一种基于路径排序的好友推荐方法与系统
文献发布时间:2023-06-19 10:29:05
技术领域
本发明涉及推荐技术领域,尤其涉及一种基于路径排序的好友推荐方法与系统。
背景技术
在社交网络平台,好友推荐是一个常用功能,通常情况下好友推荐根据共同好友共同关注,用户标签(性别,年龄,地址,喜好)等进行推荐。
在现有的技术方案中,二度人脉好友推荐运用非常广泛,比如在一些主流的社交产品中就有可能认识的人这样的功能,一般来说可能认识的人是通过二度人脉搜索得到的,假如A和B是好友关系,B和C是好友关系,然而C和A不是好友关系,那么A和C是二度好友关系,他们可以通过B认识,B是中间人;或者是根据用户标签,把标签相近的用户推荐给对方。
上述两个现有的推荐算法无个性化,无法挖掘用户的潜在兴趣,也无法为新用户产生推荐。
发明内容
本发明针对上述的推荐具有局限性的技术问题,提出一种基于路径排序的好友推荐方法与系统。
第一方面,本申请实施例提供了一种基于路径排序的好友推荐方法,包括:
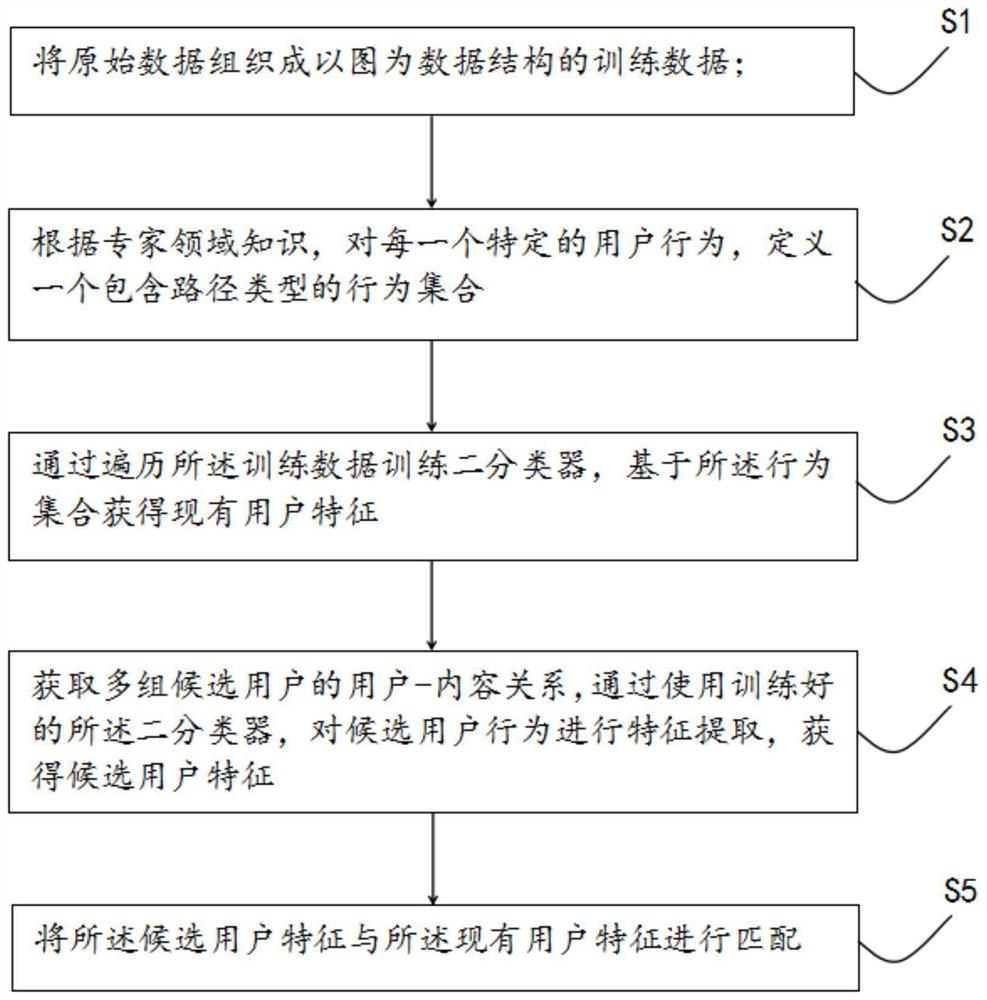
训练数据获得步骤:将原始数据组织成以图为数据结构的训练数据;
定义集合步骤:根据专家领域知识,对每一个特定的用户行为,定义一个包含路径类型的行为集合;
现有用户特征获得步骤:通过遍历所述训练数据训练二分类器,基于所述行为集合获得现有用户特征;
候选用户特征获得步骤:获取多组候选用户的用户-内容关系,通过使用训练好的所述二分类器,对候选用户行为进行特征提取,获得候选用户特征;
匹配步骤:将所述候选用户特征与所述现有用户特征进行匹配。
上述基于路径排序的好友推荐方法,其中,所述训练数据获得步骤包括:
采样步骤:对于已发生的用户行为,围绕用户-内容关系使用封闭世界假设对负样本进行采样,采样结果为所述训练数据中的样本。
上述基于路径排序的好友推荐方法,其中,所述现有用户特征获得步骤包括:
特征矩阵构建步骤:遍历所述训练数据中的每一条所述样本,以所述样本中的起始实体为起点,使用所述行为集合内的路径类型作为约束,对现有用户在一定时间段内的行为构建稀疏特征矩阵;
模型训练步骤:以所述稀疏特征矩阵为输入训练二分类器,将所述二分类器的全连接层作为行为特征;
聚类步骤:对于同一个用户的所述行为集合,对应获取与所述行为集合相同数量的所述行为特征,对所述行为特征进行聚类,获取聚类结果中最大的簇的均值为现有用户特征。
上述基于路径排序的好友推荐方法,其中,所述匹配步骤包括:
距离计算步骤:计算所述候选用户特征与所述现有用户特征的欧式距离或余弦距离;
上述基于路径排序的好友推荐方法,其中,所述候选用户特征与所述现有用户特征的欧式距离或余弦距离越小,候选用户与现有用户行为越接近。
第二方面,本申请实施例提供了一种基于路径排序的好友推荐系统,包括:
训练数据获得模块:将原始数据组织成以图为数据结构的训练数据;
定义集合模块:根据专家领域知识,对每一个特定的用户行为,定义一个包含路径类型的行为集合;
现有用户特征获得模块:通过遍历所述训练数据训练二分类器,基于所述行为集合获得现有用户特征;
候选用户特征获得模块:获取多组候选用户的用户-内容关系,通过使用训练好的所述二分类器,对候选用户行为进行特征提取,获得候选用户特征;
匹配模块:将所述候选用户特征与所述现有用户特征进行匹配。
上述基于路径排序的好友推荐系统,其中,所述训练数据获得模块包括:
采样单元:对于已发生的用户行为,围绕用户-内容关系使用封闭世界假设对负样本进行采样,采样结果为所述训练数据中的样本。
上述基于路径排序的好友推荐系统,其中,所述现有用户特征获得模块包括:
特征矩阵构建单元:遍历所述训练数据中的每一条所述样本,以所述样本中的起始实体为起点,使用所述行为集合内的路径类型作为约束,对现有用户在一定时间段内的行为构建稀疏特征矩阵;
模型训练单元:以所述稀疏特征矩阵为输入训练二分类器,将所述二分类器的全连接层作为行为特征;
聚类单元:对于同一个用户的所述行为集合,对应获取与所述行为集合相同数量的所述行为特征,对所述行为特征进行聚类,获取聚类结果中最大的簇的均值为现有用户特征。
上述基于路径排序的好友推荐系统,其中,所述匹配模块包括:
距离计算单元:计算所述候选用户特征与所述现有用户特征的欧式距离或余弦距离;
上述基于路径排序的好友推荐系统,其中,所述候选用户特征与所述现有用户特征的欧式距离或余弦距离越小,候选用户与现有用户行为越接近。
与现有技术相比,本发明的优点和积极效果在于:
本发明可以根据用户行为,比如阅读,播放,观看,点赞,关注,收藏,购买等行为推荐兴趣相近的好友,可以挖掘用户的潜在兴趣,并可以为新用户产生推荐。
附图说明
图1为本发明提供的一种基于路径排序的好友推荐方法的步骤示意图;
图2为本发明提供的基于图1中步骤S3的流程图;
图3为本发明提供的一种基于路径排序的好友推荐系统的框架图。
其中,附图标记为:
11、训练数据获得模块;111、采样单元;12、定义集合模块;13现有用户特征获得模块;131、特征矩阵构建单元;132、模型训练单元;133、聚类单元;14、候选用户特征获得模块;15匹配模块;151、距离计算单元。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行描述和说明。应当理解,此处所描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。基于本申请提供的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。
显而易见地,下面描述中的附图仅仅是本申请的一些示例或实施例,对于本领域的普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图将本申请应用于其他类似情景。此外,还可以理解的是,虽然这种开发过程中所作出的努力可能是复杂并且冗长的,然而对于与本申请公开的内容相关的本领域的普通技术人员而言,在本申请揭露的技术内容的基础上进行的一些设计,制造或者生产等变更只是常规的技术手段,不应当理解为本申请公开的内容不充分。
在本申请中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本申请的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域普通技术人员显式地和隐式地理解的是,本申请所描述的实施例在不冲突的情况下,可以与其它实施例相结合。
