一种考虑时空特征的网联车辆轨迹聚类方法
文献发布时间:2023-06-19 10:48:02
技术领域
本发明涉及轨迹聚类技术,具体涉及一种考虑时空特征的网联车辆轨迹聚类方法。
背景技术
近年来,随着通信技术的发展以及网联车辆的增多,越来越多网联车辆的GPS轨迹数据被采集或记录在云端。轨迹数据一般是由多条带有时间戳的位置信息构成的带有时序性的序列,描述的是车辆的移动行为,通过对车辆轨迹数据进行分析,可以挖掘大量的出行信息。
聚类是通过分析数据对象之间的相似性,并把相似性高的数据划分成同一类,通过对车辆的轨迹进行聚类可以获取很多信息,如:通过聚类结果可以分析居民日常出行的热点路径,支撑路网重点通道和路段的判断识别,辅助公交路线的修改和设立等多种有关城市交通规划管理的方面。
传统的聚类算法如Kmeans是以距离作为对象的相似性度量标准,这也是大多数聚类算法所采纳的,而且一般使用欧氏距离做为距离的计算方法,但是仅仅以欧氏距离衡量轨迹之间的差异性并没有考虑轨迹之间的时间特征,因此并不能取得很好的聚类效果。
发明内容
本发明的目的在于提供一种考虑时空特征的网联车辆轨迹聚类方法,以充分考虑影响聚类的各种因素,提高聚类结果的准确性。
为了解决上述问题,本发明提供的技术方案包括:
1.一种考虑时空特征的网联车辆轨迹聚类方法,其特征在于,所述方法包括如下步骤:
步骤一、对轨迹区域内的交叉路口进行编号,根据轨迹通过的路段,将轨迹转化为其经过的交叉口的编号序列;
步骤二、计算轨迹间的空间距离、时间距离以及编辑距离;其中所述编辑距离为组成估计的字符串之间的编辑距离;
步骤三、根据步骤二计算出的空间距离、时间距离以及编辑距离数据,采用信息量权数法对三个距离的权重系数进行计算,进而求出考虑了时空差异性的综合距离;
步骤四、基于聚类对象局部密度和距离对轨迹进行聚类。首先对轨迹数据及其部分特征进行描述与定义。其包括:计算轨迹对象的局部密度ρ
优选地,将每条轨迹作为一个对象,
计算轨迹对象的局部密度
轨迹对象之间的距离
优选地,定义如下若干记号:n
优选地,步骤一中轨迹数据转化为交叉口的编号序列包括如下子步骤:
S11:将轨迹集所在地区的交叉口标定编号集C={1,2,…,n},并记录对应的经纬度坐标为L
S12:设定交叉口范围半径为r,通过遍历轨迹点与交叉口范围进行比较得到轨迹经过的交叉口编号序列。
优选地,所述步骤二中计算轨迹之间空间距离、时间距离以及编辑距离包括如下子步骤:
优选地,计算轨迹间的空间距离,取两条轨迹的起点和终点经纬度坐标,将地球近似看作球形,利用地球半径R与起始点经纬度坐标计算起始点距离之和作为轨迹间的空间距离;
优选地,计算轨迹间的时间距离,计算两条轨迹的开始时间之差作为轨迹间的时间距离;
优选地,计算轨迹间的编辑距离,根据步骤S12所得轨迹的交叉口编号序列计算轨迹间的编辑距离。
优选地,,综合距离的计算包括如下子步骤:
S31:将步骤二中求得的三个距离数据进行归一化处理;
S32:根据三个距离的数据分别计算其平均值
S33:对变异系数归一化处理,归一化处理的结果作为各距离的权重系数W
实现本发明目的的技术解决方案为:一种考虑时空特征的网联车辆轨迹聚类方法,包括如下步骤:
S1:对轨迹区域内的交叉路口进行编号,根据轨迹通过的路段,将轨迹转化为其经过的交叉口的编号序列;
S2:计算轨迹间的时间距离、编辑距离以及空间距离;
S3:根据步骤2计算出的三种距离数据,采用信息量权数法对三个距离的权重系数进行计算,进而求出考虑了时空差异性的综合距离;
S4:采用一种考虑聚类对象局部密度和距离的聚类方法对轨迹进行聚类;
进一步,步骤S1中轨迹数据转化为交叉口的编号序列包括如下子步骤:
S11:将轨迹集所在地区的交叉口标定编号集C={c
S12:设定交叉口范围半径为r,通过遍历轨迹点与交叉口范围进行比较得到轨迹经过的交叉口编号序列。
进一步,步骤S2中计算轨迹之间空间距离、时间距离以及编辑距离包括如下子步骤:
S21:计算轨迹间的时间距离,计算两条轨迹的开始时间之差作为轨迹间的时间距离;
