一种基于无监督学习的时间序列异常检测方法及系统
文献发布时间:2023-06-19 10:27:30
技术领域
本发明涉及计算机数据安全技术领域,具体来说是一种基于无监督学习的时间序列 异常检测方法及系统。
背景技术
运营商内部有大量的服务器,不同的服务器有各自的作用域,涉及到敏感信息的服 务需要更严格的监控,以防止可能存在的攻击或者数据泄露。操作员在访问系统的行为具有时间上的关联性和周期性,可以通过构建时间序列,利用局部异常因子算法,结合DTW,做用户行为时间序列和自己类似的群体之间的比较,达到对敏感信息的访问进行 监控和异常检测的目的。
如申请号为202011012234.X公开的一种时间序列数据异常检测方法和装置,所述方 法包括:获多个时间序列数据,并对多个时间序列数据进行预处理;通过Tsfresh对预处理后的多个时间序列数据进行特征提取,并获取所提取的时间序列特征的贡献度信息; 根据贡献度信息对时间序列特征进行PCA降维;通过IForest对降维后的时间序列特征进 行标注,以构成样本集,其中,样本集包括训练集和测试集;通过训练集训练得到多种 分类模型;通过测试集测试每种分类模型的异常检测准确率;获取待检测时间序列数据, 并将待检测时间序列数据分别输入每种分类模型,以得到相应的异常检测结果;根据每 种分类模型的异常检测准确率和异常检测结果对多种分类模型进行投票融合,以确定最 终的异常检测结果。该方法为有标注的监督学习,通过提取时间序列的统计特征,结合 标注进行监督学习训练,
现有的时间序列的异常检测主要有:基于历史数据的统计检测,这种方法会有过多 的点被识别成异常点;利用预测加统计的方法,在现实场景中,用户操作可能存在的周期很长,而数据量相对较少,利用这种方法无法准确预测;通过计算时间序列的周期性 特征来挖掘机器行为的,但很多场景中本就存在机器行为,适用范围受限;通过抽取时 间序列统计特征,利用有监督算法进行分类,这种方法需要更多的人工干预和较多里历 史专家经验积累。由于各个岗位的操作行为必然有所不同,岗位内部也可能有着不同的 分工,操作员也可能有调岗的情况存在,所以对某一特定岗位做时间序列异常检测也很 容易造成过多的异常误报,而且大量的时间序列异常检测模型也存在管理困难,应用不 便的问题。
发明内容
本发明所要解决的技术问题在于提供一种有效解决标签样本缺失、准确率低、误报 率高问题的基于无监督学习的时间序列异常检测方法。
本发明通过以下技术手段实现解决上述技术问题的:
一种基于无监督学习的时间序列异常检测方法,包括以下步骤:
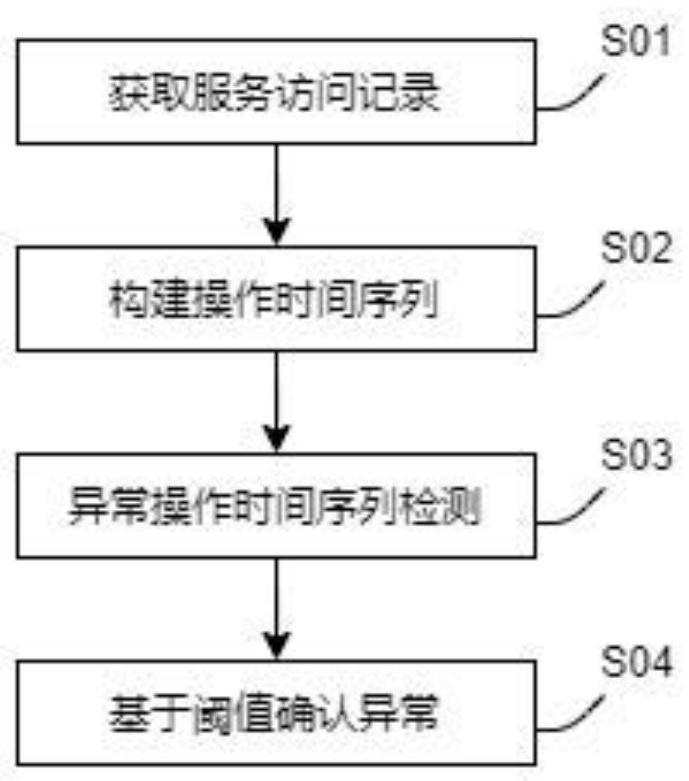
S01.获取服务访问记录,构建用于比较的时间序列;
S02.构建时间序列,选择设定的时间段,对用户访问服务的次数做统计,形成时间序列;
S03.异常操作时间序列检测,采用局部异常因子算法对步骤S02中的时间序列表做 局部异常因子检测,采用动态时间规整距离计算序列间的距离,并根据距离计算局部异常因子;
S04.根据步骤S03中计算出的局部异常因子进行筛选,超过阈值的操作为异常操作。
本发明提供了一种基于无监督学习的行为序列异常检测方法,在现实场景中,用户 的操作行为受岗位、工作内容影响,不同的岗位、不同的工作内容、甚至是工作调动都可能影响到操作上的时间序列,本发明通过将DTW距离替代局部异常因子算法中的距 离算法来对运营商或类似企业内部服务器访问行为进行异常检测,可以只应用一个模型, 在没有对用户进行分类的情况下做时间序列的无监督异常检测,不需要区分类型,不需 要根据序列的周期性、季节性等特征管理多个模型。有效解决标签样本缺失、准确率低、 误报率高等问题,同时有效提高了相关问题解决的普适性。
进一步的,在步骤S03之前,还包括对所述步骤S02中的时间序列进行平滑处理的步骤。
进一步的,所述步骤S03中的局部异常因子算法的具体计算过程为:一个时间序列为一个样本;假设时间序列集合为
S={s
其主要计算过程是:
1)计算各样本的k距离
D
其中D
2)计算各样本的k距离领域
样本s
3)计算可达距离
RD
其RD
4)计算局部可达密度
由于整个数据集可能有多类数据,不同类的点密度不一定相同,所以利用k距离邻域计算局部可达密度
其中,
5)计算局部异常因子
其中分子表示s
进一步的,所述样本间距离d(s
