一种基于生成对抗网络的人体行为预测方法及系统
文献发布时间:2023-06-19 10:32:14
技术领域
本发明涉及动作识别技术领域,特别是涉及一种基于生成对抗网络的人体行为预测方法及系统。
背景技术
随着深度学习的出现,基于深度学习人体行为识别已经取得巨大突破。人体行为预测是计算机视觉领域一个比较基础和重要的任务,在安防、自动驾驶、人机交互等方面有着广泛的应用前景和研究价值。与人体行为识别任务不同,人体行为预测是对一段只能观测到部分的视频序列,基于当前的观测结果,给出视频所属的行为类别。而现有的基于深度学习的人体行为识别中,视频的观测率是100%,无法实现对一段只能观测到部分的视频序列的行为识别。
发明内容
本发明的目的是提供一种基于生成对抗网络的人体行为预测方法及系统,以实现对不完整的视频序列的行为识别。
为实现上述目的,本发明提供了如下方案:
一种基于生成对抗网络的人体行为预测方法,所述预测方法包括如下步骤:
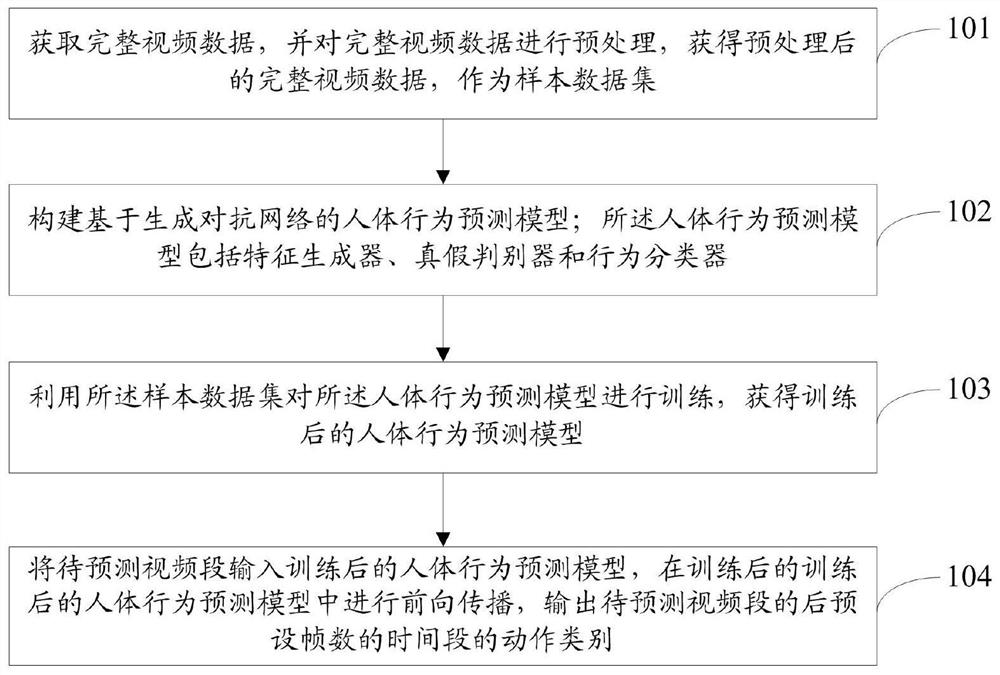
获取完整视频数据,并对完整视频数据进行预处理,获得预处理后的完整视频数据,作为样本数据集;
构建基于生成对抗网络的人体行为预测模型;
利用所述样本数据集对所述人体行为预测模型进行训练,获得训练后的人体行为预测模型;
将待预测视频段输入训练后的人体行为预测模型,在训练后的人体行为预测模型中进行前向传播,输出待预测视频段的后预设帧数的时间段的动作类别。
可选的,所述人体行为预测模型包括特征生成器、真假判别器和行为分类器;
所述特征生成器分别与所述真假判别器和所述行为分类器连接;
所述特征生成器包括存在时序依赖关系的多个卷积长短时记忆模块,每个所述卷积长短时记忆模块均包括多个卷积长短时记忆单元;
所述真假判别器和所述行为分类器均包括两个全连接层和一个激活函数层。
可选的,所述利用所述样本数据集对所述人体行为预测模型进行训练,获得训练后的人体行为预测模型,具体包括:
利用样本数据集对特征生成器和真假判别器进行预训练,获得预训练后的特征生成器和预训练后的真假判别器;
利用样本数据集对预训练后的特征生成器和行为分类器进行训练,获得训练后的人体行为预测模型。
可选的,所述利用样本数据集对特征生成器和真假判别器进行预训练,获得预训练后的特征生成器和预训练后的真假判别器,具体包括:
将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入特征生成器,获得后预设帧数的生成图像;将后预设帧数的生成图像与前预设帧数的真实图像进行合并,并将合并后的视频数据与预处理后的完整视频数据输入真假判别器,对真假判别器进行训练,直到真假判别器能够识别生成图像与真实图像,获得第n次预训练后的真假判别器;
将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入特征生成器,获得后预设帧数的生成图像,将后预设帧数的生成图像与前预设帧数的真实图像进行合并,并将合并后的视频数据与预处理后的完整视频数据输入真假判别器,对特征生成器进行训练,直到真假判别器无法识别生成图像与真实图像,获得第n次预训练后的真假判别器;
令n的数值增加1,重复上述步骤,直到n的数值达到预训练次数阈值,得到预训练后的特征生成器和预训练后的真假判别器。
可选的,所述利用样本数据集对预训练后的特征生成器和行为分类器进行训练,获得训练后的人体行为预测模型,具体包括:
将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入预训练后的特征生成器,获得后预设帧数的生成图像;
后预设帧数的生成图像输入行为分类器,获得后预设帧数的生成图像的分类结果;
根据所述分类结果,利用公式loss=L
根据所述总损失误差使用随机梯度下降算法进行误差反向传播,更新预训练后的特征生成器和行为分类器的参数,返回步骤“将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入预训练后的特征生成器,获得后预设帧数的生成图像”,直到训练次数达到训练次数阈值,输出训练后的人体行为预测模型。
一种基于生成对抗网络的人体行为预测系统,所述预测系统包括:
样本数据集获取模块,用于获取完整视频数据,并对完整视频数据进行预处理,获得预处理后的完整视频数据,作为样本数据集;
人体行为预测模型构建模块,用于构建基于生成对抗网络的人体行为预测模型;