除非另作定义,本申请所涉及的技术术语或者科学术语应当为本申请所属技术领域内具有一般技能的人士所理解的通常意义。本申请所涉及的“一”、“一个”、“一种”、“该”等类似词语并不表示数量限制,可表示单数或复数。本申请所涉及的术语“包括”、“包含”、“具有”以及它们任何变形,意图在于覆盖不排他的包含;例如包含了一系列步骤或模块(单元)的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可以还包括没有列出的步骤或单元,或可以还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。本申请所涉及的“连接”、“相连”、“耦接”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电气的连接,不管是直接的还是间接的。本申请所涉及的“多个”是指两个或两个以上。“和/或”描述关联对象的关联关系,表示可以存在三种关系,例如,“A和/或B”可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。本申请所涉及的术语“第一”、“第二”、“第三”等仅仅是区别类似的对象,不代表针对对象的特定排序。
下面结合附图所示的各实施方式对本发明进行详细说明,但应当说明的是,这些实施方式并非对本发明的限制,本领域普通技术人员根据这些实施方式所作的功能、方法、或者结构上的等效变换或替代,均属于本发明的保护范围之内。
在详细阐述本发明各个实施例之前,对本发明的核心发明思想予以概述,并通过下述若干实施例予以详细阐述。
本发明提出一种基于路径排序的好友推荐方法,通过将用户的行为特征作为输入训练分类器,得到现有用户特征,利用训练好的分类器提取候选用户特征,并与现有用户特征进行匹配,得到用户行为的接近程度,以此为参考进行用户推荐。
知识图谱:知识图谱(Knowledge Graph)又称为科学知识图谱,在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。知识图谱主要目标是用来描述真实世界中存在的各种实体和概念,以及他们之间的强关系,我们用关系去描述两个实体之间的关联,例如姚明和火箭队之间的关系,他们的属性,我们就用“属性--值对“来刻画它的内在特性,比如说人物,他有年龄、身高、体重属性。
网络连接性(Connectvity):网络连接性是指网络中实体的联系的紧密程度,网络中实体间联系的路径数越多,则网络连接性越强。
实体:实体是知识库所表示成的图中的一个节点,表示成物理世界中的物体或者概念。例如“北京”就可以表示图中的一个实体。
实体类型(entity type):为实体存储了相关信息的人员、组织、对象类型或概念。描述正在被掌控的信息的类型。比如北京上海是地点类型。
关系:关系是知识库所表示成的图中的一条边,连接两个实体,用于表示两个实体的联系,具有方向。例如“北京”位于“上海”北方,其中“北京”与“上海”均为实体,位于北方就是“北京”与“上海”的关系。
关系类型(relation type):实体与实体,实体与属性的类型,如果关系有方向就是有向,没有关系就是无向。
关系推理:知识图谱上已经有了非常多的实体对和关系,但是由于数据的更新迭代以及不完整性,注定了这个知识图谱的不完整,同样,他里面也隐藏着我们难以轻易发现的信息。这时就需要关系推理来帮助我们发现这些隐藏的信息。
下面是一个关系推理的例子:我们没有证据直接指明梅琳达·盖茨和西雅图的关系。然而,我们可以通过观察到知识图谱中包含这样的一条路径“梅琳达·盖茨-配偶-比尔·盖茨-主席-微软-总部在-西雅图”,推测出梅林达可能居住在西雅图。
