一种基于RGB室外道路场景图像的红绿灯识别方法
文献发布时间:2023-06-19 10:48:02
技术领域
本发明涉及图像识别技术领域,尤其涉及一种基于RGB室外道路场景图像的红绿灯识别方法。
背景技术
无人驾驶、智能辅助驾驶、导航等技术中需要实时识别道路上的红绿灯,目前红绿灯识别一般采用实时目标检测网络,主流网络有基于候选区域的目标检测器或单次目标检测器。基于候选区域的目标检测器,会使用特征提取器对整图进行特征提取,再在特征图上创建候选区域ROI,将各个候选区域进行卷积和分类,得到检测结果;此方法虽然对红绿灯等小物体效果良好,但在开发端NVIDIA TX2推理速度很慢,不能满足实时性要求,如FasterR-CNN等网络模型。单次目标检测器,会基于滑动窗口进行预测,同时预测anchors的边界框和类别,再提取特征进行卷积和分类,得到检测结果;此方法在开发端NVIDIA TX2推理速度较快,但是对检测红绿灯等小物体检测效果很差,如YOLOV3、SSD等网络模型。
发明内容
本发明的目的是克服上述现有技术的缺点,结合主流网络模型的优缺点,采用一种新的方法--基于中心点的检测网络CenterNet,将检测目标定位到一个点,即检测矩形框的中心点,再卷积回归目标的类别位置等其他属性,得到检测结果;此方法对检测红绿灯等小物体效果良好,在开发端NVIDIA TX2推理速度较快,能同时满足识别精度和实时性要求。
本发明是通过以下技术方案来实现的:
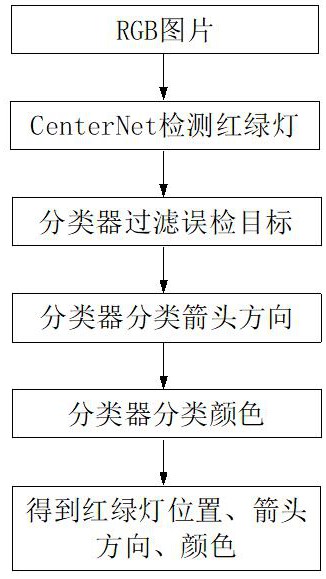
一种基于RGB室外道路场景图像的红绿灯识别方法,包括如下步骤:
S1、基于Nvidia Tx2平台,实时获取道路场景的RGB图片,对RGB图片进行归一化处理后,输入CenterNet网络进行推理,得到红绿灯的位置信息,所述红绿灯的位置信息包括各红绿灯的中心点坐标(在RGB图片中的坐标位置)、宽度和高度等;
S2、依据上述步骤得到的各红绿灯的位置信息,从RGB原图片中抠取包含有红绿灯的目标区域,得到各个目标区域及其位置信息;
S3、将步骤S2中得到的各目标区域依次输入排除误检的自定义分类器中,剔除目标区域为背景的目标区域(非红绿灯或关闭的红绿灯),保留目标区域为红绿灯正常显示的目标区域及其位置信息,所述目标区域为背景的目标区域包括红绿灯关闭的目标区域;
S4、将步骤S3中保留的各目标区域依次输入分类箭头方向的自定义分类器中,剔除目标区域为背景的目标区域(非红绿灯,如非红绿灯的箭头或圆形),保留目标区域为向左箭头、向右箭头、向前箭头、掉头箭头或圆形指示灯的目标区域及其位置信息和箭头方向信息;
S5、将步骤S4中保留的各目标区域依次输入分类指示灯颜色的自定义分类器中,剔除目标区域颜色为背景的目标区域(非红绿灯,分类出的目标区域中可能含有非红绿灯颜色的箭头圆形等),保留目标区域为红色、黄色或绿色的目标区域及其位置信息、箭头方向和颜色等;
S6、将步骤S5中保留的各目标区域依次提取特征,得到RGB图片中能识别到的红绿灯信息,所述红绿灯信息包括各红绿灯在RGB图片中的位置信息、红绿灯的方向信息和红绿灯的颜色信息等。
进一步地,所述S1步骤中的RGB图像由RGB摄像头获得。
为提高识别效率,充分利用Nvidia TX2硬件平台性能,进一步地,所述S1步骤中CenterNet网络推理的步骤包括:基于Nvidia TX2硬件平台,将Pytorch训练好的网络模型转换成ONNX模型,再将ONNX模型通过TensorRT生成TRT加速模型,推理时直接加载TRT加速模型,提高了红绿灯检测和分类的速度,达到实时识别的效果。
进一步地,所述S3步骤中排除误检的自定义分类器的网络模型包括输入层、隐藏层和输出层,分别如下:
数据由输入层输入,分类器模型需要训练和验证,故需要准备一定数量的样本数据集,并将其随机分为训练样本集和测试样本集,本发明中,样本数据集为图片样本,输入层输入样本数据集,并将输入的样本数据集中的图片重定义尺寸大小为1*3*48*48,其中,用于训练和测试的样本数据集有两类:0类为正常显示的红绿灯图片,1类为与红绿灯类似的背景图片和指示灯关闭的红绿灯图片等;
隐藏层共有六层,分别为:
第一层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第二层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第三层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第四层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第五层:包括一个卷积层、一个归一化层和一个激活函数层;
第六层:包括一个卷积层、一个归一化层和一个激活函数层;
输出层为二分类分类器,输出两个类别:0表示输入图片为背景,1表示输入图片为红绿灯,可以根据分类器输出排除误检。
进一步地,所述S4步骤中分类箭头方向的自定义分类器的网络模型包括输入层、隐藏层和输出层,分别如下:
输入层输入样本数据集,并将输入的样本数据集中的图片重定义尺寸大小为1*3*48*48,其中,用于训练和测试的样本数据集有6类:0类为指示灯关闭的红绿灯图片,1类为箭头向左的红绿灯图片,2类为箭头向右的红绿灯图片,3类为箭头向前的红绿灯图片,4类为箭头方向为掉头的红绿灯图片,5类为指示灯为圆形的红绿灯图片;
隐藏层共有六层,分别为:
第一层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第二层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第三层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第四层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第五层:包括一个卷积层、一个归一化层和一个激活函数层;
第六层:包括一个卷积层、一个归一化层和一个激活函数层;
输出层为多分类分类器,输出六个类别:0表示背景,1表示向左箭头,2表示向右箭头,3表示向前箭头,4表示掉头箭头,5表示圆形指示灯。
进一步地,所述S5步骤中分类指示灯颜色的自定义分类器的网络模型包括输入层、隐藏层和输出层,分别如下:
输入层输入样本数据集,并将输入的样本数据集中的图片重定义尺寸大小为1*3*48*48,其中,用于训练和测试的样本数据集有4类:0类为指示灯颜色是背景色的红绿灯图片,1类为指示灯颜色是红色的红绿灯图片,2类为指示灯颜色是黄色的红绿灯图片,3类为指示灯颜色是绿色的红绿灯图片;
隐藏层共有六层,分别为:
第一层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第二层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第三层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第四层:包括一个卷积层、一个归一化层、一个激活函数层和一个最大池化层;
第五层:包括一个卷积层、一个归一化层和一个激活函数层;
第六层:包括一个卷积层、一个归一化层和一个激活函数层;
输出层为多分类分类器,输出4个类别:0表示背景,1表示红色,2表示黄色,3表示绿色。
进一步地,所述卷积层的卷积核为3*3, 步长为1,边界补零为1;所述归一化层中采用Batch Normalize函数,所述激活函数层采用Relu激活函数,所述最大池化层采用2X2矩阵, 步长为2,边界补零为0。
进一步地,所述CenterNet网络包括图片输入层、骨干网络和三个卷积神经网络,RGB图片由图片输入层进入骨干网络中进行特征提取,得到特征图后,分别输入三个卷积神经网络中,分别得到热力图、中心点偏移量、目标的宽度和高度,由热力图得到中心点坐标,由此得到图片上各红绿灯的中心点位置和宽高。
进一步地,所述骨干网络为DLA-34网络,DLA-34网络的底层添加了跳转连接,并对每个卷积层替换为可变形卷积层的上采样阶段。
本发明使用RGB相机获取图像信息,采用基于中心点的检测网络CenterNet检测红绿灯位置信息;因网络CenterNet对红绿灯等小物体检测漏检少,但误检多,因此需要对检测到的红绿灯进行二分类,排除误检部分和没有指示灯显示的红绿灯,只保留正常显示的红绿灯;实际应用需要识别红绿灯箭头的方向,故进一步对红绿灯箭头实现多分类;且实际需要识别红绿灯颜色的状态,故进一步对红绿灯颜色实现多分类;同时设计开发以上用到的自定义分类器网络模型。
