一种基于大文件的快速解析系统
文献发布时间:2023-06-19 10:41:48
技术领域
本发明涉及文件处理相关技术领域,尤其是指一种基于大文件的快速解析系统。
背景技术
目前大文件解析常用方案为使用大数据架构,虽然解析效率高,但是一套大数据架构在部署上较为繁重,且要求服务器配置较高,同时需要额外的人力成本。
非大数据架构的文件解析效率较低,同时对横向扩展性支持较差。
发明内容
本发明是为了克服现有技术中存在上述的不足,提供了一种低成本的基于大文件的快速解析系统。
为了实现上述目的,本发明采用以下技术方案:
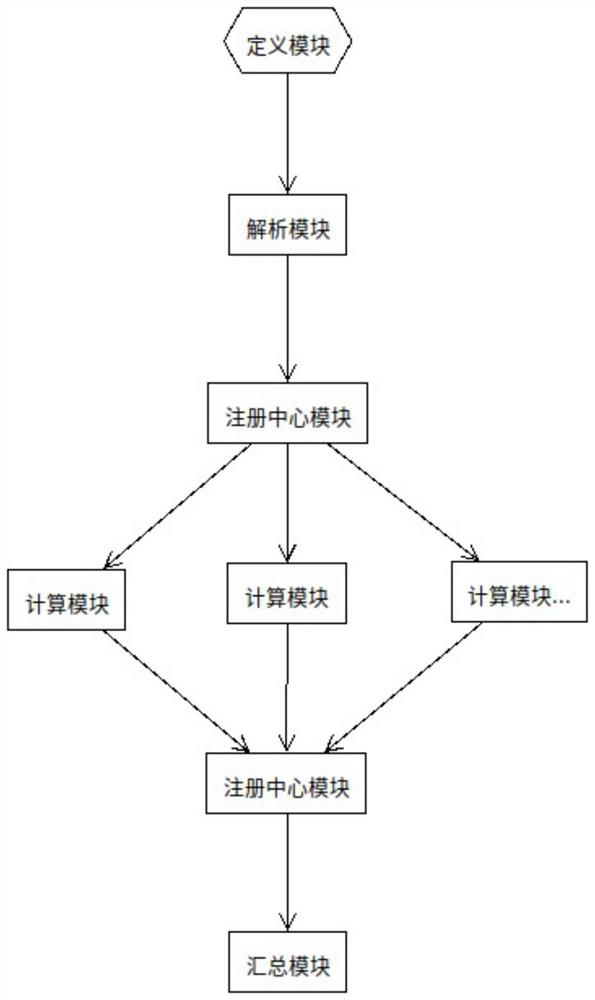
一种基于大文件的快速解析系统,包括定义模块、解析模块、注册中心模块、计算模块、汇总模块;
定义模块用于设置大文件读取方式及定义相关参数,与解析模块连接;
解析模块用于解析大文件元信息及发布计算任务,与注册中心模块连接;
注册中心模块用于存储待计算任务及每个任务的结果,与计算模块连接;
计算模块用于接收计算任务及执行解析计算,与注册中心模块连接;
汇总模块用于读取计算模块解析结果并汇总数据,与注册中心模块连接。
本发明公开了一种基于大文件的快速解析方案,包括定义模块、解析模块、注册中心模块、计算模块、汇总模块,通过该方案可以以一种简单的低成本的系统架构高效的完成大文件解析工作,且同时完美支持横向扩展用于提升解析效率。
作为优选,所述定义模块在整个系统运行前执行完,需要完成以下设置及定义:
第一:设置大文件读取方式,即把待解析的大文件通过http方式代理出来,后续通过http地址获取到文件内容,且需要支持http-range请求;
第二,定义每个计算任务的文件大小,即每次http-range请求的大小,需要根据实际情况设置,每次计算任务的请求大小应该控制在服务器内存范围内。
作为优选,由于定义模块已经代理出大文件的http请求,同时支持了range,那么解析模块就需要获取到该大文件的元数据信息,主要是文件的总大小,得到文件总大小后,根据定义模块设置的计算任务文件大小,得出任务总数及每个任务的文件解析范围,得到每个任务的信息后需要进行发布,即向注册中心模块写入该信息,同时携带文件名称,用于区分任务。
作为优选,所述注册中心模块采用zookeeper实现,zookeeper是一种树形结构的存储,此处定义两种树形节点,每个节点由不同的模块写入和读取:
第一:任务节点,由解析模块写入,由计算模块读取,该节点下为任务集合;
第二:结果节点,由计算模块写入,由汇总模块读取,该节点下为计算完成后的结果集合。
作为优选,所述计算模块是支持横向扩展的模块,需要监听注册中心模块中的任务节点,当收到新增的监听消息后,需要先对该节点进行加锁,然后读取该节点的内容,得到文件流后进行具体的业务计算,最后将该任务节点删除。
作为优选,所述汇总模块需要监听注册中心模块中的结果节点,当收到新增的监听消息后,对其内容进行处理,将结果集存储存入内存或具体第三方数据库,后续监听到其他节点数据后进行数值累加,读取完毕后删除该结果节点。
