分布式语音处理系统及方法
文献发布时间:2023-06-19 10:35:20
技术领域
本申请涉及分布式语音处理领域,尤其涉及一种分布式语音处理系统及方法。
背景技术
语音识别技术和关键词识别技术日趋成熟,且在市场中的应用越来越广泛,比如儿童玩具、教育产品、智能家居等产品中都加入了语音识别功能,实现语音交互控制的功能。
当前的语音识别有两种常见的方法,一种是基于单个设备的本地识别,另一种是基于本地识别结合服务器云端的识别。
对于第一种方法,智能家居市场上常用的单个设备实现本地语音控制,其语音识别过程是将原始语音采集到一个设备,在这个设备上进行计算获得识别结果。这种方法在应用过程中,如果用户在空间环境中移动或需要跨房间识别时,受拾音距离的限制,常常不能顺利完成语音识别,从而导致出现不能识别或识别效果差的情况。
对于第二种方法,市面上通常通过智能音箱或者智能网关等进行语音识别。这些设备作为控制中枢,同时也是语音识别的唯一入口。设备必须先连接到互联网,然后接入相应的云端服务器也需要连接到互联网。这些设备从云端获取语音识别结果,进而完成语音识别或语音控制。这种方法存在问题,例如作为语音识别的唯一入口的设备发生故障、或者网络出现波动等,都会造成语音识别失败的问题。特别是,当网络稳定性较差时,容易导致识别响应速度慢。此外,此类语音识别方法将语音上传至云端,并且设备需要实时监听周围环境声音,容易导致出现用户隐私安全问题。
与此同时,这两种方法都存在不能跨房间的语音识别控制等问题。
除了上述两种方法之外,还存在另外一种本地中心识别方法,其将多个点的原始语音采集后,传输到一个中心设备进行语音识别。该方法可以用于解决拾音距离短、跨房间识别难、人员移动等问题。但这个方法严重依赖中心设备,当中心设备出现故障时会导致整个系统的语音识别功能失效。并且,由于直接传输原始语音数据对网络要求很高,数据传输的时延大,其实际的识别效果欠佳。
中国专利(CN111415658A)公开了一种去中心化语音控制多设备系统及其控制方法。在该方案中,设备首先识别出语音中的唤醒词,然后将识别出的唤醒词向系统内所有设备发送,并同时接收系统内其他设备发送的唤醒词。设备对所有的唤醒词进行筛选,筛选出与本设备匹配的唤醒词。在该方案中,如果设备接收到的语音中包含自身不支持的唤醒词(即语音指令),则可能导致语音控制失败。
中国专利(CN110136708A)公开了一种基于蓝牙mesh的分布式语音控制系统及控制方法,该控制系统包括蓝牙Mesh网络、语音控制器、蓝牙节点设备;语音控制器包括语音采集,语音降噪,语音识别,蓝牙模块,及可选的wifi模块。语音控制器之间通过蓝牙互相通信并实时保持数据同步,任一语音控制器都可控制网络内蓝牙节点设备;蓝牙节点设备通过蓝牙Mesh网络与语音控制器通信,根据接收Mesh数据或其自身的按键事件进行响应操作。在该方案中,每一语音控制器采集语音,进行语音降噪和回音消除,然后进行语音本地或者在线识别,语义理解解析出要控制的信息,封装成Mesh数据,通过蓝牙模块发送至Mesh网络中。如果语音控制器不支持当前的控制指令,则可能会导致设备无法识别自己不支持的语音指令,最终导致语音控制失败。
综上,现有技术中需要一种改进的分布式语音处理方案,以解决现有技术中存在的上述问题。应理解,上述所列举的技术问题仅作为示例而非对本发明的限制,本发明并不限于同时解决上述所有技术问题的技术方案。本发明的技术方案可以实施为解决上述或其他技术问题中的一个或多个。
发明内容
为克服现有技术存在的缺陷,本发明公开了一种分布式语音处理系统及其处理方法。
在本发明的一方面,提供一种分布式语音处理系统,包括多个节点设备,所述多个节点设备组成网络,其中每个节点设备包括处理器、存储器、通信模块以及声音处理模块,且所述多个节点设备中的至少一个节点设备包括声音采集模块;其中,
所述声音采集模块配置为采集音频信号;
所述声音处理模块配置为对所述音频信号进行预处理以得到第一声音预处理结果;
所述通信模块配置为将所述声音预处理结果发送到所述网络中的一个或多个节点设备;
所述通信模块还配置为从所述网络接收来自至少一个其他节点设备的一个或多个第二声音预处理结果;及
所述声音处理模块还配置为基于所述第一声音预处理结果和/或所述一个或多个第二声音预处理结果执行语音识别以得到第一语音识别结果。
