基于Strahler分级的流域及河流编码方法及装置
文献发布时间:2023-06-19 10:35:20
技术领域
本发明涉及编码技术领域,尤其涉及一种基于Strahler分级的流域及河流编码方法以及装置。
背景技术
数字流域是水文科学与应用研究、水文信息管理、地理、环境、生态等领域科学研究的重要基础数据。基于数字高程模型和GIS水文分析技术生成的数字流域数据集一般包含河网、流域边界、流向等。其中,河网和流向定义了水循环及伴随水循环的其它物质或能量循环的拓扑关系(如源与汇、上下游等方向性关系),流域则定义了基于自然水流过程的计算或管理的单元或范围。对提取的河网及流域进行精巧的编码,以承载拓扑结构信息从而更好地服务于水文信息的编制、存储、检索和跨行业交流与应用,是数字流域技术的一个关键问题。
SL 249-2012公布了中国河流代码标准,该标准对全国集水面积大于500平方公里或长度大于30公里、有大型、重要中型水库和水闸所在的河流进行了系统性、实用性、唯一性编码。该标准主要适用于水利部门河流信息的编制、存储、检索等领域的管理与应用,其编码原则中强调了对防汛抗旱等工作的支持作用,其编码格式为数字与字母混编,长度为8位。该编码标准已应用于中国水利部门,为防汛抗旱、水利部门的信息化管理提供了重要支撑。该标准未对占全国河流总数约50%的中、小河流进行编码,主要服务对象不包含公众,只能有限支撑水文建模、地理、环境、生态等跨行业应用。
专利文献CN 108804804 A公开了一种基于数字河网的大数量子流域快速编码方法,该发明采用全数字的编码格式,能够反映河流的级别、拓扑关系,有较好的代码容量、可扩展性及易读性。该方法可用于单个独立流域及其内含子流域编码,方便于独立流域内的子流域间联系对比。例如,级数较小流域的集水面积大于级数较大的流域,同一级数的流域集水面积基本相当;小流域与大流域之间的汇流关系等等。但一个区域可能包含多个独立流域,如中国境内有长江、黄河、珠江等诸多直接入海的独立流域。由于CN 108804804 A的编码总是从1开始,其应用于长江流域编码后,黄河等其它流域无码可用。另外,不同独立流域之间的联系对比不方便,如同为1级的两个流域的水文特征可能因为集水面积相差百倍而有显著区别,此时将面积较小的1级独立流域与面积较大独立流域的3级或4级子流域进行比较可能更合理。
上述两种编码方法在我国河流、流域编码方面均有很好的应用或参考价值,基本上满足编码技术要求的科学性、唯一性、完整性和可拓展性。但是,需要说明的是,标准SL249-2012所覆盖的河流有限,编码的适用针对性很强,跨行业应用和交流存在一定限制,而专利文献CN 108804804 A在编码过程中,注重了独立流域内的河流及子流域的联系对比(即纵向对比),但独立流域之间的河流及子流域的联系对比(即横向对比)则存在一定困难。
由此,现有的编码的方法导致的编码覆盖的河流有限、可拓展性差、不能清楚的表征河流拓扑的问题,尚未得到解决。
发明内容
本发明提供了一种基于Strahler分级的流域及河流编码方法以及装置,以解决现有的编码方法覆盖的河流数据维度有限、可拓展性差、不能全面的表征河流拓扑的问题。
根据本发明的第一方面,提供了一种基于Strahler分级的流域及河流编码方法,所述方法包括:对获取到的DEM数据进行预处理,其中,所述预处理至少包括:内流区处理、黄河悬河处理和洼地处理;从预处理后的DEM数据中分析得到河网数据,其中,所述河网数据中至少包括多个流域以及多个河流;基于Strahler分级方法对所述多个河流进行分级;根据预设的编码策略,并通过所述多个河流的分级对所述多个流域以及所述多个河流进行编码。
进一步地,所述流域至少包括独立流域以及子流域。
