一种基于语义的跨指令架构二进制代码相似性检测方法
文献发布时间:2023-06-19 10:27:30
技术领域
本发明涉及漏洞检测技术领域,是一种基于语义的跨指令架构二进制代码相似性检测方法。
背景技术
以往的跨指令架构二进制代码相似性研究通常需要人工选择二进制代码的特征进行基本块嵌入,这些特征不仅需要专业知识,而且嵌入信息较少,不能完整表达二进制代码的语义。如Gemini、Genius。
为了解决上面的问题,SAFE、Asm2vec等方法将基于静态词表示的方法应用到二进制代码中。基本块中的运算符和操作数被表示为定维向量,基本块嵌入中的每个元素都是自动计算的实数,大大提高了基本块嵌入中的信息容量。但这些方法并不适合跨指令架构的基本块嵌入,因为不同指令架构中元素不可能出现在相同的语境中。
发明内容
本发明用于不同指令架构(如x86、ARM等)间二进制代码的相似性检测,可以用于漏洞检测、版权纠纷、恶意软件分析等领域,本发明提供了一种基于语义的跨指令架构二进制代码相似性检测方法,本发明提供了以下技术方案:
一种基于语义的跨指令架构二进制代码相似性检测方法,包括以下步骤:
步骤1:构建不同指令架构的汇编语言数据集,提取具有相同语义的不同指令架构的汇编代码对;
步骤2:对汇编代码基本块对进行归一化处理;
步骤3:进行汇编代码编码器的预训练,将汇编代码语义相似性任务转化为自然语言神经机器翻译任务;
步骤4:进行负采样,使模型能够区分语义不同但嵌入向量相近的基本块;
步骤5:结合字符串语义的基本块嵌入,将字符串嵌入向量与嵌入网络获得的嵌入向量进行对齐并拼接,组成新的基本块嵌入向量;
步骤6:嵌入网络的训练,输出x86和ARM的嵌入向量;
步骤7:进行二进制代码相似性比较,判断两个不同指令架构的二进制代码是否相似。
优选地,所述步骤1具体为:
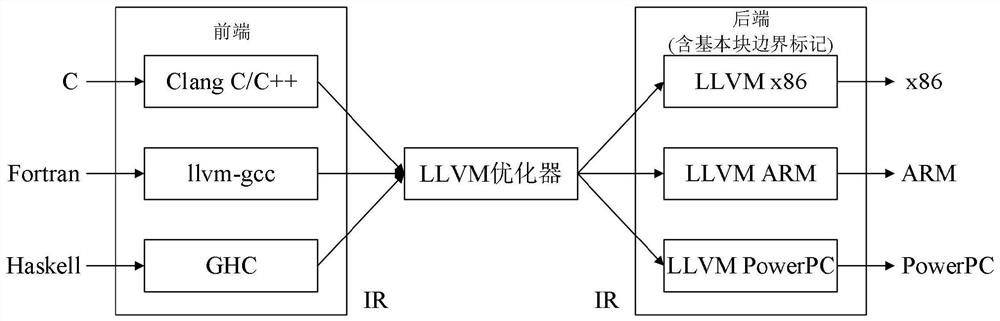
训练基本块嵌入具有相同语义的汇编代码基本块对,使用更改后的LLVM编译器将源代码编译成带有基本块边界标记的中间语言IR,经过优化器优化后再使用LLVM的不同后端生成不同指令架构的汇编语言,其中每个基本块拥有唯一标识符且边界已经被标记,通过正则过滤提取具有相同语义的不同指令架构的汇编代码对。
优选地,所述步骤2具体为:
对于寄存器,x86中的寄存器分为14类,其中包含指针寄存器、浮点数寄存器、四类通用寄存器、四类数据寄存器和四类地址寄存器,其中通用寄存器、数据寄存器和地址寄存器按照其存储的数据长度分为4种类型,分别是8位、16位、32位和64位;对于ARM中的寄存器被分为两类:通用寄存器和指针寄存器,对x86基本块的汇编代码进行归一化操作。
优选地,所述步骤3具体为:
将汇编代码语义相似性任务转化为自然语言神经机器翻译任务,根据生成的具有相同语义的不同指令架构汇编代码对训练当前主流的神经机器翻译模型Transformer,模型产生的中间向量包含丰富的汇编代码语义信息;
将x86基本块和ARM基本块分别表示为S=(s
其中,
得到x86编码器,将x86汇编代码嵌入为一个含有语义特征的向量。
优选地,所述步骤4具体为:
在预训练模型的基础上,通过测量两个x86基本块嵌入向量E
其中,d为嵌入维度,e
在训练嵌入网络时需要使用三元组,包括锚点、正样本、负样本,随机找到一个x86-ARM基本块对A,作为锚点和正样本,通过计算距离找到与基本块对A嵌入向量相近但语义不同的另一个x86-ARM基本块对B,当锚点为基本块对A的ARM基本块,则正样本为基本块对A的x86基本块,负样本为基本块对B的x86基本块;当锚点为基本块对A的x86基本块,则正样本为基本块对A的ARM基本块,负样本为基本块对B的ARM基本块。
优选地,所述步骤5具体为:
收集基本块中使用过的字符串,使用LSTM为每个字符串嵌入为一个向量,并使用Sum Pooling为每个基本块中的所有字符串向量计算出最终嵌入,将字符串嵌入向量与嵌入网络获得的嵌入向量进行对齐并拼接,组成新的基本块嵌入向量。
优选地,所述步骤6具体为:
使用负采样获得的三元组样本,通过嵌入网络模型后分别获得正样本、负样本和锚点的语义嵌入向量;