给定两个长度分别为n和m的时间序列:
1)创建距离矩阵D
其中
2)计算累加距离
其中d(i,j)表示
根据公式从样本(1,1)开始计算,直至计算到(m,n),最后样本(m,n)的累加距 离就是时间序列s
本发明还提供一种基于无监督学习的时间序列异常检测系统,包括:
获取服务访问记录模块,用于获取服务访问记录,构建用于比较的时间序列;
构建时间序列模块,选择设定的时间段,对用户访问服务的次数做统计,形成时间序列;
异常操作时间序列检测模块,采用局部异常因子算法对步骤S02中的时间序列表做 局部异常因子检测,采用动态时间规整距离计算序列间的距离,并根据距离计算局部异常因子;
异常操作确认模块,根据计算出的局部异常因子进行筛选,超过阈值的操作为异常 操作。
进一步的,还包括对时间序列进行平滑处理的平滑处理模块。
进一步的,所述异常操作时间序列检测模块中的局部异常因子算法的具体计算过程 为:一个时间序列为一个样本;假设时间序列集合为
S={s
其主要计算过程是:
1)计算各样本的k距离
D
其中D
2)计算各样本的k距离领域
样本s
3)计算可达距离
RD
其RD
4)计算局部可达密度
由于整个数据集可能有多类数据,不同类的点密度不一定相同,所以利用k距离邻域计算局部可达密度
其中,
5)计算局部异常因子
其中分子表示s
进一步的,所述样本间距离d(s
给定两个长度分别为n和m的时间序列:
1)创建距离矩阵D
其中
2)计算累加距离
其中d(i,j)表示
根据公式从样本(1,1)开始计算,直至计算到(m,n),最后样本(m,n)的累加距 离就是时间序列s
本发明还提供一种处理设备,包括至少一个处理器,以及与所述处理器通信连接的 至少一个存储器,其中:所述存储器存储有可被处理器执行的程序指令,所述处理器调用所述程序指令能够执行上述的方法。
本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储计算机指令, 所述计算机指令使所述计算机执行上述的方法。
本发明的优点在于:
本发明提供了一种基于无监督学习的行为序列异常检测方法,在现实场景中,用户 的操作行为受岗位、工作内容影响,不同的岗位、不同的工作内容、甚至是工作调动都可能影响到操作上的时间序列,本发明通过将DTW距离替代局部异常因子算法中的距离 算法来对运营商或类似企业内部服务器访问行为进行异常检测,可以只应用一个模型, 在没有对用户进行分类的情况下做时间序列的无监督异常检测,不需要区分类型,不需 要根据序列的周期性、季节性等特征管理多个模型。有效解决标签样本缺失、准确率低、 误报率高等问题,同时有效提高了相关问题解决的普适性。
附图说明
图1为本发明实施例中检测方法的流程框图;
图2为本发明实施例中两个一维序列示例图;
图3为本发明实施例中假设的4中类型序列得分曲线图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明 一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在 没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本实施例提供一种基于无监督学习的时间序列异常检测方法,包括以下步骤:
S01获取服务访问记录
操作员处在各自的岗位上,都有各自的职责,对服务数据的访问行为在各自的工作 周期或者相同岗位操作员的工作周期内都应该是类似的,而不同岗位间的操作差异度应 该更大,如果有异常于其他所有序列的操作行为,那么就很有可能是异常的。所以这里获取服务访问记录,用于构建用于比较的时间序列
S02构建时间序列
不同的业务可能存在不同的访问频率,选择合适的时间段(例如5分钟),对用户访问服务的次数做统计。
一般运营商类似的行业操作行为都和月相关,可直接按照月份划分周期,切割生成 一个个的时间序列。不同的业务如果有自己特定的周期性,也可以选择各自的周期进行划分
由于不同的业务可能有不同的特征,可以对上面构成的时间序列做一些移动平均或 缩放
S03异常操作时间序列检测
由于各个岗位的操作行为必然有所不同,岗位内部也可能有着不同的分工,操作员 也可能有调岗的情况存在,所以对某一特定岗位做时间序列异常检测也很容易造成过多 的异常误报,而且大量的时间序列异常检测模型也存在管理困难,应用不便的问题。采用局部异常因子算法,则可以在无监督的情况下一次性检测出各个岗位上可能存在的异常操作