进一步地,所述河网数据中包括多个栅格,其中,所述从预处理后的DEM数据中分析得到河网数据的步骤包括:通过D8算法对所述多个栅格进行处理,生成每个栅格的流向;计算生成所述每个栅格的集水面积;将满足预设集水面积阈值的栅格确定为河网栅格;获取所述河网栅格中的流域出口;统计流入所述流域出口的河网栅格;根据所述流入所述流域出口的河网栅格以及所述每个栅格的流向确定所述流域出口对应的集水范围;根据所述集水范围确定所述河流以及所述流域。
进一步地,所述基于Strahler分级方法对所述多个河流进行分级的步骤包括:将满足预设条件的所述河网栅格确定为河源栅格;根据所述每个栅格的流向获取河源栅格的至少一个下游栅格;统计流入所述下游栅格的个数;根据所述个数判断所述下游栅格所在河流的等级。
进一步地,所述根据预设的编码策略,并通过所述多个河流的分级对所述多个流域以及所述多个河流进行编码的步骤包括:计算得到多个所述独立流域的面积;根据多个所述独立流域的面积得到每个独立流域的面积排名;根据所述独立流域的面积排名以及所述独立流域包含的河流的最高分级生成所述每个独立流域的编码;根据所述独立流域的编码以及所述独立流域包含的所有的河流的分级生成所述独立流域包含的所有的河流的编码;根据所述独立流域包含的最高等级的河流的编码生成所述独立流域包含的子流域的编码。
根据本发明的第二方面,提供了一种基于Strahler分级的编码装置,所述装置包括:预处理单元,用于对获取到的DEM数据进行预处理,其中,所述预处理至少包括:内流区处理、黄河悬河处理和洼地处理;分析单元,用于从预处理后的DEM数据中分析得到河网数据,其中,所述河网数据中包括多个流域以及多个河流;分级单元,用于基于Strahler分级装置对所述多个河流进行分级;编码单元,用于根据预设的编码策略,并通过所述多个河流的分级对所述多个流域以及所述多个河流进行编码。
可选地,所述流域至少包括独立流域以及子流域。
可选地,所述河网数据中包括多个栅格,其中,所述分析单元包括:处理模块,用于通过D8算法对所述多个栅格进行处理,生成每个栅格的流向;计算生成所述每个栅格的集水面积;第一确定模块,用于将满足预设集水面积阈值的栅格确定为河网栅格;第一获取模块,用于获取所述河网栅格中的流域出口;第一统计模块,用于统计流入所述流域出口的河网栅格;第二确定模块,用于根据所述流入所述流域出口的河网栅格以及所述每个栅格的流向确定所述流域出口对应的集水范围;第三确定模块,用于根据所述集水范围确定所述河流以及所述流域。
可选地,所述分级单元包括:第四确定模块,用于将满足预设条件的所述河网栅格确定为河源栅格;第二获取模块,用于根据所述每个栅格的流向获取河源栅格的至少一个下游栅格;第二统计模块,用于统计流入所述下游栅格的个数;判断模块,用于根据所述个数判断所述下游栅格所在河流的等级。
可选地,所述编码单元包括:第二计算模块,用于计算得到多个所述独立流域的面积;得到模块,用于根据多个所述独立流域的面积得到每个独立流域的面积排名;第一生成模块,用于根据所述独立流域的面积排名以及所述独立流域包含的河流的最高分级生成所述每个独立流域的编码;第二生成模块,用于根据所述独立流域的编码以及所述独立流域包含的所有的河流的分级生成所述独立流域包含的所有的河流的编码;第三生成模块,用于根据所述独立流域包含的最高等级的河流的编码生成所述独立流域包含的子流域的编码。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。
图1是根据本发明实施例一的基于Strahler分级的流域及河流编码方法的示意图;
图2是根据本发明实施一的河流、流域提取与编码流程图;
