一种基于位稀疏计算的神经网络加速方法
文献发布时间:2023-06-19 10:48:02
技术领域
本发明涉及人工智能技术领域,尤其是涉及一种基于位稀疏计算的神经网络加速方法。
背景技术
近年来,神经网络在各种领域相比于传统算法有了极大的进步。在图像、视频、语音处理领域,各种各样的网络模型被提出,例如卷积神经网络、循环神经网络。训练较好的CNN模型把ImageNet数据集上5类顶尖图像的分类准确率从73.8%提升到了84.7%,也靠其卓越的特征提取能力进一步提高了目标检测准确率。RNN在语音识别领域取得了最新的词错率记录。总而言之,由于高度适应大量模式识别问题,神经网络已经成为许多人工智能应用的有力备选项。然而,神经网络模型仍旧存在计算量大、存储复杂问题。同时,神经网络的研究目前还主要聚焦在网络模型规模的提升上。例如,做224x224图像分类的最新CNN模型需要390亿浮点运算(FLOP)以及超过500MB的模型参数。由于计算复杂度直接与输入图像的大小成正比,处理高分辨率图像所需的计算量可能超过1000亿。为了减少神经网络的计算量以及存储量,本发明提出一种基于位稀疏的神经网络加速方法。
发明内容
针对现在技术中存在的问题,本发明提供一种基于位并行计算的神经网络加速方法,针对神经网络计算数据有效位的计算,减少神经网络的计算量,同时采用高并行度以及数据复用减少内存访问次数来降低能耗。
一种基于位稀疏计算的神经网络加速方法,步骤如下:
步骤(1).动态定点量化,将浮点数据转化为动态定点数据;
神经网络中有大量的参数,如果采用32位浮点数表示,不仅对内存的占用空间大,而且读取效率不高。故在不影响精度的前提下,采用动态定点数量化,将神经网络的32位浮点数据量转化为16位动态定点数据,可以大大减少数据的存储空间,同时提高数据读写的效率。
步骤(2).为了提高数据位的稀疏程度,采用二进制编码和booth编码。
步骤(3).神经网络加速单元设计;
神经网络中主要的运算在于卷积层和全连接层,它们计算方式都是一样的,都是乘加运算。那么对于神经网络的加速,针对卷积层和全连接层进行神经网络加速单元设计。
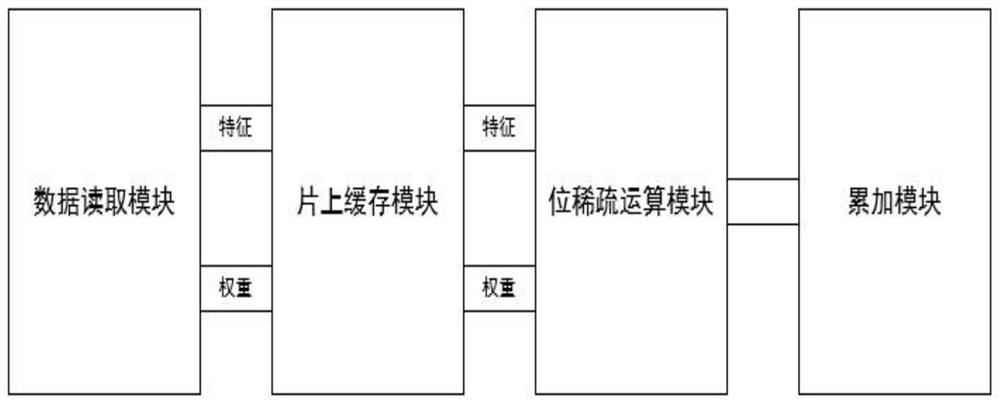
神经网络加速单元包括数据读取模块(DMA)、片上缓存模块、位稀疏运算模块和累加模块,用于完成卷积层和全连接层的运算。
神经网络的参数量是巨大的,同时片上缓存模块的大小是有限的,所以不可能将神经网络的参数量一次性读取进来,所以需要将所需要的数据权重和特征进行分块,分批次进行读取和运算。数据的分块方式采用输入通道和输出通道并行的分块方式,数据读取模块即DMA模块读取数据的时采用输入通道和输出通道并行的分块方式读取所需要的权重和特征。DMA模块采用突发模式读取数据,即根据所需数据的长度以及数据存放的基地址进行数据读取,突发长度为16。
片上缓存模块用于对权重和特征数据的缓存,采用乒乓buffer单元,增加运算时的数据复用,降低对外部存储器的访问次数,降低访存产生的功耗。更加高效地供给数据给位稀疏运算模块。片上缓存单元的存在,可以减少对外部存储器的重复访问,同时更好利用数据复用机制,大大降低了访存功耗。
