基于Actor-Critic框架深度强化学习算法的交通灯信号控制方法
文献发布时间:2023-06-19 10:32:14
技术领域
本发明涉及智能交通领域道路交叉口交通灯信号控制方法,具体涉及一种基于Actor-Critic框架深度强化学习算法的交通灯信号控制方法。
背景技术
交通信号控制是在无法实现道路交通流空间分离的地方(主要是指平面道路交叉口),在时间上给相互冲突的交通流分配通行权的一种交通管理措施。作为城市交通管理的重要手段,交通信号控制地质量水平在很大程度上决定了城市道路网络的运行质量。优质的交通信号控制方法能够有效引导和调度交通流,增加道路交叉口的通行能力、降低交叉口碰撞事故的发生率,提高交通系统的整体效益;而设计不完善的信号控制方法则有可能降低城市道路利用率、增加车辆延误、加重交通拥堵。
近几年迅速兴起的人工智能技术,为智能交通信号控制带来了新的发展契机。强化学习作为机器学习的一个重要分支,无需建立环境模型,仅通过与外部环境的交互与试错即可完成智能序贯决策,能够在时变性和随机性较强的城市道路交通系统中实现高效自适应控制,因此成为智能信号控制的研究热点。基于强化学习的交通信号控制技术种类繁多,主流方法分为两类。第一类主要依靠基于值函数的强化学习方法,如Q学习、SARSA等方法;第二类主要依靠基于策略的强化学习方法,如策略梯度法。
已有方法的主要不足可以归纳为以下两点:首先,现有方法的控制效果亟待提升。基于值函数的强化学习算法在复杂的城市路网系统中很难训练出准确的值函数,且状态空间和动作空间过高时此类算法将面临维度灾难;基于策略的强化学习算法虽然运算复杂度较低,但是采样轨迹方差过大,因此模型训练效率偏低且收敛效果较差。其次,现有方法的可行性和安全性偏低。目前多数方法都选择了相序不固定的信号配时方案,如果将其应用于真实路口,很可能引发司机和行人不解甚至不满,并且增加交叉口的事故发生率。
发明内容
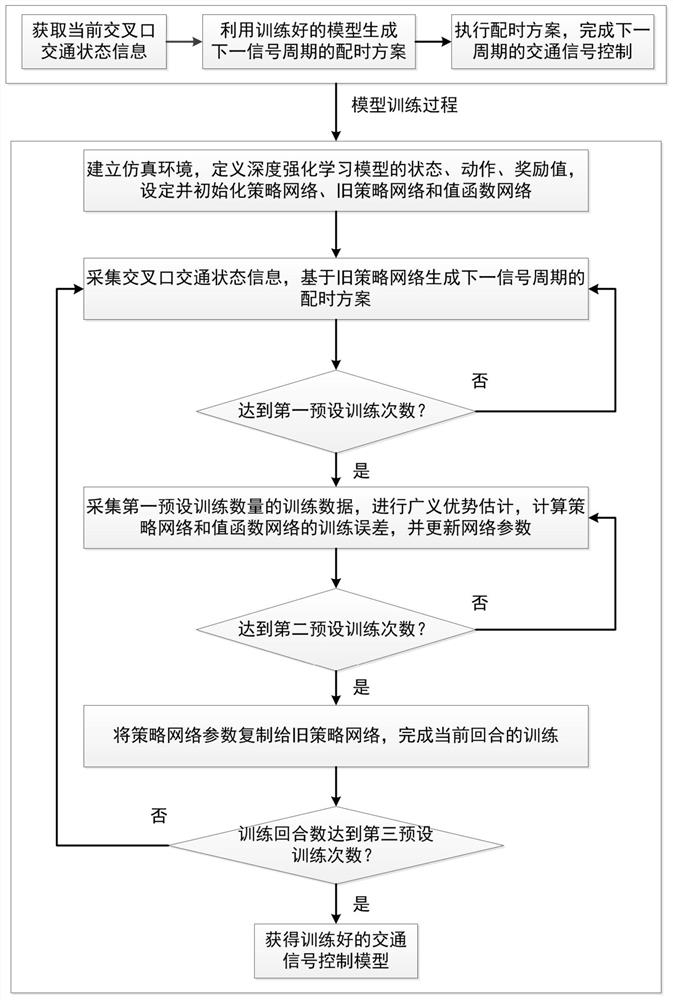
为了克服现有技术的上述不足,本发明提供一种基于Actor-Critic框架深度强化学习算法的交通灯信号控制方法,该控制方法包括:
步骤S10,获取当前交叉口的交通状态信息;
步骤S20,利用训练好的交通信号控制模型,根据当前交叉口的交通状态生成下一周期的信号配时方案;
其中,所述交通信号控制模型是基于Actor-Critic框架的深度强化学习方法训练的,具体包含以下步骤:
步骤B10,配置仿真路口环境和车流数据到交通模拟器,搭建交通仿真环境,定义深度强化学习模型的状态、动作和奖励值函数,设定并初始化策略网络、旧策略网络和值函数网络。
步骤B20,采集当前交叉口的交通状态信息,基于旧策略网络生成下一信号周期的交通灯配时方案,并由交通模拟器仿真下一个信号周期;
步骤B30,判断仿真步数是否达到第一预设训练次数,若没有达到,则返回步骤B20,否则执行步骤B40;
步骤B40,采集第一预设训练次数的经验,所述经验包括交叉口状态、动作和奖励;进行广义优势估计,计算策略网络和值函数网络的训练误差,并更新网络参数;