图3是根据本发明实施一的河流、流域编码结构示意图;
图4是根据本发明实施一的子流域的河流编码示意图;
图5是根据本发明实施一的独立流域的流域编码示意图;以及
图6是根据本发明实施二的基于Strahler分级的编码装置的示意图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
实施例一
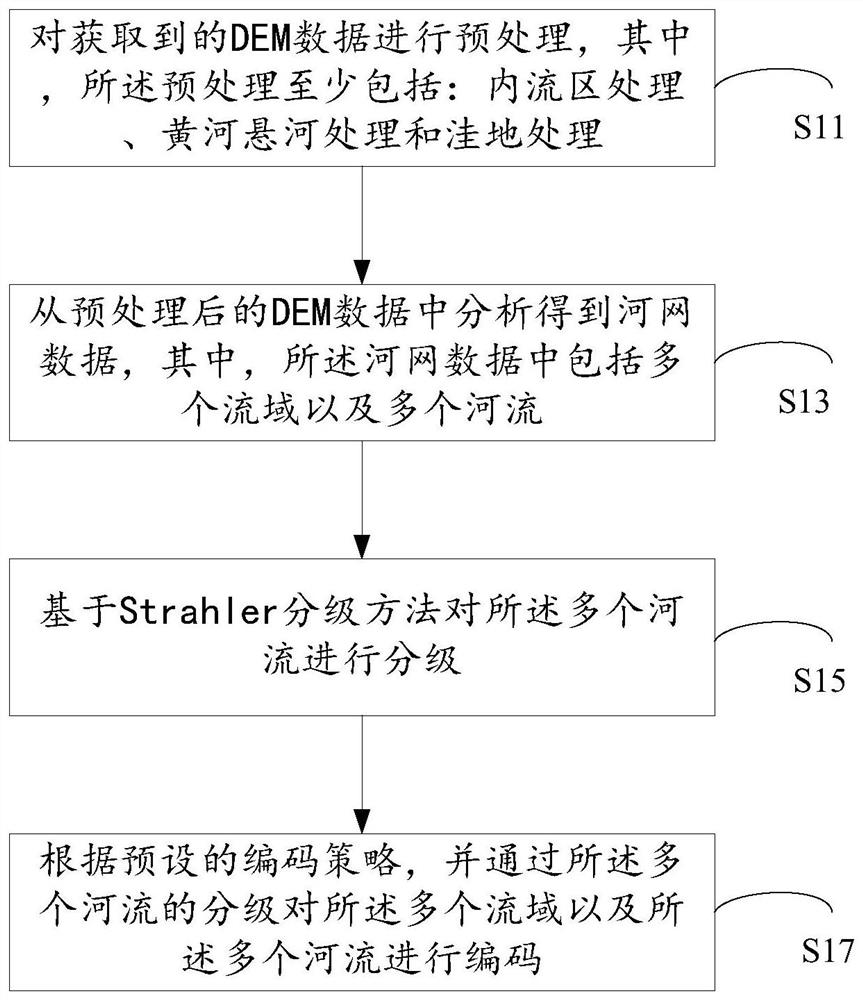
本方案提供了一种基于Strahler分级的流域及河流编码方法,本方案可以执行于服务器等计算机等设备,如图1所示,该方法可以包括:
步骤S11,对获取到的DEM数据进行预处理,其中,预处理至少包括:内流区处理、黄河悬河处理和洼地处理。
具体的,在本方案中,上述DEM数据可以为栅格格式(如ESRI ASCII等)的地形数据,优选的,本方案采用的是250m水平分辨率的SRTM DEM数据,然后对该数据进行一系列预处理操作不限于内流区处理、黄河悬河处理和洼地处理。本方案可以根据中国外流入海流域、内陆河内陆湖流域及黄河下游的地形数据进行预处理,生成对原始DEM改动量较小(约6%)的无洼地DEM派生数据,以保证水流路径的连续性和尽可能符合中国境内水流的实际情形。
在一种可选的实施例中,上述步骤S11对获取到的DEM数据进行预处理可以包括:
步骤S111,构建数字流域时,默认独立流域的出口均位于海岸线或陆湖边界上,在本方案中,独立流域是指最终排水出口落海岸线、内陆干或有水湖泊岸线上的流域,为保证能够准确提取内陆河,地形数据预处理时将内陆湖区域的DEM赋为空值。如长江、黄河、珠江等均为外流独立流域,塔里木河、青海湖为内流独立流域,而洞庭湖、鄱阳湖、太湖则均为长江流域的子流域,因为它们最终通过长江干流入海。
步骤S112:根据地形数据数字化黄河下游干流,手动抬高河流两侧河岸的海拔高度,以描述“人工堤坝”的约束作用,较合理地提取出黄河下游河段和流域边界。
步骤S113:在洼地处理过程中,当上游相邻栅格的原始高度大于洼地栅格的原始高度时,洼地处理前后保持二者高差不变,该洼地处理方法在保证水流路径连续的前提下,最大程度地保留原始DEM的高程信息,有利于更加合理地计算流向和提取数字河网,经过该填洼流程后,可以为需要地形数据的水文研究提供修改量小且无洼地的DEM。
步骤S13,从预处理后的DEM数据中分析得到河网数据,其中,河网数据中包括多个流域以及多个河流。
具体的,在本方案中,在对DEM数据进行预处理后,本方案从预处理之后的DEM数据中分析得到河网数据,基于上述河网数据提取河流,以及划分流域,可选的,上述流域可以包括独立流域及各独立流域内含的子流域,独立流域可以为最终排水出口落在中国的边境线或内陆湖泊上的集水区,子流域指各独立流域内部进一步细分的各个子集水区。
步骤S15,基于Strahler分级方法对多个河流进行分级。
具体的,在分析得到多个河流中,本方案可以基于Strahler分级方法对多个河流进行分级,上述Strahler分级的规则可以为如下:无支流汇入的河流(即河源)为1级河流;相同级别河流交汇时,交汇点下游河段级数增加一级,不同级别河流交汇时,交汇点下游河段级数保持为交汇河流中的最高等级。例如,两条1级河流交汇,交汇点下游为2级河流;两条2级河流交汇,交汇点下游为3级河流;1级河流与2级河流交汇,交汇点下游依然为2级河流,以此类推。
步骤S17,根据预设的编码策略,并通过多个河流的分级对多个流域以及多个河流进行编码。
