化学品雌激素受体激活活性的预测模型及筛查方法
文献发布时间:2023-06-19 10:32:14
技术领域
本发明涉及化学品环境健康风险评价技术领域,更具体地涉及一种化学品雌激素受体激活活性的预测模型及筛查方法。
背景技术
随着工业的发展,人类更多地暴露于环境化学品,其中环境内分泌干扰物通过干扰人体激素正常功能,引起人体可逆或者不可逆的生物效应,而受到了政府和研究者的极大关注。早在1999年,美国环保署(Environmental Protection Agency,EPA)就实施了内分泌干扰物筛选计划。我国国家自然科学基金委员会于2000年也以“环境类激素影响人类健康的机理”为重点项目进行招标,开始了我国在环境类激素方面的大规模研究。而环境雌激素干扰物作为其中重要一类,通过干扰人体内源性雌激素正常功能,可能导致生殖功能障碍、出生缺陷、生长发育异常和生殖系统肿瘤等生理效应,也是当今化学品管理中环境健康风险评价的重要部分。截止2017年,在欧洲化学品登记、评估、授权及限制法规(Regulationof Registration,Evaluation,Authorization,and Restriction of Chemicals)下进行预注册的化学品数量已达145,297种。对于潜在的内分泌干扰物进行筛选和测试,美国EPA环境内分泌干扰物筛选和测试顾问委员会推荐了由20余种离体与活体测试方法联合组成的多终点方法体系,但是如此实验方法耗费的实验资源和时间巨大。面对如此庞大数量的化学品,应用此方法一一筛查显然不切实际。因此,迫切需要计算方法对化学品潜在雌激素干扰效应进行快速筛查评价。
定量活性构效关系(Quantitative Structure Activity Relationships,QSAR)根据已知化学结构性质即分子描述符和生理活性间的定性/定量变化关系,建立基于分子描述符的定性/定量活性预测模型。这一方法的使用大大提高了化学品筛查的效率,成为化学品评价的重要工具之一。传统QSAR预测模型需预先计算和设定一定数量的分子描述符。分子描述符种类繁多,包括分子构成、分析指纹、拓扑指数和三维结构特征等千种描述符。然而受模型方法本身所限,大量与所研究性质无关的描述符的输入会导致模型稳健性较差,并且增加计算复杂性。从统计学角度,分子描述符往往需要进行预先筛选,剔除冗余、相关性高和代表性低的描述符信息。此外,分子描述符的计算亦需要具备一定经验和化学基础,先验知识的判断也一定程度限制了QSAR预测模型的应用和预测性能。随着深度学习(Deep Learning)浪潮的再一次兴起,深度神经网络(Deep Neural Network,DNN)模型在众多领域取得了优异的成果,尤其是在计算机视觉和自然语言处理方面的成功让我们看到将其用于化学品分子识别以至分子性质预测的潜力。深度神经网络模型有着不同于传统机器学习算法的更灵活的结构,使得其可以接受更加丰富多样的输入信息,而不再局限于人为定义的描述符特征,不仅减小了模型使用时前期数据准备的要求,也大幅度提升了模型预测效果。卷积神经网络(Convolutional Neural Networks,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。由于其稀疏连接和权值共享的特点,使其可以提取输入信息的局部特征,并减少了待学习的模型参数从而提高模型的学习效率。而目前CNN在环境雌激素活性评价领域尚未应用。
