共享候选列表
文献发布时间:2023-06-19 10:22:47
【相关申请的交叉引用】
本申请是要求如下申请的优先权的非临时申请的一部分:2018年08月17日提出的申请号为62/719,175的美国临时专利申请案、2018年9月19日提出的申请号为62/733,101的美国临时专利申请案、2018年10月03日提出的申请号为62/740,430的美国临时专利申请案、2019年1月8日提出的申请号为62/789,566的美国临时专利申请案和2019年8月15日提出的申请号为16/541,627的美国专利申请案。且上述列出的申请的内容以引用方式整体并入本文中。
【技术领域】
本公开总体上涉及视频处理。更具体而言,本公开涉及使用共享候选列表来对共享边界内的多个像素块进行编码或解码的方法。
【背景技术】
除非本文另外指出,否则本节中描述的方法不是权利要求的现有技术,并且不被包括在本节中而被承认为现有技术。
高效视频编码(HEVC)是由视频编码联合协作团队(JCT-VC)开发的视频编码标准。在HEVC中,将编码图片分区(partitioned)为由编码树单元(CTU)表示的不重叠的正方形块区域。编码图片可以由切片的集合表示,每个切片包括整数个CTU。切片中的各个CTU按光栅扫描顺序进行处理。可以使用至多两个运动向量和参考索引来使用帧内预测或帧间预测来解码双向预测(bi-predictive)(B)切片,以预测每个块的采样值。仅使用帧内预测来对帧内(intra)(I)切片进行解码。使用帧内预测或帧间预测使用最多一个运动向量和参考索引来解码预测性(predictive)(P)切片,以预测每个块的采样值。
为每个编码单元(CU)指定一个或多个预测单元(PU)。预测单元与关联的CU语法一起,作为用于发信预测子信息的基本单元。应用指定的预测过程来预测PU内部相关像素采样的值。根据所选的PU类型,CU可以分为一个、两个或四个PU。HEVC定义了八种类型的分区,用于将CU划分为PU。
可以使用残差四叉树(RQT)结构进一步划分CU,以表示相关的预测残差信号。RQT的叶节点对应于结果转换单元(TU)。变换单元由大小为8x8、16x16或32x32的亮度采样的变换块(TB)或大小为4x4的四个亮度采样的变换块和4:2:0颜色格式的图片的色度采样的两个相应变换块组成。将整数变换应用于变换块,并且在比特流中对量化的系数值进行编码。最小和最大变换块大小在序列参数集中指定。
在HEVC中,术语编码树块(CTB)、编码块(CB)、预测块(PB)和变换块(TB)被定义为指代分别来自关联的CTU、CU、PU和TU的一种颜色分量的二维采样阵列。因此,CTU由一个亮度CTB、两个色度CTB和未使用三个单独色平面编码的颜色图片中的相关语法元素组成。发信的编码树划分通常应用于亮度块和色度块,尽管在遇到某些最小大小约束时也会有一些例外情况。
【发明内容】
以下发明内容仅是说明性的,而无意于以任何方式进行限制。即,提供以下概述以介绍本文描述的新颖和非显而易见的技术的概念、重点、益处和优点。在下面的详细描述中将进一步描述选择而非全部实现。因此,以下概述并非旨在标识所要求保护的主题的必要特征,也不旨在用于确定所要求保护的主题的范围。
本公开的一些实施例提供了一种视频编解码器,其使用共享候选列表来对共享边界内的多个像素块进行编解码(例如,编码或解码)。视频编解码器识别包含视频序列中当前图片的多个像素块的共享边界。视频编解码器基于由共享边界定义的区域的空间或时间相邻将一个或多个预测候选识别为共享候选列表。视频编解码器通过使用从共享候选列表中选择的一个或多个预测候选来对共享边界所包围的一个或多个像素块进行编解码。当对一个或多个像素块进行编码时,可以通过使用共享候选列表来并行地对第一像素块和第二像素块进行并行编码。
在一些实施例中,由共享边界定义的区域是编码树单元(CTU)的一部分,共享边界对应于CTU的子树的根,并且正被编码的像素块对应CTU的叶CU。在一些实施例中,共享候选列表包括运动向量,该运动向量用于对由共享边界定义的区域的相邻块进行编码。该区域可以对应于CU,并且共享候选列表是CU的合并或AMVP候选列表。共享候选列表包括的运动向量可以包括各种类型的合并或AMVP候选,例如仿射候选、IBC候选、子-PU候选、基于历史的候选、不相邻的候选等。
在一些实施例中,通过遍历编码树单元(CTU)来识别共享边界,该编码树单元(CTU)被划分(split)成编码单元(CU)的层次结构以识别大于或等于阈值的CU以及该CU是小于阈值的子CU的父CU。在一些实施例中,通过遍历编码树单元(CTU)来识别共享边界,该编码树单元被划分成编码单元(CU)的层次结构以识别小于或等于阈值的CU并且该CU是大于阈值的父CU的子CU。
【附图说明】
包括附图以提供对本公开的进一步理解,并且附图被并入本公开并构成本公开的一部分。附图示出了本公开的实施方式,并且与描述一起用于解释本公开的原理。可以理解的是,附图不一定按比例绘制,因为为了清楚地说明本公开的概念,某些组件可能被显示为与实际实现中的尺寸不成比例。
图1示出了建立在四叉树(QT)划分结构上的编码树,该四叉树划分结构表示将编码树单元(CTU)划分为CU。
图2概念性地示出了通过二叉树划分对编码单元(CU)的分区。
图3概念性地示出了通过四叉树划分和二叉树划分对CU进行分区。
图4示出了用于在MTT结构中分区CTU的几种划分类型或模式。
图5示出了在一些实施例中用于发信CTU的分区结构的决策树。
图6示出为帧间预测模式设置的MVP候选。
图7示出了包括合并的双向预测合并候选的合并候选列表。
图8示出了包括缩放的合并候选的合并候选列表。
图9示出了将零向量候选添加到合并候选列表或AMVP候选列表的示例。
图10示出了四参数仿射运动模型。
图11示出了仿射帧间模式的MVP推导。
图12示出了用于定义或识别共享候选列表的共享边界的几个示例。
图13示出了划分树的子树,其与可以由共享候选列表编码的共享边界中的CU相对应。
图14示出了用于识别共享候选列表的共享边界。
图15a和图15b示出了使用CU大小阈值来识别共享候选列表的共享边界。
图16示出了一组CU节点的示例。
图17示出了可使用共享候选列表来编码CTU内的多个CU的示例视频编码器。
图18示出了视频编码器的实施共享候选列表的部分。
图19概念性地示出了使用共享候选列表来编码多个CU的过程。
图20示出了实施共享候选列表的实例视频解码器。
图21示出了视频解码器的实现共享候选列表的部分。
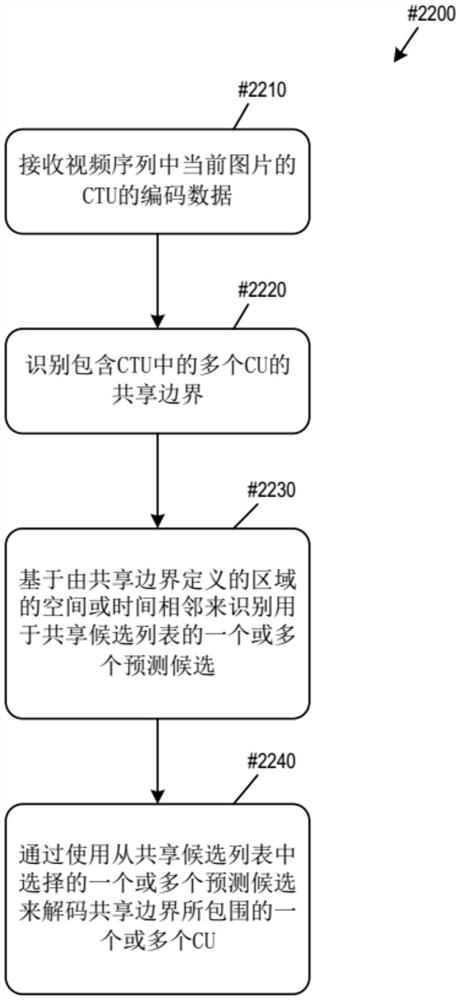
图22概念性地示出了使用共享候选列表来解码多个CU的过程。
图23概念性地示出了用于实现本公开的一些实施例的电子系统。
【具体实施方式】
在下面的详细描述中,通过示例的方式阐述了许多具体细节,以便提供对相关教导的透彻理解。基于本文描述的教导的任何变化、导出和/或扩展都在本公开的保护范围内。在一些情况下,与本文公开的一个或多个示例实现有关的公知的方法、过程、组件和/或电路可以在没有详细描述的情况下以相对较高的水平进行描述,以避免不必要地混淆本公开的教导的各个方面。
I.分区结构
在HEVC中,图片由切片组成,而切片由CTU组成。CTU是大小为8x8、16x16、32x32和64x64的正方形。一个CTU分为几个编码单元(CU)。四叉树结构用于划分CTU。CTU大小为MxM(M是64、32或16的值之一)。CTU可以是单个CU,也可以分为4个大小为M/2xM/2的单元,它们是编码树节点。如果单位是叶节点,则它们将成为CU。否则,可以进一步拆分四叉树,直到节点的大小达到SPS中指定的最小CU大小为止。图1示出了将CTU划分为四叉树。实线是CU边界。每个CU中存在一个或多个PU(prediction unit)。
PU与CU耦合,是用于共享预测信息的基本块。在每个PU内部,应用相同的预测过程。根据PU分区类型,CU可以被分成1、2或4个PU。PU只能拆分一次。可替代地,可以使用二叉树(BT)分区结构。具体而言,可以将一个块递归地划分为2个较小的块。对称的水平和垂直划分是最有效和最简单的划分类型。在一些实施例中,仅使用这两种划分类型。可以递归划分二叉树分区过程,直到划分块的宽度或高度达到可在视频比特流中以高级语法定义的最小块宽度或高度为止。