具体的,在本方案中,可以预先定义一个编码规则,根据通过上述Strahler方法得到的河流的分级来对河流、流域(独立流域以及子流域)进行编码。上述的编码规则可以为:各流域的编码全部由数字组成,以追求代码简明性,例如,中国境内集水面积按从大到小排在1-999位的所有独立流域均有唯一编码;各独立流域的编码由4位数字构成,前3位为按中国境内集水面积从大到小的位次,取值001-999,第4位为各独立流域内含的最高Strahler河流级数,取值1-9。有编码的独立流域内含的所有子流域均有唯一编码,子流域的编码包含并拓展所属上级流域的编码,以表征流域的拓扑关系;支流、子流域的Strahler等级每下降1级,其编码增加两位,取值00-99。图3中描述了依据上述预设的编码策略得到的代码结构。编码第一节有4位码,前3位表示最高等级河流按集水面积位次(001-999),编码第4位表示最高等级河流Strahler级数(1-9)。编码第5位开始,独立流域内河流级数每减小一级,相应河流的编码位在其汇入的河流的编码基础上增加两位(依次从00,02,03,…,99中取值),该两位数码从00-99逐一递增,数值自下游向上游增加,实现对所有的河流进行编码。
需要说明的是,本方案通过上述方法,提出一种基于Strahler河流级数的中国流域编码方法,本方案可以通过编写整套C++程序来实现,采用统一的算法和地形数据(DEM),提取中国境内河流、划分流域并进行Strahler河流定级,实现对河流及流域的编码,为促进水利信息管理、水文科学研究和行业间水文信息共享与交流提供基础参考。由此,本方案解决了现有的编码方法现有的编码的方法导致的编码覆盖的河流有限、可拓展性差的技术问题。本方案根据自然水流汇集规律,基于传统的Strahler河流定级方法,假设自然条件下中国境内各个独立流域内及独立流域间同级流域的水文特征具有可比性,采用统一的标准和计算程序,自动提取并对中国境内的河流、流域进行编码,编码具有简明性、唯一性、代码容量大、可扩展性强、能反应河网、流域拓扑结构、支持独立流域内部及独立流域之间河流、流域的联系对比等特征,有利于促进水利信息管理、水文科学研究和行业间水文信息共享与交流。
可选的,本方案中的流域至少包括独立流域以及子流域,结合图2,本方案首先对地形数据(DEM)进行预处理,包括内流区处理、黄河悬河处理和洼地处理;然后,提取河网与划分流域,包括流向和集水面积计算、河流提取、流域划分等过程,接着,采用Strahler方法进行河流定级;接着,制定河流、流域编码规则;最后,对河流和流域进行编码。
可选的,河网数据中包括多个栅格,其中,步骤S13从预处理后的DEM数据中分析得到河网数据的步骤可以包括:
步骤S131,通过D8算法对多个栅格进行处理,生成每个栅格的流向。
步骤S132,计算生成每个栅格的集水面积。
步骤S133,将满足预设集水面积阈值的栅格确定为河网栅格。
步骤S134,获取河网栅格中的流域出口。
步骤S135,统计流入流域出口的河网栅格。
步骤S136,根据流入流域出口的河网栅格以及每个栅格的流向确定流域出口对应的集水范围。
步骤S137,根据集水范围确定河流以及流域。
具体的,在本方案中,首先利用D8算法进行流向计算,然后计算结果计算集水面积,本方案可以选择合理的集水面积阈值进行河流提取,集水面积阈值越大,提取的河网越稀疏,反之则越密集。本发明通过控制河溪表面积占流域集水面积比例确定来集水面积阈值,最后,根据流向,从流域出口出发,逆着水流方向标记流入该流域出口的栅格,通过迭代计算获得该流域出口对应的流域范围(即集水区),根据上述流域范围划分上述独立流域以及独立流域内的多个子流域。
