一种基于深度强化学习的空间搜索方法及设备
文献发布时间:2023-06-19 10:32:14
技术领域
本发明涉及机器学习和空间搜索技术领域,特别涉及一种基于深度强化学习的空间搜索方法及设备。
背景技术
基于路径优化的组合优化问题是运筹学中的经典问题,更有着广泛的实际应用场景,如旅行商问题、邮差问题、车辆路径问题等。针对此类NP-hard问题,主要有三种传统方法求解:精确算法,近似算法及启发式算法。常见的精确算法主要有分支限界法、动态规划法,然而精确解法受限于时间复杂度,只适用于小规模问题;近似算法包括贪婪算法、局部搜索算法、松弛算法等,提供了在多项式时间内的近似解。然而近似算法不能保证所得解的质量,最坏情况往往不尽人意;启发式算法包括遗传算法、粒子群算法等,能够相对快速得到解,然而启发式方法缺少理论支持,同时这类算法的设计需要掌握大量专业知识和反复试验,更依赖于研究者的专业水与经验。
随着大数据时代的到来以及计算能力的不断提高,基于大数据驱动的深度学习技术得到了飞速发展。深度学习的方法由于具有自动学习能力和在大数据集上较好的拟合特性,近年来越来越受到人们的青睐。深度学习在很多应用领域如图像分类、目标检测(典型应用如人脸识别、行人识别、车辆识别等)、图像分割等都有着广泛的应用。同时深度学习在解决组合优化问题上的能力也越来越受到人们重视,如AlphaGo已经远远超越人类棋手。然而这些研究均关注在一些经典模拟问题的求解,对于基于现实状态及需求的空间搜索路径优化的实际问题缺乏相关的解决方案。
发明内容
为解决上述技术问题,本发明提供了一种基于深度强化学习的空间搜索方法及设备,该方法从实际问题出发,建立空间搜索路径规划收益评价函数作为机器学习目标,通过强化学习迭代训练提升模型预测预期收益的能力,最终得到基于预期收益最大的空间搜索路径规划策略。该方法能够适用于大规模的空间搜索路径规划问题,并且能够保证结果质量。
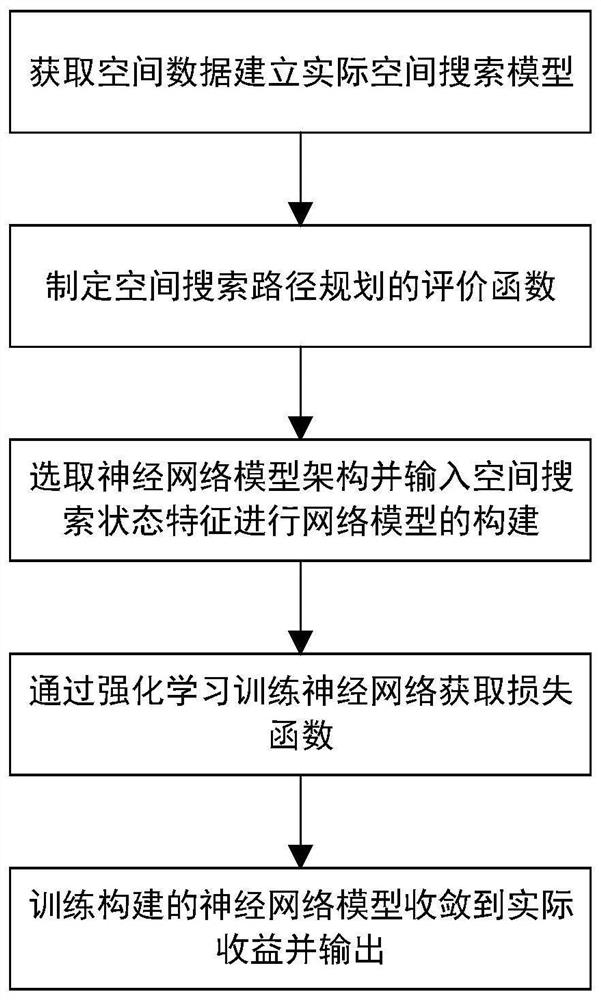
本发明提供了一种基于深度强化学习的空间搜索方法,具体技术方案如下:
S1:获取空间数据信息,建立实际空间搜索模型;
S2:根据建立的空间搜索模型中的参数制定空间搜索路径规划结果的评价函数;
S3:根据所述空间搜索模型,对路径规划的收益或对决策或对收益和决策共同建模;
获取当前时刻的空间搜索状态特征,并输入深度神经网络中,根据神经网络输出的决策或预期收益最高的行动进行下一步空间搜索更新轨迹;
S4:根据评价函数计算实际收益,采用强化学习方法迭代训练神经网络获取损失函数;
S5:通过反向传播训练神经网络,经过多次迭代,将训练收敛的神经网络作为空间搜索路径规划决策模型输出。
进一步的,在步骤S1模型的构建中,对于欧式空间可通过多种神经网络模型对空间搜索路径优化收益或决策建模,例如通过卷积神经网络对欧式空间结构化信息进行收集挖掘或者利用循环神经网络对时间上前后状态之间的相互影响进行建模;
进一步的,所述评价函数根据现实需求进行制定,通过实际的空间参数计算时空覆盖效率,得到各时间段的空间搜索收益。
进一步的,在所述评价函数的制定过程中,根据实际空间参数的重要性,构建该参数的重要性权重并进行时空覆盖率的计算,得到结合空间参数重要性的评价函数。
进一步的,步骤S3中当前状态的输入特征向量的获取包括根据不同区域时间的自由特征利用加权求和或平均的方式获取代表当前状态的空间搜索状态特征向量或根据特征类别通过OneHot向量的方式表示。
进一步的,所述损失函数的构建根据实际收益的分布类型采用不同的计算方式,包括绝对值损失函数、平方差损失函数、SmoothL
进一步的,在步骤S4中对网络模型进行强化学习训练获得损失函数时,根据建模类型选取不同的强化学习算法,对收益建模的神经网络采用Q-Learing或SARSA算法进行训练;对决策建模的神经网络的训练采用REINFORCE算法;对收益和决策同时建模的神经网络的训练采用演员-评论员算法。
进一步的,在利用反向传播训练神经网络的过程中,通过随机梯度下降法或基于梯度一阶导数二阶导数的快速下降法或对重点区域时间段设定样本权重,根据样本权重进行梯度分配,来训练神经网络。
本发明还提供了一种电子设备,包括处理器和存储器,所述处理器与存储器连接;
所述处理器,用于调用并执行所述存储器中的计算机程序,并执行如上所述的基于深度强化学习的空间搜索方法;