图2显示了划分过程(左)及其二叉树(右)的示例。在二叉树的每个划分的非叶节点中,标志指示使用水平还是垂直,0指示水平划分,1指示垂直划分。二叉树划分结构可以用于将CTU分区为CU,即根节点是CTU,叶节点是CU。并且为了简化,作为另一个实施例,没有从CU到PU的进一步分区。这意味着CU等于PU,因此,它等于二叉树的叶节点是预测的基本单位。
在一些实施例中,使用QTBT结构(四叉树加二叉树结构)。它结合了四叉树和二叉树。在QTBT结构中,首先,通过四叉树划分过程对块进行分区,可以迭代四叉树(QT)划分过程,直到大小达到最小叶节点大小为止。其次,如果叶四叉树块不大于允许的最大二叉树根节点大小,则可以将叶四叉树块进一步划分为二叉树(BT)分区,可以迭代二叉划分,直到划分块的宽度或高度达到最小允许宽度或高度为止,或者二叉树划分深度达到最大允许深度。图3示出了QTBT结构的示例。QTBT结构可以用于将CTU分区为CU,即,根节点是通过QTBT结构划分为多个CU的CTU,并且通过预测和变换编码来进一步处理CU。并且为了简化,作为另一个实施例,没有从CU到PU的进一步分区。这意味着CU等于PU,因此,它等于QTBT树的叶节点是用于预测的基本单位。
对于I切片,将QTBT结构分别应用于亮度和色度。对于P和B切片,QTBT结构同时应用于亮度和色度(色度达到某些最小大小时除外)。换句话说,在I切片中,QTBT结构的块分区树在亮度CTB和两个色度CTB之间有所不同。具体地,亮度CTB具有QTBT结构的块分区,并且两个色度编码树单元(CTB)具有另一QTBT结构的块分区。
与HEVC中的四叉树(QT)结构相比,诸如四叉树-二叉树(QTBT)的灵活CU结构显示出良好的编码性能。如图3所示,在QTBT中,CTU首先被四叉树结构分区。四叉树叶节点进一步由二叉树结构分区。为了将一个块递归地分成两个较小的块,除了常规的对称水平和垂直划分类型之外,还可以选择非对称水平和垂直划分类型。构造二叉树结构后,二叉树叶节点表示为CU,无需进行任何进一步分区即可用于预测和变换。
为了进一步支持更多的分区形状以实现更灵活的分区,设计三叉树(TT)分区方法以捕获位于块中心的对象,而四叉树(QT)和二叉树(BT)分区方法总是沿着块中心划分。
多类型树(Multi-Type-Tree,简写为MTT)块分区通过允许MTT的第二级中的二叉树和三叉树分区方法来扩展QTBT中的两级树结构的概念。MTT中的两个树级别分别称为区域树(region tree,简写为RT)和预测树(prediction tree,简写为PT)。第一级RT始终是四叉树(QT)分区,而第二级PT可以是二叉树(BT)分区或三叉树(TT)分区。例如,CTU首先被RT分区,这是QT分区,并且每个RT叶节点可以被PT进一步划分,PT是BT或TT分区。可以用PT进一步划分被PT分区的块,直到达到最大PT深度为止,例如,可以首先通过垂直BT分区对一个块进行分区,以生成左子块和右子块,以及左子块通过水平TT分区进一步划分,而右子块通过水平BT分区进一步划分。PT叶节点是用于预测和变换的基本CU,并且不会进一步划分。
图4示出了用于在MTT结构中分区CTU的几种划分类型或模式(a)-(e)。划分类型(a)(b)和(c)分别对应于四叉树划分、垂直二叉树划分和水平二叉树划分。划分类型(d)和(e)称为三叉树(或三元树(ternary tree))划分类型,可将一个块划分为三个较小的块。三元树划分的三个较小的块在一个空间维度上具有减小的大小,而在另一空间维度上保持相同的大小。通过允许四分之一的垂直或水平分区,三叉树分区方法可以提供沿着块边界更快定位小对象的功能。
图5示出了根据MTT块分区的用于块分区的树型信令的示例。RT信令可以类似于QTBT块分区中的四叉树信令。为了发信PT节点,发信一个附加的比特子(bin),以指示它是二叉树分区还是三叉树分区。对于被RT划分的块,发信第一比特子,以指示是否还有另一个RT划分,如果该块未被RT进一步划分(即,第一比特子为0),则发信第二比特子以指示是否存在PT划分。如果该块未被PT进一步划分(即第二比特子为0),则该块为叶节点。如果该块被PT进一步划分(即第二比特子为1),则发送第三比特子指示水平或垂直分区,然后发送第四比特子来区分二叉树(BT)或三叉树(TT)分区。
在构造MTT块分区之后,MTT叶节点是CU,无需进一步分区即可用于预测和变换。在MTT中,树形结构分别针对I切片中的亮度和色度进行编码,并同时应用于P和B切片中的亮度和色度(当达到色度的某些最小大小时除外)。也就是说,在I切片中,亮度CTB具有其QTBT结构的块分区,并且两个色度CTB具有另一QTBT结构的块分区。
II.帧间预测模式的候选
a.合并模式和AMVP模式
为了获得混合编码架构的最佳编码效率,HEVC为每个PU采用帧内预测和/或帧间预测模式。对于帧内预测模式,空间相邻的重构像素可用于生成35个方向上的方向预测。对于帧间预测模式,运动信息用于重构时间参考帧,时间参考帧用于生成运动补偿的预测。运动信息可以包括运动向量、运动向量预测子、运动向量差、用于选择参考帧的参考索引等。
当在帧间AMVP模式下对PU进行编码时,利用传输的运动向量差(MVD)执行运动补偿的预测,该运动向量差可与运动向量预测子(MVP)一起用于推导运动向量(MV)。为了在帧间AMVP模式下确定MVP,高级运动向量预测(AMVP)方案用于在包括两个空间MVP和一个时间MVP的AMVP候选集中选择运动向量预测因子。因此,在AMVP模式下,需要对MVP的MVP索引和相应的MVD进行编码和传输。另外,还指定并发送在列表0(L0)和列表1(L1)的双向预测和单向预测中指定预测方向的帧间预测方向,以及针对每个列表的参考帧索引。
当在跳过或合并模式下对PU进行编码时,除了所选择的候选的合并索引(Mergeindex)之外,没有运动信息被发送。这是因为“跳过”和“合并”模式利用运动推断方法(MV=MVP+MVD,其中MVD为零)从位于同一位置的图片的空间相邻块(空间候选)或时间块(时间候选)获得运动信息,其中该同一位置的图片是列表0或列表1中的第一个参考图片,其在切片标头中被发信。在跳过PU(Skip PU)的情况下,残差信号也被省略。为了确定跳过和合并模式(Merge mode)的合并索引,使用合并方案在包含四个空间MVP和一个时间MVP的合并候选集中选择运动向量预测子。
图6示出了用于帧间预测模式(即,跳过、合并和AMVP)的MVP候选集。该图示出了正在被编码或解码的视频图片或帧的当前块600。当前块600(可以是PU或CU)参考相邻块以将空间和时间MVP导出为用于AMVP模式、合并模式或跳过模式的MVP列表或候选列表。
对于AMVP模式,左MVP是A
对于跳过模式和合并模式,从A
1.组合的双向预测合并候选(导出候选类型1)
2.按比例缩放的双向预测合并候选(导出候选类型2)
3.零向量合并/AMVP候选(导出候选类型3)
对于导出候选类型1,通过组合原始合并候选来创建组合的双向预测合并候选。具体地,如果当前切片是B切片,则可以通过组合来自列表0和列表1的候选来生成进一步的合并候选。图7示出了包括合并的双向预测合并候选的合并候选列表。如图所示,具有mvL0(列表0中的运动向量)和refIdxL0(列表0中的参考图片索引)或mvL1(列表1中的运动向量)和refIdxL1(列表1中的参考图片索引)的两个原始候选用于创建双向预测合并候选。
对于导出候选类型2,通过缩放原始合并候选来创建缩放合并候选。图8示出了包括缩放的合并候选的合并候选列表。如图所示,原始合并候选具有mvLX(列表X中的运动向量,X可以是0或1)和refIdxLX(列表X中的参考图片索引,X可以是0或1)。例如,原始候选A是具有mvL0_A和参考图片索引ref0的列表0单向预测MV。候选A首先被复制到列表L1中,具有参考图片索引ref0'。通过基于ref0和ref0'缩放mvL0_A来计算缩放后的MV mvL0'_A。创建在列表L0中具有mvL0_A和ref0,在列表L1中具有mvL0’_A和ref0’的按比例缩放的双向预测合并候选,并将其添加到合并候选列表中。同样,创建一个缩放的双向预测合并候选,该合并候选在列表0中具有mvL1’_A和ref1’,在列表1中具有mvL1_A,ref1,并将其添加到合并候选列表中。