综上所述,基于传统机器学习算法建立的定量构效关系数学预测模型虽然大大提高了化学品评价和性质快速筛查的进程,但由于可用描述符的限制,使其在较为复杂的体系中难以实现足够的预测效果;且描述符的计算和收集需要一定的时间、计算资源以及一定的学科基础,也一定程度限制了预测模型的应用。因此需要一种可以接受更加丰富输入信息的端到端模型,实现化学结构到性质的直接映射,减小模型使用中前期数据准备的要求,提高模型的预测效果和筛查能力。
发明内容
有鉴于此,本发明的主要目的在于提供一种化学品雌激素受体激活活性的预测模型及筛查方法,以期至少部分地解决上述技术问题中的至少之一。
为了实现上述目的,作为本发明的一个方面,提供了一种化学品雌激素受体激活活性预测模型的建立方法,包括:
S1获取已知雌激素受体激活活性的化学品数据,其中,所述化学品数据包括化学品的SMILES编码;
S2将SMILES编码转换得到M×N的数字矩阵;
S3将获得的已知化学品的数字矩阵数据分为训练集和验证集,构建以SMILES数字矩阵为输入的卷积神经网络模型;
S4使用训练集训练卷积神经网络模型,使用验证集确定卷积神经网络模型的最优超参数,得到最优卷积神经网络模型。
作为本发明的另一个方面,还提供了一种化学品雌激素受体激活活性的预测模型,采用如上所述的建立方法获得。
作为本发明的又一个方面,还提供了一种化学品雌激素受体激活活性的筛查方法,采用如上所述的预测模型,包括:
将待评价化学品的SMILES编码,转换成大小为M×N的数字矩阵后输入所述的预测模型中,得到雌激素受体激活活性预测值;
若预测值大于或等于预设阈值则认为化学品具有雌激素受体激活活性,若预测值小于预设阈值则认为化学品不具有雌激素受体激活活性。
基于上述技术方案可知,本发明的化学品雌激素受体激活活性的预测模型及筛查方法,具有如下有益效果:
(1)不同于传统机器学习算法建立的数学预测模型,本发明所采用的卷积神经网络模型无需人为定义的可量化的结构参数作为分子描述符,节省了分子描述符计算和描述符挑选的时间和计算资源,且应用时对计算化学基础的要求更低;
(2)本发明所采用的卷积神经网络模型,相比于使用固定长度的分子指纹和传统机器学习预测模型有着更优异的预测性能;
(3)本发明建立了一个端到端的化学品雌激素受体激活活性预测模型,直接建立化学结构与雌激素激活活性之间的映射,可以实现从化学品活性向化学结构的反推,寻找雌激素激活活性的化学结构特征,有助于特定活性化学品的设计发现;
(4)本发明适用于大规模化学品雌激素激活活性的筛查;方法简单快速,效率高,该方法在化学品风险评价、环境安全性评估等领域具有广阔的应用前景。
附图说明
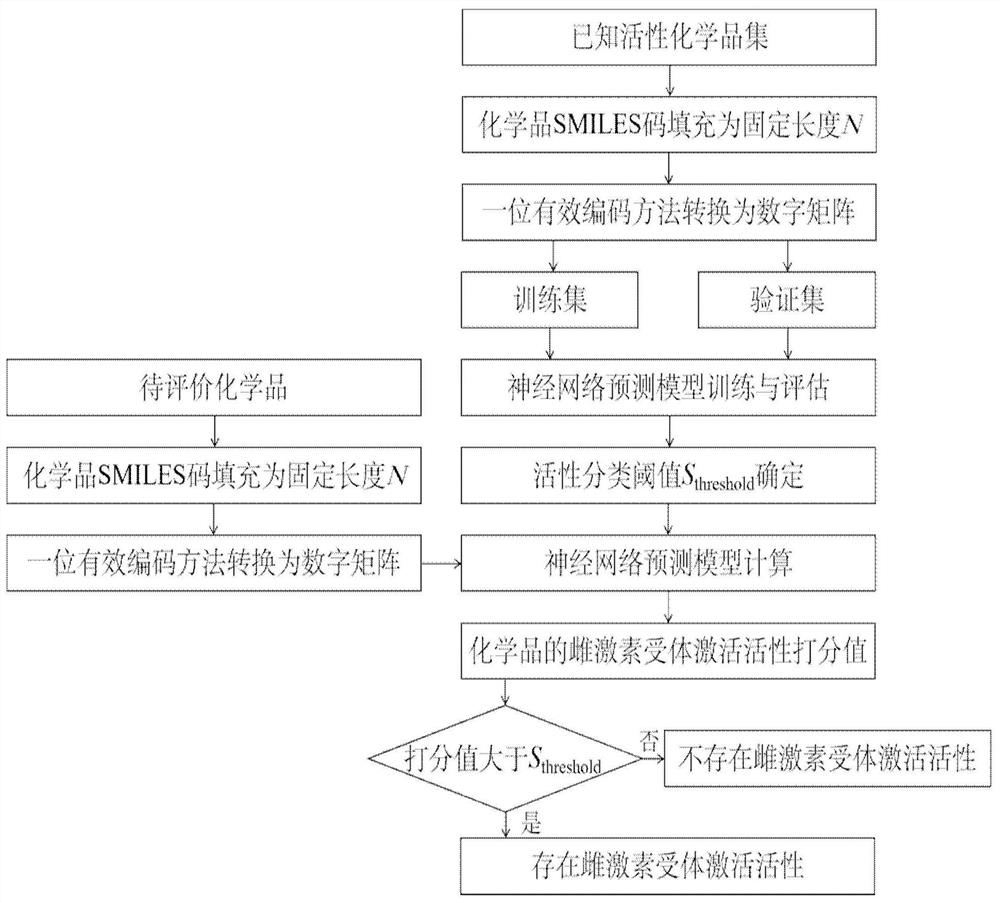
图1为本发明实施例1采用基于化学品SMILES编码的端到端雌激素受体激活活性快速筛查方法进行化学品评价示意图;
图2为本发明实施例1中深度神经网络结构示意图;
图3为本发明实施例1中炔雌醇SMILES经一位有效编码法转换后的数字矩阵的图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。
根据对现有化学品雌激素受体激活活性预测模型的文献调研,可见所涉及的方法或技术存在缺点。使用传统机器学习方法建立的数学模型,需要以人为定义的量化分子结构参数作为分子描述符,不仅可能造成分子结构信息确实,分子数据的前期准备也会消耗较多时间和计算资源。本发明的目的是要提供一种基于分子结构SMILES编码的深度神经网络模型,建立分子结构到性质的端到端预测模型,节省了模型训练和应用时分子描述符收集计算所需的时间和计算资源,且减小应用时对计算化学基础的要求。