优选地,所述通信模块还配置为将所述第一语音识别结果发送到所述网络中的一个或多个节点设备;
优选地,所述通信模块还配置为从所述网络接收来自至少一个其他节点设备的一个或多个第二语音识别结果;及
优选地,所述声音处理模块还配置为基于所述第一语音识别结果和所述一个或多个第二语音识别结果执行语音识别以得到最终语音识别结果。
在本发明的另一方面,提供一种分布式语音处理系统的处理方法,由网络中的节点设备执行,包括:
若所述节点设备包括声音采集模块,则执行下述步骤:采集音频信号;对所述音频信号进行预处理以得到第一声音预处理结果;以及将所述声音预处理结果发送到所述Mesh网络中的一个或多个节点设备;
从所述Mesh网络接收来自至少一个其他节点设备的一个或多个第二声音预处理结果;及
基于所述第一声音预处理结果和/或所述一个或多个第二声音预处理结果执行语音识别。
优选地,所述分布式语音处理系统的处理方法还包括将所述第一语音识别结果发送到所述网络中的一个或多个节点设备;
从所述网络接收来自至少一个其他节点设备的一个或多个第二语音识别结果;及
基于所述第一语音识别结果和所述一个或多个第二语音识别结果执行语音识别以得到最终语音识别结果。
本申请提供的方案可以在不接入互联网的情况下,扩展识别距离,提高人员移动情况下的识别率,轻松实现跨房间语音控制。同时,还能更近一步让语音识别更贴近用户习惯,更适应生活使用场景。
此外,本发明通过网络中的节点设备进行分布式地语音识别,可以实现超远距离或跨多个房间的语音识别控制。本发明的技术方案使得网络中的每个节点设备都参与到语音识别的过程中,一方面,实现了去中心化的设计,从而减少因关键中心节点故障导致的识别失败,并且该设计可以实现网络中的设备并发式地进行语音识别,可以提高语音识别的效率;另一方面,在识别过程中传输的信息是声音预处理信息,即非原始音频数据,因此对网络的带宽要求不高,提高了语音识别的稳定性。通过传输非原始音频数据,可以产生两个优点:首先,相对于直接传输原始数据的语音识别方法,本发明中的方案所需传输的数据量下降;其次,相比于直接传输识别结果的语音识别方法,本发明中的方案传输的是声音预处理结果,可以避免因为不支持指令而导致的识别失败,提高了语音识别的稳定性和鲁棒性。
附图说明
在下文中,将基于实施例参考附图进一步解释本申请。
图1示意性地示出根据本发明的分布式语音处理系统的一个实施例的框图;
图2示意性地示出根据本发明的分布式语音处理系统的另一实施例的框图;
图3示意性地示出根据本发明的分布式语音处理系统的一个实施例的节点设备的框图;
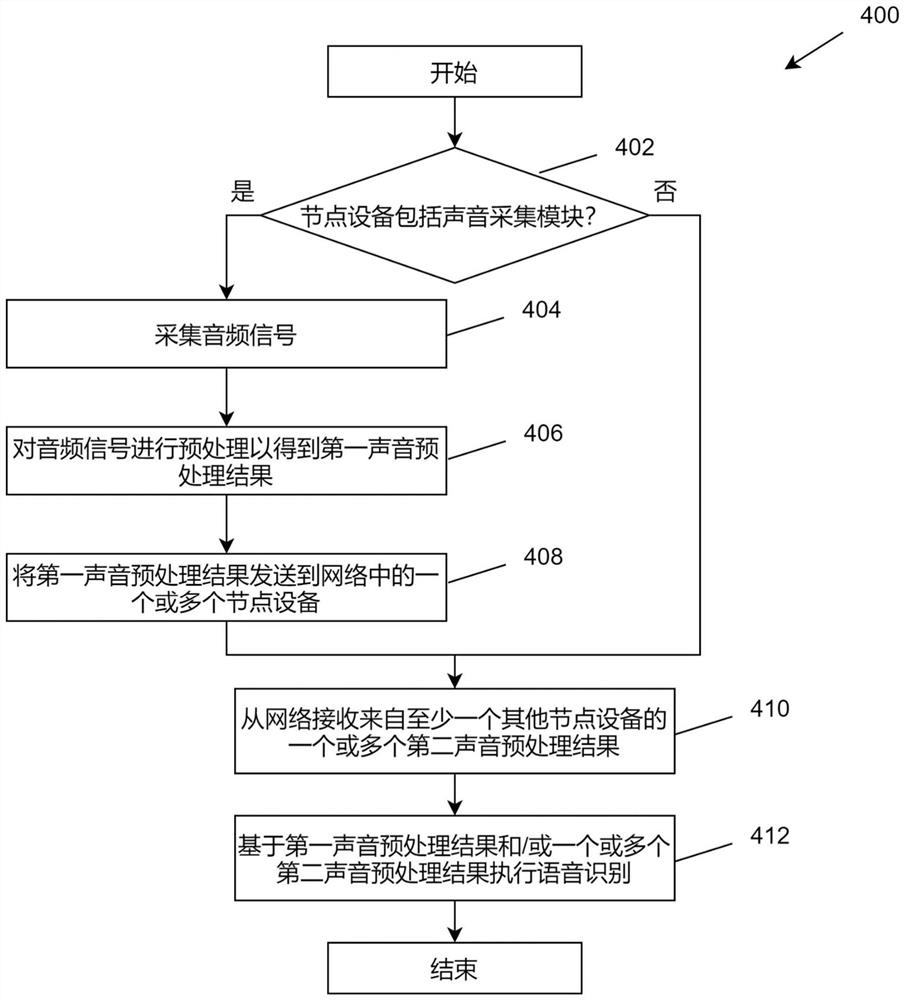
图4示意性地示出根据本发明的分布式语音处理方法的一个实施例的流程图;
图5示意性地示出根据本发明的分布式语音处理方法的另一实施例的流程图;
图6示意性地示出根据本发明的分布式语音处理方法的一个具体实施例的流程图;以及
图7示意性地示出根据本发明的分布式语音处理方法的另一具体实施例的流程图。
具体实施方式
以下将结合附图和具体的实施方式,对本申请的分布式语音识别处理系统及其处理方法进行详细说明。应理解,附图所示以及下文所述的实施例仅仅是说明性的,而不作为对本申请的限制。此外应理解,在本公开中,例如“第一”、“第二”、“第三”等序数词,除非明确指明或由技术上下文确定,仅用于指示技术方案中的不同或相同元素,而不意味着对这些元素的顺序或重要性的任何限制。
图1示出了根据本发明的分布式语音处理系统100的一个实施例的框图,该系统包括网络110中的多个节点设备102、104、106以及112、114和116。应理解,网络100可以例如是家庭和/或办公室使用的有线、无线和/或有线无线混合网络,包括但不限于在智能家居场景中通常所采用的无线网络。各个设备之间组成网络110,可以采用有线或者无线的方式进行通信。其中,有线的方式可以采用网线或者电力线载波等通信方式,无线的方式可以采用Wi-Fi,BLE,Zigbee等通信方式,实现各个设备之间的组网通信。
在一个具体实施例中,各个节点设备均具有连接其他节点设备的能力。各个节点设备之间可以进行自组网,构成自组织网络或者群组网络。各个设备之间还可以组成Mesh网络,可以实现Mesh网络中的任何设备节点都可同时作为路由器,即网络中的每个节点都能发送和接收信号,每个节点都能与一个或多个对等节点进行直接通信。
