一种基于对比学习的实体关系三元组抽取方法
文献发布时间:2023-06-19 10:32:14
技术领域
本发明属于文本信息关系抽取技术领域,尤其是涉及一种基于对比学习的实体关系三元组抽取方法。
背景技术
关系抽取是自然语言处理和知识图谱的重要信息提取任务,用于从非结构化文本中检测实体对及其之间的关系。考虑一下这句话:“巴黎被誉为法国的浪漫之都。”由此,理想的关系抽取是将(法国,首都,巴黎)这个三元组抽取出来,其中首都是巴黎和法国的关系。
过去,研究者提出了流水线方法,他们通常将关系抽取问题解构为两个单独的任务:基于命名实体识别的实体词提取和关系分类。因此,他们首先提取到实体,然后预测实体之间的关系。不幸的是,这种流水线方法存在弊端,因为他们忽略了命名实体识别和关系分类任务之间的关联性,从而导致错误传播。
最近,有研究者提出了几种基于神经网络的模型来联合提取句子中的实体和关系。这些模型使用参数共享机制同时提取实体和关系。除了这些方法外,也有研究者提出了一种基于递归神经网络的编码器-解码器模型也就是CopyRE,以提取具有重叠实体的三元组。这种端到端的生成三元组提取不仅可以直接获取三元组并缓解错误传播问题,而且还可以生成T5样式的域外实体和关系。此外,还有研究者提出了一种多任务学习框架CopyMTL,该框架配备了复制机制以允许预测多令牌实体。也有研究者引入了三元组的表示方案和基于指针网络的解码方法,这进一步提高了CopyRE的性能。
编码器-解码器模型是功能强大的工具,已在许多NLP任务中获得成功,例如从结构化数据生成句子任务和开放信息提取任务。尽管已经取得了重大进展,但是现有方法仍然存在两个关键问题。
首先,由于递归神经网络的固有缺陷,它们无法捕获长期依赖关系,从而导致重要信息的丢失,从而导致模型无法应用在更长的文本。
第二,缺乏机制致力于生成忠实的三元组,序列到序列的体系结构会产生不忠实的序列,从而产生意义上的矛盾。
例如,给定句子“钱塘江流经杭州,被誉为天下第一潮,是吴越文化的主要发源地之一”,以往模型可以生成三元组实例“钱塘江位于杭州”。尽管从逻辑上讲是正确的,但无法从给定的句子中找到直接的证据来支持它。
发明内容
本发明提供了一种基于对比学习的实体关系三元组抽取方法,解决了以往序列到序列的生成模型方法会产生不忠实的三元组序列情况,优化了实体关系三元组生成的准确率。
一种基于对比学习的实体关系三元组抽取方法,包括以下步骤:
(1)对于训练数据集,利用伯努利分布进行批次采样,采样后的一部分数据作为三元组生成训练集,另一部分作为对比学习初始数据集;
(2)在对比学习初始数据集中,将选出的黄金三元组作为积极实例,并通过在积极实例中用随机令牌替换一个实体来生成损坏的三元组作为消极实例,从而构造二元分类的对比学习训练集;
(3)利用多层Transformer体系结构作为骨干编码网络,构建实体关系抽取网络,所述的实体关系抽取网络包括令牌化模块、生成模块和对比学习模块;
(4)利用三元组生成训练集和对比学习训练集对实体关系抽取网络的生成模块和对比学习模块进行训练,采用批量动态注意掩码机制来对三元组生成任务和三元组对比学习判别任务进行联合优化训练;
(5)实体关系抽取网络训练结束后,进行实体关系三元组抽取的应用,通过波束搜索生成实体关系的三元组序列;
(6)通过三元组过滤算法滤除不忠实的三元组,通过启发式规则剔除不合理性的三元组,得到最终的三元组。
步骤(1)的具体过程为:
设定训练数据集按照伯努利分布进行批次采样,具体公式为:
x~Bernouli(1,p)
