1620
gtcagttgct acatgaagga tcatcccggt atcaccgagg aagacgccgt caatcaagtt 1680
aatgccatgg ttgataactt gaccaaggag cttaactggg agcttcttag gccagacagt 1740
ggtgtcccta tctcttacaa gaaagtcgcc ttcgacattt gtagagtttt ccattacgga 1800
tataagtata gagacggttt ctctgtcgcc tctattgaga ttaagaacct tgtcactaga 1860
accgtcgttg aaactgtccc actttaa 1887
<210> 3
<211> 3165
<212> DNA
<213> 人工序列
<400> 3
atgccgccgc tattcaaggg actgaaacag atggcaaagc caattgccta tgtttcaaga 60
ttttcggcga aacgaccaat tcatataata cttttttctc taatcatatc cgcattcgct 120
tatctatccg tcattcagta ttacttcaat ggttggcaac tagattcaaa tagtgttttt 180
gaaactgctc caaataaaga ctccaacact ctatttcaag aatgttccca ttactacaga 240
gattcctctc tagatggttg ggtatcaatc accgcgcatg aagctagtga gttaccagcc 300
ccacaccatt actatctatt aaacctgaac ttcaatagtc ctaatgaaac tgactccatt 360
ccagaactag ctaacacggt ttttgagaaa gataatacaa aatatattct gcaagaagat 420
ctcagtgttt ccaaagaaat ttcttctact gatggaacga aatggaggtt aagaagtgac 480
agaaaaagtc ttttcgacgt aaagacgtta gcatattctc tctacgatgt attttcagaa 540
aatgtaaccc aagcagaccc gtttgacgtc cttattatgg ttactgccta cctaatgatg 600
ttctacacca tattcggcct cttcaatgac atgaggaaga ccgggtcaaa tttttggttg 660
agcgcctcta cagtggtcaa ttctgcatca tcacttttct tagcattgta tgtcacccaa 720
tgtattctag gcaaagaagt ttccgcatta actctttttg aaggtttgcc tttcattgta 780
gttgttgttg gtttcaagca caaaatcaag attgcccagt atgccctgga gaaatttgaa 840
agagtcggtt tatctaaaag gattactacc gatgaaatcg tttttgaatc cgtgagcgaa 900
gagggtggtc gtttgattca agaccatttg ctttgtattt ttgcctttat cggatgctct 960
atgtatgctc accaattgaa gactttgaca aacttctgca tattatcagc atttatccta 1020
atttttgaat tgattttaac tcctacattt tattctgcta tcttagcgct tagactggaa 1080
atgaatgtta tccacagatc tactattatc aagcaaacat tagaagaaga cggtgttgtt 1140
ccatctacag caagaatcat ttctaaagca gaaaagaaat ccgtatcttc tttcttaaat 1200
ctcagtgtgg ttgtcattat catgaaactc tctgtcatac tgttgtttgt cttcatcaac 1260
ttttataact ttggtgcaaa ttgggtcaat gatgccttca attcattgta cttcgataag 1320
gaacgtgttt ctctaccaga ttttattacc tcgaatgcct ctgaaaactt taaagagcaa 1380
gctattgtta gtgtcacccc attattatat tacaaaccca ttaagtccta ccaacgcatt 1440
gaggatatgg ttcttctatt gcttcgtaat gtcagtgttg ccattcgtga taggttcgtc 1500
agtaaattag ttctttccgc cttagtatgc agtgctgtca tcaatgtgta tttattgaat 1560
gctgctagaa ttcataccag ttatactgca gaccaattgg tgaaaactga agtcaccaag 1620
aagtctttta ctgctcctgt acaaaaggct tctacaccag ttttaaccaa taaaacagtc 1680
atttctggat cgaaagtcaa aagtttatca tctgcgcaat cgagctcatc aggaccttca 1740
tcatctagtg aggaagatga ttcccgcgat attgaaagct tggataagaa aatacgtcct 1800
ttagaagaat tagaagcatt attaagtagt ggaaatacaa aacaattgaa gaacaaagag 1860
gtcgctgcct tggttattca cggtaagtta cctttgtacg ctttggagaa aaaattaggt 1920
gatactacga gagcggttgc ggtacgtagg aaggctcttt caattttggc agaagctcct 1980
gtattagcat ctgatcgttt accatataaa aattatgact acgaccgcgt atttggcgct 2040
tgttgtgaaa atgttatagg ttacatgcct ttgcccgttg gtgttatagg ccccttggtt 2100
atcgatggta catcttatca tataccaatg gcaactacag agggttgttt ggtagcttct 2160
