一种RDN超分辨网络的训练方法及图像生成方法
文献发布时间:2023-06-19 10:27:30
技术领域
本发明属于超分辨领域,涉及改善一种与深度学习相结合的数据插值方法,可用于残差密集网络RDN(Residual Dense Network)超分辨网络的训练,具体涉及一种新的RDN超分辨网络训练方法及图像生成方法。
背景技术
大量的电子图像应用领域,人们经常期望得到高分辨率(简称HR)图像。高分辨率意味着图像中的像素密度高,能够提供更多的细节,而这些细节在许多实际应用中不可或缺。例如,高分辨率医疗图像对于医生做出正确的诊断是非常有帮助的;使用高分辨率卫星图像就很容易从相似物中区别相似的对象;如果能够提供高分辨的图像,计算机视觉中的模式识别的性能就会大大提高。自从上世纪七十年代以来,电荷耦合器件(CCD)、CMOS图像传感器已被广泛用来捕获数字图像。尽管对于大多数的图像应用来说这些传感器是合适的,但是当前的分辨率水平和消费价格不能满足今后的需求。例如,人们希望得到一个便宜的高分辨率数码相机/便携式摄像机,或者期望其价格逐渐下降;科学家通常需要一个非常高的接近35毫米模拟胶片的分辨率水平,这样在放大一个图像的时候就不会有可见的瑕疵。因此,寻找一种增强当前分辨率水平的方法是非常必须的。
图像插值,即增加单幅图像的尺寸可以增强图像的分辨率。传统的图像插值有最近邻插值法,双线性插值法,三次内插法等。都在一定程度上完成了图像超分辨率任务。但是传统方法没有解决一个基本问题,就是当图片处于低分辨率的时候,图片本身缺少足够的高频信息。传统方法经过线性差值之后,并没有补全足够的高频信息,这使得图片在放大之后面临,边缘模糊,图像不清晰的问题。
深度学习提供了另一种解决思路,通过神经网络强大的学习能力,以及用很深的网络来学习低分辨率图片所能提供的语义信息和边缘信息,通过非线性的方式生成对应的高分辨率图片。
深度学习网络在网络特别深的时候,会发生梯度消失问题,RDN网络在加深网络的同时吸取了desnet网络和resnet网络,将网络的中间信息处理层加深到了100多层,并取得了优秀的成绩,但是仍然存在信息填补不能满足需要的问题。
本发明聚焦RDN在现实应用中所存在的问题,进行了改进,通过使用生成模型的方法来重新训练RDN网络。
发明内容
针对现有技术中存在的技术问题,本发明的目的在于提供一种RDN超分辨网络的训练方法及图像生成方法,利用训练后的RDN超分辨网络对低分辨图像进行处理可以生成高分辨率图像。本发明将RDN超分辨网络放在GAN的框架上进行训练,有助于网络学到真实世界的数据分布。而GAN的框架一共分为两个部分,生成器和判别器。生成器部分就是RDN网络结构不变。在每个卷积层都添加普归一化,以促进网络训练的稳定性。而判别器由本发明设计。实验证明,如果判别器的判别能力更强的话,最后生成器生成的结果也会变得更好。为了提升判别起的能力,我们决定采用结合LSGAN的多尺度判别器。
传统GAN有模型崩塌以及生成器经常学习不到有用的东西的问题。模型崩塌的后果是生成模型无法生成多种样本。但是我们的任务是超分辨率,目的就是尽可能的接近原图,所以不必考虑模型崩塌的问题。至于生成器学习不到有用的东西的问题,究其原因是因为生成器和判别器学习能力不对等,经常出现判别器学习速度过快,损失很快降到0,从未导致的生成器无法进行梯度更新。LSGAN已经解决了这个问题,将损失函数变为MSE损失,变成与真实标签的距离。因此无论判别器的损失是否为0,生成器都可以进行更新。
提升网络的感受野,可以提升判别器的判别能力。最直接的做法就是使用更大的网络卷积核。例如从原来的3*3卷积核提升为5*5或7*7的卷积核。但是这么做的后果就是会使得判别器的网络变大,需要训练更多的参数,整个模型占用的显存更多,因此我们使用另一种方法,将生成器生成的图片进行不同程度的下采样,那么相对应的判别器的感受野也就获得了不同程度的扩大。对每张图像用bicubic插值方法,进行下采样2倍和4倍。
