一种基于注意力的宽度图卷积神经网络模型及其训练方法
文献发布时间:2023-06-19 10:27:30
技术领域
本发明涉及图像处理及深度学习技术领域,特别是涉及一种基于注意力的宽度图卷积神经网络模型及其训练方法。
背景技术
随着图卷积神经网络机器学习研究地不断加深,能够聚集更丰富节点信息且能扩宽模型感受野、提升分类表现的高阶图卷积网络模型和高低阶图卷积网络模型先后被不同的研究者提出。现有的高阶图卷积网络模型和高低阶图卷积网络模型的分类表现在一定程度上都达到了研究者的预期,但它们仍有不足之处:高阶图卷积网络模型设计了一种包括一阶图卷积到P阶图卷积,不同阶卷积使用不同权重参数,利用两个高阶图卷积层学习高阶节点之间的关系和聚集不同距离邻域节点信息的高阶图卷积,且在每个高阶图卷积聚集了不同距离的邻域信息后,利用列连接将这些邻域信息进行拼接,最后通过一个全连接层融合这些邻域信息的网络架构,由于其采用不同阶卷积不同的权重参数、堆叠多个高阶图卷积层,及全连接融合不同距离邻域信息的技术必要会造成复杂度增大,参数量成倍增加,进而增加了过拟合风险;虽然高低阶图卷积网络模型采用权重共享机制一定程度上较少了参数量,但其同样堆叠了多层高低阶图卷积层使得模型的参数量和复杂度并没有显著减少,同样不能避免过拟合风险。此外,高阶图卷积网络模型和高低阶图卷积网络模型都未对不同距离邻域节点对于分类预测的重要性加以区分,而是同等重要的考虑不同距离邻域节点的贡献度,与现实信息有一定的偏差,一定程度上会影响分类预测的效果。
因此,如何基于现有高阶图卷积网络和高低阶图卷积网络的研究,区分不同距离邻域节点对分类预测的重要性,在保证现有模型的分类表现、减少计算复杂度和参数量及避免过拟合风险的基础上,使得模型的构建和应用更贴近现实是非常有意义的。
发明内容
本发明的目的是减少现有高阶图卷积网络和高低阶图卷积网络的计算复杂度和参数量,避免过拟合风险的同时,区分不同距离邻域节点对于预测任务的重要性,使得模型的构建和应用更贴近现实,进而提高分类表现。
为了实现上述目的,有必要针对上述技术问题,提供了一种基于注意力的宽度图卷积神经网络模型及其训练方法。
第一方面,本发明实施例提供了一种基于注意力的宽度图卷积神经网络模型,所述宽度图卷积神经网络模型模型依次包括、注意力高阶图卷积层、信息融合池化层和输出层;
所述输入层,用于接收训练数据集的图特征;
所述注意力高阶图卷积层,用于根据所述图特征进行零阶到k阶的注意力图卷积运算,得到图卷积数据;
所述信息融合池化层,用于根据所述图卷积数据进行零阶到k阶的特征融合,得到融合数据;
所述输出层,用于根据所述融合数据输出模型结果。
进一步地,所述注意力高阶图卷积层由在不同阶数的图卷积都引入注意力机制得到。
进一步地,在所述注意力高阶图卷积层的任一阶数图卷积引入新的自连接。
进一步地,所述注意力高阶图卷积层包括基于权重共享的零阶图卷积到k阶图卷积,表示为:
其中,X是图的输入矩阵,w是参数矩阵,
进一步地,所述宽度图卷积神经网络模型模型的输出层HGCN
其中,σ(·)为激活函数,SP(·)为信息融合函数,softmax(·)为多分类输出函数。
进一步地,所述σ激活函数为ReLU非线性激活函数。
进一步地,所述信息融合池化层采用SP求和信息融合池化,其计算公式如下:
第二方面,本发明实施例提供了一种基于注意力的宽度图卷积神经网络模型的训练方法,所述训练方法的步骤包括:
根据训练数据集进行预处理,得到预处理特征;
将所述预处理特征输入所述宽度图卷积神经网络模型,进行特征训练,得到训练结果。
进一步地,所述根据训练数据集进行预处理,得到预处理特征的步骤包括:
获取所述训练数据集,并确定所述训练数据集的类型;
根据所述训练数据集的类型,选取特定方法得到所述图的输入矩阵和正则化邻接矩阵;
将所有不同阶数的所述图的正则化邻接矩阵加权作和,得到预处理邻接矩阵;
将所述预处理邻接矩阵和所述图的输入矩阵作积,得到预处理特征。
进一步地,所述将所述预处理特征输入所述宽度图卷积神经网络模型,进行特征训练,得到训练结果的步骤包括:
将所述宽度图卷积神经网络模型的参数矩阵进行随机初始化,并将所述注意力分数初始化为特定值;