步骤B50,判断训练次数是否达到第二预设训练次数,若没有达到,则返回步骤B40,否则执行步骤B60;
步骤B60,将策略网络参数复制给旧策略网络,完成当前回合的训练;
步骤B70,判断训练回合数是否达到第三预设训练次数,若没有达到,则返回步骤B20,开启新一回合的训练;若已达到,则获得训练好的交通信号控制模型。
在本发明中,步骤B10中所述的“车流数据”为真实道路上采集的车流数据,而步骤B10中所述的“定义深度强化学习模型的状态、动作和奖励值函数”,其方法为:
B101,将状态s
B102,将动作a
其中
已有的基于强化学习的信号控制算法中设计的动作大多定义为“维持当前相位”或“切换当前相位”,因此信号控制方案中的相位顺序很可能是不断变化的。由本发明设计的动作可知,本发明生成的信号控制方案的相位顺序是稳定不变的,且每次只在较小的范围内改变某一个相位的时长,这种方案的实用性更强且安全性更高。
B103,将奖励值函数r
其中T表示每回合的轨迹数,q
步骤B10中所述的“设定并初始化策略网络、旧策略网络和值函数网络”,其方法为:
策略网络、旧策略网络和值函数网络的输入信息均为交叉口实时状态s
步骤B20中所述的“生成下一信号周期的交通灯配时方案”,其方法为:
旧策略网络的输出中,概率最高的动作即为当前时间步所选动作,根据前文所述的动作定义,延迟或缩短当前信号周期某一相位的时长(也可能是不修改任一相位时长),即为下一信号周期的交通灯配时方案。
步骤B40中所述采集第一预设训练次数的经验并进行广义优势估计的方法为:
广义优势函数的定义如下:
其中B为第一预设训练次数,mod是运算符,表示除法后取余,γ∈[0,1]是折扣因子,λ∈[0,1]是超参数,通过合理调整λ的取值能够有效权衡状态值函数的方差和偏差。
步骤B40中所述“计算策略网络和值函数网络的训练误差,并更新网络参数”,其方法为:
策略网络的训练采用了近端策略优化算法,其目标函数为:
其中r
clip()函数用于将r
值函数网络的目标函数为:
其中
采集第一预设训练次数的轨迹,输入策略网络、旧策略网络和值函数网络,获得动作概率分布π
优选地,步骤B102所述的时长延长w秒,时长缩短w秒,均取5秒;所述的较小的范围内是指10秒之内。
与现有技术相比,本发明具有以下有益效果:
本发明基于Actor-Critic框架的深度强化学习算法,并使用了广义优势估计和近端策略优化等先进的强化学习技术,显著提升了信号控制模型的控制效果,显著降低了交叉口平均排队长度、平均旅行时间和车辆平均延误等指标;本发明提出的全新的奖励值函数的定义方法,能够显著提升模型的训练效率;本发明生成的交通灯信号配时方案相序稳定且相邻周期的配时方案变化幅度不大,具备较高的实用性和安全性。
附图说明
图1为本发明方法的流程示意图。
图2为本发明实施例的强化学习模型结构示意图。
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,对其不起任何限定作用。
如图1所示,一种基于Actor-Critic框架深度强化学习算法的交通灯信号控制方法,包括以下步骤:
步骤S10,获取当前交叉口的交通状态信息;