对于导出的候选类型3,通过组合零向量和参考索引来创建零向量候选。如果创建的零向量候选不是重复的,则将其添加到合并/AMVP候选列表。图9示出了将零向量候选添加到合并候选列表或AMVP候选列表的示例。
b.子-PU时间运动向量预测(ATMVP)
ATMVP(高级时间运动向量预测)模式(或也称为子PU时间运动向量预测(SbTMVP))是用于合并候选的基于子PU的模式。ATMVP模式使用空间相邻获取初始向量,该向量用于获取并置图片上并置块的坐标。撷取并置图片上的并置块的子CU(通常为4x4或8x8)运动信息,并将其填充到当前合并候选的子CU(通常为4x4或8x8)运动缓冲器中。存在ATMVP的数种实施方式。ATMVP的描述如下:ITU-T SG 16 WP 3和ISO/IEC JTC 1/SC 29/WG 11的联合视频探索小组(JVET):第3次会议:2016年5月26日至6月1日,瑞士日内瓦,标题:“AlgorithmDescription of Joint Exploration Test Model 3”。在以下情况中也描述了ATMVP:ITU-T SG 16 WP 3和ISO/IEC JTC 1/SC 29/WG 11的联合视频专家组(JVET)第11次会议:卢布尔雅那,SI,2018年7月10-18日,JVET-K0346-v3,标题:“CE4-related:One simplifieddesign of advanced temporal motion vector prediction(ATMVP)”。
c.空间-时间运动向量预测(STMVP)
STMVP模式是用于合并候选的基于子PU的模式。子PU的运动向量是按照光栅扫描顺序递归生成的。当前子PU的MV推导在MV缩放之前确定了两个空间相邻和一个时间相邻。在撷取和缩放MV之后,将所有可用的运动向量(最多3个)进行平均,并将其分配为当前子PU的运动向量。STMVP的描述如下:ITU-T SG 16 WP 3和ISO/IEC JTC 1/SC 29/WG 11的联合视频探索小组(JVET):第3次会议:瑞士日内瓦,2016年5月26日至6月1日,标题:“AlgorithmDescription of Joint Exploration Test Model 3”,特别是第2.3.1.2节:空间-时间运动向量预测(STMVP)。
d.基于历史的合并模式和AMVP
实施基于历史的合并模式的视频编解码器可以将一些先前的CU的合并候选存储在历史阵列中。对于当前正在被编码或解码的CU,视频编解码器可使用历史阵列内的一个或多个候选来增强原始合并模式候选。基于历史的方法也适用于AMVP候选列表。基于历史的合并模式在以下文档中有描述:ITU-T SG 16 WP 3和ISO/IEC JTC 1/SC 29/WG 11的联合视频专家组(JVET)第11次会议上:卢布尔雅那,SI,2018年7月10-18日,文档:JVET-K0104,“CE4-related:History-based Motion Vector Prediction”。
e.非相邻合并模式和AMVP
非相邻合并候选使用远离当前CU的一些空间候选。基于非相邻的方法也可以应用于AMVP候选列表。非相邻合并模式的示例如下所示:ITU-T SG 16 WP 3和ISO/IEC JTC 1/SC 29/WG 11的联合视频专家组(JVET),第11次会议:卢布尔雅那,SI,2018年7月10-18,文档:JVET-K0228,标题:“CE 4-2.1:Adding non-adjacent spatial merge candidates”。非相邻合并候选的示例如下:ITU-T SG 16 WP 3和ISO/IEC JTC 1/SC 29/WG 11的联合视频专家组(JVET),第11次会议:卢布尔雅那,SI,2018年7月10-18,文档:JVET-K0286,标题:“CE4:Additional merge candidates(Test 4.2.13)”
f.仿射合并模式
HEVC仅将平移运动模型用于运动补偿预测。现实世界中还有许多其他类型的运动,例如放大和缩小、旋转、透视运动和其他不规则运动。这些其他类型的运动中的某些可以用仿射变换或仿射运动表示,它们可以保留点、直线和平面。仿射变换不一定要保留直线之间的角度或点之间的距离,但其要保留直线上点之间的距离之比。当仿射运动块正在移动时,可以通过两个控制点运动向量或四个参数来描述该块的运动向量场(vectorfield),如下所示:
变换后的块是矩形块。此运动块中每个点的运动向量场可以用以下公式描述:
其中,(v
图11示出了仿射帧间模式的MVP推导。如图11所示,从块A
在一些实施例中,如果当前PU是合并PU,则检查相邻的五个块(图11中的C
g.当前图片参考(Current Picture Referencing,简写为CPR)
当前图片参考(CPR)也被称为帧内块复制(IBC)。CPR(或IBC)运动向量是指当前图片中已经重构的参考采样的运动向量。CPR编码的CU被发信为帧间编码的块。CPR编码的CU的亮度运动(或块)向量必须为整数精度。色度运动向量也被裁剪为整数精度。与AMVR结合使用时,CPR模式可以在1像素(1-pel)和4像素运动向量精度之间切换。当前图片位于参考图片列表L0的末尾。为了减少存储器消耗和解码器复杂性,VTM3中的CPR仅允许使用当前CTU的重构部分。该限制允许使用硬件上的本地片上存储器来实现CPR模式。
在编码器侧,针对CPR执行基于哈希的(hash-based)运动估计。编码器对宽度或高度不大于16个亮度采样的块执行RD检查。对于非合并模式,首先使用基于哈希的搜索来执行块向量搜索。如果哈希搜索未返回有效的候选,则将执行基于块匹配的本地搜索。在基于哈希的搜索中,当前块和参考块之间的哈希密钥匹配(hash key matching)(32位CRC)被扩展为所有允许的块大小。当前图片中每个位置的哈希密钥计算均基于4x4子块。对于较大尺寸的当前块,当所有4×4子块的所有哈希密钥与对应参考位置中的哈希密钥匹配时,确定哈希密钥与参考块的哈希密钥匹配。如果发现多个参考块的哈希密钥与当前块的哈希密钥匹配,则计算每个匹配参考的块向量成本,然后选择成本最小的那个。
在块匹配搜索中,将搜索范围设置为当前CTU中当前块的左侧和顶部的N个采样。在CTU的起始处,如果没有时间参考图片,则将N的值初始化为128。如果存在至少一个时间参考图片,则将N的值初始化为64。哈希命中率定义为CTU中使用基于哈希的搜索找到匹配项的采样的百分比。在对当前CTU进行编码时,如果哈希命中率低于5%,则N将减少一半。
III.共享候选列表
为了简化编解码器操作复杂度,一些实施例提供了一种使用共享候选列表来编码或解码多个像素块的方法。候选列表是指合并模式或AMVP模式候选列表,或其他类型的预测候选列表(例如DMVR或双边微调(bi-lateral refinement)候选列表、仿射合并模式、子块合并模式、仿射帧间/AMVP模式、IBC合并、IBC AMVP)。共享候选列表是基于大于叶CU(例如,父CU,或QTBT或QTBTTT树中子树的一个根,或QT树的一个节点)的边界生成的候选列表,并且可以为边界内或子树内的所有叶CU共享生成的候选列表。
在一些实施例中,共享候选列表是由公共共享边界(也称为共享边界)包含或其内的CU共享的候选列表。对于一些实施例,“共享边界”被定义为在图片内部对准的最小块的矩形区域(最小块通常为4x4)。“共享边界”内的每个CU可以使用基于“共享边界”生成的公共共享候选列表。具体地,共享候选列表的候选包括基于“共享边界”的空间相邻位置和时间相邻位置,或由共享边界定义的区域。共享边界可以是正方形块或非正方形块。共享边界的大小/深度/宽度/高度可以在比特流中以序列级、图片级或切片级发信。
图12示出了用于定义或识别共享候选列表的共享边界的几个示例。这些示例包括:与QT划分为四个4x4 CU的8x8 CU对应的正方形共享边界1210;与BT划分成两个4x8 CU的8x8 CU相对应的正方形共享边界1220;矩形共享边界1230,其对应于BT划分为两个4x8CU的4x16根CU;以及矩形共享边界1240,其对应于被TT划分为两个4x4 CU和一个4x8 CU的4x16 CU。对应于共享边界的CU也被称为共享边界的根CU。