图2示意性地示出根据本发明的分布式语音处理系统200的另一实施例的框图,其中部分节点设备形成群组,从而本发明的系统也可以按广播或多播方式向群组发送消息。应理解,节点设备可以处于一个或多个群组中,且群组可以是动态的、可由用户自定义的,而不必要求群组之间的节点设备必须具有固定的硬件或通信连接关系。
在图1和图2所示的系统中,用户与节点设备间可能具有不同距离。例如用户108处于设备B和设备C之间,且处在设备B和设备C的拾音距离之内,但是用户108离设备A和其他设备较远,无法通过设备A和其他设备直接接收用户108发出的语音信号。
图3示意性地示出根据本发明的分布式语音处理系统的一个实施例的节点设备300的框图。如图3所示,每个节点设备300可以包括处理器302、存储器304、通信模块306以及声音处理模块312。多个节点设备中的至少一个节点设备包括声音采集模块308。可选地,节点设备300还可以包括输出模块312,其中处理器302可以提供μs级精准的时钟;通信模块306可以采用有线(比如,网线/电力线载波等)或者无线(比如,Wi-Fi/BLE/Zigbee等)的任何方式,用于与其他设备进行组网通信;存储器304可以记录组网信息和识别模型参数;输出模块312例如可以是扬声器、开关量装置等;声音采集模块308例如可以是单个麦克风、多个麦克风,或者是麦克风阵列。
声音采集模块308可以配置为采集音频信号。声音处理模块310可以配置为对音频信号进行预处理以得到本地产生的声音预处理结果。通信模块306可以配置为将本地产生的声音预处理结果发送到网络110中的一个或多个节点设备。通信模块306还可以配置为从网络110接收来自至少一个其他节点设备的一个或多个声音预处理结果。应理解,在本申请的上下文中,本地产生的声音预处理结果可以称为“第一声音预处理结果”,通过网络从其他节点设备接收的声音预处理结果可以称为“第二声音预处理结果”。声音处理模块310还可以配置为基于本地产生的声音预处理结果和/或一个或多个通过网络110接收的声音预处理结果执行语音识别。以此方式,节点设备300可以得到本地产生的语音识别结果。
节点设备的声音处理模块执行的语音识别可以包括但不限于唤醒词检测、关键词识别、连续语音识别等。作为非限制性示例,节点设备的声音处理模块执行语音识别得到的语音识别结果可以包括设备标识,识别结果,识别结果的有效时间,识别开始时间,声音质量。第一语音识别结果还可以包括指令信息和设备标识,以指示目标设备进行相应的操作。
在一个或多个实施例中,本发明的分布式语音识别方案一方面可以利用本地产生和来自网络的声音预处理结果,另一方面还可以利用本地产生和来自网络的语音识别结果。
在本发明的一个实施例中,本发明的节点设备可以对不同来源的语音识别结果进行仲裁。作为非限制性示例,通信模块306还可以配置为将本地产生的语音识别结果发送到网络中的一个或多个节点设备。通信模块306还配置为从网络接收来自至少一个其他节点设备的一个或多个语音识别结果。应理解,在本申请的上下文中,本地产生的语音识别结果可以称为“第一语音识别结果”,通过网络从其他节点设备接收的语音识别结果可以称为“第二语音识别结果”。声音处理模块310还配置为基于第一语音识别结果和一个或多个第二语音识别结果执行语音识别以得到最终语音识别结果。此外,在一个具体实施例中,声音处理模块310还配置为对第一语音识别结果和一个或多个第二语音识别结果执行加权处理以得到最终语音识别结果。
例如,节点设备的声音处理模块可以配置为基于第一语音识别结果和一个或多个第二语音识别结果的声音质量分配权重,声音质量越高则分配的权重越大。又如,节点设备的声音处理模块可以配置为基于第一语音识别结果和一个或多个第二语音识别结果的来源设备分配权重,如果来源设备为本节点设备,则分配的权重越大。
在本发明的上下文中,声音预处理结果是从原始语音到语音识别结果的识别过程中产生的中间结果。在一个具体实施例中,第一声音预处理结果和一个或多个第二声音预处理结果的每个包括声音特征值、声音质量及声音时间信息。在一个具体实施例中,节点设备的通信模块306从网络接收来自至少一个其他节点设备的一个或多个第二声音预处理结果,其中第二声音预处理结果包括声音特征值、声音质量及声音时间信息,还可以包括音频信号的递增序号。其中,预处理结果中的声音特征值为音频信号的MFCC特征值或PLP特征值。声音质量可以包括音频信号的信噪比和幅度。声音时间信息可以包括音频信号的开始时间和结束时间。声音时间信息可以包括音频信号的开始时间和持续时间。本领域技术人员应理解,本发明的实施不限于此。相反,本领域技术人员可以基于现有以及将来开发出的语音识别和处理技术,可以采用任何合适的声音预处理结果以实现本发明的方案。