其中,p为生成训练集的采样概率值,这部分采样作为三元组生成训练集,1-p为对比学习数据集的采样概率值,这部分采样作为对比学习初始数据集;p的概率值是超参数,用于控制采样比例。
步骤(2)中,在构造二元分类的对比学习训练集时,还包括:
对于积极实例,将积极实例对应的源数据文本和目标黄金三元组拼接起来,并存入到正样本实例数据集中;
对于消极实例,将目标黄金三元组的任意头实体、尾实体或者关系用随机令牌替换,然后将其与对应的源数据文本拼接起来,并存入到负样本实例数据集中。
正样本实例数据集和负样本实例数据集构成二元分类的对比学习训练集。
步骤(3)中,令牌化模块,用于将传入实体关系抽取网络的文本内容通过分词技术对文本进行标记化,并通过将相应的令牌词嵌入,位置嵌入和语义嵌入相加来表示最终的嵌入信息。
生成模块用于完成三元组生成任务,三元组生成任务采用Transformer体系结构获取上下文信息并预测以下对象:
其中,x
损失函数优化目标用以下公式表示:
式中,loss
对比学习模块用于完成对比学习判别任务,对比学习判别任务利用对比学习训练集作为具有全零掩码的二元分类,对比学习数据集中包含正样本实例数据集和负样本实例数据集,将输入句子用以下公式连接起来并将其输入到输入编码器中:
[CLS],x
其中,x
利用带有MLP层的[CLS]表示来计算分类得分z,公式如下:
z=f
式中,f
然后,利用交叉熵进行损失对比优化,公式如下:
其中,loss
步骤(4)中,动态注意掩码机制按照输入任务的不同采用两类不同的掩码机制,在训练生成模块时采用序列到序列的掩码机制,在训练对比学习模块时采用双向的掩码机制。
步骤(5)中,通过波束搜索生成实体关系的三元组序列具体过程为:设定超参数集束宽为k,每次在生成的结果中选择概率最高的前k个,在最终候选输出序列的集合中,采用以下公式得分最高的结果作为生成三元组序列:
其中,L为最终候选序列长度,α为惩罚项因子,用以惩罚较长序列在以上分数中较多的对数相加项;t′表示当前序列步骤,c表示融合了输入文本上下文信息的句子编码向量,P表示序列生成概率。
步骤(6)的具体过程为:
取得波束搜索生成可能的三元组序列;对生成的三元组序列进行启发式规则的约束,剔除结构不合理的三元组;对每个三元组通过对比学习分类器进行匹配分数计算;滤除低于匹配分数阈值的生成三元组;将生成三元组重组成预定的输出结构,传入输出序列中。
与现有技术相比,本发明具有以下有益效果:
1、本发明解决了以往流水线方法存在的先判断实体后关系导致的错误传播问题,端到端的模型结构也有效提高了关系抽取中重叠实体抽取的准确率,在捕获长期依存关系方面也比现有的三元组抽取方法更好,在多个中英文文本语料抽取中也取得了较好的效果。
2、本发明设计了带有多层Transformer的三元组对比学习训练框架,该框架是一个共享的Transformer模块,具有支持编码器-解码器模型架构的三元组序列生成形式,除了预先训练的模型之外,训练模型不需要任何其他参数,采用的批处理动态注意掩码可以联合优化不同的对象,推断机制可以确保忠实的推理。
3、本发明设计了一种端到端的实体关系三元组抽取框架,其中输出三元组可以是任意自定义的范式,可以支持更灵活的三元组序列生成形式,相比以往序列标注形式的输出具备更多的应用场景。
附图说明
图1为本发明实施例提供的基于对比学习的实体关系三元组抽取方法的流程示意图;
图2为本发明实施例提供的实体关系抽取网络模型结构示意图;
图3为本发明实施例提供的图1中步骤600的流程示意图。