在一种可选的实施例中,首先计算各栅格的八邻域(D8)流向,进一步计算各栅格的集水面积,然后通过设定超过集水面积阈值的栅格为河网栅格,反之为山坡栅格来提取河网。各个独立流域的集水面积阈值不同。选取办法为,首先估算各个独立流域的河流水面面积占总集水面积的百分比(我们采用的是遥感测量手段),然后设定多个阈值分别提取河网水系并计算相应河网面积百分占比,选取与前面的估算百分比最接近的阈值作为优选的河流提取集水面积阈值。最后根据流向结果,从流域出口出发,逆着水流方向标记流入该流域出口的栅格,通过迭代计算划定该流域出口对应的流域集水范围。为了便于后续计算及使用,对河网和流域边界ASCII文件进行矢量化。
可选的,步骤S15基于Strahler分级方法对多个河流进行分级的步骤可以包括:
步骤S151,将满足预设条件的河网栅格确定为河源栅格。
步骤S152,根据每个栅格的流向获取河源栅格的至少一个下游栅格。
步骤S153,统计流入下游栅格的个数。
步骤S154,根据个数判断下游栅格所在河流的等级。
在一种可选的实施例中,基于上述提取的栅格河网数据,可以采用Strahler方法及C++数据结构中的队列技术,进行河流定级,具体的,首先,根据流向和提取的河流找出所有的河源,将河源栅格的等级赋为1,加入1级河流队列。河源栅格满足两个条件:其一,属于河流栅格;其二,相邻栅格中没有流向该栅格的河流栅格。然后,根据流向从河源向下游移动一个栅格,统计流入当前栅格的相邻河流栅格个数,如果个数等于1,则当前栅格的河流等级与上游河流栅格相同,继续向下游移动;如果个数大于1,则表明当前栅格为河流交叉点,判断上游河流栅格的最高等级和个数,如果只有1个最高等级,则当前栅格的河流等级等于最高等级,如果有多个最高等级,则当前栅格的河流等级等于最高等级加1,保留当前栅格作为下一级河流的“河源”,加入2级河流队列中。最后,对1级河流队列中的所有河源重复上述过程,得到2级河流队列;对2级河流队列中的所有“河源”重复上述过程,得到3级河流队列,以此类推,直至下一级河流队列为空,定级结束。
例如,采用250米分辨率SRTM DEM数据,初步提取了中国境内约40万条河流,最高河流等级为9级,其中:1级河流约31万条,2级河流约6.7万条,3级河流约1.5万条,4级河流约3300条,5级河流约800条,6级河流约200条,7级河流约50条、8级河流10条以及9级河流2条。中国境内提取的河网总长约240万km。
可选的,步骤S17根据预设的编码策略,并通过多个河流的分级对多个流域以及多个河流进行编码的步骤可以包括:
步骤S171,计算得到多个独立流域的面积。
步骤S172,根据多个独立流域的面积得到每个独立流域的面积排名。
步骤S173,根据独立流域的面积排名以及独立流域包含的河流的最高分级生成每个独立流域的编码。
步骤S174,根据独立流域的编码以及独立流域包含的所有的河流的分级生成独立流域包含的所有的河流的编码。
步骤S175,根据独立流域包含的最高等级的河流的编码生成独立流域包含的子流域的编码。
具体的,在上述步骤S175中,对独立流域内含的子流域进行编码。本方案可以设定子流域的编码与其内部所含的最高等级河流的编码相同,干流局部集水区的编码为所对应的干流河流编码尾部添加“00”。流域内的集水区可以划分为子流域和干流局部集水区两大部分。子流域为次一级支流的全部集水范围,干流局部集水区则是子流域内最高等级河流的局部集水范围。
例如,8级独立珠江流域的集水面积由其内含的5个7级支流与珠江干流河段(8级)对应的局部集水区拼接构成,则5个7及支流所在的子流域编码为“0058”尾部添加“01”、02”、“03”、“04”、“05”,8级干流局部集水区的编码为“0058”尾部添加“00”。