本领域技术人员应理解,适用于本发明的预处理技术可以包括但不限于信号分帧、预加重、快速傅里叶变换(Fast Fourier Transform,FFT)等预处理。预处理方法可以根据音频信号获得音频参数、生成频域信号或进行梅尔频率倒谱特征(Mel-FrequencyCepstral Coefficients,MFCC)算法或感知线性预测(Perceptual Linear Predictive,PLP)算法提取,用于表征语音信息的内容。
在一个具体实施例中,节点设备的声音处理模块310还配置为对于第一声音预处理结果和一个或多个第二声音预处理结果中的每个,判断其声音质量是否超过预定阈值,若否,则丢弃该语音预处理结果。
在一个具体实施例中,节点设备的声音处理模块310还配置为在第一声音预处理结果和一个或多个第二声音预处理结果中,选取一个或多个声音质量最高的声音预处理结果进行语音识别以得到第一语音识别结果。
作为示例而非限制,节点设备的声音处理模块执行语音识别得到的第一语音识别结果可以包括指令信息,其中,指令信息是具体数值,如011,该指令信息例如可由支持相应指令的节点设备所理解和执行。此外,节点设备的声音处理模块执行语音识别得到的第一语音识别结果可以包括指令信息,其中,不同的节点设备支持不同范围的指令信息。
此外,节点设备的声音处理模块还可以配置为在第一声音预处理结果和一个或多个第二声音预处理结果中,选取一个或多个声音质量最高的声音预处理结果进行语音识别以得到第一语音识别结果。
在一个实施例中,节点设备的声音处理模块可以判断第一声音预处理结果的声音质量是否超过预定阈值,若超过,则选择第一声音预处理结果进行语音识别以得到第一语音识别结果。
作为示例实施例,节点设备的通信模块可以通过单播、多播和/或广播的方式将第一语音识别结果发送到网络中的一个或多个节点设备。
在一个实施例中,对于第一语音识别结果中的设备标识与本节点设备的设备标识不一致的第一语音识别结果,通过节点设备的通信模块将该第一语音识别结果发送到网络中的一个或多个节点设备。相反,对于第一语音识别结果中的设备标识与本节点设备的设备标识一致的第一语音识别结果,则不将该第一语音识别结果发送到网络中的一个或多个节点设备。
在一个实施例中,节点设备的声音处理模块可以对得到的最终语音识别结果进行时间有效性判断,如果超过识别结果的有效时间,则不执行识别结果所对应的相应操作。此外,节点设备的声音处理模块可以对于得到的最终语音识别结果判断设备标识,如果设备标识为本节点设备,则执行识别结果所对应的相应操作。
作为非限制性示例,节点设备的声音处理模块可以对于得到的最终语音识别结果判断设备标识,如果设备标识为本节点设备,则输出反馈信息并通过通信模块发送到网络中的其他一个或多个节点设备。
此外,节点设备的声音处理模块可以对于得到的最终语音识别结果判断设备标识,如果设备标识为本节点设备,则输出反馈信息,其中输出反馈信息至少包括识别时间、识别结果和递增序号的最大值。
图4示意性地示出根据本发明的分布式语音处理方法400的一个实施例的流程图。该分布式语音处理方法由网络中的节点设备执行。在步骤402,判断节点设备是否包括声音采集模块。如果是,则转到步骤404。如果否,则转到步骤410。在步骤404,采集音频信号。在步骤406,对音频信号进行预处理以得到第一声音预处理结果。在步骤408,将第一声音预处理结果发送到网络中的一个或多个节点设备。在步骤410,从网络接收来自至少一个其他节点设备的一个或多个第二声音预处理结果。在步骤412,基于第一声音预处理结果和/或一个或多个第二声音预处理结果执行语音识别。
在一个实施例中,可以对第一声音预处理结果和一个或多个第二声音预处理结果中的每个,判断其声音质量是否超过预定阈值,若否,则丢弃该语音预处理结果。
在另一个实施例中,可以在第一声音预处理结果和一个或多个第二声音预处理结果中选取一个或多个声音质量最高的声音预处理结果进行语音识别以得到第一语音识别结果。