所述存储器用于存储计算机程序。
本发明的有益效果如下:
1、通过根据实际的空间参数建立空间搜索路径规划的评价函数作为优化目标,使得获得的网络模型能够基于现实状态及需求输出收益最大的空间搜索路径规划策略,适用于大规模的空间搜索路径规划问题。
2、根据不同空间区域时间的自有特征获取当前状态的特征向量,输入到构建的模型中获取预期收益,通过评价函数计算得到实际收益,利用强化学习方法训练获得实际收益和预期收益的损失函数,保证模型最终输出结果的准确性。
附图说明
图1是本发明的方法整体流程示意图;
图2是本发明的电子设备的结构示意图。
具体实施方式
在下面的描述中对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
本发明的实施例提供了一种基于深度强化学习的空间搜索算法,本实施例中以警车巡逻检查为例,在警车巡逻过程中,需要保持一定程度的时空覆盖率,既要对热点区域加大巡逻次数,又要保证各区域都要巡检到,如图1所示,方法的具体步骤流程如下:
S1:获取空间数据信息,建立实际空间搜索模型;
本实施例中城市的路网节点作为一个天然的图结构G,采用图卷积网络获取空间参数,进行实际空间搜索模型的构建;
将道路的交点作为节点S,道路作为边E,根据空间区域的规模设定空间细粒度,将整个路网节点S划分为N个子节点,即S
即M辆警车走过的路径是R={R
S2:根据建立的空间搜索模型中的参数制定空间搜索路径规划结果的评价函数;
基于步骤S1中构建的实际空间搜索模型,该模型中巡逻的目的就是在一个时间段中达到最大的节点覆盖,即:
若要达到最大化节点覆盖,那每个节点最多只能巡逻一次,用C
S3:根据所述空间搜索模型,对路径规划的收益或对决策或对收益和决策共同建模;
获取当前时刻的空间搜索状态特征,即将代表当前空间区域的实时状态的图数据G(S,E)作为图卷积神经网络输入特征,在规划下一时刻的巡逻路线时,既要考虑实际空间区域的结构特征当前状态,也要考虑M辆警车的历史巡逻轨迹R;
因此,将(G,R)作为图卷积网络Q(θ)的输入,输出获得当前输入特征下采取任意决策对应的预期收益,即下一时刻M辆车分别要巡逻的节点集合对应的预期收益;
将其中最大的预期收益对应的行动路径作为基于当前状态所规划的下一个时间段的最佳路径更新行动轨迹,得到R′={R′
其中,v
S4:根据评价函数计算实际收益,并通过实际收益与预期收益的差构建损失函数;
根据步骤S2中获得的评价函数Coverage(t),计算选择新决策后的巡逻收益,在下面的表述中将评价函数记为c,选择新决策后的巡逻收益计算公式如下所示:
r(R,G,v)=c(R′,G)-c(R,G)
根据建模类型选取不同的强化学习算法,因而本实施例中采用Q-learning强化学习方法训练收益网络,根据实际收益的分布类型采用不同的损失函数,本实施例中采用最小平方误差作为损失函数,损失函数计算如下所示:
((γmax
S5:通过反向传播训练神经网络,经过多次迭代,将训练收敛的神经网络作为空间搜索路径规划决策模型输出;
本实施例中采用随机梯度下降法训练图卷积网络,在完成一个巡逻周期T后,初始化,历史巡逻路径R,进行下一次迭代训练,经过N次完整巡逻周期的迭代训练,使得图卷积网络收益模型收敛至实际收益时得到的决策函数即为最终的网络模型,将当前的状态特征输入到模型中输出最大收益的行动为决策行动路径,所述决策函数如下表示:
π(v|R,G):=argmax
实施例2
本发明的实施例提供了一种基于深度强化学习的空间搜索算法,基于上述实施例,在步骤S2中,所述评价函数的制定中,根据空间搜索模型中的参数的重要性,在计算过程中附加参数的重要性权重,例如在警车巡逻路径规划问题模型中,根据不同节点治安情况不同,调整对应节点s的巡逻频次,即需要对节点s设定权重W
实施例3
本发明的实施例基于上述实施例还提供了一种电子设备,如图2所示,所述电子设备包括处理器和存储器,所述处理器与存储器连接;
所述处理器,用于调用并执行所述存储器中的计算机程序,并执行上述实施例中所述的基于深度强化学习的空间搜索方法;
所述存储器用于存储计算机程序。
本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何新的组合。
- 一种基于深度强化学习的空间搜索方法及设备
- 基于区块链的网络空间搜索方法、系统及计算设备