在一些实施例中,共享的候选列表是由子树内的CU共享的候选列表。“子树”可以指的是QTBT、QTBTTT的子树或另一种类型的划分树(split tree)。图13示出了划分树的子树,其与可以由共享候选列表编码的共享边界中的CU相对应。该图示出了CTU 1300,其划分结构由分层树1350表示,该分层树是QTBT或QTBTTT划分树。在CTU 1300内,共享边界1310定义了根CU,其被划分成具有各种划分深度的几个子CU。共享边界1310所包含的子CU对应于划分树1350中的子树1360中的节点,并且子树1360中的叶节点对应于共享边界1310中的叶CU。换句话说,共享候选列表由子树1360的叶节点共享。
可以基于共享块边界(例如,诸如共享边界1310或子树1360之类的根CU边界)来生成共享候选列表。对于子树内的某些或全部叶CU重复使用共享候选列表。针对子树的根生成共享候选列表,即,基于根CU或子树的矩形边界(或共享边界)来识别共享候选列表的候选的空间相邻位置和时间相邻位置。
共享候选列表的候选是基于由共享边界定义的区域的空间或时间相邻来识别的预测候选。然后,通过使用从共享候选列表中选择的一个或多个预测候选,对共享边界所包围的一个或多个CU进行编码。
图14示出了用于识别共享候选列表的共享边界1400。共享边界1400定义区域1410。区域1410可以对应于CU。区域1410可以是划分树或CTU(例如,BT、QT、MTT等)的一部分,并且可以划分成诸如CU 1411、1412、1413和1414的子CU。子CU可以是不能进一步划分的叶CU。子CU也可以被分成更大的划分深度的子CU,直到到达叶CU为止。在该示例中,由共享边界1400定义的区域1410(或与区域1410相对应的根CU)被划分为几个叶CU,包括叶CU1421、1422和1423。
叶CU 1421、1422和1423全部通过使用基于共享边界1400识别或定义的共享候选列表来编码。共享候选列表可以是合并模式列表、AMVP列表、IBC合并列表、IBC AMVP列表或其他类型的预测候选列表。共享候选列表可以包括从区域1410的相邻(例如,来自空间相邻A
本公开的一些实施例提供了用于识别共享边界的方法。在一些实施例中,定义了用于识别共享边界SHARED_THD的CU大小阈值。对于任何叶CU,CU大小<=SHARED_THD的最大根CU将用作共享子树根,或使用共享候选列表的子树的根。在图12的示例中,对于共享边界1240处的共享候选列表,两个4x4 CU和一个4x8 CU属于相同的4x16 CU。在该示例中,SHARED_THD为64,因此4x16 CU(大小为64)是“共享子树”的根,其边界是共享边界1240(因为共享边界1240定义的区域是4x16 CU)。因此,合并列表是基于4x16 CU生成的,并由4x16CU的所有子CU(在此示例中为2个4x4 CU和一个4x8 CU)共享。
图15a和图15b示出了使用CU大小阈值来识别共享候选列表的共享边界。该示例使用32作为CU大小阈值(SHARED_THD)。在一些实施例中,识别共享边界包括遍历CTU以识别小于或等于阈值的CU并且该CU是大于该阈值的父CU的子CU。在一些实施例中,识别共享边界包括遍历CTU以识别大于或等于阈值的CU,并且该CU是小于阈值的子CU的父CU。该图示出了识别三个CTU或CU 1510、1520和1530中的共享边界。
图15a示出了通过识别小于或等于SHARED_THD(32)的CU并且识别出的CU是大于SHARED_THD的父CU的子CU而识别共享边界。视频编解码器可从叶CU到CTU根遍历每个CTU。
对于CTU或CU 1510,遍历遇到大小为16小于SHARED_THD 32的4x4 CU 1511,并且CU 1512是大小为64大于32的8x8 CU 1512的QT子级。结果,视频编码器将4x4 CU 1511识别为共享候选列表的根CU,并且将其边界1515识别为如图15a所示的实施例中的共享边界。
对于CTU或CU 1520,遍历遇到大小为16小于32的4x4 CU 1521。4x4 CU 1521是大小为32的8x4 CU 1522的BT子级,其大小小于32。遍历继续至8x4 CU 1522,其大小等于32。因此,视频编码器将8x4 CU 1522标识为共享候选列表的根CU,并将其边界1525标识为如图15a所示的实施例中的共享边界。
对于CTU或CU 1530,遍历遇到大小16小于32的4x4 CU 1531,并且CU 1531是大小64大于32的4x16 CU 1532的TT子级。作为结果在图15a所示的实施例中,视频编解码器将4×4CU 1531识别为共享候选列表的根CU,并将其边界1535识别为共享边界。
图15b示出了通过识别大于或等于SHARED_THD的CU并且识别出的CU是小于SHARED_THD的子CU的父CU来识别共享边界。视频编码器可从CTU根向叶CU遍历每个CTU。
对于CTU或CU 1510,遍历遇到大小为64大于32的8x8 CU 1512。8x8 CU 1512是大小为16小于32的4x4 CU 1511的QT父级。结果,在图15b所示的实施例中,视频编码器将8x8CU 1512识别为共享候选列表的根CU,并且将其边界1517识别为共享边界。
对于CTU或CU 1520,遍历遇到大小等于32的8x4 CU 1522。8x4 CU 1522是大小为16小于32的4x4 CU 1521的BT父级。结果在图15b所示的实施例中,视频编解码器将8×4CU1522识别为共享候选列表的根CU,并将其边界1527识别为共享边界。
对于CTU或CU 1530,遍历遇到大小为64大于32的4x16 CU 1532。4x16CU 1532是大小为16小于32的4x4 CU 1531的TT父级。结果,在第15b图所示的实施例中,视频编码器将4x16 CU 1532识别为共享候选列表的根CU,并且将其边界1537识别为共享边界。
在一些实施例中,用于标识共享边界SHARED_THD的CU大小阈值是固定的,并且对于所有图片大小和所有比特流都是预定义的。在一些实施例中,SHARED_THD可以根据图片大小而变化,即,对于不同的图片大小,SHARED_THD可以是不同的。在一些实施例中,可以从编码器向解码器发信SHARED_THD。在发信SHARED_THD中的单元的最小大小还可以在序列级别(sequence level)、图片级别、切片级别或PU级别中被分别编码。在一些实施例中,要求所选择或识别的共享子树根完全在当前图片内。如果子树根在图片边界之外有一些像素,则该子树将不用作共享子树根。
在一些实施例中,共享边界的根CU(或父CU)或大小/深度/形状/宽度/高度被用于导出共享候选列表。导出共享候选列表时,对于任何基于位置的导出(例如,根据当前块/CU/PU位置/大小/深度/形状/宽度/高度导出参考块位置),使用根CU或共享边界的位置和形状/大小/深度/宽度/高度。
在一些实施例中,根CU或共享边界的大小/深度/形状/区域/宽度/高度可以是预先定义的或以序列/图片/切片/图块/CTU行级别(row-level)或预先定义的区域(例如CTU或CTU行)发信。根CU或共享候选列表的共享边界可以是正方形或非正方形的。根CU或共享边界的大小/深度/形状/区域/宽度/高度可以被预先定义和/或取决于输入图片的大小/深度/宽度/高度。
在一些实施例中,如果当前CU大于或等于定义的阈值区域/大小/形状/面积/宽度/高度,并且子分区之一或所有子分区或某些子分区为小于定义的阈值区域/大小/形状/面积/宽度/高度,则当前CU是根CU或共享边界。在一些实施例中,如果当前CU的深度小于(例如,浅于)或等于定义的阈值深度,并且子分区之一或所有子分区或某些子分区的深度比定义的阈值深度大(例如深于),则当前CU是根CU或共享边界。