本发明的有益效果是:可以以一种简单的低成本的系统架构高效的完成大文件解析工作,且同时完美支持横向扩展用于提升解析效率。
附图说明
图1是本发明的系统框图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步的描述。
如图1所述的实施例中,一种基于大文件的快速解析系统,包括定义模块、解析模块、注册中心模块、计算模块、汇总模块;
定义模块用于设置大文件读取方式及定义相关参数,与解析模块连接;定义模块在整个系统运行前执行完,需要完成以下设置及定义:
第一:设置大文件读取方式,即把待解析的大文件通过http方式代理出来,后续通过http地址获取到文件内容,且需要支持http-range请求;此处以nginx代理为例,配置如下:
其中:
8888为对外开放的端口
/bigFile.log为对外开放的请求地址
add_header Accept-Ranges bytes为支持range请求
root为实际大文件的本地路径
最终访问该文件可以采用:http://服务器ip:8888/bigFile.log方式访问
第二,定义每个计算任务的文件大小,即每次http-range请求的大小,需要根据实际情况设置,每次计算任务的请求大小应该控制在服务器内存范围内。比如:待解析文件为1TB,计算模块的机器配置为1核2GB,那么每次计算任务的请求大小应该控制在服务器内存范围内,此时每个计算任务的文件文件就为1GB,那么最终该文件会产生1024个子任务。
解析模块用于解析大文件元信息及发布计算任务,与注册中心模块连接;由于定义模块已经代理出大文件的http请求,同时支持了range,那么解析模块就需要获取到该大文件的元数据信息,主要是文件的总大小,范例如下:
#解析模块需要发送的请求
HEAD http://代理服务器:888/bigFile.log
#响应内容如下:
HTTP/1.1 200OK
Server:nginx/1.16.1
Date:Sat,26Dec 2020 07:04:45GMT
Content-Type:application/octet-stream
Content-Length:20003921
Last-Modified:Sat,26Dec 2020 07:04:44GMT
Connection:keep-alive
ETag:"5fe6e08c-1313c51"
Accept-Ranges:bytes
其中:
Content-Length为当前文件总大小,单位为byte
得到文件总大小后,根据定义模块设置的计算任务文件大小,得出任务总数及每个任务的文件解析范围,比如每个任务文件大小为1MB,如果总文件大小按照上述范例为20003921字节,那么每个任务的信息如下:
任务1:Range:bytes=0-1048576
任务2:Range:bytes=1048577-2097153
任务3:Range:bytes=2097154-3145730
...