gccatgcgtg gctgtaaggc aatcaatgct ggcggtggtg caacaactgt tttaactaag 2220
gatggtatga caagaggccc agtagtccgt ttcccaactt tgaaaagatc tggtgcctgt 2280
aagatatggt tagactcaga agagggacaa aacgcaatta aaaaagcttt taactctaca 2340
tcaagatttg cacgtctgca acatattcaa acttgtctag caggagattt actcttcatg 2400
agatttagaa caactactgg tgacgcaatg ggtatgaata tgatttctaa aggtgtcgaa 2460
tactcattaa agcaaatggt agaagagtat ggctgggaag atatggaggt tgtctccgtt 2520
tctggtaact actgtaccga caaaaaacca gctgccatca actggatcga aggtcgtggt 2580
aagagtgtcg tcgcagaagc tactattcct ggtgatgttg tcagaaaagt gttaaaaagt 2640
gatgtttccg cattggttga gttgaacatt gctaagaatt tggttggatc tgcaatggct 2700
gggtctgttg gtggatttaa cgcacatgca gctaatttag tgacagctgt tttcttggca 2760
ttaggacaag atcctgcaca aaatgttgaa agttccaact gtataacatt gatgaaagaa 2820
gtggacggtg atttgagaat ttccgtatcc atgccatcca tcgaagtagg taccatcggt 2880
ggtggtactg ttctagaacc acaaggtgcc atgttggact tattaggtgt aagaggcccg 2940
catgctaccg ctcctggtac caacgcacgt caattagcaa gaatagttgc ctgtgccgtc 3000
ttggcaggtg aattatcctt atgtgctgcc ctagcagccg gccatttggt tcaaagtcat 3060
atgacccaca acaggaaacc tgctgaacca acaaaaccta acaatttgga cgccactgat 3120
ataaatcgtt tgaaagatgg gtccgtcacc tgcattaaat cctaa 3165
<210> 4
<211> 1059
<212> DNA
<213> 人工序列
<400> 4
atggcttcag aaaaagaaat taggagagag agattcttga acgttttccc taaattagta 60
gaggaattga acgcatcgct tttggcttac ggtatgccta aggaagcatg tgactggtat 120
gcccactcat tgaactacaa cactccaggc ggtaagctaa atagaggttt gtccgttgtg 180
gacacgtatg ctattctctc caacaagacc gttgaacaat tggggcaaga agaatacgaa 240
aaggttgcca ttctaggttg gtgcattgag ttgttgcagg cttacttctt ggtcgccgat 300
gatatgatgg acaagtccat taccagaaga ggccaaccat gttggtacaa ggttcctgaa 360
gttggggaaa ttgccatcaa tgacgcattc atgttagagg ctgctatcta caagcttttg 420
aaatctcact tcagaaacga aaaatactac atagatatca ccgaattgtt ccatgaggtc 480
accttccaaa ccgaattggg ccaattgatg gacttaatca ctgcacctga agacaaagtc 540
gacttgagta agttctccct aaagaagcac tccttcatag ttactttcaa gactgcttac 600
tattctttct acttgcctgt cgcattggcc atgtacgttg ccggtatcac ggatgaaaag 660
gatttgaaac aagccagaga tgtcttgatt ccattgggtg aatacttcca aattcaagat 720
gactacttag actgcttcgg taccccagaa cagatcggta agatcggtac agatatccaa 780
gataacaaat gttcttgggt aatcaacaag gcattggaac ttgcttccgc agaacaaaga 840
aagactttag acgaaaatta cggtaagaag gactcagtcg cagaagccaa atgcaaaaag 900
attttcaatg acttgaaaat tgaacagcta taccacgaat atgaagagtc tattgccaag 960
gatttgaagg ccaaaatttc tcaggtcgat gagtctcgtg gcttcaaagc tgatgtctta 1020
actgcgttct tgaacaaagt ttacaagaga agcaaatag 1059
<210> 5
<211> 867
<212> DNA
<213> 人工序列
<400> 5
atgactgccg acaacaatag tatgccccat ggtgcagtat ctagttacgc caaattagtg 60
caaaaccaaa cacctgaaga cattttggaa gagtttcctg aaattattcc attacaacaa 120
agacctaata cccgatctag tgagacgtca aatgacgaaa gcggagaaac atgtttttct 180
ggtcatgatg aggagcaaat taagttaatg aatgaaaatt gtattgtttt ggattgggac 240
gataatgcta ttggtgccgg taccaagaaa gtttgtcatt taatggaaaa tattgaaaag 300
ggtttactac atcgtgcatt ctccgtcttt attttcaatg aacaaggtga attactttta 360
