一种基于词向量的企业所属新兴产业分类方法
文献发布时间:2023-06-19 10:41:48
技术领域
本发明属于自然语言处理技术领域,尤其涉及一种基于词向量的企业所属新兴产业分类方法。
背景技术
在进行企业与产业联系的分析中,人工将企业分类到对应企业是一件费时费力的事情,尤其是在面对大量需要分类的企业样本时和出现缺乏相关分类经验的新兴产业的时候。所有企业都有经营范围,并且经营范围可以体现出企业所属产业,使用经营范围对企业所属产业归类进行分析。经营范围与产业都是由词语组成,并且这些同一经营范围或同一产业的词语之间存在相似性,因此可以采用词向量之间的距离作为词语相似度的衡量标准。
在进行算法研究中,发现适当的引入外部参数,包括使用产业描述信息作为补充知识、使用词语逆文档频率和词语词性作为词语权重,可以取得更好的分类结果。除此外,采用无监督的算法可以节省对于大量样本标注的时间和人力成本。综上,基于对加速企业分类,提高分析效率的考虑,发明了一种基于词向量的企业所属新兴产业分类方法。
在现有的发明技术中,如公开号CN110019769的专利申请公开一种智能企业分类方法,里面使用了基于SVM(支持向量机)的有监督分类方法,此类方法有如下短板:需要人工给大量的样本预先进行标注,并且需要对模型进行一定时间的训练。该方法不具备对新兴产业分类的能力,对于有新的标签出现时,需要大量时间重新进行训练,并且在使用时需要部署预先训练完成的网络,对计算机算力要求较高。
发明内容
本发明旨在对企业与产业相关分析时提供一种对于企业所属新兴产业快速准确的分类方法,鉴于已有的发明需要人工标注大量数据和大量时间进行模型训练,并且无法拓展新兴产业,因此本发明提出了一种无需人工标注、无需训练、适应性强、准确率高、可拓展性强的的基于词向量的企业所属新兴产业分类方法。
本发明所采用的技术方案是:一种基于词向量的企业所属新兴产业分类方法,其特征在于,包括以下步骤:
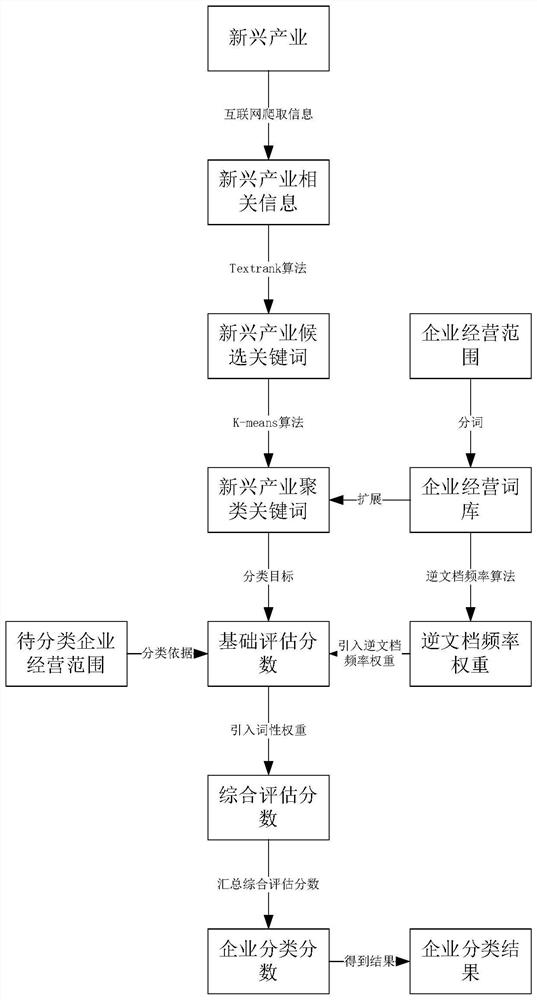
步骤1:获得输入的新兴产业,根据新兴产业的名称在互联网上获得相关信息;根据新兴产业相关信息利用Textrank算法得到候选关键词,获得新兴产业的候选关键词;根据候选关键词利用K-means算法聚类获得新兴产业聚类关键词;
步骤2:从官方网站获取企业经营范围,根据企业经营范围得到企业经营词库;根据企业经营词库,对新兴产业聚类关键词进行扩展,得到新兴产业关键词词库;
步骤3:根据企业经营词库,获得词语的逆文档频率权重;
步骤4:根据待分类企业经营范围与新兴产业关键词词库,得到基础评估分数;根据基础评估分数,得到综合评估分数;根据综合评估分数,得到企业分类分数;根据企业分类分数,得到企业所属新兴产业分类结果;
作为优选,步骤1所述新兴产业为:
Ind
p∈[1,M]
其中,Ind
步骤1所述根据新兴产业的名称在互联网上获得相关信息:
将Ind
步骤1所述根据新兴产业相关信息利用Textrank算法得到候选关键词,获得新兴产业的候选关键词:
利用Textrank算法从
key
其中,key
步骤1所述根据候选关键词利用K-means算法聚类获得新兴产业聚类关键词:
使用word2vec技术将key
key
其中,w2v(·)表示将词语转换成词向量的函数,key
使用K-means对w2v(key
其中,K
所述新兴产业聚类关键词为:
D
p∈[1,M],q∈[1,K
其中,D
作为优选,步骤2所述官方网站获取企业经营范围,根据企业经营范围得到企业经营词库:
步骤2所述的企业经营范围记为
S
1≤g≤N
其中,S