将所述预处理特征输入所述宽度图卷积神经网络模型,根据学习率优化结合所述训练数据集属性调整所述注意力分数,并采用损失函数和梯度下降法进行训练,得到收敛的参数矩阵。
上述本申请提供了一种基于注意力的宽度图卷积神经网络模型及其训练方法,通过所述模型及其训练方法,实现了采用仅有输入层、注意力高阶图卷积层、SP求和信息融合池化层及softmax函数输出层的基于注意力的宽度图卷积神经网络模型,结合该模型训练前的特征预处理方法,并依此得到精准分类的效果。与现有技术相比,该模型及其训练方法在实际分类应用上,不仅通过采用引入自连接赋予自身节点更高权重来聚集更多阶邻域间的更丰富的节点信息,且区分不同距离邻域节点对分类预测的贡献度的高阶图卷积,很好的提升了模型的学习能力和分类精度,还通过设计一层注意力高阶图卷积层,并在不同阶图卷积间采用权重共享机制,有效的减少了参数量、降低了模型的复杂度和训练难度,避免了过拟合的风险。
附图说明
图1是本发明实施例中基于注意力的宽度图卷积神经网络模型及其训练方法的应用场景示意图;
图2是基于注意力的宽度图卷积神经网络模型的示意图;
图3是采用SP信息融合池化层的基于注意力的高效宽度图卷积神经网络模型的示意图;
图4是图3基于注意力的宽度图卷积神经网络模型的训练方法的流程示意图;
图5是图4中步骤S11获取训练集数据预处理,得到预处理特征的流程示意图;
图6是图4中步骤S12将预处理特征输入基于注意力的宽度图卷积神经网络模型进行特征训练的流程示意图;
图7是本发明实施例中计算机设备的内部结构图。
具体实施方式
为了使本申请的目的、技术方案和有益效果更加清楚明白,下面结合附图及实施例,对本发明作进一步详细说明,显然,以下所描述的实施例是本发明实施例的一部分,仅用于说明本发明,但不用来限制本发明的范围。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供的基于注意力的宽度图卷积神经网络是对现有高阶图卷积神经网络和高低阶图卷积神经网络的改进,该模型及其训练方法,可以应用于如图1所示的终端或服务器上。其中,终端可以但不限于是各种个人计算机、笔记本电脑、智能手机、平板电脑和便携式可穿戴设备,服务器可以用独立的服务器或者是多个服务器组成的服务器集群来实现。服务器可采用基于注意力的宽度图卷积神经网络模型(HGCN
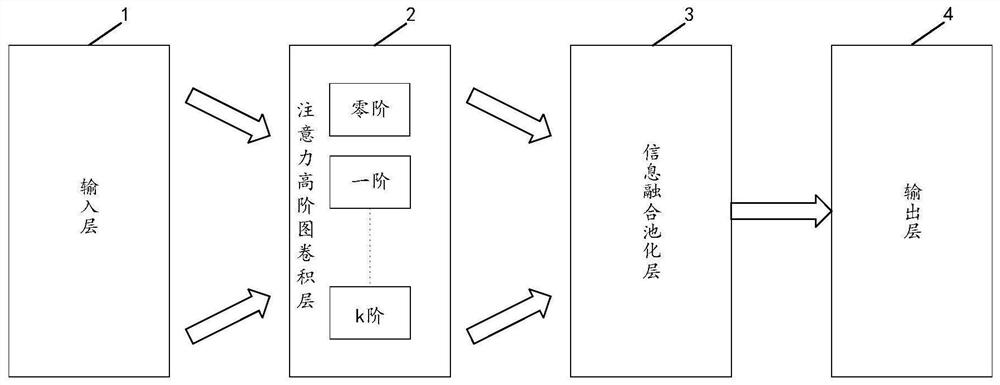
在一个实施例中,如图2所示,提供了一种基于注意力的宽度图卷积神经网络模型包括输入层1、注意力高阶图卷积层2、信息融合池化层3和输出层4;所述输入层1,用于接收训练数据集的图特征;所述注意力高阶图卷积层2,用于根据所述图特征进行零阶到k阶的注意力图卷积运算,得到图卷积数据;所述信息融合池化层3,用于根据所述图卷积数据进行零阶到k阶的特征融合,得到融合数据;所述输出层4,用于根据所述融合数据输出模型结果。
其中,注意力高阶图卷积层和信息融合池化层都只有1个,即基于注意力的宽度图卷积神经网络模型的结构为:输入层1与注意力高阶图卷积层2相连,注意力高阶图卷积层2与信息融合池化层3相连,信息融合池化层3再与采用softmax函数进行多分类输出的输出层4相连。
注意力机制源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类往往根据需求忽略部分可见信息,只关注信息特定的一部分。为了合理利用有限的视觉信息处理资源,人类需要选择视觉区域中的特定部分,然后集中关注它,从而筛选出有价值的信息,视觉注意力机制极大的提高了人类处理视觉信息的效率。深度学习中的注意力机制借鉴了人类视觉注意力机制的思维方式,以期从大量数据中快速筛选出高价值的信息。
本实施例中的注意力高阶图卷积层是在不同阶图卷积都引入注意力机制,且在任一阶数图卷积引入新的自连接的高阶图卷积层。其中,引入注意力机制是指利用一系列的注意力分数a
其中,
其中,X是图的输入矩阵,w是参数矩阵,
上述注意力高阶图卷积包括包括基于权重共享的零阶图卷积到k阶图卷积,使得注意力高阶图卷积的参数量与一阶图卷积的参数量保持一致,不仅通过在任一阶数图卷积引入新的自连接
其中,X是图的输入矩阵,w是参数矩阵,
上述图卷积最高阶数k=2时,即采用0阶、1阶和2阶邻域混合的HGCN