本发明基本原理是,对于字符串形式的分子结构SMILES编码转化为数字矩阵;卷积网络中的卷积操作可以提取SMILES编码中内含的大量分子结构信息;已有研究表明深层神经网络可以拟合任意数学函数,所以模型中的全连接层可以在卷积操作提取的分子结构信息和分子特定性质间建立数学函数关系,以实现特定分子性质的预测。本发明利用卷积神经网络灵活结构,无需化学品的可量化的结构参数作为描述符即可预测化学品生理活性,节约了化学品描述符收集计算的成本,提高了化学品快速筛查的速度;此外该模型直接在化学结构和性质之间建立联系,有利于指导特定性质化学品的合成设计,在化学品的快速筛查和设计等领域具有广阔的应用前景。
本发明公开了一种化学品雌激素受体激活活性预测模型的建立方法,包括:
S1获取已知雌激素受体激活活性的化学品数据,其中,所述化学品数据包括化学品的SMILES编码;
S2将SMILES编码转换得到M×N的数字矩阵;
S3将获得的已知化学品的数字矩阵数据分为训练集和验证集,构建以SMILES数字矩阵为输入的卷积神经网络模型;
S4使用训练集训练卷积神经网络模型,使用验证集确定卷积神经网络模型的最优超参数,得到最优卷积神经网络模型。
在本发明的一些实施例中,步骤S1中所述化学品数据还包括化学品雌激素受体激活活性二元类别。
在本发明的一些实施例中,步骤S2中将所述SMILES编码转换得到M×N的数字矩阵的方法具体包括:
S2.1将化学品的SMILES编码的字符串拆分为单个字符组成的字符向量;
S2.2设定字符向量为固定长度N,若字符向量长度小于N,则在字符向量后填充字符“0”,使字符向量长度为N;若字符向量长度大于N,则取前N个字符。其中,N的取值可以根据需要设定,例如可以设定为50-150;
S2.3化学品数据中的化学物共涵盖M种字符,将该M个字符按照一定顺序排列为字符列表;对于每个化学品,遍历其长度为N的SMILES字符向量,根据字符在字符列表中对应的位置i,将该字符转换为位置i处为1,其余均为0的长度为M的数字向量;对于字符向量后填充的字符“0”,则转换为长度为M的均为0的数字向量,得到M×N的数字矩阵。其中,M的取值可以根据需要设定,例如可以设定为36-45;
在本发明的一些实施例中,步骤S3中所述卷积神经网络模型包括n
在本发明的一些实施例中,第i层卷积层包含channel
在本发明的一些实施例中,将最后一层卷积的输出大小为
在本发明的一些实施例中,全连接层中当前层的每一个结点都与上一层的所有结点相连,每层的节点数分别为
在本发明的一些实施例中,全连接层的最后一层即输出层,输出化学品雌激素受体激活活性的预测值s。
在本发明的一些实施例中,步骤S4中所述确定卷积神经网络模型的最优超参数的方法包括:
S4.1预设置一组模型超参数为{α,λ,P
S4.2基于预设置合适的超参数和训练集数据迭代训练卷积神经网络模型;
S4.3使用验证集的化合物对超参数{α,λ,P
在本发明的一些实施例中,步骤S4.3中所述最优超参数为统计参数最优时的超参数;
在本发明的一些实施例中,所述统计参数包括真阳性、真阴性、假阳性、假阴性、敏感性、特异性、准确率、平衡准确性中的至少一种。
本发明还公开了一种化学品雌激素受体激活活性的预测模型,采用如上所述的建立方法获得。
本发明还公开了一种化学品雌激素受体激活活性的筛查方法,采用如上所述的预测模型,包括:
将待评价化学品的SMILES编码,转换成大小为M×N的数字矩阵后输入所述的预测模型中,得到雌激素受体激活活性预测值;
若预测值大于或等于预设阈值则认为化学品具有雌激素受体激活活性,若预测值小于预设阈值则认为化学品不具有雌激素受体激活活性。
在本发明的一些实施例中,所述预设阈值的确定方法包括:
将若干已知化学品的SMILES编码,转换成大小为M×N的数字矩阵后输入所述的预测模型中,得到雌激素受体激活活性预测值集合S;
将S由大到小排序,根据每个已知化学品的预测值和对应的活性标签,计算真阳性率和假阳性率;以假阳性率为x轴,真阳性率为y轴,得到受试者操作特性曲线;
受试者操作特性曲线中计算真阳性率相对于假阳性率变化率最大点t所对应的预测值s
在一个示例性实施例中,一种化学品雌激素受体激活活性快速筛查的新方法,包括以下步骤:从公开数据库或文献中获取雌激素受体激活活性的化学品结构和活性数据,将化学品的结构编码,转换为可以处理的数字矩阵形式;建立基于SMILES数字矩阵的雌激素受体激活活性卷积神经网络预测模型;根据预测模型输出预测活性值和预测性能确定雌激素受体激活活性的判定阈值;将待测化学品SMILES码编码后输入模型得到预测结果。
具体地,本发明的一种化学品雌激素受体激活活性快速筛查方法,包括以下步骤:
该方法使用的化学品SMILES编码为规范化的Canonical SMILES,其包括以下步骤:
步骤1:从公开数据库或文献中获取已知雌激素受体激活活性的化学品数据,包括化学品雌激素受体激活活性二元类别和化学品的简化分子线性输入规范(SimplifiedMolecular Input Line Entry Specification,SMILES),即SMILES编码,并将SMILES编码转换为M×N的数字矩阵。
具体地,本步骤包括以下子步骤:
子步骤11,从公开数据库或文献中获取已知雌激素受体激活活性的化学品数据,包括其化学结构的SMILES编码和化学品二元活性类别(数字“1”代表有活性,数字“0”代表无活性)。
子步骤12,将化学品的SMILES编码的字符串拆分为单个字符组成的字符向量。设定字符向量为固定长度N。若字符向量长度小于N,则在字符向量后填充字符“0”,使字符向量长度为N;若字符向量长度大于N,则取前N个字符。其中,N的取值可以根据需要设定,例如可以设定为50-150;
子步骤13,将字符向量通过一位有效编码方法转换为易于处理的数字矩阵。化学品数据集中所包含的化学物共涵盖M种字符,将该M个字符按照一定顺序排列为字符列表。对于每个化学品,遍历其长度为N的SMILES字符向量,根据字符在字符列表中对应的位置i,将该字符转换为位置i处为1,其余均为0的长度为M的数字向量。对于字符向量后填充的字符“0”,则转换为长度为M的均为0的数字向量。SMILES编码转换后得到M×N的数字矩阵。其中,M的取值可以根据需要设定,例如可以设定为36-45;
步骤2:将已有化学品数据随机分为训练集和验证集,并构建以SMILES数字矩阵为输入的卷积神经网络模型。
具体地,本步骤包括以下子步骤:
子步骤21,将已有化学品数据按照t∶v比例随机分为训练集和验证集,其中t%的数据作为训练集,用于训练卷积神经网络模型;v%的数据作为验证集,用于模型超参数搜索和预测能力评估。其中,t∶v的取值可以根据需要设定,例如可以为4∶1或7∶3;
子步骤22,本发明所构建的卷积神经网络模型包括n
训练集中化合物的数字矩阵[M,N]作为模型输入。
卷积层的第一层为一维卷积层,包含channel
卷积层第二层为一维卷积层,包含channel
卷积层的第三层至最后一卷积层n
全连接层中当前层的每一个结点都与上一层的所有结点相连,每层的节点数分别为
全连接层的最后一层即输出层,节点数为1。使用sigmoid激活函数变换使输出值在0~1范围内,即为化学品雌激素受体激活活性的预测值s;
步骤3:使用训练集中的化学品数据训练模型,验证集的化学品数据进行预测验证,搜索并确定卷积神经网络模型的最优超参数;