封闭世界假设:封闭世界假定是当前不是已知的事物都为假的假定。在这里指如果一组由start node与end node组成的pair在特征计算阶段发现不在正样本集合中,则视其为负样本。
路径类型(path types):路径类型指的是一个由一组描述了关系类型的标签而组成的序列。
实施例一:
参照图1所示,图1为本发明提供的一种基于路径排序的好友推荐方法的步骤示意图。如图1所示,本实施例揭示了一种基于路径排序的好友推荐方法(以下简称“方法”)的具体实施方式。
具体而言,本实施例所揭示的方法主要包括以下步骤:
步骤S1:将原始数据组织成以图为数据结构的训练数据。
具体而言,对于已发生的用户行为,围绕用户-内容这一重要类型的关系使用封闭世界假设采样负样本,其中内容包括但不限于文章、视频、音乐、商品等。
然后,执行步骤S2:根据专家领域知识,对每一个特定的用户行为,包括但不限于点赞、收藏、关注等,定义一个包含路径类型的行为集合,例如:(用户1,行为1,行为2,行为3,内容1)。包含在这一集合中的路径类型,可以更加有效地进行推荐。
参照图2,执行步骤S3:通过遍历所述训练数据训练二分类器,基于所述行为集合获得现有用户特征。
其中,步骤S3具体包括以下内容:
步骤S31:遍历所述训练数据中的每一条所述样本,以所述样本中的起始实体(用户)为起点,使用所述行为集合内的路径类型作为约束,对现有用户在一定时间段内的行为构建稀疏特征矩阵;
步骤S32:以所述稀疏特征矩阵为输入训练二分类器,用于用户-行为-内容类型关系,将所述二分类器的全连接层作为行为特征;
步骤S33:对于同一个用户的所述行为集合,对应获取与所述行为集合相同数量的所述行为特征,对所述行为特征进行聚类,获取聚类结果中最大的簇的均值为现有用户特征。
具体而言,经过遍历,对于同一个用户的n个行为集合,会得到n个特征向量,对n个特征向量进行聚类,找到最大的簇的均值用来表示当前用户特征,其中所用的聚类方法包括但不限于kmeans。
执行步骤S4:获取多组候选用户的用户-内容关系,通过使用训练好的所述二分类器,对候选用户行为进行特征提取,获得候选用户特征。
具体而言,对于一个新的用户,使用上述相同方式,获取多组候选用户-内容关系及其特征向量。使用已训练好的分类器,对候选用户行为进行特征提取。
最后执行步骤S5:将所述候选用户特征与所述现有用户特征进行匹配。
具体而言,计算所述候选用户特征与所述现有用户特征的欧式距离或余弦距离,所述候选用户特征与所述现有用户特征的欧式距离或余弦距离越小,候选用户与现有用户行为越接近,兴趣爱好越相似;反之距离越大,兴趣爱好差异越大,将兴趣爱好相似的用户进行推荐。
以下,具体说明本方法的应用流程如下:
1、定义10种路径类型,每种特征类型即为一维特征。每种路径类型及其描述如下:
路径类型指的是一个由一组描述了关系类型的标签而组成的序列。每种关系类型的起始实体类型如下表:
2、遍历训练样本的中每一个样本,以起始实体为起点,进行随机游走,从而得到每个样本的特征选择结果。例如:(样本1:Path type1:内容1)、(样本2:Path type2:内容2)、(样本3:Path type3:内容3)、(样本4:Path type4:内容1)、(样本5:Path type5:内容5)。