对企业经营范围经过去除停用词和分词后,得到步骤2所述企业经营词库,记为:
F=[Split(S
Split(S
其中,F表示企业经营词库,Split(·)表示去除停用词和分词函数,x
步骤2所述根据企业经营词库,对新兴产业聚类关键词进行扩展:
将新兴产业聚类关键词用余弦相似度寻找相似度最高的3个词语:
其中,cossim(·,·)表示计算余弦相似度的函数,w2v(·)表示将词语转换成词向量的函数,x
将F中与D
A
其中,A
作为优选,步骤3所述根据企业经营词库,获得词语的逆文档频率权重:
根据企业经营词库中词语的分布,计算所有词语的逆文档频率,记为:
1≤g≤G,1≤h≤G
其中,idf
根据逆文档频率,使用归一化算法,得到归一化的逆文档频率,记为:
其中,idf
根据归一化的逆文档频率得到逆文档频率权重,记为:
其中,idf(·)为计算逆文档频率权重的函数,word为任意词语,F为企业经营词库;
作为优选,步骤4根据待分类企业经营范围与新兴产业关键词词库,得到基础评估分数:
待分类企业记为:
C
其中,C
待分类企业的经营范围记为:
Scope
其中,Scope
将Scope
query
其中,query
根据待分类企业经营范围分词与新兴产业关键词词库得到余弦相似度,记为:
其中,cossim(·,·)表示计算余弦相似度的函数,w2v(·)表示将词语转换成词向量的函数,query
根据余弦相似度计算词语相似度,记为:
sim(query
其中,sim(·,·)表示计算词语相似度的函数,cossim(·,·)表示计算余弦相似度的函数,query
根据词语相似度,计算基础评估分数,记为:
其中,base(query
步骤4所述根据基础评估分数,得到综合评估分数:
根据基础评估分数,引入词语词性权重,计算综合评估分数,记为:
其中,score(query
步骤4所述根据综合评估分数,得到企业分类分数:
根据综合评估分数,得到企业分类分数,记为:
其中,classify(C
步骤4所述根据企业分类分数,得到企业所属新兴产业分类结果:
根据企业分类分数,得到企业所属新兴产业分类结果,记为:
Ind
其中,Ind
本发明优点在于,本发明优点在,无需人工标注、无需训练、适应性强、准确率高,并且可以对新增新兴产业进行分类。
附图说明
图1:为本发明实施例的流程图。
图2:为本发明实施例的方法对比效果图。
图3:为本发明实施例的结果展示图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
新兴产业为发明人根据政府报告中提及新兴产业和近年产业发展统计得到,所有新兴产业记为Ind;企业经营词库中企业由工商注册数据库得到,所有企业经营词库记为F;待分类企业根据企业名在查询对应企业的官方网站得到,所有待分类企业记为C。
请见附图1,本发明提供了一种基于词向量的企业所属新兴产业分类方法,包括以下步骤:
步骤1:获得输入的新兴产业,根据新兴产业的名称在互联网上获得相关信息;根据新兴产业相关信息利用Textrank算法得到候选关键词,获得新兴产业的候选关键词;根据候选关键词利用K-means算法聚类获得新兴产业聚类关键词;
步骤1所述新兴产业为:
Ind
p∈[1,M]
其中,Ind
步骤1所述根据新兴产业的名称在互联网上获得相关信息:
将Ind
步骤1所述根据新兴产业相关信息利用Textrank算法得到候选关键词,获得新兴产业的候选关键词:
利用Textrank算法从
key
其中,key
步骤1所述根据候选关键词利用K-means算法聚类获得新兴产业聚类关键词:
使用word2vec技术将dey
key