局部异常因子算法(Local Outlier Factor)通过计算“局部可达密度”来反映一个样本的异常程度,一个样本的局部可达密度越大,这个样本就越有可能是异常样本。
本实施例中假设时间序列集合为
S={s
其主要计算过程是:
1)计算各样本的k距离
D
其中D
2)计算各样本的k距离领域
样本s
3)计算可达距离
RD
其RD
4)计算局部可达密度
由于整个数据集可能有多类数据,不同类的点密度不一定相同,所以利用k距离邻域计算局部可达密度
其中,
5)计算局部异常因子
其中分子表示s
然而,通常局部异常因子算法中计算样本距离的方式多为欧式距离、杰卡德差异等 数值向量距离或布尔向量距离,由于时间序列自身噪音及波动性的特点,相似的时间序列会呈现多样变化,这些距离在度量时间序列的相似度上存在一些局限性,所以本发明 中采用动态时间规整距离(DTW)来进行样本间的距离度量,也就是上面的样本间距离 d(s
本发明中样本间距离d(s
给定两个长度分别为n和m的时间序列:
1)创建距离矩阵D
其中
2)计算累加距离
其中d(i,j)表示
根据公式从样本(1,1)开始计算,直至计算到(m,n),最后样本(m,n)的累加距 离就是时间序列s
以序列[1,5,8,11,56,21,32,8]和[1,3,7,9,16,29,31,34,33]两个一维序列为例, 如图2所示:
各个网格中左下角的值为序列两点间的距离,示例中以各点差的绝对值作为距离, 网格右上角为累加距离,细箭头表示累加距离的来源方向,由于数值较多,没有全部标识出来,最后计算出右上角的DTW距离为71,DTW计算路径就是从最右上角按照累加距 离来源方向溯源而来的粗箭头所示。
在上面DTW距离算法的基础上,有很多优化方法(例如约束路径寻找范围来增加计算速度或者避免比较时对时间序列之间做过多的位移等等),其最终都是为了计算两个 时间序列的相似度。
利用DTW距离就能够比较好的度量时间序列间的距离,做到相似的操作时间序列距 离更近,差异较大的序列距离更远,从而能够应用局部异常因子算法来做时间序列的异常检测。
利用上述修改后的局部异常因子算法去检测S02中构建的操作时间序列。
假设存在图3所示的四种类型的序列,其中左上角7个序列,右上角7个序列,左 下角和右下角各1个序列
从图3中可以看出左下和右下中的序列是异于其他序列的
取k=5,即邻域有5个邻居,按照局部异常因子的计算原理,得分比1越大的就越异常
利用修改后的局部异常因子对上面的序列进行计算得出的得分如下:
[0.991,0.999,1.018,0.975,0.981,1.036,1.004,1.269,1.335,1.391,1.089,1.33 3,1.335,1.338,2.861,4.079]
从得分中可以看出左下和右下中的序列的得分,也就是最后两个得分明显是大于1 的;
S05设置阈值,对局部异常因子得分超过阈值的时间序列进行确认或进一步的排查。
在现实场景中,用户的操作行为受岗位、工作内容影响,不同的岗位、不同的工作内容、甚至是工作调动都可能影响到操作上的时间序列,本实施例通过将DTW距离替代 局部异常因子算法中的距离算法来对运营商或类似企业内部服务器访问行为进行异常 检测,可以只应用一个模型,在没有对用户进行分类的情况下做时间序列的无监督异常 检测,不需要区分类型,不需要根据序列的周期性、季节性等特征管理多个模型。
基于上述方法,本实施例提供一种基于无监督学习的时间序列异常检测系统,包括 以下步骤:
获取服务访问记录模块,操作员处在各自的岗位上,都有各自的职责,对服务数据的访问行为在各自的工作周期或者相同岗位操作员的工作周期内都应该是类似的,而不同岗位间的操作差异度应该更大,如果有异常于其他所有序列的操作行为,那么就很有 可能是异常的。所以这里获取服务访问记录,用于构建用于比较的时间序列
构建时间序列模块,不同的业务可能存在不同的访问频率,选择合适的时间段(例如5分钟),对用户访问服务的次数做统计。
一般运营商类似的行业操作行为都和月相关,可直接按照月份划分周期,切割生成 一个个的时间序列。不同的业务如果有自己特定的周期性,也可以选择各自的周期进行划分