3、以用户作为start node起始实体,随机采样计算每一个维度的特征值(仅计算每个样本特征选择后的特征维度)。训练前需要对权重进行初始化,如下表。以用户1一段时间内的行为为例,假设用户1在该时间内有如下行为(Path type1-内容1:观看-内容1),(Path type3-内容2:阅读→点赞-内容2),可以得到该用户的输入为[1,0,0,1,0,0,0,0,0,0,0…]。
4、使用上述方法计算全部用户固定时间段内特征,作为模型的输入,经过训练数据训练分类器,即可更新当前的模型参数。
5、取全连接层的数据作为该段时间内用户特征。每个用户不同时间段的行为都会得到一个特征向量,对每一个用户单独聚类,找到最大的簇,计算该簇内向量均值,作为该用户特征。
6、最后,对于一个新的用户,使用已训练好的分类器,对用户行为进行特征提取。
7、根据步骤6得到到用户特征向量,与现有用户特征进行匹配(计算向量的欧式距离或者余弦距离,距离越小,用户行为越接近)。
实施例二:
结合实施例一所揭示的一种基于路径排序的好友推荐方法,本实施例揭示了一种基于路径排序的好友推荐系统(以下简称“系统”)的具体实施示例。
参照图3所示,所述系统包括:
训练数据获得模块11:将原始数据组织成以图为数据结构的训练数据;
定义集合模块12:根据专家领域知识,对每一个特定的用户行为,定义一个包含路径类型的行为集合;
现有用户特征获得模块13:通过遍历所述训练数据训练二分类器,基于所述行为集合获得现有用户特征;
候选用户特征获得模块14:获取多组候选用户的用户-内容关系,通过使用训练好的所述二分类器,对候选用户行为进行特征提取,获得候选用户特征;
匹配模块15:将所述候选用户特征与所述现有用户特征进行匹配。
其中,所述训练数据获得模块11包括:
采样单元111:对于已发生的用户行为,围绕用户-内容关系使用封闭世界假设对负样本进行采样,采样结果为所述训练数据中的样本。
其中,所述现有用户特征获得模块13包括:
特征矩阵构建单元131:遍历所述训练数据中的每一条所述样本,以所述样本中的起始实体为起点,使用所述行为集合内的路径类型作为约束,对现有用户在一定时间段内的行为构建稀疏特征矩阵;
模型训练单元132:以所述稀疏特征矩阵为输入训练二分类器,将所述二分类器的全连接层作为行为特征;
聚类单元133:对于同一个用户的所述行为集合,对应获取与所述行为集合相同数量的所述行为特征,对所述行为特征进行聚类,获取聚类结果中最大的簇的均值为现有用户特征。
其中,所述匹配模块15包括:
距离计算单元151:计算所述候选用户特征与所述现有用户特征的欧式距离或余弦距离;通过距离计算单元151计算的所述候选用户特征与所述现有用户特征的欧式距离或余弦距离越小,候选用户与现有用户行为越接近。
本实施例所揭示的一种基于路径排序的好友推荐系统与实施例一所揭示的一种基于路径排序的好友推荐方法中其余相同部分的技术方案,请参实施例一所述,在此不再赘述。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
综上所述,基于本发明的有益效果在于,可以根据用户行为,比如阅读,播放,观看,点赞,关注,收藏,购买等行为推荐兴趣相近的好友,可以挖掘用户的潜在兴趣,并可以为新用户产生推荐。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 一种基于路径排序的好友推荐方法与系统
- 一种基于链路预测的在线社交网络好友推荐方法与系统