在使用GAN架构的同时,我们还引用了perceptual loss作为辅助训练的损失函数,用于计算损失值L
VGG
本发明的技术方案为:
一种RDN超分辨网络的训练方法,其特征在于,将RDN超分辨网络放在GAN的框架上进行训练,GAN的框架包括生成器和判别器,生成器为RDN超分辨网络;其步骤包括:
1)将训练所用的每对低分辨率样本图像和高分辨率样本图像进行归一化处理;其中低分辨率图像作为输入,高分辨率图像作为标签数据;
2)将低分辨率样本图像输入到生成器,提取该低分辨率样本图像的浅层信息;
3)提取到的浅层信息输入到生成器的RDB层,提取该低分辨率样本图像的边缘信息;
4)生成器将各RDB层提取的信息在信道维度上叠加在一起,然后进行卷积处理、上采样后重构生成高分辨率图像;
5)将步骤4)生成的高分辨率图像作为假数据,计算该假数据与对应标签数据之间的曼哈顿距离,得到损失值L
6)利用VGG网络提取该假数据的特征与对应标签数据的特征,然后计算该假数据的特征与对应标签数据的特征之间的损失值L
7)将步骤4)生成的高分辨率图像及其多个下采样数据作为假数据,将输入的该低分辨率样本图像对应的标签数据及其多个下采样后的数据作为真实数据,根据该假数据与该真实数据计算生成器中损失函数的损失值;
8)将步骤4)生成的高分辨率图像及其多个下采样数据作为假数据,将输入的该低分辨率样本图像对应的标签数据及其多个下采样后的数据作为真实数据,根据该假数据与该真实数据计算判别器中损失函数的损失值;
9)将步骤5)、6)、7)所得损失值以加权的方式叠加在一起,作为生成器的损失,进行生成器的参数更新;将步骤8)得到的损失值作为判别器的损失,进行判别器参数更新;重复步骤1)~8)的处理,直至达到收敛条件。
进一步的,所述判别器采用结合LSGAN的多尺度判别器。
进一步的,所述RDN超分辨网络采用kaiming初始化方式进行初始化。
进一步的,对每一RDB层的输出进行上采样并将前RDB层的上采样输出作为后一RDB层的条件。
进一步的,以步骤5)得到的损失值L
进一步的,采用公式损失函数
一种高分辨率图像生成方法,其步骤包括:将待处理的低分辨率图像输入到上述方法训练的RDN超分辨网络;该RDN超分辨网络提取该低分辨率图像的浅层信息,并将其输入到RDB层进行边缘信息提取,然后将经过不同RDB层提取的边缘信息在通道维度上叠加在一起,再进行卷积处理、上采样后,得到高分辨率图像。
附图说明
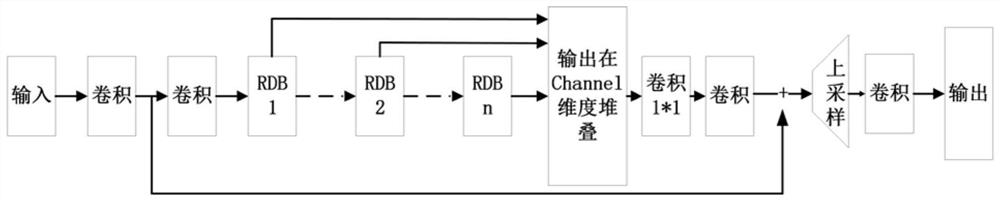
图1为RDN结构图。
图2为RDB结构图。
图3为判别器结构图;
(a)处理输入的原始图像,(b)处理原始图像经过下采样2倍和四倍处理后得到的图像。
具体实施方式
下面结合附图对本发明进行进一步详细描述。
RDN超分辨网络采用kaiming初始化方式,进行初始化,生成器模型采用RDN结构不变,判别器采用多尺度判别器,生成器的损失函数为标签图像与生成器生成图像的L1损失,LSGAN的损失,perceptual loss的加权和。只有LSGAN的判别器损失用来优化更新判别器。
RDN超分辨网络使用Adam优化器更新,并使用TTRU策略,用以促进GAN训练的稳定性,生成器和判别器都在原有基础上,对每一个卷积层都进行普归一化操作。具体RDN超分辨网络结构图如图1、图2所示。
RDN超分辨网络一共有8个RDB模块,每个RDB模块有16个Resnet模块,每个Resnet层由四个卷积层构成,网络学习率为0.0001,共训练200个epoch(遍历一次所有训练数据为一个epoch),在100个epoch过后,进行学习率衰减,衰减率为0.9。训练数据集为DIV2k,下采样方法为双三次插值算法(BICUBIC算法)。
网络一共分为分为两个大模块,生成器和判别器。神经网络有两个过程,训练过程和测试过程。
训练过程步骤:
1)对GAN的生成器和判别器参数初始化。
2)将训练所用的每一对低分辨率样本图像和高分辨率样本图像进行预处理,归一化等操作;其中低分辨率图像作为输入,高分辨率图像作为标签数据。
3)将低分辨率样本图像输入到生成器的特征提取层,提取到浅层信息即边缘信息。
4)提取到的浅层信息继续输入到RDB层,用以提取更丰富的边缘信息例如轮廓,颜色等,并在一定程度下,提取语义信息并进行语义填充。
5)将经过不同RDB层提取的信息在channel维度上叠加在一起(训练的时候,数据一共有四个维度,BCHW。B是指batch,即一批处理几张;C是指channel,信道;H和W分别是行和列),然后经过卷积处理,因为我们发现,每个层都有可以进行上采样的能力,只不过能力不同,如果只将最后一RDB层的输出进行上采样,对整个网络尤其最后一RDB层的压力将会很大,将前面的RDB层的输出作为其后一RDB层的条件,辅助最后一RDB层,整个网络的输出将会变得更好,生成更清晰的图像。
6)将所有的RDB层的输出在channel维度上叠加在一起,经过卷积处理后,经过pixel shuffle upsample上采样后,经过卷积降低维度到三信道,这样就可以得到生成器重构生成的图片了。
7)将生成的图片作为假数据,将对应真实数据作为假数据的标签数据,求出他们之间的L1距离(像素矩阵的L1距离),得到L
8)求生成的图片与真实数据之间的perceptual loss,即他们经过VGG特征提取层之后得到的特征之间的L1距离(特征矩阵的L1距离),得到L
9)将生成的图片以及多个下采样后的数据作为假数据,将真实数据以及多个下采样后的数据作为标签数据,依据LSGAN网络提出的GAN loss计算公式,得到损失值L
其中,α和β为预先定义的超参数,我们将其设置为0.0001和0.001
10)将生成的图片以及多个下采样后的数据作为假数据,将真实数据以及多个下采样后的数据作为标签数据,得到GAN中D的loss。
11)将第7、8、9步中所有的损失以加权的方式叠加在一起,以步骤7)中求得的损失为主,剩下两个为辅,加在一起后,作为生成器的损失,进行生成器的参数更新。
12)将第10步的损失作为判别器的损失,进行判别器参数更新。
13)重复步骤2-12),并观察损失函数收敛情况,并注意定期保存模型,直到运行200个epoch或损失收敛。
测试过程步骤:
1)载入训练过程学习到的网络参数。
2)将图像进行预处理,归一化等操作。
3)将图像输入到生成器的特征提取层,提取到浅层信息即边缘信息。
4)提取到的浅层信息继续输入到RDB层,用以提取更丰富的边缘信息例如轮廓,颜色等。
5)将经过不同RDB层提取的信息在channel维度上叠加在一起,然后经过卷积处理,因为我们发现,每个层都有可以进行上采样的能力,只不过能力不同,如果只将最后一层的输出进行上采样,对整个网络尤其最后一层的压力将会很大,将前面的RDB层的输出作为条件,辅助最后一层,整个网络的输出将会变得更好。
6)将所有的RDB层的输出在channel维度上叠加在一起,经过卷积处理后,经过pixel shuffle upsample上采样后,经过卷积降低维度到三信道,这样就可以得到生成器生成的图片了。
7)将步骤6)生成的图像按归一化操作的逆操作进行还原,即可得到生成的图片。输入的测试图片是低分辨率图像,生成的图像是经过超分辨网络RDN之后得到的高分辨率图像。
实际应用中,只需要在使用之前,进行一遍训练过程,得到足够优秀的RDN的模型参数后,在使用时,只需要运行测试过程就可以得到优秀的经过超分辨率操作的高分辨率图片,即只需要将低分辨率图像输入到训练后的RDN超分辨网络里,经过前向传播即可得到高分辨率且清晰的图像。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 一种RDN超分辨网络的训练方法及图像生成方法
- 一种生成对抗网络的训练方法、动画图像生成方法