作为非限制性示例,本发明的方法可以结合本地识别结果与来自网络的识别结果以得到最终语音识别结果。例如,节点设备可以将第一语音识别结果发送到网络中的一个或多个节点设备。节点设备可以从网络接收来自至少一个其他节点设备的一个或多个第二语音识别结果。节点设备可以基于第一语音识别结果和一个或多个第二语音识别结果执行语音识别以得到最终语音识别结果。
在另一个具体实施例中,可以对第一语音识别结果和一个或多个第二语音识别结果执行加权平均以得到最终语音识别结果。
在一个或多个实施例中,本发明的方案还利用本地产生的以及来自网络的声音预处理结果的片段进行拼接以获得。
在一个实施例中,提供了一种分布式语音处理系统,包括:多个节点设备,该多个节点设备组成网络,其中每个节点设备包括处理器、存储器、通信模块以及声音处理模块,且所述多个节点设备中的至少一个节点设备包括声音采集模块;其中声音采集模块配置为采集音频信号;声音处理模块配置为对音频信号进行预处理以得到第一声音预处理结果;其中,通信模块还配置为从该网络接收来自至少一个其他节点设备的一个或多个第二声音预处理结果;该第一声音预处理结果和该一个或多个第二声音预处理结果中的每个包括一个或多个数据块;该一个或多个数据块中的每个数据块包括时间信息,该时间信息标识该声音处理模块完成该数据块预处理的时间;该一个或多个数据块中的每个数据块还包括递增序号,该递增序号依据数据块中的时间信息分配;该声音处理模块还配置为按照递增序号递增顺序拼接该第一声音预处理结果和/或一个或多个第二声音预处理结果的数据块,以得到完整的第三声音预处理结果;以及该声音处理模块还配置为对该第三声音预处理结果进行处理以得到最终的语音识别结果。
在一个实施例中,通信模块配置为将第一声音预处理结果发送到该网络中的一个或多个节点设备。
在一个实施例中,第一和/或第二声音预处理结果中的每个数据块配置为具有相同的时长。
在一个实施例中,递增序号是多个节点设备中的每个节点设备的声音处理模块对该音频信号进行预处理时为数据块分配的。
在一个实施例中,递增序号是多个节点设备中的每个节点设备的声音处理模块对从网络接收来自至少一个其他节点设备的第二声音预处理结果后,为第二声音预处理结果的数据块分配的。
在一个实施例中,声音处理模块配置为检测数据块的时间差,如果时间差在指定阈值以内,则分配相同的递增序号。
在一个实施例中,声音处理模块配置为从相同递增序号的数据块中选择声音质量最优的数据块进行拼接。
图5示意性地示出根据本发明的分布式语音处理方法500的另一实施例的流程图。该方法由网络中的节点设备执行。在步骤502,判断节点设备是包括声音采集模块。如果是,则转到步骤504。如果否,则转到步骤508。在步骤504,采集音频信号。在步骤506,对该音频信号进行预处理以得到第一声音预处理结果。在步骤508,从网络接收来自至少一个其他节点设备的一个或多个第二声音预处理结果,其中第一声音预处理结果和一个或多个第二声音预处理结果中的每个包括一个或多个数据块,其中一个或多个数据块中的每个数据块包括时间信息,该时间信息标识声音处理模块完成数据块预处理的时间,且其中一个或多个数据块中的每个数据块还包括递增序号,该递增序号依据数据块中的时间信息分配。在步骤510,按照递增序号递增顺序拼接第一声音预处理结果和/或一个或多个第二声音预处理结果的数据块,以得到完整的第三声音预处理结果。在步骤512,对第三声音预处理结果进行处理以得到最终的语音识别结果。
应理解,在本发明的上下文中,将第一声音预处理结果和/或一个或多个第二声音预处理结果的数据块拼接所得的声音预处理结果称为“第三声音预处理结果”。
在一个实施例中,该分布式语音处理方法还包括,将第一声音预处理结果发送到网络中的一个或多个节点设备。
在一个实施例中,第一声音预处理结果中的每个数据块配置为具有相同的时长。
在一个实施例中,递增序号是多个节点设备中的每个节点设备的声音处理模块对音频信号进行预处理时为数据块分配的,其中递增序号根据时间信息分配。
在一个实施例中,递增序号是多个节点设备中的每个节点设备的声音处理模块对从网络接收来自至少一个其他节点设备的第二声音预处理结果后,为第二声音预处理结果的数据块分配的,其中递增序号根据时间信息分配。
在一个实施例中,声音处理模块配置为检测数据块的时间差,如果时间差在阈值以内,则分配相同的递增序号。