具体地,本步骤包括以下子步骤:
子步骤31,设定合适的批处理数据量batchsize和学习率α,此外为了提高模型的泛化能力,以防止模型过度拟合还在模型中加入权重衰减(L2)正则化项和全连接层中加入随机失活,参数设定为L2正则化项参数λ和随机失活操作的比率P
子步骤32,基于预设置合适的超参数和训练集数据训练模型,进行E代(epoch)训练,并保存每一代的模型参数。每次迭代的模型用于验证集的预测,计算真阳性(TruePositive,TP)、真阴性(True Negative,TN)、假阳性(False Positive,FP)、假阴性(FalseNegative,FN)、敏感性(Sensitivity,Se)、特异性(Specificity,Sp)、准确率(Accuracy,Acc)、平衡准确性(Balanced Accuracy,BA)统计参数,对模型进行评价。
TP:表示验证集中预测为正,实际也为正的样本个数;
FP:表示验证集中预测为正,实际为负的样本个数;
FN:表示验证集中预测与负,实际为正的样本个数;
TN:表示验证集中预测为负,实际也为负的样本个数;
为了避免过拟合提高模型的泛化能力,选择E代(epoch)迭代中对验证集预测结果平衡准确性BA最优时对应的模型。
子步骤33,为了进一步提高模型效果,对所用参数进行搜索优化,在一定范围内,一定步长下:
选定一组学习率参数α,得到不同学习率对应的平衡准确性BA,选定BA最优时的α;
选定一组L2正则化项参数λ,得到不同L2正则化项参数对应的平衡准确性BA,选定BA最优时的λ;
选定一组随机失活操作的比率P
使用训练集中的化学品训练模型,使用验证集中的化学品选择最优超参数,具体包括以下子步骤:
在本发明的一些实施例中,子步骤33,具体可以为:
使用训练集的化合物构建模型,进行E代(epoch)训练,每代训练所选取的样本数量为BS。使用验证集的化合物对超参数{α,λ,P
选定在一定范围内,一定步长下的一组α,计算不同α对应的平衡准确性BA,选取BA最大时所对应的α
选定在一定范围内,一定步长下的一组λ,计算不同λ对应的平衡准确性BA,选取BA最大时所对应的λ
选定在一定范围内,一定步长下的一组P
最终获得模型的一组超参数{α
步骤4:根据模型输出预测值和验证集中化学品已知活性类别确定雌激素受体激活活性判定阈值(即预设阈值)。
具体地,本步骤包括以下子步骤:
子步骤41,用此前训练得到的最优预测模型对验证集进行预测,得到验证集中化学品的雌激素激活活性预测值和其对应的活性类别标签,并使用此数据画出受试者操作特性曲线(ROC曲线);
具体地,使用子步骤33所获得的最优超参数{α
s
子步骤42,ROC曲线中TPR相对于FPR变化率最大点t所对应的预测值s
步骤5:将待评价化学品的SMILES编码,转换成大小为M×N的数字矩阵后输入所获得的卷积神经网络模型,得到雌激素受体激活活性预测值,若得分高于判定阈值则认为化学品具有雌激素受体激活活性,反之亦然。
具体地,本步骤包括以下子步骤:
子步骤51,待评价化学品按照子步骤12~子步骤13所述方法编码SMILES码,得到M×N的SMILES码数字矩阵。将此数字矩阵作为所得卷积神经网络模型的输入,计算得到化学品雌激素受体激活活性的预测值s
子步骤52,如果预测活性值s
以下通过具体实施例结合附图对本发明的技术方案做进一步阐述说明。需要注意的是,下述的具体实施例仅是作为举例说明,本发明的保护范围并不限于此。
实施例1
请参阅图1,本实例基于卷积神经网络的化学品雌激素受体激活活性快速筛查方法包括以下步骤:
(1)化学品数据的获得和预处理:
下载美国环保署(EPA)毒理学预测研究项目ToxCast中雌激素受体活性相关的18个高通量测试数据(https://www3.epa.gov/research/COMPTOX/CERAPP_files.html,TrainingSet.zip)和化学品的SMILES结构。根据体外高通量测试数据处理方法,将化学品的数值型雌激素受体激活活性转化为二元活性类别。为了提高数据的可靠性,保留两种来源雌激素激活活性一致的数据。最终数据集包括1317个化学品,其中具有雌激素激活活性的化学品144个,不具有雌激素激活活性的化学品1173个。
(2)化学结构转换为数字矩阵
将化学品的SMILES码字符串拆分为单个字符组成的字符向量,再将字符向量填充为固定长度120的向量。若字符数少于120,则字符向量在后部填充字符“0”,使字符向量长度为120,若字符数大于120的字符向量则只取前120个字符进行后续计算。
数据集分子空间内共涵盖38个SMILES字符,将其按照以下顺序组成字符列表:
[″,′#′,′(′,′)′,′+′,′-,′/′,′:′,′1′,′2′,′3′,′4′,′5′,′6′,′7′,′8′,′=,′@′,′A′,
′B′,′C′,′F′,′H′,′I′,′N′,′O′,′P′,′S′,′[′,′\\′,′]′,′c′,′l′,′n′,′o′,′r′,′s′,′i′]
根据字符在字符列表中对应的位置i,一位有效数字编码将该字符转换为位置i处为1,其余均为0的长度为38的数字向量。对于填充的字符“0”,则转换为长度为38的均为0的数字向量。SMILES码字符串转换后得到38×120的数值矩阵。
(3)深度神经网络模型的训练和超参数搜索
将已有化学品数据按照4∶1比例随机分为训练集和验证集,验证集用于模型超参数搜索和预测能力评估(数字“1”代表有活性,数字“0”代表无活性)。
如图2所示,所构建的深度神经网络模型可分为7层,包含卷积层和全连接层两种结构,其中前3层为卷积层,后接4层全连接层:
训练集中化合物的数字矩阵[38,120]作为模型输入。
卷积层的第一层为一维卷积层,包含9个卷积核,卷积核的尺寸为38×9,卷积步长为1;随后进行批标准化(Batch normalization)使得训练过程中每一层神经网络的输入保持相同分布的;再使用线性整流函数(Rectified Linear Unit,ReLU)作为激活函数将神经网络中的线性特征转换为非线性特征。输出为大小为9×112的数据。
卷积层第二层为一维卷积层,包含9个卷积核,卷积核的尺寸9×9,卷积步长为1,随后进行批标准化使得训练过程中每一层神经网络的输入保持相同分布的;再使用ReLU函数作为激活函数将神经网络中的线性特征转换为非线性特征。输出为大小为9×104的数据。
卷积层第三层仍为一维卷积层,包含11个卷积核,卷积核尺寸为9×10,卷积步长为1,输出为大小为11×95的数据。将最后一层卷积的输出大小为11×95的矩阵转换为长度为1045的向量作为全连接层的输入。
全连接层即当前层的每一个结点都与上一层的所有结点相连,每层的节点数分别为150,50,20,1。除最后一层外每一层输出使用ReLU激活函数将神经网络中的线性特征转换为非线性特征;
全连接层的最后一层即输出层,节点数为1,使用sigmoid激活函数变换使结果在0~1范围内,即为化学品雌激素受体激活活性的预测值S;