在一些实施例中,如果当前CU小于或等于定义的阈值区域/尺寸/形状/面积/宽度/高度,并且当前CU的父CU大于定义的阈值区域/大小/形状/面积/宽度/高度,当前CU是共享候选列表的根CU(即共享边界)。例如,如果定义的阈值区域为1024,当前CU大小为64x32(宽度为64,高度为32),则使用垂直TT划分(64x32 CU分为16x32子CU,32x32子-CU和16×32子CU),在一个实施例中,64×32当前CU是根CU。此64x32 CU中的子CU使用基于64x32CU的共享候选列表。64x32当前CU可能未标识为根CU。而是将16x32子CU,32x32子CU和16x32子CU标识为根CU。在一些实施例中,如果当前CU的深度大于(例如,深于)或等于定义的深度,并且父CU小于(例如,浅于)所定义的深度,则当前CU为根CU。
在一些实施例中,当在当前CU上执行TT划分为三个不同大小的分区时,根CU或共享边界区域/大小/深度/形状/面积/宽度/高度在不同的TT分区中可以是不同的。例如,对于通过TT分为第一、第二和第三分区的当前CU,对于第二分区,根CU或共享边界区域/大小/深度/形状/面积/宽度/高度的阈值为与CU相同。然而,对于第一和第三分区,根CU或共享边界区域/大小/形状/面积/宽度/高度的阈值(或用于识别其的阈值)相对于第二分区可以除以2(或深度增加1)。
在一些实施例中,为QT分区或QT划分CU定义了根CU或共享边界。如果叶QT CU等于或大于定义的阈值区域/大小/QT深度/形状/面积/宽度/高度,则将根CU或共享边界标识或定义为叶QT CU区域/大小/QT深度/形状/面积/宽度/高度。QT叶CU内的所有子CU(例如,被BT或TT划分或分区)使用QT叶CU作为根CU或共享边界。如果QT CU(不是QT叶CU)等于定义的阈值区域/大小/QT深度/形状/面积/宽度/高度,则此QT CU用作根CU或共享边界。QT CU内的所有子CU(例如,被QT、BT或TT划分或分区)使用QT CU作为根CU或共享边界。在一个示例中,根CU或共享边界的区域/大小/QT深度/形状/面积/宽度/高度被用于导出参考块位置。在另一示例中,当前CU的区域/大小/QT深度/形状/面积/宽度/高度被用于导出参考块位置。如果参考块位置在根CU或共享边界的内部,则将参考块位置移到根CU或共享边界的外部。在另一示例中,当前CU的区域/大小/QT深度/形状/面积/宽度/高度被用于导出参考块位置。如果参考块位置在根CU或共享边界之内,则不使用参考块。
在上述深度(或定义的用于识别根CU或共享候选列表的共享边界的阈值深度)中,该深度可以等于(((A*QT深度)>>C)+((B*MT深度)>>D)+E)>>F+G或((((A*QT深度)>>C)+((B*BT深度)>>D)+E)>>F+G,其中A、B、C、D、E、F、G是整数。例如,深度可以等于2*QT深度+MT深度或2*QT深度+BT深度或QT深度+MT深度或QT深度+BT深度。
一些实施例为共享的候选列表或非正方形合并估计区域(merge estimationregion,简写为MER)提供阈值定义(或用于定义阈值的方法)。令共享候选(或MER)阈值表示为T。共享边界是CU划分树中的祖先(例如,父代)节点,表示为ANC_NODE。选择共享边界(或ANC_NODE)以满足以下条件:
条件1:ANC_NODE(的大小)<=T
条件2:ANC_NODE的父对象(的大小)>T
条件3:ANC_NODE的像素位于当前图片边界内。视频编码器通过以下方式搜索满足这些条件的ANC_NODE:(i)从叶CU追溯(在划分树上)追溯到CTU根,或(ii)从CTU根(在划分树上)向下到叶CU。在一些实施例中,条件2可能不存在。如果叶CU在图片边界附近,则对于一个节点,如果满足条件1和2,但不满足条件3,则该节点将不是ANC_NODE,并且视频编解码器转至子CU,以搜索ANC_NODE。
在一些实施例中,对ANC_NODE的确定是从CTU根向下(在划分树上)到叶CU的搜索过程,并且选择共享边界(或ANC_NODE)以满足这些条件:
条件1:ANC_NODE(的大小)>=T.
条件2:对于解码,一个划分子项(splitting child)(例如BT划分或TT划分或QT划分)的大小 条件3:ANC_NODE的像素位于当前图片边界内。在一些实施例中,条件1可能不存在。如果叶CU在图片边界附近,则对于一个节点,如果满足条件1和2,但不满足条件3,则该节点将不会被标识为ANC_NODE,并且视频编码器将进入子CU,以搜索ANC_NODE。对于条件2,当前CU的最小划分子项(如果当前CU大小=cur_size)为:对于QT:cur_size/4,对于TT:cur_size/4,对于BT:cur_size/2。在一些实施例中,如果满足条件1和2但不满足条件3,则当前CU不是ANC_NODE,并且视频编解码器转至子CU以在条件1、2和3符合ANC_NODE的情况下搜索节点或子CU。如果对于叶CU,条件1、2和3不全部满足,则该叶CU将不具有共享模式(例如,没有共享候选列表),并且视频编解码器为叶CU本身生成合并模式列表。例如,如果T=64,并且当前节点或CU的大小为128,则在解码器侧,此节点将进一步划分为TT(子节点1为32,子节点2为64,子节点3为32),则ANC_NODE是当前节点(大小128)。再举一个例子,如果T=64并且当前节点或CU的大小为128,则若在解码器侧该节点被进一步划分为BT(子节点1为64,子节点2为64),则当前节点不是ANC_NODE。 在一些实施例中,共享边界是CU划分树中一个祖先(父)节点的CU节点组(Groupof CU node),表示为SHARED_BOUND。“CU节点组”是属一个公共父节点或一个公共祖先节点的几个非重叠CU/节点(在CU划分树节点中),这些CU节点可以合并为一个矩形区域。在一个实施例中,CU节点组的CU必须全部是公共父节点的“1级”子节点。在一些实施例中,该组CU节点中的CU可以具有相同的祖先节点,但是不一定是“1级”公共父节点。图16示出了“CU节点组”的示例。在图中,“CU节点组”有2个子CU占据了一半的父节点。SHARED_BOUND的确定是从CTU根向下(在划分树上)到叶CU的搜索过程。选择共享边界(或SHARED_BOUND)以满足以下条件: 条件1:SHARED_BOUND(的大小)>=T. 条件2:对于解码,“CU节点组”内的一个CU节点 条件3:SHARED_BOUND的像素位于当前图片边界内。在一些实施例中,条件1可能不存在于图片边界附近。这是因为如果叶CU在图片边界附近,则为了满足条件3,可以在图片边界附近放弃或舍弃条件1。 在一些实施例中,共享列表概念可以应用于CPR。CPR的合并列表可以在共享边界或根CU上共享并生成(此处共享边界是指共享根边界或共享矩形边界)。合并列表可以包括CPR候选或非CPR候选,但是共享列表可以存储两种类型,并且可以在共享边界上生成。 对于CPR中的双树(dual-tree)流,在某些情况下,亮度将运行叶CU扫描,而色度将再次运行,即,对亮度和色度均执行叶CU扫描。在这种情况下,亮度情况和色度情况的共享边界可能不同。在一些实施例中,生成用于亮度情况的CPR的共享列表,然后生成用于色度情况的CPR的共享列表。即,亮度和色度的共享阈值可以不同,并且它们的共享边界可以不同。对于多假设合并(多假设:合并帧间+帧内,或合并帧间+合并帧间,或合并帧间+AMVP帧间),对合并列表执行后处理以移除所有CPR候选。(从共享候选列表中)移除CPR候选也可以在共享边界上执行。 一些实施例基于共享候选列表为合并模式提供共享合并索引和共享参考索引。“用于共享的子CU”可以指代使用共享候选列表的子树内或“共享边界”内的CU。 为了使用共享合并索引,在合并模式下,不仅每个“用于共享的子CU”的合并候选列表彼此相等(使用共享合并候选列表),而且每个“用于共享的子CU”的最终选择的合并索引彼此相等(使用共享的合并候选索引)。为了将共享参考索引用于合并模式,在合并模式下,不仅每个“用于共享的子CU”的合并候选列表彼此相等(使用共享的合并候选列表),每个“用于共享的子CU”都选择了合并索引,其对应的候选具有的参考索引等于“用于共享的子CU”的所有其他CU的选定合并索引。 对于一些实施例,共享候选列表、共享合并索引和其他共享属性的方法可以应用于其他类型的合并列表构造方法,诸如基于历史的合并模式构造和非相邻合并候选。也就是说,共享属性提议或共享候选列表通常适用于所有合并模式算法和AMVP模式算法。