在一个实施例中,声音处理模块配置为从相同递增序号的数据块中选择声音质量最优的数据块。
图6示意性地示出根据本发明的分布式语音处理方法600的一个具体实施例的流程图。在该实施例中,对节点设备进行自组网,建立群组,让每台组网的节点设备都进行语音识别,在群组内交换识别信息的方法,将原本由一个节点设备的语音识别系统改进为分布在多个节点设备上的语音识别系统,从而解决了语音识别、关键词识别和语音控制场景中,依赖单一控制中心,依赖网络服务器,不能跨区域,隐私信息不安全等问题。
在步骤604,节点设备上电的时候,发现是否存在群组网络。如果不存在群组网络,则在步骤606创建群组网络。如果已经存在群组网络,则在步骤608加入该群组网络。节点设备在接入群组网络后,先在步骤610更新网络中其他设备功能点,以获知网络中其他设备所支持的功能点是否有修改,同时或之后,在步骤612将自身的设备功能点在群组网络中进行广播。应理解在本发明的上下文中,“功能点”用于告知其他接入群组的其他节点设备自己具有哪些方面的输入和输出功能。应理解,在本发明的上下文中,“群组网络”是指在其中支持广播和/或多播的节点设备所构成的网络,包括但不限于具有各种拓扑结构(例如Mesh拓扑结构)的Wi-Fi、BLE和ZigBee网络,并且可以是有线、无线或混合网络。
在步骤614,节点设备通过分布式识别获取识别结果,并在步骤616判断该识别结果的设备标识是否为本设备。如果设备标识不是本设备,则在步骤622发送识别信息。作为非限制性示例,识别信息可以包括识别设备标识、识别时间、识别结果、识别结果的可信度。如果设备标识是本设备,则在步骤618执行输出,并随后在步骤620将执行结果信息发送到网络中的其他节点设备。作为非限制性示例,执行结果信息可以包括设备标识、识别时间、识别结果,执行结果等。
图7示意性地示出根据本发明的分布式语音处理方法700的另一具体实施例的流程图。如图7所示,该实施例中的分布式语音处理方法包括三个输入和一个输出,三个输入分别是:在步骤702通过本地麦克风采集的声音,在步骤708从网络收集的声音预处理信息,以及在步骤714从网络收集的语音识别信息;一个输出是在步骤720输出的语音识别结果。
在该实施例中,分布式语音处理方法700分为三个阶段:预处理阶段、分析决策阶段,以及识别仲裁阶段。
在预处理阶段,本地麦克风采集的声音会先经过步骤704的声音预处理,获得预处理信息,然后在步骤706将预处理信息发送到群组网络。预处理信息例如包含有所采集声音的可用于识别模型辨识的特征信息。预处理信息例如还包含有所采集声音的信噪比和幅度等可用于评估声音质量的信息。预处理信息例如还包含有该信息的递增序号。作为示例而非限制,预处理信息还可以包含开始时间信息和结束时间信息。
在步骤710的分析决策阶段,对网络收集的声音预处理信息和本地获取到的声音预处理信息的声音质量进行排序,分析筛选出最优质的预处理信息送入后续的语音识别步骤712。在步骤712,执行语音识别以输出本地识别信息。本地或者网络识别信息例如可以包括但不限于识别的结果、语音识别的设备标识、识别结果的有效时间、识别开始时间和声音质量中的译者或多者。
在识别仲裁阶段,先针对在步骤714从网络收集到的识别信息在步骤716进行分析判断,根据识别信息的时效去掉过期的信息。然后与步骤712的本地语音识别的输出一起在步骤718进行识别仲裁。步骤718的识别仲裁根据网络语音识别结果和本地语音识别结果所携带的声音质量进行排序,以选取较佳的语音识别结果来产生最终的语音识别结果。例如,可以选取指定数量的几个声音质量较稿高的语音识别结果进行加权以获取最后的识别结果。
下面通过场景示例,进一步说明本发明的原理。在第一个场景中,参考图2所示,其中设备A、设备B、设备C依次上电。设备A首先上电后,发现不存在群组网络,因此创建群组网络。设备B和设备C上电后,发现群组网络已存在,则加入该群组网络。设备B和设备C在接入群组网络后,先更新网络中其他设备的功能点(即设备A)是否有修改,同时将本设备(即设备B和设备C)的功能点在群组里面进行广播,告知其他接入群组的其他节点设备自己具有的输入和输出功能。
用户处于设备B和设备C之间并发出语音信号。设备B和设备C采集到用户发出的音频信号,设备A因为与用户的的距离较远,超出设备A的声音采集模块的拾音距离,因此不能采集到用户发出的音频信号。