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
如图1所示,一种基于对比学习的实体关系三元组抽取方法,包括:
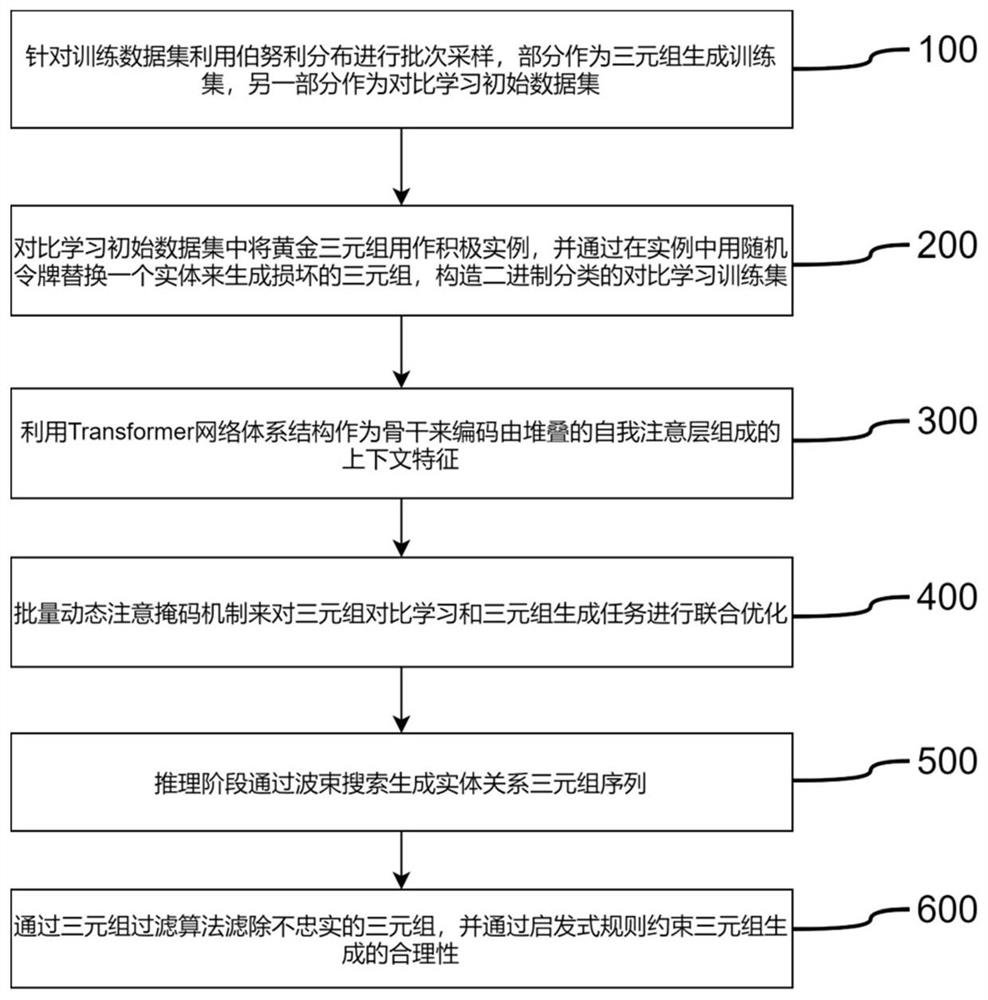
步骤100、针对训练数据集利用伯努利分布进行批次采样,部分作为三元组生成训练集,另一部分作为对比学习初始数据集,具体为:
设定训练数据集进行批次采样按照伯努利分布进行采样,具体公式为:
x~Bernouli(1,p)
其中,p为生成训练集的采样概率值,这部分采样作为三元组生成训练集;1-p为对比学习数据集的采样概率值,这部分采样作为对比学习初始数据集;p的概率值是超参数,用于控制采样比例。
步骤200、对比学习初始数据集中将黄金三元组用作积极实例,并通过在实例中用随机令牌替换一个实体来生成损坏的三元组,构造二元分类的对比学习训练集;
在本发明实施例中,积极实例与消极实例是由同一个原始对比学习数据集中的实例产生。
如图2所示,步骤200进一步包括:
步骤210、分别传入正样本原始数据集和负样本原始数据集;
步骤220、正样本原始数据集中,将源数据文本和目标黄金三元组拼接起来,并存入到正样本实例数据集中;
具体地,目标黄金三元组存在多个时,利用分隔符将其隔开,例如实例中存在两个三元组时,与源数据文本重新组合为如下预定的数据形式规格:
Source test[SEQ]h
其中,Source text为源文本数据,[SEQ]为源文本数据与目标黄金三元组之间的预设分隔符,[S2S_SEQ]为不同目标黄金三元组之间的预设分隔符,h为头实体,r为关系,t为尾实体,->为三元组的指向分隔符。
步骤230、负样本原始数据集中,将目标黄金三元组的任意头实体、尾实体或者关系用随机令牌替换,然后将其与源数据文本拼接起来并存入到负样本实例数据集中;
具体地,目标黄金三元组存在多个时,每个被替换的黄金三元组分别用随机令牌替换头实体、尾实体或者关系中的一个,按照与正样本实例数据集预定的数据形式规格与数据源文本重新组合。
在实施前述步骤后,得到构造二元分类的对比学习训练集,其中包含正样本实例数据集和负样本实例数据集。
步骤300、利用Transformer网络体系结构作为骨干来编码由堆叠的自我注意层组成的上下文特征。
具体地,给定输入文本x,我们在目标输入的开头添加一个特殊的序列开始标记[SOS],使用整个输入的表示作为输出向量。
此外,在每个输出序列的末尾附加一个特殊标记,即序列末尾[EOS],[EOS]令牌用作特殊令牌,以终止用于三重生成的解码过程。
输入表示与用于BERT的输入表示相同,使用WordPiece将文本标记为子词单位,例如,单词“predict”分为“predict”和“##ed”,其中“##”指的是属于一个单词的片段,通过将相应的令牌嵌入,位置嵌入和段嵌入相加来计算每个输入令牌向量表示形式。
本发明的实体关系抽取网络利用多层Transformer体系结构作为骨干编码网络来堆叠自我注意层的上下文特征,采用以下公式计算每一层的Transformer自我编码:
H
其中,H
本发明构建的实体关系抽取网络包括令牌化模块、生成模块和对比学习模块。
形式上,本发明把优化目标分为两个任务,三元组生成任务和对比学习判别任务。
生成模块用于完成三元组生成任务,三元组生成任务采用Transformer体系结构获取上下文表示并优化以下对象:
其中,x