此外,在一些实施例中,发信标记以打开或关闭候选列表共享方法。在一些实施例中,可以发信标志以指示是否启用了共享候选列表。发信中单位的最小大小也可以按序列级别、图片级别、切片级别或PU级别分别编码。 IV.示例的视频编码器 图17示出了可使用共享候选列表来编码CTU内的多个CU的实例视频编码器1700。如图所示,视频编码器1700从视频源1705接收输入视频信号,并将该信号编码为比特流1795。视频编码器1700具有若干组件或模块,用于对来自视频源1705的信号进行编码,至少包括选自以下的一些组件:变换模块1710、量化模块1711、逆量化模块1714、逆变换模块1715、图片内估计模块1720、帧内预测模块1725、运动补偿模块1730、运动估计模块1735、环路滤波器1745、重构图片缓冲器1750、MV缓冲器1765和MV预测模块1775以及熵编码器1790。运动补偿模块1730和运动估计模块1735是帧间预测模块1740的一部分。 在一些实施例中,模块1710至1790是由计算设备或电子装置的一个或多个处理单元(例如,处理器)执行的软件指令的模块。在一些实施例中,模块1710-1790是由电子装置的一个或多个集成电路(IC)实现的硬件电路的模块。尽管将模块1710–1790图示为单独的模块,但是某些模块可以组合为单个模块。 视频源1705提供原始视频信号,该原始视频信号无需压缩即可呈现每个视频帧的像素数据。减法器1708计算视频源1705的原始视频像素数据与来自运动补偿模块1730或帧内预测模块1725的预测像素数据1713之间的差。变换模块1710将该差(或剩余像素数据或残差信号1709)转换成变换系数(例如,通过执行离散余弦变换(DCT))。量化模块1711将变换系数量化为量化数据(或量化系数)1712,其由熵编码器1790编码为比特流1795。 逆量化模块1714对量化数据(或量化系数)1712进行逆量化以获得变换系数,并且逆变换模块1715对变换系数执行逆变换以产生重构残差1719。重构残差1719与预测像素数据1713相加产生重构像素数据1717。在一些实施例中,重构像素数据1717被临时存储在行缓冲器(未示出)中,用于图片内预测和空间MV预测。重构像素由环路滤波器1745滤波,并存储在重构图片缓冲器1750中。在一些实施例中,重构图片缓冲器1750是视频编码器1700外部的存储器。在一些实施例中,重构图片缓冲器1750是视频编码器1700内部的存储器。 图片内估计模块1720基于重构的像素数据1717执行帧内预测以产生帧内预测数据。帧内预测数据被提供给熵编码器1790,以被编码为比特流1795。帧内预测数据还被帧内预测模块1725用来产生预测像素数据1713。 运动估计模块1735通过产生MV来执行帧间预测,其中,MV针对存储在重构图片缓冲器1750中的先前解码的帧的参考像素数据。这些MV被提供给运动补偿模块1730以产生预测像素数据。 代替对比特流中的完整的实际MV进行编码,视频编码器1700使用MV预测来生成预测的MV,并且将用于运动补偿的MV与预测的MV之间的差编码为残差运动数据并存储在比特流1795。 MV预测模块1775基于为对先前的视频帧进行编码而生成的参考MV(即,用于执行运动补偿的运动补偿MV)来生成预测MV。MV预测模块1775从MV缓冲器1765中的先前视频帧中撷取参考MV。视频编码器1700将为当前视频帧生成的MV存储在MV缓冲器1765中,作为用于生成预测MV的参考MV。 MV预测模块1775使用参考MV来创建预测的MV。可以通过空间MV预测或时间MV预测来计算预测的MV。熵编码器1790将当前帧的预测MV和运动补偿MV(MC MV)之间的差(残差运动数据)编码到比特流1795中。 熵编码器1790通过使用诸如上下文自适应二进制算术编码(CABAC)或霍夫曼编码的熵编码技术将各种参数和数据编码到比特流1795中。熵编码器1790将各种报头元素、标志以及量化的变换系数1712以及残差运动数据作为语法元素编码到比特流1795中。比特流1795又被存储在存储设备中或者通过通信介质,例如网络,被发送到解码器。 环路滤波器1745对重构的像素数据1717执行滤波或平滑操作,以减少编码的伪像,特别是在像素块的边界处。在一些实施例中,执行的滤波操作包括采样自适应偏移(SAO)。在一些实施例中,滤波操作包括自适应环路滤波器(ALF)。 图18说明视频编码器1700的实施共享候选列表的部分。如图所示,运动补偿模块1730包括一个或多个CU运动补偿模块1831-1834。每个CU运动补偿模块处理一个叶CU的编码。当对CU运动补偿模块1831-1834的各CU进行编码时,CU运动补偿模块1831-1834可以访问共享候选列表1800的内容以及重构的图片缓冲器1750的内容。每个CU运动补偿模块从共享候选列表中选择预测候选,并且从重构图片缓冲器1750中撷取相应的采样,以通过运动补偿来执行预测。来自不同的CU运动补偿模块1831-1834的预测被用作预测像素数据1713。 重要的是要注意,即使被编码的CU是彼此相邻的,不同的CU补偿模块1831-1834仍可以并行地对其各自的CU执行运动补偿。这是因为使用共享候选列表的CU之间没有相互依赖关系,因此可能会同时进行编码。 从MV缓冲器1765撷取共享候选列表1800的内容,该MV缓冲器1765存储由共享边界定义的区域的各个相邻的运动向量,该共享边界可以对应于CTU的根CU或子树。共享候选列表1800从MV缓冲器1765包括的运动向量可以包括各种类型的合并或AMVP候选,诸如仿射候选、IBC候选、子PU候选、基于历史的候选、非相邻候选等。基于历史的候选可以被存储在历史缓冲器1810中,该历史缓冲器是存储先前编码的CU的合并候选的FIFO。 图19概念性地示出了用于使用共享候选列表来编码多个CU的过程1900。在一些实施例中,实现编码器1700的计算设备的一个或多个处理单元(例如,处理器)通过执行存储在计算机可读介质中的指令来执行过程1900。在一些实施例中,实现视频编码器1700的电子装置执行过程1900。 视频编码器接收(在步骤1910)视频序列中当前图片的CTU的数据。数据可以是来自视频源的当前图片中与CTU对应的区域的原始像素数据。可以将CTU作为QT、BT或TT划分树划分为CU或子CU。 视频编码器识别(在步骤1920处)包含CTU中的多个CU(或像素块)的共享边界。共享边界可以对应于CTU的子树的根。可以基于CU大小阈值(SHARED_THD)来识别共享边界。在一些实施例中,通过遍历CTU以识别大于或等于CU大小阈值的CU并且该CU是小于阈值的子CU的父CU,来标识共享边界。在一些实施例中,通过遍历CTU以标识小于或等于CU大小阈值的CU并且该CU是大于该阈值的父CU的子CU,来标识共享边界。然后,将所识别的CU的边界定义为共享边界。 视频编码器基于由共享边界定义的区域的空间或时间相邻来识别(在步骤1930)共享候选列表的一个或多个预测候选。该区域可以对应于CU,并且共享候选列表可以用作CU的合并候选列表。共享候选列表包括的运动向量可以包括各种类型的合并或AMVP候选,例如仿射候选、IBC候选、子PU候选、基于历史的候选、不相邻的候选等。 视频编码器通过使用从共享候选列表中选择的一个或多个预测候选来对共享边界包含的一个或多个CU进行编码(在步骤1940处)。所选择的预测候选用于执行运动补偿预测。被编码的CU是CTU的叶CU。在一些实施例中,并非共享边界内的所有叶CU都使用共享候选列表来编码,而是仅具有与根CU相同的特征的叶CU可以使用共享候选列表来编码。编码的CU作为语法元素的编码比特(code bit)存储在比特流中。 V.示例的视频解码器 图20示出实施共享候选列表的实例视频解码器2000。如图所示,视频解码器2000是图片解码或视频解码电路,其接收比特流2095并将比特流的内容解码为视频帧的像素数据以供显示。视频解码器2000具有用于解码比特流2095的若干组件或模块,包括选自逆量化模块2005、逆变换模块2010、帧内预测模块2025、运动补偿模块2030、环路滤波器2045、解码图片缓冲器2050、MV缓冲器2065、MV预测模块2075和解析器2090中的一些组件。运动补偿模块2030是帧间预测模块2040的一部分。 