人体行为预测模型训练模块,用于利用所述样本数据集对所述人体行为预测模型进行训练,获得训练后的人体行为预测模型;
动作类别预测模块,用于将待预测视频段输入训练后的人体行为预测模型,在训练后的人体行为预测模型中进行前向传播,输出待预测视频段的后预设帧数的时间段的动作类别。
可选的,所述人体行为预测模型包括特征生成器、真假判别器和行为分类器;
所述特征生成器分别与所述真假判别器和所述行为分类器连接;
所述特征生成器包括存在时序依赖关系的多个卷积长短时记忆模块,每个所述卷积长短时记忆模块均包括多个卷积长短时记忆单元;
所述真假判别器和所述行为分类器均包括两个全连接层和一个激活函数层。
可选的,所述人体行为预测模型训练模块,具体包括:
人体行为预测模型预训练子模块,用于利用样本数据集对特征生成器和真假判别器进行预训练,获得预训练后的特征生成器和预训练后的真假判别器;
人体行为预测模型训练子模块,用于利用样本数据集对预训练后的特征生成器和行为分类器进行训练,获得训练后的人体行为预测模型。
可选的,人体行为预测模型预训练子模块,具体包括:
真假判别器预训练单元,用于将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入特征生成器,获得后预设帧数的生成图像;将后预设帧数的生成图像与前预设帧数的真实图像进行合并,并将合并后的视频数据与预处理后的完整视频数据输入真假判别器,对真假判别器进行训练,直到真假判别器能够识别生成图像与真实图像,获得第n次预训练后的真假判别器;
特征生成器预训练单元,用于将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入特征生成器,获得后预设帧数的生成图像,将后预设帧数的生成图像与前预设帧数的真实图像进行合并,并将合并后的视频数据与预处理后的完整视频数据输入真假判别器,对特征生成器进行训练,直到真假判别器无法识别生成图像与真实图像,获得第n次预训练后的真假判别器。
可选的,所述人体行为预测模型训练子模块,具体包括:
生成图像获取单元,用于将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入预训练后的特征生成器,获得后预设帧数的生成图像;
分类结果获取单元,用于后预设帧数的生成图像输入行为分类器,获得后预设帧数的生成图像的分类结果;
总损失误差计算单元,用于根据所述分类结果,利用公式loss=L
参数更新单元,用于根据所述总损失误差使用随机梯度下降算法进行误差反向传播,更新预训练后的特征生成器和行为分类器的参数,返回步骤“将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入预训练后的特征生成器,获得后预设帧数的生成图像”,直到训练次数达到训练次数阈值,输出训练后的人体行为预测模型。
与现有技术相比,本发明的有益效果是:
本发明提出了一种基于生成对抗网络的人体行为预测方法及系统,所述预测方法包括如下步骤:获取完整视频数据,并对完整视频数据进行预处理,获得预处理后的完整视频数据,作为样本数据集;构建基于生成对抗网络的人体行为预测模型;利用所述样本数据集对所述人体行为预测模型进行训练,获得训练后的人体行为预测模型;将待预测视频段输入训练后的人体行为预测模型,在训练后的人体行为预测模型中进行前向传播,输出待预测视频段的后预设帧数的时间段的动作类别。本发明利用生成对抗网络的特征生成器生成后预设帧数的视频帧图像,然后利用行为分类器对后预设帧数的视频帧图像进行识别,获得行为识别结果,实现了对不完整的视频序列的行为识别。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提供的一种基于生成对抗网络的人体行为预测方法的流程图;
图2为本发明提供的人体行为预测模型的结构图;
图3为本发明提供的特征生成器的结构图;
图4为本发明提供的真假判别器的结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种基于生成对抗网络的人体行为预测方法及系统,以实现对不完整的视频序列的行为识别。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1所示,本发明一种基于生成对抗网络的人体行为预测方法,所述预测方法包括如下步骤:
步骤101,获取完整视频数据,并对完整视频数据进行预处理,获得预处理后的完整视频数据,作为样本数据集。
预处理包括提帧、尺寸裁剪、片段分割、稀疏采样等。
具体的,假设输入网络的视频序列为S
步骤102,构建基于生成对抗网络的人体行为预测模型。
生成对抗网络(GAN)是近年来来获得大量关注的图像生成模型,由一个生成网络与一个判别网络组成,通过让两个神经网络相互博弈的方式进行学习。是非监督式学习的一种方法。生成网络从潜在空间中随机采样作为输入,其输出结果需要尽量模仿训练集里的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实。
如图2所示,所述人体行为预测模型包括特征生成器G、真假判别器D和行为分类器C。所述特征生成器分别与所述真假判别器D和所述行为分类器C连接。
所述特征生成器G包括存在时序依赖关系的多个卷积长短时记忆模块,每个所述卷积长短时记忆模块均包括多个卷积长短时记忆单元。
如图3所示,本发明使用ConvLSTM(Convolutional LSTM Network,卷积长短时记忆模块)作为特征生成器的基本单元,不同于FC-LSTM,ConvLSTM输入门与各个门之间的连接是卷积而不是全连接,这种固有的卷积和LSTM结构,能更好地处理和保留数据的时空特征。ConvLSTM计算表达式如下:
其中*表示卷积操作,°表示哈达玛积操作。X
本发明使用多个ConvLSTM级联作为特征生成器G的基本结构,如图3所示。本发明使用视频片段作为特征生成器G的输入,让模型学习与输入片段相类似的特征数据,然后通过LSTM结构预测生成类似的数据。
所述真假判别器和所述行为分类器均包括两个全连接层和一个激活函数层。
生成对抗网络包括一个特征生成器G和一个真假判别器D,其中特征生成器G用来生成和输入相类似的数据分布,真假判别器D能够准确地把生成的数据和真实数据进行分类。简而言之,真假判别器D就是一个二分类器,对生成的数据输出0,表示假;对真实的数据输出1,表示真。所谓的对抗,指的是特征生成器G和真假判别器D的互相对抗。特征生成器G尽可能生成逼真样本,真假判别器D则尽可能去判别该样本是真实样本还是生成的假样本。
如图4所示,本发明的真假判别器由两个全连接层FC和一个sigmoid激活函数组成,两个全连接层的维度分别为4096和1024。
行为分类器C与真假判别器D相类似,行为行为分类器由两个全连接层FC和一个softmax激活函数组成,对于每个生成的特征输出对应类别的概率分布。同时,对于真实特征样本,本发明也通过行为分类器得到它们的概率分布,以此来得到更优的动作预测和分类的结果。该行为分类器中使用的全连接层的维度与真假判别器一致,分别为4096和1024。
步骤103,利用所述样本数据集对所述人体行为预测模型进行训练,获得训练后的人体行为预测模型。
步骤103所述利用所述样本数据集对所述人体行为预测模型进行训练,获得训练后的人体行为预测模型,具体包括:
利用样本数据集对特征生成器和真假判别器进行预训练,获得预训练后的特征生成器和预训练后的真假判别器。具体包括:将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入特征生成器,获得后预设帧数的生成图像;将后预设帧数的生成图像与前预设帧数的真实图像进行合并,并将合并后的视频数据与预处理后的完整视频数据输入真假判别器,对真假判别器进行训练,直到真假判别器能够识别生成图像与真实图像,获得第n次预训练后的真假判别器;将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入特征生成器,获得后预设帧数的生成图像,将后预设帧数的生成图像与前预设帧数的真实图像进行合并,并将合并后的视频数据与预处理后的完整视频数据输入真假判别器,对特征生成器进行训练,直到真假判别器无法识别生成图像与真实图像,获得第n次预训练后的真假判别器;令n的数值增加1,重复上述步骤,直到n的数值达到预训练次数阈值,得到预训练后的特征生成器和预训练后的真假判别器。
利用样本数据集对预训练后的特征生成器和行为分类器进行训练,获得训练后的人体行为预测模型,具体包括:将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入预训练后的特征生成器,获得后预设帧数的生成图像;后预设帧数的生成图像输入行为分类器,获得后预设帧数的生成图像的分类结果;根据所述分类结果,利用公式loss=L