对比学习模块用于完成对比学习判别任务,对比学习判别任务利用对比学习训练集作为具有全零掩码的二元分类,对比学习数据集其中包含积极实例数据集和负样本实例数据集,将输入句子用以下公式连接起来并将其输入到输入编码器中:
[CLS],x
其中,x
利用带有MLP层的[CLS]表示来计算分类得分z,公式如下:
z=f
然后利用交叉熵进行损失对比优化,公式如下:
其中,
步骤400、批量动态注意掩码机制来对三元组对比学习和三元组生成任务进行联合优化;
如图2所示,具体地,动态注意掩码机制按照输入任务的不同采用两类不同的掩码机制,右上部分表示生成模块掩码,右下部分表示对比学习模块掩码,在生成模块中S
在训练生成模块时需要语言模型做序列到序列的编码,Transformer系统架构中的Attention矩阵中引入下三角形形式的Mask,右上角被设置为无穷大,使目标黄金三元组序列看不到源文本序列,往下的右上角值设置为无穷大,其他值为0,这是为了让目标序列只注意到上文,忽略其下文。
在训练对比学习模块时需要语言模型做双向编码,Transformer系统架构中的Attention矩阵中引入双向语言模型掩码机制,源文本数据与目标黄金三元组序列范围掩码值都设置为0,只对padding进行掩码,设置为无穷大。
步骤500、推理阶段通过波束搜索生成实体关系三元组序列;
具体地,在预训练结束后,设定超参数集束宽为k,每次在生成的结果中选择概率最高的前k个,在最终候选输出序列的集合中,选择以下公式得分最高的结果作为生成三元组序列:
其中,L为最终候选序列长度,α惩罚项因子用以惩罚较长序列在以上分数中较多的对数相加项,一般为0.75。
步骤600、通过三元组过滤算法滤除不忠实的三元组,并通过启发式规则约束三元组生成的合理性;
如图3所示,步骤600进一步包括:
步骤610、取得波束搜索生成可能的三元组序列;
步骤620、对生成的三元组序列进行启发式规则的约束,剔除结构不合理的三元组;
具体地,启发式规则约束要求生成的三元组序列遵循以下数据格式,并调整或删除不满足格式的三元组,关系应遵循由主体指向客体的规则:
h
步骤630、对每个三元组通过对比学习分类器进行匹配分数计算;
具体地,对每个三元组进行以下公式的匹配计算:
match_score=Contrastive_Classify(x
其中,match_score为分类器匹配分数,Contrastive_Classify为对比学习分类器,x
步骤640、滤除那些低于匹配分数阈值的生成三元组;
具体地,我们设定match_score匹配阈值分数θ,将超过阈值分数的生成序列三元组合并到待输出的三元组列表中。
步骤650、将生成三元组列表重组成预定的输出结构,传入输出序列中。
为验证本发明的效果,本发明分别选取NYT和WebNLG两个英文数据集和MIE中文医疗数据集进行实验,NYT包含了24种关系和104518个三元组,WebNLG包含了246种关系和12863个三元组,MIE包含了343种关系和18212个三元组。表1为三个数据集上关系抽取结果。
表1
通过实验结果可以看出,在NYT和WebNLG数据集上,本发明基于对比学习的实体关系三元组抽取方法取得了显著的实验结果,并且可以生成超出实体和关系域的三元组,这对于开放域关系抽取也有帮助,与MIE数据集上,本发明显示出在中文数据集上可以有效解决实体词之间的重叠问题,也能够取得可比的性能。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
- 一种基于对比学习的实体关系三元组抽取方法
- 一种基于主动深度学习的实体关系联合抽取方法及系统