本发明采用CenterNet模型确保召回率减少漏检,同时响应快效率高,使用排除误检的自定义own分类器剔除误检的和无指示灯的,使用分类箭头方向的自定义own分类器得到指示灯方向信息,使用分类指示灯颜色的自定义own分类器得到指示灯颜色信息,很好地解决了因场景、光照等因素引起的漏检误检误识别,再结合硬件平台推理加速,实现了红绿灯的实时识别;从检测红绿灯位置信息、过滤误检目标、分类箭头方向、分类颜色等,采用多个网络模型分工合作,降低了因各种原因导致的误识别,提高了红绿灯识别的准确率及效率。
附图说明
图1为本发明的流程框架图。
图2为本发明的CenterNet网络框架图。
图3为本发明CenterNet中DLA-34骨干网络的结构图。
图4为本发明中自定义分类器的网络框架图。
具体实施方式
一种基于RGB室外道路场景图像的红绿灯识别方法,如图1,包括如下步骤:
S1、基于Nvidia Tx2平台,实时获取道路场景的RGB图片,对RGB图片进行归一化处理后,输入CenterNet网络中进行推理,得到各红绿灯的位置信息,所述红绿灯的位置信息包括各红绿灯的中心点坐标(在RGB图片中的坐标位置)、宽度和高度等;
道路场景的RGB实时图片可由RGB摄像头获得,得到的图片类型为RGB,当然也可以由其它类型的摄像头经过转换得到RGB图片。对RGB图片进行归一化处理主要是去除光照和阴影等的影响,归一化处理的方法可采用现有的技术,在此不赘述。
CenterNet网络是通过目标中心点来呈现目标,然后在中心点位置回归出目标的一些属性,例如size, dimension, 3D extent, orientation, pose,这样目标检测问题变成了一个标准的关键点估计问题。将图像传入全卷积网络,得到一个热力图,热力图峰值点即中心点,由每个特征图的峰值点位置预测目标的宽、高信息。模型训练采用标准的监督学习,推理仅仅是单个前向传播网络,不存在NMS这类后处理,故而处理速度快。
本发明通过CenterNet网络对输入的RGB图片进行推理,识别图片中的红绿灯,所述CenterNet网络包括图片输入层、骨干网络和三个卷积神经网络,其网络框架如图2所示,将RGB图片重定义尺寸后输入骨干网络中进行特征提取,得到特征图后,分别输入三个卷积神经网络中做三个卷积计算,分别得到热力图、中心点偏移量、目标的宽度和高度,由热力图得到中心点坐标,由此得到图片上各红绿灯的中心点位置和宽高。
CenterNet架构可采用常用的骨干网络,如Resnet-18、ResNet-101、DLA-34、Hourglass-104等。作为本发明的一种实施例,采用DLA-34为骨干网络的CenterNet网络,DLA-34网络的底层添加了跳转连接,并对每个卷积层替换为可变形卷积层的上采样阶段。DLA的结构能够迭代式地将网络结构的特征信息融合起来,让模型有更高的精度和更少的参数。本实施例中,如图3,CenterNet架构中的DLA-34骨干网络的底层添加了更多的跳转连接,并对每个卷积层替换为可变形卷积层的上采样阶段。采用全卷积上采样版的DLA,用deformable卷积来跳跃连接低层和输出层;将原来上采样层的卷积都替换成3*3的deformable卷积。在每个输出head前加了一个3*3*256的卷积,然后做1*1卷积得到期望输出。
本实施例中,图片重新调整的尺寸为512*512,由DLA-34得到的特征图的尺寸为128*128*256,预测热力图尺寸为128*128*80(表示80个类别),预测中心点偏移量尺寸为128*128*2(2表示x, y),预测宽度和高度尺寸为128*128*2(2表示宽度和高度)。
为提高识别效率,充分利用Nvidia TX2硬件平台性能,CenterNet网络推理的步骤包括:基于Nvidia TX2硬件平台,将Pytorch训练好的网络模型转换成ONNX模型,再将ONNX模型通过TensorRT生成TRT加速模型,推理时直接加载TRT加速模型,提高了红绿灯检测和分类的速度,达到实时识别的效果。
S2、依据上述步骤得到的各红绿灯的位置信息,从RGB原图像中抠取包含有红绿灯的目标区域,得到各个目标区域及其位置信息。由S1得到的各红绿灯的中心点位置、目标的宽度和高度值即可得到包含有红绿灯的各个目标区域(即CenterNet中的目标框),以及各个目标区域的位置信息。
由于由CenterNet网络对本申请的红绿灯等小物体进行目标检测时,漏检少,但误检多,因此需要对检测到的红绿灯目标区域进行二分类,进一步剔除误检的部分,其方法为:
S3、将步骤S2中得到的各目标区域依次输入排除误检的自定义分类器中,剔除目标区域为背景的目标区域(非红绿灯或关闭的红绿灯),保留目标区域为红绿灯正常显示的目标区域,并记录保留的各目标区域的位置信息,所述目标区域为背景的目标区域包括红绿灯关闭的目标区域。该分类器为一个二分类分类器。
由于在实际应用中需要识别红绿灯箭头的方向,因此需要进一步对红绿灯箭头实现多分类,其方法为:
S4、将步骤S3中保留的各目标区域依次输入分类箭头方向的自定义分类器中,剔除目标区域为背景的目标区域(非红绿灯,如非红绿灯的箭头或圆形),保留目标区域为向左箭头、向右箭头、向前箭头、掉头箭头或圆形指示灯的目标区域,并记录保留的各目标区域的位置信息和箭头方向信息。该分类器为一个多分类分类器。
由于实际应用中还需要识别红绿灯的实时颜色,因此需要进一步对红绿灯颜色实现多分类,其方法为:
S5、将步骤S4中保留的各目标区域依次输入分类指示灯颜色的自定义分类器中,剔除目标区域颜色为背景的目标区域(非红绿灯,如非红黄绿的其它颜色的箭头或圆形),保留目标区域为红色、黄色或绿色的目标区域,并记录保留的各目标区域的位置信息、箭头方向和颜色等。该分类器为一个多分类分类器。目标区域颜色为背景的目标区域,指有些目标区域中含有除红黄绿之外颜色的箭头、类似箭头或圆形,如蓝色的箭头、紫色的圆形等,这些非本发明所要识别的红绿灯,因此需剔除。
S6、将步骤S5中保留的各目标区域依次提取特征,得到RGB图片中能识别到的红绿灯信息,所述红绿灯信息包括各红绿灯在RGB图片中的位置信息、红绿灯的方向信息和红绿灯的颜色信息等,用作导航、无人驾驶或辅助驾驶之用。
上述排除误检的自定义分类器、分类箭头方向的自定义分类器、分类指示灯颜色的自定义分类器可采用现有的可实现对应功能的分类器,如最近邻分类器、朴素贝叶斯分类器、决策树、逻辑回归、神经网络等,将采集的样本分为训练样本和测试样本,在训练样本上执行分类器算法,生成分类模型;再将测试样本输入分类模型,生成预测结果;根据预测结果,评估分类模型的性能。
作为其中一些实施例,排除误检的自定义分类器、分类箭头方向的自定义分类器、分类指示灯颜色的自定义分类器采用卷积神经网络构造分类器,网络框架图可如图4所示,均包括输入层、隐藏层和输出层,每一层都有对应的神经网络与下一层连接,其中隐藏层中含有六层,数据由输入层输入,输入层主要用于获取输入的信息,隐藏层主要进行特征提取,输出层用于对接隐藏层并输出模型结果。各分类器具体描述如下:
所述S3步骤中排除误检的自定义分类器的网络模型包括输入层、隐藏层和输出层,分别如下:
输入层:网络模型需要训练和验证,故需要预先准备样本数据集,包括用于训练模型的训练样本数据集和用于测试模型的测试样本数据集。样本数据集由输入层输入,本发明中,输入的数据集为图片,并将输入的样本数据集中的图片重定义尺寸大小(可用resize函数)为1*3*48*48;其中,用于训练和测试的样本数据集有两类:0类仅包含正常显示的红绿灯图片,如正在显示前行的红绿灯图片、正在显示左转的红绿灯图片等,1类为与红绿灯类似的背景图片和指示灯关闭的红绿灯图片等,如路边的小灯笼、指示灯关闭的红绿灯等,用于训练排除误检的自定义own分类器;
隐藏层共有六层,分别为:
第一层:通过32*3*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0,下采样缩小一倍;
第二层:通过64*32*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0;
第三层:通过128*64*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0;
第四层:通过256*128*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0;
第五层:通过512*256*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为0,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射;
第六层:通过2*512*1*1的卷积进行分类,其卷积的步长为1、pad(边界补零)为0,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,得到最终分类结果;