当k=3时,即采用0阶、1阶、2阶和3阶邻域混合的HGCN
当k=n时,即采用0阶到n阶邻域混合的HGCN
在上述模型中同一图卷积层的各阶邻域均采用相同权重参数,来实现权重共享和降低参数量,具体体现在公式(1)-(4)中参数W的选择。
本实施例中通过构建只有一层且同时引入注意力机制和自连接的高阶图卷积层的网络架构,不仅减少了参数量和模型的计算量,有效的提升了模型训练效率,而且基于自身节点特征对分类预测的影响更大的考虑,通过引入自连接加大自身节点信息的权重的方式提高了模型的分类效果,还采用给更重要的图卷积更高的权重,不重要的图卷积较小的权重的注意力分数打分原则来调整不同距离的邻域节点对于预测目标分类的贡献度,使得模型的构建和应用更贴合实际信息,达到进一步提高分类精度的目的。
在实际应用于大规模的分类训练时,需要先计算出
优选地,σ激活函数为ReLU(·)非线性激活函数。
其中,ReLU激活函数是用来进行非线性处理的。由于线性模型的表达力不够,且有些数据特征不一定是线性可分的,为了解决这一问题就在信息融合层之后采用激活函数进行非线性处理,常用的非线性激活函数包括sigmoid、tanh和ReLU、ElU、PReLU等,上述激活函数都可使用,但各有优劣,而本实施例中采用神经网络中用的最多的ReLU函数,它的公式定义如下:
f(x)=max(0,x),
即,保留大于等于0的值,其余所有小于0的数值直接改写为0。通过这种方法对卷积后产生的特征图中的值进行映射,就可以在特征提取时直接舍弃掉那些不相关联的数据,操作更方便。
由于非线性激活函数可以提高模型的表达能力,但对图分类任务用处不是很大,尤其是对于本实施例中只有一层注意力高阶图卷积层的宽度图卷积神经网络模型而言,是可以省略非线性激活的处理,进一步减少模型计算的复杂度,但可以能会损失一点精度,总体来说对模型的分类精度影响不大,因此,在该模型的实际应用中可以根据分类任务的具体情况决定是否需要使用非线性激活函数,若对精度上要求比较高可以选择使用非线性激活函数,若希望减少模型的计算复杂度提升模型的性能,可以省略非线性激活的处理。
优选地,信息融合池化层采用SP求和信息融合池化来融合从零阶到k阶的不同阶邻域的节点信息,其具体计算公式如下:
对应的采用SP信息融合的注意力高阶图卷积能聚集更多更丰富的邻域信息获得全局图结构信息的同时,还考虑了自身节点在分类预测时更加重要,及不同距离的邻域节点对于预测目标分类的贡献度不同的因素,如图3所示,模型的表达式如下:
其中,H为注意力高阶图卷积层的输出值,即为该模型的softmax函数输出层的输入值。
以一个具体的三阶实施例来说明上述本实施例中的信息融合方式,高阶的情况类似。假设邻域的阶数k=3,假设其零阶邻域为H
设a
本实施例采用基于SP信息融合的注意力高阶图卷积算法实现过程如下:
输入:
卷积运算:
信息融合:H
非线性激活:H=σ(H
本实施例中图网络先输入到注意力高阶图卷积进行上述的算法处理,再使用SP求和信息融合池化层来混合不同邻域的零阶到高阶的特征,经过非线性激活后输入softmax函数输出层得到分类概率结果的方法,能够在学习过程中保留更多更丰富的特征信息进行全局图拓扑的学习的同时,还区分了不同距离的邻域节点对于预测目标分类的贡献度,且考虑了预测时自身节点更重要的作用,进而很好地提升了学习效果。
在一个实施例中,如图4所示,任一上述基于注意力的宽度图卷积神经网络模型的训练方法的步骤包括:
S11、根据训练数据集进行预处理,得到预处理特征;
其中,如图5所示,所述获取训练数据集进行预处理,得到预处理特征的步骤S11包括:
S111、获取所述训练数据集,并确定所述训练数据集的类型;
其中,训练数据集根据实际的分类需求进行选择,比如文本分类的数据集可选取Reuters21578的R52和R8、20-Newsgroups(20NG)、Ohsumed(OH)以及Movie Review(MR),半监督分类可选取Cora、Citeseer、Pubmed,多视图分类可选取Modelnet10和Modelnet40等,每一种分类任务的数据集的内容都不相同,其类型也就不同。
S112、根据所述训练数据集的类型,选取特定方法得到所述自连接宽度图卷积神经网络模型的图的输入矩阵和正则化邻接矩阵。