由于不同的业务可能有不同的特征,可以对上面构成的时间序列做一些移动平均或 缩放
异常操作时间序列检测模块,由于各个岗位的操作行为必然有所不同,岗位内部也 可能有着不同的分工,操作员也可能有调岗的情况存在,所以对某一特定岗位做时间序列异常检测也很容易造成过多的异常误报,而且大量的时间序列异常检测模型也存在管理困难,应用不便的问题。采用局部异常因子算法,则可以在无监督的情况下一次性检 测出各个岗位上可能存在的异常操作。
局部异常因子算法(Local Outlier Factor)通过计算“局部可达密度”来反映一个样本的异常程度,一个样本的局部可达密度越大,这个样本就越有可能是异常样本。
本实施例中假设时间序列集合为
S={s
其主要计算过程是:
1)计算各样本的k距离
D
其中D
2)计算各样本的k距离领域
样本s
3)计算可达距离
RD
其RD
4)计算局部可达密度
由于整个数据集可能有多类数据,不同类的点密度不一定相同,所以利用k距离邻域计算局部可达密度
其中,
5)计算局部异常因子
其中分子表示s
然而,通常局部异常因子算法中计算样本距离的方式多为欧式距离、杰卡德差异等 数值向量距离或布尔向量距离,由于时间序列自身噪音及波动性的特点,相似的时间序列会呈现多样变化,这些距离在度量时间序列的相似度上存在一些局限性,所以本发明 中采用动态时间规整距离(DTW)来进行样本间的距离度量,也就是上面的样本间距离 d(s
本发明中样本间距离d(s
给定两个长度分别为n和m的时间序列:
1)创建距离矩阵D
其中
2)计算累加距离
其中d(i,j)表示
根据公式从样本(1,1)开始计算,直至计算到(m,n),最后样本(m,n)的累加距 离就是时间序列s
以序列[1,5,8,11,56,21,32,8]和[1,3,7,9,16,29,31,34,33]两个一维序列为例, 如图2所示:
各个网格中左下角的值为序列两点间的距离,示例中以各点差的绝对值作为距离, 网格右上角为累加距离,细箭头表示累加距离的来源方向,由于数值较多,没有全部标识出来,最后计算出右上角的DTW距离为71,DTW计算路径就是从最右上角按照累加距 离来源方向溯源而来的粗箭头所示。
在上面DTW距离算法的基础上,有很多优化方法(例如约束路径寻找范围来增加计算速度或者避免比较时对时间序列之间做过多的位移等等),其最终都是为了计算两个 时间序列的相似度。
利用DTW距离就能够比较好的度量时间序列间的距离,做到相似的操作时间序列距 离更近,差异较大的序列距离更远,从而能够应用局部异常因子算法来做时间序列的异常检测。
利用上述修改后的局部异常因子算法去检测S02中构建的操作时间序列。
假设存在图3所示的四种类型的序列,其中左上角7个序列,右上角7个序列,左 下角和右下角各1个序列
从图3中可以看出左下和右下中的序列是异于其他序列的
取k=5,即邻域有5个邻居,按照局部异常因子的计算原理,得分比1越大的就越异常
利用修改后的局部异常因子对上面的序列进行计算得出的得分如下:
[0.991,0.999,1.018,0.975,0.981,1.036,1.004,1.269,1.335,1.391,1.089,1.33 3,1.335,1.338,2.861,4.079]
从得分中可以看出左下和右下中的序列的得分,也就是最后两个得分明显是大于1 的;
异常操作确认模块,设置阈值,对局部异常因子得分超过阈值的时间序列进行确认 或进一步的排查。
本发明还提供一种处理设备,包括至少一个处理器,以及与所述处理器通信连接的 至少一个存储器,其中:所述存储器存储有可被处理器执行的程序指令,所述处理器调用所述程序指令能够执行上述的方法。
本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储计算机指令, 所述计算机指令使所述计算机执行上述的方法。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对 本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或 者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 一种基于无监督学习的时间序列异常检测方法及系统
- 一种基于无监督学习的时间序列异常检测方法