分别拼接对应基本块的字符串向量,获得具有语义和字符串的嵌入向量,其中锚点的嵌入比负样本的嵌入接近正样本的嵌入,通过下式表示采用基于余量的三元损失函数:
L=max{D(E
其中,E
优选地,所述步骤7具体为:
给出不同指令架构的两个二进制代码,通过反汇编获得各自的汇编代码,分别获得汇编代码基本块的语义嵌入向量,对嵌入向量计算欧氏距离判断两个不同指令架构的二进制代码是否相似。
本发明具有以下有益效果:
本发明同时结合了基本块的语义特征和字符串特征,使用预训练好的嵌入模型可以快速对不同指令架构的基本块进行比较。可以加快漏洞检测、版权纠纷等需要比较不同指令架构基本块的准确率和效率。
附图说明
图1为LLVM优化示意图;
图2为归一化操作示意图;
图3为基于语义的跨指令架构二进制代码相似性检测方法流程图。
具体实施方式
以下结合具体实施例,对本发明进行了详细说明。
具体实施例一:
根据图1-图3所示,本发明提供一种基于语义的跨指令架构二进制代码相似性检测方法,包括以下步骤:
一种基于语义的跨指令架构二进制代码相似性检测方法,包括以下步骤:
步骤1:构建不同指令架构的汇编语言数据集,提取具有相同语义的不同指令架构的汇编代码对;
所述步骤1具体为:
训练基本块嵌入具有相同语义的汇编代码基本块对,使用更改后的LLVM编译器将源代码编译成带有基本块边界标记的中间语言IR,经过优化器优化后再使用LLVM的不同后端生成不同指令架构的汇编语言,其中每个基本块拥有唯一标识符且边界已经被标记,通过正则过滤提取具有相同语义的不同指令架构的汇编代码对。
步骤2:对汇编代码基本块对进行归一化处理;
所述步骤2具体为:
对于寄存器,x86中的寄存器分为14类,其中包含指针寄存器、浮点数寄存器、四类通用寄存器、四类数据寄存器和四类地址寄存器,其中通用寄存器、数据寄存器和地址寄存器按照其存储的数据长度分为4种类型,分别是8位、16位、32位和64位;对于ARM中的寄存器被分为两类:通用寄存器和指针寄存器,对x86基本块的汇编代码进行归一化操作。
步骤3:进行汇编代码编码器的预训练,将汇编代码语义相似性任务转化为自然语言神经机器翻译任务;
所述步骤3具体为:
将汇编代码语义相似性任务转化为自然语言神经机器翻译任务,根据生成的具有相同语义的不同指令架构汇编代码对训练当前主流的神经机器翻译模型Transformer,模型产生的中间向量包含丰富的汇编代码语义信息;
将x86基本块和ARM基本块分别表示为S=(s
其中,
得到x86编码器,将x86汇编代码嵌入为一个含有语义特征的向量。
步骤4:进行负采样,使模型能够区分语义不同但嵌入向量相近的基本块;
所述步骤4具体为:
在预训练模型的基础上,通过测量两个x86基本块嵌入向量E
其中,d为嵌入维度,e
在训练嵌入网络时需要使用三元组,包括锚点、正样本、负样本,随机找到一个x86-ARM基本块对A,作为锚点和正样本,通过计算距离找到与基本块对A嵌入向量相近但语义不同的另一个x86-ARM基本块对B,当锚点为基本块对A的ARM基本块,则正样本为基本块对A的x86基本块,负样本为基本块对B的x86基本块;当锚点为基本块对A的x86基本块,则正样本为基本块对A的ARM基本块,负样本为基本块对B的ARM基本块。
步骤5:结合字符串语义的基本块嵌入,将字符串嵌入向量与嵌入网络获得的嵌入向量进行对齐并拼接,组成新的基本块嵌入向量;
所述步骤5具体为:
收集基本块中使用过的字符串,使用LSTM为每个字符串嵌入为一个向量,并使用Sum Pooling为每个基本块中的所有字符串向量计算出最终嵌入,将字符串嵌入向量与嵌入网络获得的嵌入向量进行对齐并拼接,组成新的基本块嵌入向量。
步骤6:嵌入网络的训练,输出x86和ARM的嵌入向量;
所述步骤6具体为:
使用负采样获得的三元组样本,通过嵌入网络模型后分别获得正样本、负样本和锚点的语义嵌入向量;
分别拼接对应基本块的字符串向量,获得具有语义和字符串的嵌入向量,其中锚点的嵌入比负样本的嵌入接近正样本的嵌入,通过下式表示采用基于余量的三元损失函数:
L=max{D(E
其中,E
步骤7:进行二进制代码相似性比较,判断两个不同指令架构的二进制代码是否相似。
所述步骤7具体为:
给出不同指令架构的两个二进制代码,通过反汇编获得各自的汇编代码,分别获得汇编代码基本块的语义嵌入向量,对嵌入向量计算欧氏距离判断两个不同指令架构的二进制代码是否相似。
具体实施例二:
本发明主要提出一种基本块嵌入模型,然后将跨指令架构的二进制代码通过反汇编得到对应架构的汇编代码基本块,使用提出的嵌入模型将基本块嵌入为向量,通过比较嵌入后向量的余弦相似度来确定不同指令架构二进制代码的相似性。
提出的基本块嵌入模型中,这两个嵌入模块可以用于任何其他架构上的基本块。这里指定x86和ARM只是为了便于描述。
步骤一:构建不同指令架构的汇编语言数据集。
训练基本块嵌入需要大量具有相同语义的汇编代码基本块对,为接下来训练基本块的语义嵌入做准备。这里认为同一源代码编译出来的汇编代码在语义上是等价的,因此使用更改后的LLVM编译器将源代码编译成带有基本块边界标记的中间语言IR,经过优化器优化后再使用LLVM的不同后端生成不同指令架构的汇编语言,其中每个基本块拥有唯一标识符且边界已经被标记,通过简单的正则过滤即可提取具有相同语义的不同指令架构的汇编代码对。
步骤二:对汇编代码基本块对进行归一化。
如果直接将原始汇编代码送入神经网络训练语义的话可能造成一些词汇不在词库(OOV)的问题。并且一些寄存器可以被同一类别的其他寄存器替换,而语义没有改变。因此,需要对汇编代码进行归一化。
汇编代码中的常量分为五类,即立即数、地址、变量名、函数名和基本块标签,分别使用‘IMM’,‘ADDRESS’,‘VAR’,‘FUNC’,‘BB’等字符进行代替。
对于寄存器来说,x86中的寄存器分为14类,其中包含指针寄存器、浮点数寄存器、四类通用寄存器、四类数据寄存器和四类地址寄存器。其中通用寄存器、数据寄存器和地址寄存器按照其存储的数据长度分为4种类型,分别是8位、16位、32位和64位。对于ARM中的寄存器被分为两类:通用寄存器和指针寄存器。
如图1所示,左为x86基本块的汇编代码,通过归一化操作后转变为右。
步骤三:汇编代码编码器的预训练。
将汇编代码语义相似性任务转化为自然语言神经机器翻译任务,使用步骤一、二生成的大量具有相同语义的不同指令架构汇编代码对训练当前主流的神经机器翻译模型Transformer,模型产生的中间向量包含丰富的汇编代码语义信息。将x86基本块和ARM基本块分别表示为S=(s
其中
步骤四:负采样。
加入负采样后的样本可以使模型能够区分语义不同但嵌入向量相近的基本块,提高模型的性能。在预训练模型的基础上,可以通过测量两个x86基本块嵌入向量E
其中
步骤五:结合字符串语义的基本块嵌入。
由于汇编代码中的变量中有一些表示字符串,且对于不同指令架构的基本块中字符串大多数情况下是相同的,这对于匹配两个基本块具有极大的促进作用。首先收集基本块中使用过的字符串,然后使用LSTM为每个字符串嵌入为一个向量,并使用Sum Pooling为每个基本块中的所有字符串向量计算出最终嵌入。最后将字符串嵌入向量与嵌入网络获得的嵌入向量进行对齐并拼接,组成新的基本块嵌入向量。
步骤六:嵌入网络的训练。
首先使用负采样获得的三元组样本,通过嵌入网络模型后分别获得正样本、负样本和锚点的语义嵌入向量。然后分别拼接对应基本块的字符串向量,获得具有语义和字符串的嵌入向量。其中锚点的嵌入应该比负样本的嵌入更接近正样本的嵌入。因此采用基于余量的三元损失函数如下所示:
L=max{D(E
其中E
步骤七:最终二进制代码相似性比较。
给出不同指令架构的两个二进制代码,通过反汇编获得各自的汇编代码。经过以上六个步骤获得的嵌入模型,就可以分别获得汇编代码基本块的语义嵌入向量,对嵌入向量计算欧氏距离即可判断两个不同指令架构的二进制代码是否相似。
以上所述仅是一种基于语义的跨指令架构二进制代码相似性检测方法的优选实施方式,一种基于语义的跨指令架构二进制代码相似性检测方法的保护范围并不仅局限于上述实施例,凡属于该思路下的技术方案均属于本发明的保护范围。应当指出,对于本领域的技术人员来说,在不脱离本发明原理前提下的若干改进和变化,这些改进和变化也应视为本发明的保护范围。
- 一种基于语义的跨指令架构二进制代码相似性检测方法
- 一种基于语义的跨指令架构二进制代码相似性检测方法