设备B和设备C对接收到的音频信号进行预处理,所获得的预处理结果至少包含所采集音频信号的可应用于语音识别模型的声音特征信息。预处理结果还包含所采集声音的信噪比和幅度等可用于评估声音质量的信息。预处理结果还包含有该音频信号的递增序号。以设备B为例,其发送的预处理数据包括N块数据,N块数据均带有递增的序号预处理结果还包含开始时间信息和结束时间信息,开始时间信息用于区别不同的声音信息。
设备B和设备C将采集到的语音进行预处理,获得相关的预处理信息发送到网络中。设备A的通信模块还从网络中接收分别来自设备B和设备C的声音预处理结果。设备B的通信模块从网络中接收来自设备C的声音预处理结果。设备C的通信模块从网络中接收来自设备B的声音预处理结果。
设备B基于自身的声音采集模块和声音预处理模块所获得的第一声音预处理结果,其信号质量已超过预定阈值。但设备B通过网络接收到的从设备C处获得的第二声音预处理结果中的采集的音频信号质量更好。设备B根据第一和第二声音预处理结果中的声音质量,选择声音质量最高的声音预处理结果(即,此处为设备C的第二声音预处理结果)进行后续的语音识别。
在图2所示的场景中,例如另一情形下,设备B基于自身的声音采集模块和声音预处理模块所获得的第一声音预处理结果,其信号质量已超过预定阈值。即使从设备C处获得的第二声音预处理结果中的采集的音频信号质量更好,设备B依然会使用自身的声音采集模块和声音预处理模块获得的预处理信号进行后续的语音识别。
在图2所示的场景中,例如另一情形下,假设设备A是电视,设备B是空调,设备C是台灯。设备A、B、C可以支持一部分共同的指令信息。例如,这三个设备共同支持指令数值范围为000-099的通用型指令信息,如唤醒指令“Hello A”。此外,这三个设备也支持不同类型的指令。例如设备A支持指令信息“提高电视音量(111)”,而设备B和设备C则不支持该指令。
在图2所示的场景中,例如另一情形下,设备A因为距离用户超过拾音距离,没有通过设备A的声音采集模块采集到音频信号。但是设备A通过网络接收到来自设备B和设备C的第二声音预处理结果。设备A根据第二声音预处理结果中的声音质量排序,选择声音质量最高的第二声音预处理结果进行后续的语音识别。
在图2所示的场景中,例如一种情形下,设备B进行语音识别获得第一语音识别结果为“Hello A”,判别该第一语音识别结果中的设备标识为设备A,因此将该第一语音识别结果转发至网络中的其他设备(即设备A和设备C)。
在图2所示的场景中,例如另一种情形下,设备A进行语音识别获得第一语音识别结果为“Hello A”,判别该第一语音识别结果中的设备标识为设备A,因此不再将该第一语音识别结果转发至网络中的其他设备。
在图2所示的场景中,例如,设备A基于自身的声音处理模块获得第一语音识别结果(“Hello A”)。设备A通过网络从设备B处接收到第二语音识别结果(“Hello C”)。设备A通过网络从设备C处接收到另一个第二语音识别结果(“Hello A”)。对于这三个语音识别结果执行加权处理,其中权重的分配考虑两个因素,即识别结果中的声音质量和识别结果的来源设备。声音质量越高,对应的语音识别结果分配的权重则越大。识别结果的来源设备为本设备,则分配的权重越大。例如本示例中的设备A,根据声音质量,对从设备B和设备C接收的第二语音识别结果分别赋予不同的权重值(B:0.6,C:0.4),对来自设备A本身的第一语音识别结果赋予更高的权重值(A:0.8)。因此,对于这三个语音识别结果最终的加权结果为“Hello A”:1.2,“Hello C”:0.6。并从而得到最终语音识别结果为“Hello A”。
在图2所示的场景中,例如,设备A基于最终语音识别结果(“Hello A”),判断该语音识别结果的时间有效性。如果发现仍在有效时间范围内,则进一步判断设备标识是否为本设备,发现该语音识别结果中的设备标识为“A”,即本设备,因此执行相应于指令信息的操作。同时,设备A向网络中的其他设备(即设备B和设备C)发送反馈信息。反馈信息至少包括识别时间、识别结果和递增序号的最大值。设备B和设备C收到反馈信息,获知本次识别结果已经执行完成,因此设备B和设备C分别停止本设备的语音识别工作以及发送工作。