caacaaagag ccactgaaaa aataactttc cctgatcttt ggactaacac atgctggtct 420
catccactat gtattgatga cgaattaggt ttgaagggta agctagacga taagattaag 480
ggcgctatta ctgcggcggt gagaaaacta gatcatgaat taggtattcc agaagatgaa 540
actaagacaa ggggtaagtt tcacttttta aacagaatcc attacatggc accaagcaat 600
gaaccatggg gtgaacatga aattgattac atcctatttt ataagatcaa cgctaaagaa 660
aacttgactg tcaacccaaa cgtcaatgaa gttagagact tcaaatgggt ttcaccaaat 720
gatttgaaaa ctatgtttgc tgacccaagt tacaagttta cgccttggtt taagattatt 780
tgcgagaatt acttattcaa ctggtgggag caattagatg acctttctga agtggaaaat 840
gacaggcaaa ttcatagaat gctataa 867
<210> 6
<211> 1197
<212> DNA
<213> 人工序列
<400> 6
atgtctcaga acgtttacat tgtatcgact gccagaaccc caattggttc attccagggt 60
tctctatcct ccaagacagc agtggaattg ggtgctgttg ctttaaaagg cgccttggct 120
aaggttccag aattggatgc atccaaggat tttgacgaaa ttatttttgg taacgttctt 180
tctgccaatt tgggccaagc tccggccaga caagttgctt tggctgccgg tttgagtaat 240
catatcgttg caagcacagt taacaaggtc tgtgcatccg ctatgaaggc aatcattttg 300
ggtgctcaat ccatcaaatg tggtaatgct gatgttgtcg tagctggtgg ttgtgaatct 360
atgactaacg caccatacta catgccagca gcccgtgcgg gtgccaaatt tggccaaact 420
gttcttgttg atggtgtcga aagagatggg ttgaacgatg cgtacgatgg tctagccatg 480
ggtgtacacg cagaaaagtg tgcccgtgat tgggatatta ctagagaaca acaagacaat 540
tttgccatcg aatcctacca aaaatctcaa aaatctcaaa aggaaggtaa attcgacaat 600
gaaattgtac ctgttaccat taagggattt agaggtaagc ctgatactca agtcacgaag 660
gacgaggaac ctgctagatt acacgttgaa aaattgagat ctgcaaggac tgttttccaa 720
aaagaaaacg gtactgttac tgccgctaac gcttctccaa tcaacgatgg tgctgcagcc 780
gtcatcttgg tttccgaaaa agttttgaag gaaaagaatt tgaagccttt ggctattatc 840
aaaggttggg gtgaggccgc tcatcaacca gctgatttta catgggctcc atctcttgca 900
gttccaaagg ctttgaaaca tgctggcatc gaagacatca attctgttga ttactttgaa 960
ttcaatgaag ccttttcggt tgtcggtttg gtgaacacta agattttgaa gctagaccca 1020
tctaaggtta atgtatatgg tggtgctgtt gctctaggtc acccattggg ttgttctggt 1080
gctagagtgg ttgttacact gctatccatc ttacagcaag aaggaggtaa gatcggtgtt 1140
gccgccattt gtaatggtgg tggtggtgct tcctctattg tcattgaaaa gatatga 1197
<210> 7
<211> 1476
<212> DNA
<213> 人工序列
<400> 7
atgaaactct caactaaact ttgttggtgt ggtattaaag gaagacttag gccgcaaaag 60
caacaacaat tacacaatac aaacttgcaa atgactgaac taaaaaaaca aaagaccgct 120
gaacaaaaaa ccagacctca aaatgtcggt attaaaggta tccaaattta catcccaact 180
caatgtgtca accaatctga gctagagaaa tttgatggcg tttctcaagg taaatacaca 240
attggtctgg gccaaaccaa catgtctttt gtcaatgaca gagaagatat ctactcgatg 300
tccctaactg ttttgtctaa gttgatcaag agttacaaca tcgacaccaa caaaattggt 360
agattagaag tcggtactga aactctgatt gacaagtcca agtctgtcaa gtctgtcttg 420
atgcaattgt ttggtgaaaa cactgacgtc gaaggtattg acacgcttaa tgcctgttac 480
ggtggtacca acgcgttgtt caactctttg aactggattg aatctaacgc atgggatggt 540
agagacgcca ttgtagtttg cggtgatatt gccatctacg ataagggtgc cgcaagacca 600
accggtggtg ccggtactgt tgctatgtgg atcggtcctg atgctccaat tgtatttgac 660
tctgtaagag cttcttacat ggaacacgcc tacgattttt acaagccaga tttcaccagc 720