根据定义的编码规则,中国境内各个独立流域的编码最短,均为4位;最高独立流域等级为9级(如长江、黄河);最长的流域编码为9级独立流域内含的1级支流,其编码长度为20位。对中国境内各个独立流域按面积降序进行编码,其中但不限于,“0019”,“0029”,“0038”,“0048”,“0058”分别指长江流域、黄河流域、松花江流域、塔里木河流域和珠江流域。本独立流域编码方式,可以根据集水面积大小及最高Strahler等级,比较独立流域的相对大小,从而既保证了同一流域内部河流、子流域的相对层级结构,又能够支撑跨独立流域的对比联系。例如,研究最大洪峰流量时,直接把淮河流域与长江流域对比,从体量上比较起来是困难的,但淮河流域和长江的洞庭湖、鄱阳湖、或太湖等子流域进行对比,从体量上讲相对较为合理。
在本方案的编码方式可以实现如下编码特点:
(1)编码包含了流域、河流的汇水拓扑结构信息。同一独立流域内,嵌套式的编码能够直观反映同一流域内部河流、子流域的汇水拓扑关系,便于建立河网索引关系,服务于水文建模及水文信息管理。例如,0019是中国境内最大的独立流域长江流域的代码,001902是9级长江流域的8级子流域鄱阳湖流域。
(2)编码包含了流域、河流的基于Strahler级数的层级结构信息。同一Strahler级数的流域或河流一般具有较好的水文学对比联系性。根据流域编码计算流域级数的数学公式是[流域级数]=[编码第4位数字]-[编码长度–4]/2,当流域编码的最末两位不为“00”时,该流域为[流域级数]级流域;当流域编码的最末两位为“00”时,该流域是[流域级数+1]级干流局部集水区。根据河流编码计算支流级数的数学公式是[河流级数]=[编码第4位数字]-[编码长度–4]/2。例如,9级长江流域的鄱阳湖子流域编码为001902,其Strahler级数为:[编码第4位数字9]-[编码长度6-4]/2=9–1=8级。又如,9级长江流域的某子流域编码为001900,其Strahler级数为:[编码第4位数字9]-[编码长度6-4]/2=9–1=8级,但其流域编码的最末两位为“00”,表明该流域是[流域级数8+1]=9级干流局部集水区。类似地005801则是8级珠江流域的7级子流域东江流域。
(3)同一独立流域内,子流域编码的长度越长,其内含最高等级河流越小,其集水面积一般也越小。例如,编码为“00590101”的流域和编码为“005901”的流域都是独立流域“0059”的子流域,且前者是后者进一步细分的子流域。
(4)不同独立流域间,也可以通过编码的简单转换计算辅助对比联系。例如,001902是9级长江流域的8级子流域鄱阳湖流域,005801则是8级珠江流域的7级子流域东江流域。同为8级,鄱阳湖流域从体量(流域集水面积、河流大小等)上讲,可能与整个珠江流域更具有可比性。根据河流或流域编码可简易直接比较体量,便于有关水文分析。
下面针对于上述步骤S171至步骤S175,介绍本方案的一种可选的实施例:
首先,本方案可以对独立流域进行编码。先确定中国境内某独立流域按面积从大到小的排序次序值(取值001-999);第二步确定独立流域内含的最高Strahler河流级数(取值1-9);第三步将独立流域的面积次序值作为前3位、对应的最高Strahler河流级数值作为第4位,构成该独立流域的4位流域编码。如珠江流域按中国境内所有独立流域集水面积降序排名第5,其所包含的最高河流Strahler级数为8级,因此,珠江流域的编码为0058。
然后,对独立流域内最高等级河流进行编码。设定独立流域内最高等级河流的编码与流域编码相同。如珠江流域的编码为0058,则珠江流域内含的8级河段其编码也为0058。本方案中,对独立流域内所有等级河流进行编码。从最高等级河流,自下游向上游追溯编码,在河流交叉口处,每遇河流级数减小一级,相应河流的编码在其汇入河流编码的基础上增加两位(依次从00,01,02,03,…,99中取值),实现对所有的河流进行编码。当支流跳N级(N≥1)汇入干流时,该支流编码在其汇入河流编码的基础上先增加(N-1)个“00”,最后两位从01-99中取值。