步骤S20,利用训练好的交通信号控制模型,根据当前交叉口的交通状态生成下一周期的信号配时方案;其中所述交通信号控制模型是基于Actor-Critic框架的深度强化学习方法训练的,具体包含以下步骤:
步骤B10,配置仿真路口环境和车流数据到交通模拟器,搭建交通仿真环境,定义深度强化学习模型的状态、动作和奖励值函数,设定并初始化策略网络、旧策略网络和值函数网络。
其中车流数据为真实道路上采集的车流数据,这一步可以根据实际情况设计路口结构和车流,交通模拟器可以是开源的也可以是商用软件,只要能实现必要的信号灯控制和路况反馈即可。
深度强化学习模型的状态s
深度强化学习模型的动作a
其中
已有的基于强化学习的信号控制算法中设计的动作大多定义为“维持当前相位”或“切换当前相位”,因此信号配时方案中的相位顺序很可能是不断变化的。由本发明设计的动作可知,本发明生成的信号配时方案的相位顺序是稳定不变的,且每次只在较小的范围内(5s)改变某一个相位的时长,这种方案的实用性更强且安全性更高。
深度强化学习的奖励值函数r
其中T表示每回合的轨迹数,q
如图2所示,策略网络、旧策略网络和值函数网络的输入信息均为交叉口实时状态s
步骤B20,采集当前交叉口的交通状态信息,基于旧策略网络生成下一信号周期的交通灯配时方案,并由交通模拟器仿真下一个信号周期。旧策略网络的输出中,概率最高的动作即为当前时间步所选动作,根据前文所述的动作定义,延迟或缩短当前信号周期某一相位的时长(也可能是不修改任一相位时长),即为下一信号周期的交通灯配时方案。在交通模拟器内按照这一方案执行下一个信号周期即可。
步骤B30,判断仿真步数是否达到第一预设训练次数,若没有达到,则返回步骤B20,否则执行步骤B40;
步骤B40,采集第一预设训练次数的经验,所述经验包括交叉口状态、动作和奖励;进行广义优势估计,计算策略网络和值函数网络的训练误差,并更新网络参数。广义优势函数的定义如下:
其中B为第一预设训练次数,mod是运算符,表示除法后取余,γ∈[0,1]是折扣因子,λ∈[0,1]是超参数,通过合理调整λ的取值能够有效权衡状态值函数的方差和偏差。
策略网络的训练采用了近端策略优化算法,其目标函数为:
其中r
clip()函数用于将r
值函数网络的目标函数为:
其中
采集第一预设训练次数的轨迹,将路口状态信息输入策略网络、旧策略网络和值函数网络,获得动作概率分布π
步骤B50,判断训练次数是否达到第二预设训练次数,若没有达到,则返回步骤B40,否则执行步骤B60;
步骤B60,将策略网络参数复制给旧策略网络,完成当前回合的训练;
步骤B70,判断训练回合数是否达到第三预设训练次数,若没有达到,则返回步骤B20,开启新一回合的训练;若已达到,则获得训练好的交通信号控制模型。
本发明能够显著提升信号控制模型的模型训练效率,明显降低交叉口平均排队长度、平均旅行时间和车辆平均延误等指标,且本发明生成的信号配时方案具备更高的实用性和安全性。
- 基于Actor-Critic框架深度强化学习算法的交通灯信号控制方法
- 基于深度强化学习中Actor-Critic框架的策略选择方法