S22:计算轨迹间的编辑距离,根据步骤S12所得轨迹的交叉口编号序列计算轨迹间的编辑距离。
S23:计算轨迹间的空间距离,取两条轨迹的起点和终点经纬度坐标,将地球近似看作球形,利用地球半径R与起始点经纬度坐标计算起始点距离之和作为轨迹间的空间距离;
进一步,步骤S3中权重系数以及综合距离的计算包括如下子步骤:
S31:将步骤S2中求得的三个距离数据进行归一化处理;
S32:根据三个距离的数据分别计算其熵值E
S33:对差异性系数归一化处理,结果作为距离的权重系数W
本发明与现有技术相比,其显著优点在于:1)在考虑轨迹差异性时引入编辑距离的概念,多维度的评估轨迹之间的差异性;2)采用一种新型的聚类方法,解决了如Kmeans等传统聚类算法需要设定聚类簇数以及多个阈值的问题。
附图说明
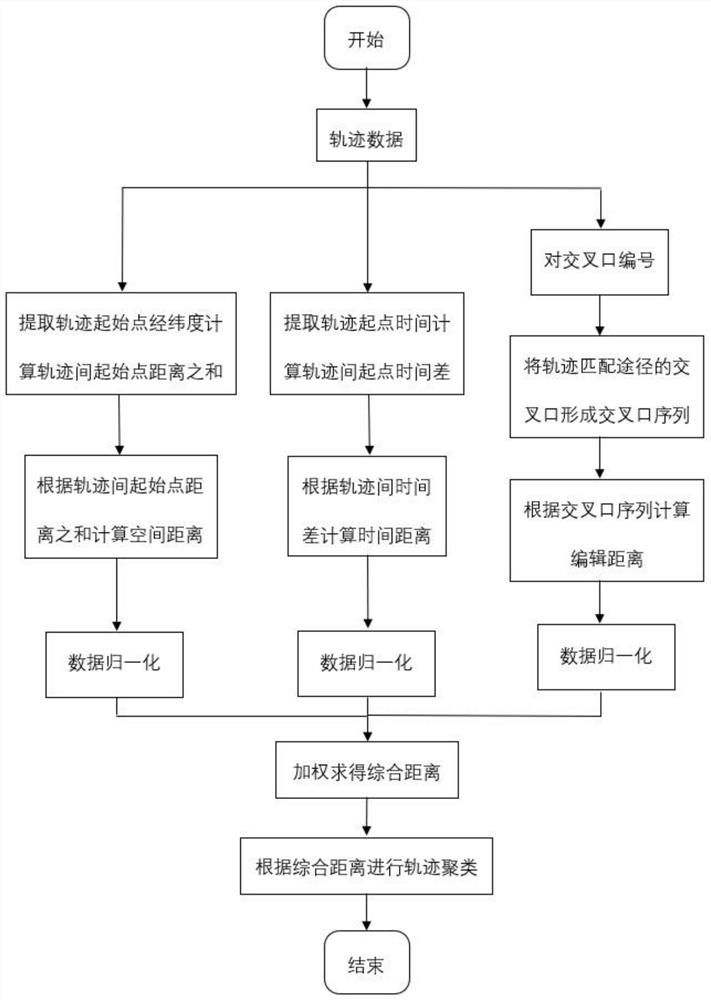
图1为本发明的方法流程示意图
图2为轨迹点转化为交叉口序列示意图
图3为空间距离计算示意图
图4为聚类中心选取示意图
具体实施方式
下面结合附图对本发明进行进一步说明:
本发明的方法流程示意图如图1所示,具体内容如下:
在本实例中的数据有轨迹数据和交叉口数据。轨迹数据由时间间隔几秒的多条数据组成,每条数据包括经纬度坐标,时间等信息,交叉口数据为交叉口的经纬度坐标,这些都是常见的数据。
步骤1:设轨迹数据集为
步骤2:首先计算轨迹间的时间距离,设两条轨迹的起始时间为time
编辑距离表示两个字符串之间的差异,具体而言,其为把一个字符串转换为另一个字符串时,所需要的最小编辑操作的次数。由于本专利的交叉口序列也是一组字符串,因此其用于本方法的交叉口序列同样适用。
所述编辑距离中的编辑操作包含替换、插入和删除三种,本方法采用动态规划的方法计算编辑距离,假设两条轨迹的交叉口序列分别为c
最终两条轨迹序列之间的编辑距离用D
编辑距离可以反应两条轨迹序列之间的形状相似性;但是对于两条形状相似的轨迹,编辑距离并不能体现轨迹之间的具体的空间差距大小,因此,本发明引入空间距离来更全面的衡量轨迹之间的空间特征。
最后计算轨迹间的空间距离,设两条轨迹的起始点经纬度坐标分别为O
设地球半径为R,如图2所示,从A和B两点分别向赤道平面作垂线,垂足分别为C和D;从A点向BD作垂线交BD于E。分别求出AC、BD、CD,再由BE和AE求出AB,算出AB所对圆心角,进而求出弧AB。具体计算公式为:
AB
由上述公式求得轨迹间起点距离为d
需要补充的是,若想更多地考虑轨迹中间部分的空间距离,可以考虑加入轨迹中间的点去计算空间距离,加入几个代表点的距离之和代表空间距离D
步骤3:根据步骤2计算可得各个轨迹之间的空间距离,时间距离和编辑距离数据,进一步地计算三个距离的权重系数。
首先对三个距离数据做归一化处理,归一化的空间距离D
定义D
进一步地根据熵值计算差异性系数:f
进一步地,计算综合距离数据D=W
步骤4:下面对于使用的聚类算法进行具体解释:
首先对轨迹数据及其部分特征进行描述与定义。
对于每条轨迹,若将其作为一个对象,定义其密度:
其中函数
参数D
进一步地,定义每个轨迹对象的距离δ
设
其中
进一步地,定义如下若干记号:n
进一步地,给出聚类算法的完整具体步骤:
Step1:计算综合距离D
Step2:计算截断距离D
Step3:计算
Step4:计算
Step5:令n
Step6:令
Step7:如果
Step8:令j=j+1,如果j≤i-1,返回Step7,否则执行Step9。
Step9:令i=i+1,如果i≤N,返回Step6,否则执行Step10。
Step10:
Step11:以ρ和δ为坐标轴建立坐标系,选取同时具有较大ρ值和δ值的对象作为聚类中心,以图4为例,轨迹t
Step12:初始化轨迹对象归类属性标记
Step13:令i=1。
Step14:如果
Step15:令i=i+1,如果i≤N,返回Step14,否则结束。
至此,聚类算法介绍完成,
- 一种考虑时空特征的网联车辆轨迹聚类方法
- 一种多时空特征融合下的兴趣点轨迹聚类方法