例如,珠江流域按中国境内集水面积排名第五,则其排序位次记为“005”;珠江流域内最高河流级数为8级,则整个珠江流域的编码为“0058”,相应地,珠江流域内最高等级河段(珠江8级干流,从珠江入海口上溯至8级河段的起始点)的编码也为0058。进一步依河流级数逐步降低,珠江的次一级(7级)支流东江的编码为“005801”,东江的支流新丰江(6级)的编码为“00580101”,新丰江的支流连平水(5级)的编码为“0058010101”,连平水的支流密溪河(4级)的编码为“005801010101”(如图3以及图4所示)。再例如,由下游向上游遇见的第一个汇入珠江7级干流东江(编码位005801)的4级支流河段,其编码长度应该增加3×2=6位,所跳跃河流级数为7-4=3,因此编码为“005801”先增加2次“00”,最后两位取值01,得该支流最终编码“005801000001”(参考图4)。图4示例了珠江的东江子流域内4级以上河流的编码。根据上述迭代步骤,对流域内构成河网的所有河流遍历,可完成全部的河流编码。
最后,对独立流域内含的子流域进行编码。在自然过程下,流域内的集水面积可以划分为子流域和干流局部集水区两大部分。子流域为次一级支流的全部集水范围,干流局部集水区则是子流域内最高等级河流的局部集水范围。例如,8级独立珠江流域的集水面积由其内含的5个7级支流与珠江干流河段(8级)对应的局部集水区拼接构成(如图5所示)。依据河流编码及前段干流、支流集水区关联关系,进一步对各独立流域内含的子流域及干流局部集水区进行编码。设定子流域的编码与其内部所含的最高等级河流的编码相同,干流局部集水区的编码为所对应的干流河流编码尾部添加“00”。
图5示例了珠江流域编码。例如,8级独立珠江流域的集水面积由其内含的5个7级支流与珠江干流河段(8级)对应的局部集水区拼接构成,则5个7及支流所在的子流域编码为“0058”尾部添加“01”、02”、“03”、“04”、“05”,8级干流局部集水区的编码为“0058”尾部添加“00”。其中,珠江的次一级(7级)子流域东江流域的编码为“005801”;东江的子流域新丰江流域(6级)的编码为“00580101”,新丰江的子流域连平水(5级)流域的编码为“0058010101”,连平水的子流域密溪河(4级)流域的编码为“005801010101”。
需要说明的是,依据本编码技术发明,对独立珠江流域的所有河流和流域进行了编码。下表1示例了在珠江流域的具体应用。表1示意了珠江流域的层级结构和内部汇水拓扑结构信息。珠江流域面积约45万km2,总河长约20万km,流域内最高河流等级为8级,4至7级子流域的数量依次分别为467、115、28和5个,4至7级子流域的平均集水面积依次分别为606,2264、10692和71739km2;珠江8级干流河段长度约490km,4至7级河流的平均长度依次分别为15、37、72和225km。表1还示意了珠江流域河流-流域编码体系。珠江流域内5个7级子流域的编码从下游至上游分别为“005801”,“005802”,“005803”,“005804”,“005805”;8级干流局部集水区的编码为“005800”;以编码为“005801”的7级子流域为例,流域内有2个6级子流域,流域编码分别为“00580101”,“00580102”,7级干流局部集水区的编码为“00580100”;以编码为“00580101”的6级子流域为例,流域内有2个5级子流域,流域编码分别为“0058010101”,“0058010102”,6级干流局部集水区的编码为“0058010100”。