位稀疏运算模块位稀疏运算单元包括数据编码模块和位运算单元。数据编码模块利用二进制编码和booth编码两种方式,根据编码后的数据位稀疏程度,选择数据位稀疏程度更高的编码数据结果。位运算单元利用编码得到的数据,进行相应的运算。
由于数据的分块方式采用输入通道和输出通道并行的分块方式,数据并没有一次性读取进来,所以一次运算结果并不能输出,经过多次运算后,通过累加器模块将所需要的运算结果进行累加后完成输出。
本发明有益效果如下:
本发明利用数据动态定点化、高并行度、数据复用、位稀疏运算模块,减少了冗余无用的计算和内存访问,对神经网络的inference进行加速,可以提高CNN的实时性,实现了较高的计算性能,同时降低了能耗。
附图说明
图1是本发明的位稀疏算法原理示意图;
图2是本发明的数据分块原理示意图;
图3是本发明的神经网络加速单元结构示意图;
图4是本发明位稀疏运算模块结构示意图。
具体实施方式
下面结合附图和实施方式对本发明进行进一步说明。
本发明方法,具体步骤包括:
一种基于位稀疏行的神经网络加速方法,具体步骤如下:
步骤(1).动态定点量化,将神经网络的32浮点数据量化为16位动态定点数据。
首先在精度允许接受范围下,将浮点数据从32位压缩到16位,降低数据的位宽,得到16位浮点数据。利用动态定点量化,将浮点数据转化为动态定点数据,所述的动态定点数据即定点数据设置有一个可移动的小数点位置。具体表示方式如下:
B=C/2
式子中B是浮点数据,C是其定点数,m是小数点的位置。
采用动态定点量化,转化后的动态定点数据的乘法运算和加法运算,需要利用小数点的位置进行计算,根据小数点的位置进行移位得到最终结果。
步骤(2).为了提高数据位的稀疏程度,采用二进制编码和booth编码。
神经网络中主要的运算为乘加运算,即权重和特征的乘加操作。在上述步骤(1)的数据量化后,得到16位定点数据,两个16bit的数据相乘,普通硬件乘法器的实现本质即移位相加,那么16位数据的所有位都要参与运算。通过位稀疏算法,采用二进制编码和booth编码方式,使数据不改变的前提下,提高了数据位的稀疏程度。利用二进制编码和booth编码后的16位数据中的0比特元素不参与运算,只有有效位为1的数据参与运算。在数据进行乘法运算的层面上,分解了乘法运算的部分,精确到位级别的运算,不会改变数据运算的结果,不仅降低数据的运算量,而且降低了运算时产生的功耗。
将步骤(1)得到的动态定点数进行相应的编码后,传输给位稀疏运算单元运算。
步骤.(3)神经网络加速单元设计
神经网络中主要的运算在于卷积层和全连接层,它们计算方式都是一样的,都是乘加运算。那么对于神经网络的加速,针对卷积层和全连接层进行神经网络加速单元设计。
如图3所示,神经网络加速单元包括数据读取模块(DMA)、片上缓存模块、位稀疏运算模块和累加模块,用于完成卷积层和全连接层的运算。
首先,神经网络加速单元所需要的数据权重和特征,按照输入通道和输出通道并行的分块方式,通过DMA将动态定点化后的数据分多次进行读取,每次读取的数据的长度为DMA的突发长度16。由DMA读取到的数据特征和权重分别放在片上缓存模块的存储单元(memory)中,片上缓存模块的作用是增加运算时的数据复用,降低对外部存储器的访问次数,降低访存产生的功耗。位稀疏运算单元包括数据编码模块和位运算单元。