任务20:Range:bytes=19922945-20003921
得到每个任务的信息后需要进行发布,即向注册中心模块写入该信息,同时携带文件名称,用于区分任务。
注册中心模块用于存储待计算任务及每个任务的结果,与计算模块连接;注册中心模块采用zookeeper实现,zookeeper是一种树形结构的存储,此处定义两种树形节点,每个节点由不同的模块写入和读取:
第一:任务节点,由解析模块写入,由计算模块读取,节点位置为:/task/文件名称(解析模块传递过来的文件名称)/,该节点下为任务集合;范例:
/
/task
/bigFile.log
/task1
/task2
/task3
/...
/task20
其中task1/task2等节点内容需要同时写入range范围(解析模块传递过来的任务详情):Range:bytes=x-x
第二:结果节点,由计算模块写入,由汇总模块读取,节点位置为:/result/文件名称(计算模块传递过来的文件名称),该节点下为计算完成后的结果集合。范例:
/
/result
/bigFile.log
/result1
/result2
/result3
/...
/result20
其中result1/result2等节点内容需要同时写入计算后的结果(计算模块传递过来的结果详情),该结果的格式视具体的业务要求而定,比如如果本次解析任务为计算整个文件中包含多少个“hello”字符,那么结果格式为:helle=12222
计算模块用于接收计算任务及执行解析计算,与注册中心模块连接;计算模块是整个方案中真正执行任务的模块,同时也是支持横向扩展的模块,需要监听注册中心模块中的任务节点:/task/,具体监听方式可以参考如下java伪代码:
PathChildrenCache pathChildrenCache=new PathChildrenCache("zookeeper服务实例","/task/",true);
//设置监听器和处理过程,cacheImpl为实现PathChildrenCacheListener接口的服务,内部可以接收到该节点下的增删改查变动通知
pathChildrenCache.getListenable().addListener(cacheImpl,Executors.newCachedThreadPool());
//开始监听
pathChildrenCache.start(StartMode.BUILD_INITIAL_CACHE);
当收到新增的监听消息后,比如:/task/bigFile.log/task1,需要先对该节点进行加锁(防止被其他计算模块重复读取),然后读取该节点的内容Range:bytes=0-1048576,发送如下请求:
请求
GET http://代理服务器:888/bigFile.log
Range:bytes=0-1048576
响应
0-1048576字节的文件流内容
得到文件流后进行具体的业务计算,比如开始计算该段文件流中包含的“hello”字符串的个数,得出结果后写入注册中心模块中的结果节点中:/result/bigFile.log/result1,结果内容为:hello=12222,最后将该任务节点删除。
汇总模块用于读取计算模块解析结果并汇总数据,与注册中心模块连接;汇总模块需要监听注册中心模块中的结果节点:/result/,具体监听方式可以参考如下java伪代码:
PathChildrenCache pathChildrenCache=new PathChildrenCache("zookeeper服务实例","/result/",true);
//设置监听器和处理过程,cacheImpl为实现PathChildrenCacheListener接口的服务,内部可以接收到该节点下的增删改查变动通知
pathChildrenCache.getListenable().addListener(cacheImpl,Executors.newCachedThreadPool());
//开始监听
pathChildrenCache.start(StartMode.BUILD_INITIAL_CACHE);
当收到新增的监听消息后比如:/result/bigFile.log/result1,对其内容进行处理,内容格式视具体业务而定,比如该范例中,我们读取到的为:hello=12222,将12222结果集存储存入内存或具体第三方数据库,后续监听到其他节点数据后进行数值累加,读取完毕后删除该结果节点。
本发明公开了一种基于大文件的快速解析方案,包括定义模块、解析模块、注册中心模块、计算模块、汇总模块,通过该方案可以以一种简单的低成本的系统架构高效的完成大文件解析工作,且同时完美支持横向扩展用于提升解析效率。已应用于当虹云产品,在读取解析CDN日志方面节省了大数据架构产生的高成本,同时此方案的解析效率比之前大数据架构下的解析效率更加高效。
- 一种基于大文件的快速解析系统
- 一种档案信息包大文件封装、解析查看方法与系统