其中,w2v(·)表示将词语转换成词向量的函数,key
使用K-means对w2v(key
其中,K
所述新兴产业聚类关键词为:
D
p∈[1,M],q∈[1,K
其中,D
步骤2:从官方网站获取企业经营范围,根据企业经营范围得到企业经营词库;根据企业经营词库,对新兴产业聚类关键词进行扩展,得到新兴产业关键词词库;
步骤2所述官方网站获取企业经营范围,根据企业经营范围得到企业经营词库:
步骤2所述的企业经营范围记为
S
1≤g≤N
其中,S
对企业经营范围经过去除停用词和分词后,得到步骤2所述企业经营词库,记为:
F=[Split(S
Split(S
其中,F表示企业经营词库,Split(·)表示去除停用词和分词函数,x
步骤2所述根据企业经营词库,对新兴产业聚类关键词进行扩展:
将新兴产业聚类关键词用余弦相似度寻找相似度最高的3个词语:
其中,cossim(·,·)表示计算余弦相似度的函数,w2v(·)表示将词语转换成词向量的函数,x
将F中与D
A
其中,A
步骤3:根据企业经营词库,获得词语的逆文档频率权重;
步骤3所述根据企业经营词库,获得词语的逆文档频率权重:
根据企业经营词库中词语的分布,计算所有词语的逆文档频率,记为:
1≤g≤G,1≤h≤G
其中,idf
根据逆文档频率,使用归一化算法,得到归一化的逆文档频率,记为:
其中,idf
根据归一化的逆文档频率得到逆文档频率权重,记为:
其中,idf(·)为计算逆文档频率权重的函数,word为任意词语,F为企业经营词库;
步骤4:根据待分类企业经营范围与新兴产业关键词词库,得到基础评估分数;根据基础评估分数,得到综合评估分数;根据综合评估分数,得到企业分类分数;根据企业分类分数,得到企业所属新兴产业分类结果;
步骤4根据待分类企业经营范围与新兴产业关键词词库,得到基础评估分数:
待分类企业记为:
C
其中,C
待分类企业的经营范围记为:
Scope
其中,Scope
将Scope
query
其中,query
根据待分类企业经营范围分词与新兴产业关键词词库得到余弦相似度,记为:
其中,cossim(·,·)表示计算余弦相似度的函数,w2v(·)表示将词语转换成词向量的函数,query
根据余弦相似度计算词语相似度,记为:
sim(query
其中,sim(·,·)表示计算词语相似度的函数,cossim(·,·)表示计算余弦相似度的函数,query
根据词语相似度,计算基础评估分数,记为:
其中,base(query
步骤4所述根据基础评估分数,得到综合评估分数:
根据基础评估分数,引入词语词性权重,计算综合评估分数,记为:
其中,score(query
步骤4所述根据综合评估分数,得到企业分类分数:
根据综合评估分数,得到企业分类分数,记为:
其中,classify(C
步骤4所述根据企业分类分数,得到企业所属新兴产业分类结果:
根据企业分类分数,得到企业所属新兴产业分类结果,记为:
Ind
其中,Ind
步骤5:对于已存在于新兴产业关键词词库的产业,采用补充关键词的方法扩展已有词库,此方法对企业所属传统产业分类也有效;对于未存在于新兴产业关键词词库的新兴产业,采用新建产业分类并利用互联网爬虫搜索的方法创建对应的新兴产业关键词词库,达到动态扩展新兴产业的目的。
最后,为说明本发明的实验效果,本发明与其他方法进行了实验对比,实验结果如附图2,证明了本发明的可行性和准确性。分类结果的示例见附图3所示。
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 一种基于词向量的企业所属新兴产业分类方法
- 基于点互信息的词向量模型和基于CNN的文本分类方法