表1珠江流域、河网编码等特征
由此类推,可采用上述编码技术对中国境内的所有河流和流域进行编码,初步编码如下表2所示。
表2中国境内代表流域、河网编码
综上,本方案公开一种基于Strahler河流级数的中国流域编码方法,其步骤包括:对地形数据(DEM)进行预处理,包括内流区处理、黄河悬河处理和洼地处理;提取河网与划分流域,包括流向和集水面积计算、河流提取、流域划分等过程;采用Strahler方法进行河流定级;制定河流、流域编码规则;对流域和河流进行编码。本方案中的河网、流域提取及编码方法均通过C++程序实现,完全独立于第三方软件。本方案通过提供一种可对中国境内绝大部分、不同大小的独立流域(总覆盖面积超过99%的国土面积)及河流进行标准统一、系统性的编码方案。解决了现有的编码方法现有的编码的方法导致的编码覆盖的河流有限、可拓展性差的技术问题。
实施例二
如图6所示,提供了一种基于Strahler分级的编码装置,该装置用于实施上述实施例一中的方法,也可以用于布置在一个计算机设备中,该装置包括:预处理单元60,用于对获取到的DEM数据进行预处理,其中,预处理至少包括:内流区处理、黄河悬河处理和洼地处理;分析单元62,用于从预处理后的DEM数据中分析得到河网数据,其中,河网数据中包括多个流域以及多个河流;分级单元64,用于基于Strahler分级装置对多个河流进行分级;编码单元66,用于根据预设的编码策略,并通过多个河流的分级对多个流域以及多个河流进行编码。
需要说明的是,本方案通过上述装置,提出一种基于Strahler河流级数的中国流域编码方案,本方案可以通过编写整套C++程序来实现,采用统一的算法和地形数据(DEM),提取中国境内河流、划分流域并进行Strahler河流定级,实现对河流及流域的编码,为促进水利信息管理、水文科学研究和行业间水文信息共享与交流提供基础参考。由此,本方案解决了现有的编码方法现有的编码的方法导致的编码覆盖的河流有限、可拓展性差的技术问题。
可选的,流域至少包括独立流域以及子流域。
可选的,河网数据中包括多个栅格,其中,分析单元包括:处理模块,用于通过D8算法对多个栅格进行处理,生成每个栅格的流向;计算生成每个栅格的集水面积;第一确定模块,用于将满足预设集水面积阈值的栅格确定为河网栅格;第一获取模块,用于获取河网栅格中的流域出口;第一统计模块,用于统计流入流域出口的河网栅格;第二确定模块,用于根据流入流域出口的河网栅格以及每个栅格的流向确定流域出口对应的集水范围;第三确定模块,用于根据集水范围确定河流以及流域。
可选的,分级单元包括:第四确定模块,用于将满足预设条件的河网栅格确定为河源栅格;第二获取模块,用于根据每个栅格的流向获取河源栅格的至少一个下游栅格;第二统计模块,用于统计流入下游栅格的个数;判断模块,用于根据个数判断下游栅格所在河流的等级。
可选的,编码单元包括:第二计算模块,用于计算得到多个独立流域的面积;得到模块,用于根据多个独立流域的面积得到每个独立流域的面积排名;第一生成模块,用于根据独立流域的面积排名以及独立流域包含的河流的最高分级生成每个独立流域的编码;第二生成模块,用于根据独立流域的编码以及独立流域包含的所有的河流的分级生成独立流域包含的所有的河流的编码;第三生成模块,用于根据独立流域包含的最高等级的河流的编码生成独立流域包含的子流域的编码。
本领域技术人员在考虑说明书及实践这里公开的公开后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
- 基于Strahler分级的流域及河流编码方法及装置
- 一种用于江河流域基于光伏提水的排沙去污装置