gaatatcctt acgtcgatgg tcatttttca ttaacttgtt acgtcaaggc tcttgatcaa 780
gtttacaaga gttattccaa gaaggctatt tctaaagggt tggttagcga tcccgctggt 840
tcggatgctt tgaacgtttt gaaatatttc gactacaacg ttttccatgt tccaacctgt 900
aaattggtca caaaatcata cggtagatta ctatataacg atttcagagc caatcctcaa 960
ttgttcccag aagttgacgc cgaattagct actcgcgatt atgacgaatc tttaaccgat 1020
aagaacattg aaaaaacttt tgttaatgtt gctaagccat tccacaaaga gagagttgcc 1080
caatctttga ttgttccaac aaacacaggt aacatgtaca ccgcatctgt ttatgccgcc 1140
tttgcatctc tattaaacta tgttggatct gacgacttac aaggcaagcg tgttggttta 1200
ttttcttacg gttccggttt agctgcatct ctatattctt gcaaaattgt tggtgacgtc 1260
caacatatta tcaaggaatt agatattact aacaaattag ccaagagaat caccgaaact 1320
ccaaaggatt acgaagctgc catcgaattg agagaaaatg cccatttgaa gaagaacttc 1380
aaacctcaag gttccattga gcatttgcaa agtggtgttt actacttgac caacatcgat 1440
gacaaattta gaagatctta cgatgttaaa aaataa 1476
<210> 8
<211> 1332
<212> DNA
<213> 人工序列
<400> 8
atgtcattac cgttcttaac ttctgcaccg ggaaaggtta ttatttttgg tgaacactct 60
gctgtgtaca acaagcctgc cgtcgctgct agtgtgtctg cgttgagaac ctacctgcta 120
ataagcgagt catctgcacc agatactatt gaattggact tcccggacat tagctttaat 180
cataagtggt ccatcaatga tttcaatgcc atcaccgagg atcaagtaaa ctcccaaaaa 240
ttggccaagg ctcaacaagc caccgatggc ttgtctcagg aactcgttag tcttttggat 300
ccgttgttag ctcaactatc cgaatccttc cactaccatg cagcgttttg tttcctgtat 360
atgtttgttt gcctatgccc ccatgccaag aatattaagt tttctttaaa gtctacttta 420
cccatcggtg ctgggttggg ctcaagcgcc tctatttctg tatcactggc cttagctatg 480
gcctacttgg gggggttaat aggatctaat gacttggaaa agctgtcaga aaacgataag 540
catatagtga atcaatgggc cttcataggt gaaaagtgta ttcacggtac cccttcagga 600
atagataacg ctgtggccac ttatggtaat gccctgctat ttgaaaaaga ctcacataat 660
ggaacaataa acacaaacaa ttttaagttc ttagatgatt tcccagccat tccaatgatc 720
ctaacctata ctagaattcc aaggtctaca aaagatcttg ttgctcgcgt tcgtgtgttg 780
gtcaccgaga aatttcctga agttatgaag ccaattctag atgccatggg tgaatgtgcc 840
ctacaaggct tagagatcat gactaagtta agtaaatgta aaggcaccga tgacgaggct 900
gtagaaacta ataatgaact gtatgaacaa ctattggaat tgataagaat aaatcatgga 960
ctgcttgtct caatcggtgt ttctcatcct ggattagaac ttattaaaaa tctgagcgat 1020
gatttgagaa ttggctccac aaaacttacc ggtgctggtg gcggcggttg ctctttgact 1080
ttgttacgaa gagacattac tcaagagcaa attgacagct tcaaaaagaa attgcaagat 1140
gattttagtt acgagacatt tgaaacagac ttgggtggga ctggctgctg tttgttaagc 1200
gcaaaaaatt tgaataaaga tcttaaaatc aaatccctag tattccaatt atttgaaaat 1260
aaaactacca caaagcaaca aattgacgat ctattattgc caggaaacac gaatttacca 1320
tggacttcat aa 1332
<210> 9
<211> 1356
<212> DNA
<213> 人工序列
<400> 9
atgtcagagt tgagagcctt cagtgcccca gggaaagcgt tactagctgg tggatattta 60
gttttagata caaaatatga agcatttgta gtcggattat cggcaagaat gcatgctgta 120
gcccatcctt acggttcatt gcaagggtct gataagtttg aagtgcgtgt gaaaagtaaa 180
caatttaaag atggggagtg gctgtaccat ataagtccta aaagtggctt cattcctgtt 240
tcgataggcg gatctaagaa ccctttcatt gaaaaagtta tcgctaacgt atttagctac 300