在一些实施例中,模块2010-2090是由计算设备的一个或多个处理单元(例如,处理器)执行的软件指令的模块。在一些实施例中,模块2010-2090是由电子装置的一个或多个IC实现的硬件电路的模块。尽管模块2010-2090被图示为单独的模块,但是某些模块可以组合为单个模块。 解析器2090(或熵解码器)接收比特流2095,并根据由视频编码或图片编码标准定义的语法来执行初始解析。解析的语法元素包括各种报头元素、标志以及量化的数据(或量化的系数)2012。解析器2090通过使用诸如上下文自适应二进制算术编码(CABAC)或霍夫曼编码的熵编码技术解析各种语法元素。 逆量化模块2005对量化数据(或量化系数)2012进行去量化以获得变换系数,并且逆变换模块2010对变换系数2016执行逆变换以产生重构残差信号2019。将来自帧内预测模块2025或运动补偿模块2030的预测像素数据2013添加到重构残差信号2019,以产生解码像素数据2017。解码像素数据由环路滤波器2045滤波,并存储在解码图片缓冲器2050中。在一些实施例中,解码图片缓冲器2050是视频解码器2000外部的存储器。在一些实施例中,解码图片缓冲器2050是视频解码器2000内部的存储器。 帧内预测模块2025从比特流2095接收帧内预测数据,并据此从存储在解码图片缓冲器2050中的解码像素数据2017产生预测像素数据2013。在一些实施例中,解码像素数据2017也存储在用于图片内预测和空间MV预测的行缓冲器(未示出)中。 在一些实施例中,解码图片缓冲器2050的内容用于显示。显示设备2055或者撷取解码图片缓冲器2050的内容以直接显示,或者将解码图片缓冲器的内容撷取到显示缓冲器。在一些实施例中,显示设备通过像素传输从解码图片缓冲器2050接收像素值。 运动补偿模块2030根据运动补偿MV(MC MV)从存储在解码图片缓冲器2050中的解码像素数据2017产生预测像素数据2013。通过将从比特流2095接收到的残差运动数据与从MV预测模块2075接收到的预测MV相加,对这些运动补偿MV进行解码。 MV预测模块2075基于为解码先前的视频帧而生成的参考MV(例如,用于执行运动补偿的运动补偿MV)生成预测的MV。MV预测模块2075从MV缓冲器2065中撷取先前视频帧的参考MV。视频解码器2000将为解码当前视频帧而生成的运动补偿MV存储在MV缓冲器2065中,作为用于产生预测MV的参考MV。 环路滤波器2045对解码的像素数据2017执行滤波或平滑操作以减少编码的伪像,特别是在像素块的边界处。在一些实施例中,执行的滤波操作包括采样自适应偏移(SAO)。在一些实施例中,滤波操作包括自适应环路滤波(ALF)。 图21示出视频解码器2000的实施共享候选列表的部分。如图所示,运动补偿模块2030包括一个或多个CU运动补偿模块2131-2134。每个CU运动补偿模块处理一个叶CU的解码。当对CU运动补偿模块2131-2134的对应CU进行解码时,CU运动补偿模块2131-2134可以访问共享候选列表2100的内容以及解码图片缓冲器2050的内容。每个CU运动补偿模块从共享候选列表中选择预测候选,并且从解码图片缓冲器2050中撷取对应的采样,以通过运动补偿执行预测。来自不同的CU运动补偿模块2131-2134的预测被用作预测的像素数据2013。 值得注意的是,即使被编码的CU是彼此相邻的,不同的CU运动补偿模块2131-2134仍可以并行地对其各自的CU执行运动补偿。这是因为使用共享候选列表的CU之间没有相互依赖关系,因此可以同时进行解码。 从MV缓冲器2065撷取共享候选列表2100的内容,该MV缓冲器2065存储由共享边界定义的区域的各个相邻(neighbor)的运动向量,该共享边界可以对应于CTU的根CU或子树。由来自MV缓冲器2065的共享候选列表2100包括的运动向量可以包括各种类型的合并或AMVP候选,诸如仿射候选、IBC候选、子PU候选、基于历史的候选、非相邻候选等。基于历史的候选可以被存储在历史缓冲器2110中,该历史缓冲器是存储先前解码的CU的合并候选的FIFO。 图22概念性地示出了用于使用共享候选列表来解码多个CU的过程2200。在一些实施例中,实现解码器2000的计算设备的一个或多个处理单元(例如,处理器)通过执行存储在计算机可读介质中的指令来执行过程2200。在一些实施例中,实现视频解码器2000的电子装置执行过程2200。 视频解码器接收(在步骤2210)视频序列中当前图片的CTU的数据。数据可以用于在CTU中作为语法元素在比特流中编码或生成的像素块。可以将CTU作为QT、BT或TT划分树划分为CU或子CU。 视频解码器识别(在步骤2220)包含CTU中的多个CU(或像素块)的共享边界。共享边界可以对应于CTU的子树的根。可以基于CU大小阈值(SHARED_THD)来识别共享边界。在一些实施例中,通过遍历CTU以识别大于或等于CU大小阈值的CU并且该CU是小于阈值的子CU的父CU,来标识共享边界。在一些实施例中,通过遍历CTU以标识小于或等于CU大小阈值的CU并且该CU是大于该阈值的父CU的子CU,来标识共享边界。然后,将所识别的CU的边界定义为共享边界。 视频解码器基于由共享边界定义的区域的空间或时间相邻来识别(在步骤2230)用于共享候选列表的一个或多个预测候选。该区域可以对应于CU,并且共享候选列表可以用作CU的合并候选列表。共享候选列表包括的运动向量可以包括各种类型的合并或AMVP候选,例如仿射候选、IBC候选、子PU候选、基于历史的候选、不相邻的候选等。 视频解码器通过使用从共享候选列表中选择的一个或多个预测候选来解码(在步骤2240处)共享边界所包围的一个或多个CU。所选择的预测候选用于执行运动补偿预测。被解码的CU是CTU的叶CU。在一些实施例中,并非共享边界内的所有叶CU使用共享候选列表来进行解码,而是仅具有与根CU相同的特征的叶CU可以使用共享候选列表来进行解码。解码的CU包括可被显示的像素数据。 VI.示例的电子系统 许多上述特征和应用被实现为被指定为记录在计算机可读存储介质(也称为计算机可读介质)上的一组指令的软件过程。当这些指令由一个或多个计算或处理单元(例如,一个或多个处理器,处理器的核心或其他处理单元)执行时,它们使处理单元执行指令中指示的动作。计算机可读介质的示例包括但不限于CD-ROM、闪存驱动器、随机存取存储器(RAM)芯片、硬盘驱动器、可擦除可编程只读存储器(EPROM)、电可擦除可编程只读存储器(EEPROM)等。计算机可读介质不包括无线或通过有线连接传递的载波和电子信号。 在本说明书中,术语“软件”旨在包括驻留在只读存储器中的固件或存储在磁存储器中的应用,其可以被读入存储器以供处理器处理。同样,在一些实施例中,可以将多个软件发明实现为较大程序的子部分,同时保留不同的软件发明。在一些实施例中,多种软件发明也可以被实现为单独的程序。最后,一起实现这里描述的软件发明的单独程序的任何组合都在本公开的范围内。在一些实施例中,软件程序在被安装以在一个或多个电子系统上运行时,定义了一种或多种执行和实施软件程序的操作的特定机器实现。 图23概念性地示出了实现本公开的一些实施例的电子系统2300。电子系统2300可以是计算机(例如,台式计算机、个人计算机、平板计算机等)、电话、PDA或任何其他种类的电子设备。这样的电子系统包括各种类型的计算机可读介质以及用于各种其他类型的计算机可读介质的接口。电子系统2300包括总线2305、(一个或多个)处理单元2310、图形处理单元(GPU)2315、系统存储器2320、网络2325、只读存储器2330、永久存储设备2335、输入设备2340,以及输出设备2345。 总线2305共同表示通信地连接电子系统2300的许多内部设备的所有系统、外围设备和芯片组总线。例如,总线2305将处理单元2310与GPU 2315、只读存储器2330、系统存储器2320和永久存储设备2335通信地连接。 处理单元2310从这些各种存储单元中撷取要执行的指令和要处理的数据,以便执行本公开的处理。在不同的实施例中,一个或多个处理单元可以是单个处理器或多核处理器。一些指令被传递到GPU 2315并由其执行。GPU 2315可以卸载各种计算或补充由处理单元2310提供的图片处理。 