其中,训练数据集的类型有上述文本数据集、半监督分类数据集、多视图分类数据集等多种类型,对于每种训练集数据在使用本实施的自连接宽度图卷积神经网络模型时,都要进行对应的预处理,得到模型的图的输入矩阵和图的正则化邻接矩阵。如当需要进行文本分类时,就需要将包括文档和标题的语料集数据进行处理构建对应的语料文本图网络,根据语料文本图网络得到模型训练使用的图的输入矩阵和图的正则化邻接矩阵。对于其它情形的数据集,如半监督数据集或多视图分类数据集等都有对应的预处理方法,在使用本实例中的模型进行分类时只需按照分类任务类型对应的常规方法将该任务对应的数据集转换为图的输入矩阵和图的正则化邻接矩阵即可。本申请后续实施例中,均以如表1所示的半监督数据集为例进行相关说明。
表1半监督分类经典数据集信息表
S113、将所有不同阶数的所述图的正则化邻接矩阵加权作和,得到预处理邻接矩阵;
其中,由于本申请构建的是只有一层注意力高阶图卷积层,没有多层图高阶卷积层,模型训练之前,可采用零阶到k阶图卷积注意力分数加权的方法对特征进行预处理,得到预处理邻接矩阵,则SP求和信息融合计算(5)式可以优化为:
且由于正则化邻接矩阵
S114、将所述预处理邻接矩阵和所述图的输入矩阵作积,得到预处理特征。
在经过上述预处理得到预处理邻接矩阵
S12、将所述预处理特征输入所述宽度图卷积神经网络模型,进行特征训练,得到训练结果。
其中,如图6所示,将所述预处理特征输入所述宽度图卷积神经网络模型,进行特征训练,得到训练结果的步骤S12包括:
S121、将所述宽度图卷积神经网络模型的参数矩阵进行随机初始化,并将所述注意力分数初始化为特定值;
其中,对模型参数矩阵进行随机初始化的方法有:权重服从高斯分布的Gaussian初始化、权重为均匀分布的Xavier初始化,及均值为0、方差为2/n的MSRA初始化。本实施例中的基于注意力的宽度图卷积神经网络模型参数矩阵的随机初始化时,可以根据实际分类需求结合上述三种初始化的特点进行选择,不会影响模型的应用效果。需要注意的是模型注意力分数的初始化值都设为1,后续在训练的过程中根据学习率优化结合所述训练数据集属性调整所述注意力分数,不同数据集对应的最大图卷积阶数不相同、各阶图卷积的注意力分数也不同。本实施例中要先确定Pubmed、Cora和Citeseer数据集对应的最大图卷积阶数后,在不同数据集的训练过程中以分类精度为依据分别在对应阶数的模型上进行注意力分数的调整。
S122、将所述预处理特征输入所述宽度图卷积神经网络模型,根据学习率优化结合所述训练数据集属性调整所述注意力分数,并采用损失函数和梯度下降法进行训练,得到收敛的参数矩阵。
其中,基于注意力的宽度图卷积神经网络模型训练的过程为:(1)对选用的训练数据集中的有效特征数据进行预处理得到的预处理特征并输入不同阶数的模型,使用初始化注意力分数和初始化参数矩阵及最大学习率进行正向传播得到分类结果,选取分类精度最高的阶数的模型作为该训练数据集后续训练的基准模型,如表2所示,基于Pubmed、Cora和Citeseer数据集上,基于注意力的宽度图卷积神经网络模型的最大阶数分别为21、8和4;(2)确定基于注意力的宽度图卷积神经网络模型的宽度值(最高阶数)后,依据低阶邻域节点比更高阶节点的重要性更大些,即近距离节点在预测分类时更重要的原则,对不同阶邻域节点的注意力分数值依次进行调整,并将调整后的注意力分数输入模型进行训练,经过正向传播得到分类结果,再通过损失函数计算交叉熵使用反向传播更新参数矩阵的梯度下降算法进行训练直至收敛,得到当前注意力分数下的收敛时的参数矩阵,并记录对应的分类精度;(3)重复步骤2的操作,不断调整注意力分数进行训练,直至得到分类精度更高的参数矩阵,作为该模型对应注意力分数下的收敛的参数矩阵,用作后续的分类测试使用,基于Pubmed、Cora和Citeseer数据集最大阶数的HGCN
表2 HGCN
表2说明:表中k是图卷积的最大阶数,模型的准确率以百分比表示,且该数字是10次运行的平均值。
本实施例中,模型训练使用的训练数据集为半监督分类节点的训练数据集Cora、Citeseer、Pubmed,根据该类训练数据集的特点,选用的损失函数为:
x
本申请实施例中模型基于半监督分类数据集进行分类训练,并分别与现有的图卷积神经模型的测试效果进行比对,结果如下表3所示:
表3 HGCN
表3说明:表中的准确率以百分比表示,且该数字是10次运行的平均值。
基于上述实验结果表3可知,本实施例提出了一种只具有一层既能同时聚集不同阶邻域节点信息,又能考虑自身节点对分类预测重要作用,且区分不同距离邻域节点对于预测目标分类的贡献度的高阶图卷积,和混合零阶到高阶不同邻域特征的SP信息融合池化层的基于注意力的宽度图卷积网络模型HGCN
在本申请上述实施例的实际应用中,若只想引入注意力机制,通过设置注意力分数的方法对不同距离邻域节点的分类贡献度进行区分,而不需要引入自连接进一步增加自身节点的权重时,可以将本申请上述各实施例中引入自连接的
需要说明的是,虽然上述流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,上述流程图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
图7示出一个实施例中计算机设备的内部结构图,该计算机设备具体可以是终端或服务器。如图7所示,该计算机设备包括通过系统总线连接的处理器、存储器、网络接口、显示器和输入装置。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统和计算机程序。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种基于注意力的宽度图卷积神经网络模型的训练方法。该计算机设备的显示屏可以是液晶显示屏或者电子墨水显示屏,该计算机设备的输入装置可以是显示屏上覆盖的触摸层,也可以是计算机设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
本领域普通技术人员可以理解,图7中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有同的部件布置。
在一个实施例中,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述基于注意力的宽度图卷积神经网络模型的训练方法的步骤。
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述基于注意力的宽度图卷积神经网络模型的训练方法的步骤。
综上,本发明实施例提供的一种基于注意力的宽度图卷积神经网络模型及其训练方法,其基于充分考虑现有高阶图卷积神经网络模型及高低阶图卷积神经网络模型的参数过多、复杂度大、训练效率低、过拟合风险,及未区分不同距离邻域节点对于预测目标分类的贡献度等多方面问题的基础上,提出了一种包括能捕捉多阶邻域信息、加大自身节点权重和区分不同距离邻域节点贡献度的注意力高阶图卷积层、混合不同阶邻域特征的SP信息融合池化层及softmax分类输出层的宽度图卷积神经网络模型,及与该模型对应的先进行特征预处理再进行训练的高效模型训练方法。该模型及其训练方法应用于实际分类测试时,采用注意力高阶图卷积层增加模型宽度、降低模型深度、减少参数量的同时,还能同时聚集多阶邻域信息、赋予自身节点更高的权重,且通过引入注意力分数区分不同距离邻域节点的分类贡献度,进而在扩宽模型感受野、避免了模型过拟合风险的同时,使得模型的构建和应用更贴合实际信息,进一步提升了模型的学习能力、稳定性和分类精度。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。
本说明书中的各个实施例均采用递进的方式描述,各个实施例直接相同或相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。需要说明的是,上述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种优选实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和替换,这些改进和替换也应视为本申请的保护范围。因此,本申请专利的保护范围应以所述权利要求的保护范围为准。
- 一种基于注意力的宽度图卷积神经网络模型及其训练方法
- 一种自连接宽度图卷积神经网络模型及其训练方法