tttaaaccta acatggacga ctactgcaat agaaacttgt tcgttattga tattttctct 360
gatgatgcct accattctca ggaggatagc gttaccgaac atcgtggcaa cagaagattg 420
agttttcatt cgcacagaat tgaagaagtt cccaaaacag ggctgggctc ctcggcaggt 480
ttagtcacag ttttaactac agctttggcc tccttttttg tatcggacct ggaaaataat 540
gtagacaaat atagagaagt tattcataat ttagcacaag ttgctcattg tcaagctcag 600
ggtaaaattg gaagcgggtt tgatgtagcg gcggcagcat atggatctat cagatataga 660
agattcccac ccgcattaat ctctaatttg ccagatattg gaagtgctac ttacggcagt 720
aaactggcgc atttggttga tgaagaagac tggaatatta cgattaaaag taaccattta 780
ccttcgggat taactttatg gatgggcgat attaagaatg gttcagaaac agtaaaactg 840
gtccagaagg taaaaaattg gtatgattcg catatgccag aaagcttgaa aatatataca 900
gaactcgatc atgcaaattc tagatttatg gatggactat ctaaactaga tcgcttacac 960
gagactcatg acgattacag cgatcagata tttgagtctc ttgagaggaa tgactgtacc 1020
tgtcaaaagt atcctgaaat cacagaagtt agagatgcag ttgccacaat tagacgttcc 1080
tttagaaaaa taactaaaga atctggtgcc gatatcgaac ctcccgtaca aactagctta 1140
ttggatgatt gccagacctt aaaaggagtt cttacttgct taatacctgg tgctggtggt 1200
tatgacgcca ttgcagtgat tactaagcaa gatgttgatc ttagggctca aaccgctaat 1260
gacaaaagat tttctaaggt tcaatggctg gatgtaactc aggctgactg gggtgttagg 1320
aaagaaaaag atccggaaac ttatcttgat aaataa 1356
<210> 10
<211> 1356
<212> DNA
<213> 人工序列
<400> 10
atgtcagagt tgagagcctt cagtgcccca gggaaagcgt tactagctgg tggatattta 60
gttttagata caaaatatga agcatttgta gtcggattat cggcaagaat gcatgctgta 120
gcccatcctt acggttcatt gcaagggtct gataagtttg aagtgcgtgt gaaaagtaaa 180
caatttaaag atggggagtg gctgtaccat ataagtccta aaagtggctt cattcctgtt 240
tcgataggcg gatctaagaa ccctttcatt gaaaaagtta tcgctaacgt atttagctac 300
tttaaaccta acatggacga ctactgcaat agaaacttgt tcgttattga tattttctct 360
gatgatgcct accattctca ggaggatagc gttaccgaac atcgtggcaa cagaagattg 420
agttttcatt cgcacagaat tgaagaagtt cccaaaacag ggctgggctc ctcggcaggt 480
ttagtcacag ttttaactac agctttggcc tccttttttg tatcggacct ggaaaataat 540
gtagacaaat atagagaagt tattcataat ttagcacaag ttgctcattg tcaagctcag 600
ggtaaaattg gaagcgggtt tgatgtagcg gcggcagcat atggatctat cagatataga 660
agattcccac ccgcattaat ctctaatttg ccagatattg gaagtgctac ttacggcagt 720
aaactggcgc atttggttga tgaagaagac tggaatatta cgattaaaag taaccattta 780
ccttcgggat taactttatg gatgggcgat attaagaatg gttcagaaac agtaaaactg 840
gtccagaagg taaaaaattg gtatgattcg catatgccag aaagcttgaa aatatataca 900
gaactcgatc atgcaaattc tagatttatg gatggactat ctaaactaga tcgcttacac 960
gagactcatg acgattacag cgatcagata tttgagtctc ttgagaggaa tgactgtacc 1020
tgtcaaaagt atcctgaaat cacagaagtt agagatgcag ttgccacaat tagacgttcc 1080
tttagaaaaa taactaaaga atctggtgcc gatatcgaac ctcccgtaca aactagctta 1140
ttggatgatt gccagacctt aaaaggagtt cttacttgct taatacctgg tgctggtggt 1200
tatgacgcca ttgcagtgat tactaagcaa gatgttgatc ttagggctca aaccgctaat 1260
gacaaaagat tttctaaggt tcaatggctg gatgtaactc aggctgactg gggtgttagg 1320
aaagaaaaag atccggaaac ttatcttgat aaataa 1356
- 一种通过代谢工程改造提高蒎烯生物合成的方法
- 一种通过代谢工程改造提高蒎烯生物合成的方法