如图2所示,当用户在设备B和设备C之间发出音频信号“Hello A”,设备B和设备C将通过各自的声音采集模块采集到该用户的音频信号。并且,设备B和设备C通过各自的声音处理模块进行预处理以得到声音预处理结果。因其与用户的距离超过声音采集模块的拾音距离,设备A和网络中的其他设备无法通过设备本身的声音采集模块采集到声音。其中,声音预处理结果包含声音特征值,声音质量信息,及声音时间信息。其中,声音特征值是音频信号的MFCC特征值或PLP特征值,即通过MFCC算法获得的声音特征值,用于表征语音信息的内容。声音质量信息包括音频信号的信噪比和幅度。声音时间信息包括音频信号的开始时间和结束时间,或音频信号的开始时间和持续时间。声音预处理结果还包含递增序号。以设备B为例,其发送的第一声音预处理数据可以包括N块数据,其中每块数据均带有递增的序号。声音时间信息可以包括音频信号的开始时间信息和/或结束时间信息,以区别不同的声音信息。
如图2所示,设备B和设备C将获得的声音预处理结果发送到网络中的所有设备。设备A通过网络分别收到设备B和设备C发出的声音预处理结果。设备B通过网络收到设备C发出的声音预处理结果。设备C通过网络收到设备B发出的声音预处理结果。设备A对从网络接收到的设备B发出的声音预处理信息和设备C发出的声音预处理信息进行优先级排序,以选择进行后续语音识别的声音预处理结果。设备B对本地获得的声音预处理信息以及从网络接收到的从设备C发出的声音预处理信息进行优先级排序,以选择进行后续语音识别的声音预处理结果。设备C对本地获得的声音预处理信息以及从网络接收到的从设备B发出的声音预处理信息进行优先级排序,以选择进行后续语音识别的声音预处理结果。
在另一实施例中,本发明的方案可以应用于连续语音识别场景。在该场景中,同样参考图2,假设用户在发出语音指令“打开厨房灯”的同时从设备B走到设备C。在本实施例中,设备A为厨房灯,设备B采集到的语音是“打开厨”,设备C采集到的语音是“房灯”。
设备B、C对语音信息进行预处理,B得到的预处理信息“打开厨”对应的特征信息以及前面所述的各项预处理信息;设备C得到的预处理信息“房灯”对应的特征信息以及前面所述的各项预处理信息。并B,C均向群组group1发送各自的预处理信息。
如上文所述,预处理数据可以包括N个块,N块数据均带有递增序号,每块数据时长例如可以为30ms,每块数据均分配有递增序号。递增序号与设备完成预处理的时间点有关。一般认为,若用户在室内发出语音指令,网络内的各个设备(A,B,C)完成预处理的时间点是接近的)。对于不同设备而言,相同/相近时间点(实际可能会有10ms左右的时间差)完成预处理的数据块的序列号相同。
在实际应用中,设备处理完每块数据后都会向群组内发送,设备收到各个数据块后会从相同序列号的数据块中选择最优的数据块(方法类似预处理排序),并将不同序列号的数据块拼接后形成完整的预处理结果。
如语音指令“Hello A”在语音预处理后可以分为10块数据(序列号000-009),设备A会从收到的多个序列号为000的数据块中选择出一个数据块;从收到的多个序列号为000的数据块中选择出一个数据块;……;并按序列号顺序对多个数据块进行拼接已形成最终的预处理结果(第一预处理结果)。
这样就可以解决人员移动的问题,若用户从发出语音命令的过程中从设备A附近移动到设备B附近,每个设备只能采集到部分语音信息,例如,设备A可以会采集到序列号为000-006的数据块,设备B可以采集到序列号为003-009的数据块,通过上述方法,设备A、B均可以收到到000-009的数据块,从而可以完成语音数据(预处理结果)的拼接。
应理解,以上分布式语音识别系统和方法仅作为示例提供,而非对本发明的限制。本领域技术人员应理解,可以将本发明的原理应用于不同于以上所述分布式语音识别系统和方法而不脱离本发明的范围。虽然出于本公开的目的已经描述了本申请各方面的各种实施例,但是不应理解为将本公开的教导限制于这些实施例。在一个具体实施例中公开的特征并不限于该实施例,而是可以和不同实施例中公开的特征进行组合。例如,在一个实施例中描述的根据本申请的方法的一个或多个特征和/或操作,亦可单独地、组合地或整体地应用在另一实施例中。关于系统/设备实施例的描述同样适用于方法实施例,反之亦然。本领域技术人员应理解,还存在可能的更多可选实施方式和变型,可以对上述系统进行各种改变和修改,而不脱离由本申请权利要求所限定的范围。
- 分布式语音处理系统及方法
- 分布式呼叫中心多地接入语音数据的处理系统及方法