训练时应用自适应矩估计优化器(Adam)方法基于梯度更新神经网络参数,学习率α为0.001,此外为了提高模型的泛化能力,以防止模型过度拟合还在模型中加入L2正则化项和全连接层中加入随机失活,参数设定为L2正则化项参数0.1和随机失活操作的比率0.2。为了缓解数据不均衡带来的问题,训练时人为提高有活性化学品的抽样权重至6倍,设置批处理数据量为150。每次训练进行150次迭代,并保存每一次迭代的模型参数。每次迭代的模型用于验证集的预测,计算真阳性(True Positive,TP)、真阴性(True Negative,TN)、假阳性(False Positive,FP)、假阴性(False Negative,FN)、敏感性(Sensitivity,Se)、特异性(Specificity,Sp)、准确率(Accuracy,Acc)、平衡准确性(Balanced Accuracy,BA)统计参数,为了避免过拟合提高模型的泛化能力,选择E代迭代中对验证集预测结果平衡准确性BA最优时对应的模型。
为了进一步避免模型的过拟合,提高模型的泛化能力,对所用超参数进行搜索优化,在一定范围内,一定步长下:
选定学习率参数α,得到不同学习率对应的平衡准确性BA,选定α为0.001;
选定L2正则化项参数λ,得到不同正则化项参数对应的平衡准确性BA,选定λ为0.05;
选定随机失活操作的比率P
(4)活性预测判定阈值的确定
使用步骤(2)所述方法训练得到的最优模型对验证集进行预测,获得验证集中化学品的预测活性值,结合其对应的雌激素受体激活活性标签值画出受试者操作特性曲线(ROC曲线)。ROC曲线中TPR相对于FPR变化率最大点t所对应的预测值s
(5)待评价化学品活性判断
炔雌醇(Ethinyl estradiol,CASRN:57-63-6)作为一种人工合成的雌激素类药物,有着较高的雌激素受体激活活性,常被用来补充雌激素不足,治疗女性性腺功能不良、闭经、更年期综合征等。作为本实例中待预测化学品,通过PubChem分子数据库查询炔雌醇,并从中得到化学品炔雌醇的Canonical SMILES:“CC12CCC3C(CCc4cc(O)ccc43)C1CCC2(O)C#C”
然后将SMILES码的长度固定为120个字符,方便后续的计算,空白部分以字符“0”填充,填充后的SMILES字符串为“CC12CCC3C(CCc4cc(O)ccc43)C1CCC2(O)C#C00000000000000000000000000000000000000000000000000000000000000000000000000000000000”填充后字符串经一位有效编码转换为数字矩阵,转换后的结果见图3。
将数字矩阵作为训练的深度神经网络模型的输入信息进行计算,得到化学品炔雌醇的雌激素受体激活活性预测活性值为0.990。与预定义的判定阈值0.25相比,预测活性值远大于判定阈值。因此可以判断炔雌醇具有雌激素受体激活活性,且化学品的预测活性值较大,说明其活性也较强,预测结论与事实相符。
(6)与其他机器学习方法预测性能比较
为了更好体现本发明所述基于深度神经网络的雌激素激活活性预测方法的优越性,将本方法与现有常用随机森林分类模型和支持向量机(Support Vector Machine,SVM)分类模型进行比较。结果如下表1所示,本发明所述方法在训练集预测上,敏感性、特异性和准确率等评价指标均显著优于其他同类方法,并在验证集上有着更好的泛化能力。
表1
综上所述,本发明通过建立的端到端雌激素受体激活活性预测模型,仅基于化学品的SMILES编码就可预测化学品的雌激素受体激活活性。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 化学品雌激素受体激活活性的预测模型及筛查方法
- 一种基于中国青鳉的化学品毒性高内涵快速筛查方法