生成对抗网络优化的目标函数如下:
其中,L
行为分类的损失函数定义如下:
其中,s∈R
综上,网络的整体目标函数表达式如下:
L
其中,λ为调节系数,主要用来调节两项损失的占比。
步骤104,将待预测视频段输入训练后的人体行为预测模型,在训练后的人体行为预测模型中进行前向传播,输出待预测视频段的后预设帧数的时间段的动作类别。
本发明还提供一种基于生成对抗网络的人体行为预测系统,所述预测系统包括:
样本数据集获取模块,用于获取完整视频数据,并对完整视频数据进行预处理,获得预处理后的完整视频数据,作为样本数据集;
人体行为预测模型构建模块,用于构建基于生成对抗网络的人体行为预测模型;所述人体行为预测模型包括特征生成器、真假判别器和行为分类器;所述特征生成器分别与所述真假判别器和所述行为分类器连接;所述特征生成器包括存在时序依赖关系的多个卷积长短时记忆模块,每个所述卷积长短时记忆模块均包括多个卷积长短时记忆单元;
所述真假判别器和所述行为分类器均包括两个全连接层和一个激活函数层。
人体行为预测模型训练模块,用于利用所述样本数据集对所述人体行为预测模型进行训练,获得训练后的人体行为预测模型。
所述人体行为预测模型训练模块,具体包括:人体行为预测模型预训练子模块,用于利用样本数据集对特征生成器和真假判别器进行预训练,获得预训练后的特征生成器和预训练后的真假判别器;人体行为预测模型训练子模块,用于利用样本数据集对预训练后的特征生成器和行为分类器进行训练,获得训练后的人体行为预测模型。
人体行为预测模型预训练子模块,具体包括:真假判别器预训练单元,用于将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入特征生成器,获得后预设帧数的生成图像;将后预设帧数的生成图像与前预设帧数的真实图像进行合并,并将合并后的视频数据与预处理后的完整视频数据输入真假判别器,对真假判别器进行训练,直到真假判别器能够识别生成图像与真实图像,获得第n次预训练后的真假判别器;特征生成器预训练单元,用于将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入特征生成器,获得后预设帧数的生成图像,将后预设帧数的生成图像与前预设帧数的真实图像进行合并,并将合并后的视频数据与预处理后的完整视频数据输入真假判别器,对特征生成器进行训练,直到真假判别器无法识别生成图像与真实图像,获得第n次预训练后的真假判别器。
所述人体行为预测模型训练子模块,具体包括:生成图像获取单元,用于将样本数据集中的预处理后的完整视频数据的前预设帧数的真实图像输入预训练后的特征生成器,获得后预设帧数的生成图像;分类结果获取单元,用于后预设帧数的生成图像输入行为分类器,获得后预设帧数的生成图像的分类结果;总损失误差计算单元,用于根据所述分类结果,利用公式loss=L
动作类别预测模块,用于将待预测视频段输入训练后的人体行为预测模型,在训练后的人体行为预测模型中进行前向传播,输出待预测视频段的后预设帧数的时间段的动作类别。
与现有技术相比,本发明的有益效果是:
本发明提出了一种基于生成对抗网络的人体行为预测方法及系统,所述预测方法涉及深度学习,动作识别以及特征预测等领域,包括如下步骤:构建基于对抗生成网络的人体行为预测模型;人体行为预测模型包括:特征生成器,真假判别器,行为分类器;采用特征生成器对训练数据集进行未来帧的特征级预测,真假判别器对生成的特征进行真假判别,同时,由行为分类器对其进行行为类别的判定;本发明提出一种新型的人体行为预测方法,具有广泛的应用价值。
本发明所述基于生成对抗网络的人体行为预测方法,是视频分析的新方法,利用生成对抗网络生成未来帧特征,进而对特征进行分类,增加了分类的可靠性,相比于传统的特征提取分类预测的方法来对未来帧进行分类,更精确。
本发明对抗生成网络在图像生成领域有突破性进展,但是其用在行为预测领域,缺少对时序信息的捕捉,本发明采用卷积长短时记忆模块作为特征生成器的主要组成部分,除了对人体行为空间特征的提取之外,还加入对时序信息的捕捉,能够对人体行为的判断做出更准确的估计。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上,本说明书内容不应理解为对本发明的限制。
- 一种基于生成对抗网络的人体行为预测方法及系统
- 一种基于人体骨架运动信息的人体行为预测方法