数据编码模块利用二进制编码和booth编码两种方式,根据编码后的数据位稀疏程度,选择数据位稀疏程度更高的编码数据结果。为了提高数据位的稀疏程度,采用这两种编码方式的原因为不同的数据利用不同编码得到的位稀疏程度不同,有的利用二进制编码得到的位稀疏程度高,有的利用booth编码后的数据位稀疏程度高,选择数据位稀疏程度更高的编码数据结果。位运算单元利用编码得到的数据,进行相应的运算。片上缓存模块和位稀疏运算模块之间采用握手信号,即位稀疏运算模块需要接收到片上缓存模块的相应的数据才能进行运算。同时当前位稀疏运算模块中的数据未完成运算,则片上缓存模块中的数据不会发送给位稀疏运算模块。数据供给的速率和运算的速率需要同步。通过片上缓存模块中的乒乓buffer提升效率,即两块数据缓存区,一块存放即将参与运算的数据,另一块存放下一次需要运算的数据。那么,当数据进入运算单元进行运算时,下下次的数据也会进入一块buffer中等待着,这样就能够高效提供数据给运算单元,同时运算单元也能够一直在运算,提高了运算的效率。累加模块将相应的运算结果进行累加后完成输出,由于数据的分块方式,数据的输出要经过多次读取和运算后才能输出,因此将运算完但是还不能输出的数据进行暂时存放,等待真正累加完得到相应的结果再进行输出。
如图4所示,位稀疏运算模块包含编码模块和运算模块,编码模块是根据二进制编码和booth编码选择位稀疏程度更高的编码结果,得到其有效位的位置。特征A和权重W相乘可以分解到位级别,其运算方式可以根据以下公式:
A×W=∑(-1)
式子中t和t'是有效数据的位置,s和s'是数据编码后的符号位。特征和权重数据的有效位可能会有多个,t
从图4分析,首先特征和权重通过位稀疏运算模块的编码模块,提高数据的位稀疏程度,得到相应的有效位和符号位。数据的有效位和符号位的个数是相同的,一个周期处理一组。有效位t和t'进行相加得到term,同时有效位的符号位进行与运算得到符号位sign,然后利用term和sign进行移位运算,送入到部分和中。当然,刚才参与运算只是一组有效位,数据的剩余有效位会按照相同的方式进行运算,知道所有有效位运算完成,部分和才可以输出。
位稀疏算法原理如图1所示:
以第一个例子来说,两个8位的数据6和3相乘,其普通乘法器的运算方法是利用所有位参与运算,移位相加。但是利用其二进制编码的数据0000_0110和0000_0011,实质上可以其有效位1所在的位置进行相应的移位运算后再相加,即左移1位、两次左移2位和一次左移3位后得到2、8、8,相加得到的结果是等于18。
以第二个例子来说,同样是两个8位的数据62和3相乘,如果利用二进制编码的话即0011_1110和0000_0011,那么62的有效位为1的数量较多,并没有很好的利用位稀疏性。这时候,可以利用另外一种编码方式booth编码,62经过booth编码后其实只有第六位和第零位是有效位,同时也引入了符号位,即2
128+64-4-2=186。
数据分块方式如图2所示,即权重和特征的分块。由于片上缓存资源的有限,所以需要对数据进行分块,多次进行读取。数据的分块方式是根据输入通道和输出通道并行度去切分的,输入通道的并行度为Tm,输出通道并行度为Tn。
- 一种基于位稀疏计算的神经网络加速方法
- 一种基于稀疏向量矩阵计算的神经网络加速器及加速方法