只读存储器(ROM)2330存储静态数据和由处理单元2310和电子系统的其他模块使用的静态数据和指令。另一方面,永久存储设备2335是读写存储设备。该设备是即使在电子系统2300关闭的情况下也存储指令和数据的非易失性存储单元。本公开的一些实施例使用大容量存储设备(诸如磁盘或光盘及其对应的磁盘驱动器)作为永久存储设备2335。 其他实施例使用可移动存储设备(例如软盘、闪存设备等,及其对应的磁盘驱动器)作为永久存储设备。像永久存储设备2335一样,系统存储器2320是读写存储设备。但是,与存储设备2335不同,系统存储器2320是易失性读写存储器,例如随机存取存储器。系统存储器2320存储处理器在运行时使用的一些指令和数据。在一些实施例中,根据本公开的处理被存储在系统存储器2320、永久存储设备2335和/或只读存储器2330中。例如,根据一些实施例,各种存储单元包括用于处理多媒体剪辑的指令。处理单元2310从这些各种存储单元中撷取要执行的指令和要处理的数据,以便执行一些实施例的处理。 总线2305还连接到输入和输出设备2340和2345。输入设备2340使用户能够向电子系统传达信息并选择命令。输入设备2340包括字母数位键盘和指示设备(也称为“鼠标控制设备”)、照相机(例如,网络摄像头)、麦克风或用于接收语音命令的类似设备等。输出设备2345显示由电子系统或输出数据生成的图片。输出设备2345包括打印机和显示设备,例如阴极射线管(CRT)或液晶显示器(LCD),以及扬声器或类似的音频输出设备。一些实施例包括既充当输入设备又充当输出设备的设备,例如触摸屏。 最后,如图23所示,总线2305还通过网络适配器(未示出)将电子系统2300耦合到网络2325。以这种方式,计算机可以是计算机网络(例如局域网(“LAN”)、广域网(“WAN”)或内联网(intranet)或网络网(network of networks),例如因特网)的一部分。电子系统2300的任何或所有组件可以与本公开结合使用。 一些实施例包括电子组件,例如微处理器,将计算机程序指令存储在机器可读或计算机可读介质(或者称为计算机可读存储介质、机器可读介质或机器可读存储介质)中的存储器和存储器。这种计算机可读介质的一些示例包括RAM、ROM、只读光盘(CD-ROM)、可记录光盘(CD-R)、可重写光盘(CD-RW)、只读数位多功能光盘(例如,DVD-ROM、双层DVD-ROM),各种可记录/可重写DVD(例如DVD-RAM、DVD-RW、DVD+RW等),闪存(例如SD卡、mini-SD卡、micro-SD卡等)、磁性和/或固态硬盘驱动器、只读和可记录的 尽管以上讨论主要是指执行软件的微处理器或多核处理器,但是许多上述特征和应用是由一个或多个集成电路执行的,例如专用集成电路(ASIC)或现场可编程控制器门阵列(FPGA)。在一些实施例中,这样的集成电路执行存储在电路本身上的指令。另外,一些实施例执行存储在可编程逻辑设备(PLD)、ROM或RAM设备中的软件。 如在本说明书和本申请的任何权利要求中使用的,术语“计算机”、“服务器”、“处理器”和“存储器”均指电子或其他技术设备。这些术语不包括个人或人群。为了说明的目的,术语“显示”或“显示中”是指在电子设备上显示。如在本说明书和本申请的任何权利要求中所使用的,术语“计算机可读介质”、“计算机可读媒介”和“机器可读介质”完全限于以可被计算机读取的形式存储信息的有形物理对象。这些术语不包括任何无线信号、有线下载信号和任何其他临时信号。 虽然已经参考许多具体细节描述了本公开,但是本领域技术人员将认识到,在不脱离本公开的精神的情况下,可以以其他特定形式来体现本公开。此外,许多附图(包括图19和图22)在概念上说明了过程。这些过程的特定操作可能无法按照所示和所描述的确切顺序执行。可以不在一个连续的一系列操作中执行特定操作,并且可以在不同的实施例中执行不同的特定操作。此外,该过程可以使用几个子过程来实现,或者作为更大的宏过程的一部分来实现。因此,本领域技术人员将理解,本公开不受限于前述说明性细节,而是由所附权利要求限定。 附加声明 文中描述的主题有时示出了包含在其它不同部件内的或与其它不同部件连接的不同部件。应当理解:这样描绘的架构仅仅是示例性的,并且,实际上可以实施实现相同功能的许多其它架构。在概念意义上,实现相同功能的部件的任何布置是有效地“相关联的”,以使得实现期望的功能。因此,文中被组合以获得特定功能的任意两个部件可以被视为彼此“相关联的”,以实现期望的功能,而不管架构或中间部件如何。类似地,这样相关联的任意两个部件还可以被视为彼此“可操作地连接的”或“可操作地耦接的”,以实现期望的功能,并且,能够这样相关联的任意两个部件还可以被视为彼此“操作上可耦接的”,以实现期望的功能。“操作上可耦接的”的具体示例包含但不限于:实体地可联结和/或实体地相互、作用的部件、和/或无线地可相互作用和/或无线地相互作用的部件、和/或逻辑地相互作用的和/或逻辑地可相互作用的部件。 此外,关于文中基本上任何复数和/或单数术语的使用,只要对于上下文和/或应用是合适的,所属技术领域具有通常知识者可以将复数变换成单数,和/或将单数变换成复数。 所属技术领域具有通常知识者将会理解,通常,文中所使用的术语,特别是在所附权利要求(例如,所附权利要求中的主体)中所使用的术语通常意在作为“开放性”术语(例如,术语“包含”应当被解释为“包含但不限干”,术语“具有”应当被解释为“至少具有”,术语“包含”应当被解释为“包含但不限干”等)。所属技术领域具有通常知识者还将理解,如果意在所介绍的权利要求陈述对象的具体数目,则这样的意图将会明确地陈述在权利要求中,在缺乏这样的陈述的情况下,不存在这样的意图。例如,为了帮助理解,所附权利要求可以包含使用介绍性短语“至少一个”和“一个或更多个”来介绍权利要求陈述对象。然而,这样的短语的使用不应当被解释为:用不定冠词“一个(a或an)”的权利要求陈述对象的介绍将包含这样介绍的权利要求陈述对象的任何权利要求限制为只包含一个这样的陈述对象的发明,即使在同一权利要求包含介绍性短语“一个或更多个”或“至少一个”以及诸如“一个(a)”或“一个(an)”之类的不定冠词的情况下(例如,“一个(a)”和/或“一个(an)”应当通常被解释为意味着“至少一个”或“一个或更多个”)也如此;上述对以定冠词来介绍权利要求陈述对象的情况同样适用。另外,即使明确地陈述了介绍的权利要求陈述对象的具体数目,但所属技术领域具有通常知识者也会认识到:这样的陈述通常应当被解释为意味着至少所陈述的数目(例如,仅有“两个陈述对象”而没有其他修饰语的陈述通常意味着至少两个陈述对象,或两个或更多个陈述对象)。此外,在使用类似于“A、B和C中的至少一个等”的惯用语的情况下,通常这样的结构意在所属技术领域具有通常知识者所理解的该惯用语的含义(例如,“具有A、B和C中的至少一个的系统”将包含但不限于具有单独的A、单独的B、单独的C、A和B—起、A和C一起、B和C一起和/或A、B和C一起的系统等)。在使用类似于“A、B或C中的至少一个等”的惯用语的情况下,通常这样的结构意在所属技术领域具有通常知识者所理解的该惯用语的含义(例如,“具有A、B或C中的至少一个的系统”将包含但不限于具有单独的A、单独的B、单独的C、A和B—起、A和C一起、B和C一起和/或A、B和C一起的系统等)。所属技术领域具有通常知识者将进一歩理解,不管在说明书、权利要求中还是在附图中,表示两个或更多个可替换的术语的几乎任意析取词和/或短语应当理解成考虑包含术语中的一个、术语中的任一个或所有两个术语的可能性。例如,短语“A或B”应当被理解成包含“A”、“B”、或“A和B”的可能性。 尽管已经在文中使用不同的方法、设备以及系统来描述和示出了一些示例性的技术,但是所属技术领域具有通常知识者应当理解的是:可以在不脱离所要求保护的主题的情况下进行各种其它修改以及进行等同物替换。此外,在不脱离文中描述的中心构思的情况下,可以进行许多修改以使特定的情况适应于所要求保护的主题的教导。因此,意在所要求保护的主题不限制于所公开的特定示例,而且这样的要求保护的主题还可以包含落在所附权利要求的范围内的所有实施及它们的等同物。
- 用于视频译码的共享候选列表和并行候选列表推导
- 用于共享候选者列表的方法和装置