输出层为二分类分类器,输出两个类别:0表示输入图片为背景(需剔除部分),1表示输入图片为红绿灯,可以根据分类器输出排除误检。
所述S4步骤中分类箭头方向的自定义分类器的网络模型包括输入层、隐藏层和输出层,分别如下:
输入层:同上,输入层输入样本数据集,并将输入的样本数据集中的图片重定义尺寸大小为1*3*48*48;其中,用于训练和测试的样本数据集有6类:0类为指示灯关闭的红绿灯图片,1类为箭头向左的红绿灯图片,2类为箭头向右的红绿灯图片,3类为箭头向前的红绿灯图片,4类为箭头方向为掉头的红绿灯图片,5类为指示灯为圆形的红绿灯图片,用于训练分类箭头方向的自定义own分类器;
隐藏层共有六层,分别为:
第一层:通过24*3*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0,下采样缩小一倍;
第二层:通过48*24*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0;
第三层:通过96*48*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0;
第四层:通过192*96*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0;
第五层:通过384*192*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为0,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射;
第六层:通过6*384*1*1的卷积进行分类,其卷积的步长为1、pad(边界补零)为0,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,得到最终分类结果;
输出层为多分类分类器,输出六个类别:0表示背景(需剔除部分),1表示向左箭头,2表示向右箭头,3表示向前箭头,4表示掉头箭头,5表示圆形指示灯,可以根据分类器输出分类箭头或指示灯的方向。
所述S5步骤中分类指示灯颜色的自定义分类器的网络模型包括输入层、隐藏层和输出层,分别如下:
输入层输入样本数据集,并将输入的样本数据集中的图片重定义尺寸大小为1*3*48*48;其中,用于训练和测试的样本数据集有4类:0类为指示灯颜色是背景色的红绿灯图片,1类为指示灯颜色是红色的红绿灯图片(包括箭头红绿灯和圆形红绿灯),2类为指示灯颜色是黄色的红绿灯图片(包括箭头红绿灯和圆形红绿灯),3类为指示灯颜色是绿色的红绿灯图片(包括箭头红绿灯和圆形红绿灯),用于训练分类指示灯颜色的自定义own分类器;
隐藏层共有六层,分别为:
第一层:通过24*3*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0,下采样缩小一倍;
第二层:通过48*24*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0;
第三层:通过96*48*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0;
第四层:通过192*96*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为1,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,通过2*2最大池化层过滤噪声和下采样,其池化的步长为2、pad(边界补零)为0;
第五层:通过384*192*3*3的卷积提取特征,其卷积的步长为1、pad(边界补零)为0,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射;
第六层:通过4*384*1*1的卷积进行分类,其卷积的步长为1、pad(边界补零)为0,再通过Batch Normalize归一化,通过Relu激活函数对特征进行非线性映射,得到最终分类结果;
输出层为多分类分类器,输出4个类别:0表示背景(需剔除部分),1表示红色,2表示黄色,3表示绿色,可以根据分类器输出分类指示灯颜色。
上列详细说明是针对本发明可行实施例的具体说明,该实施例并非用以限制本发明的专利范围,凡未脱离本发明所为的等效实施或变更,均应包含于本案的专利范围中。
- 一种基于RGB室外道路场景图像的红绿灯识别方法
- 一种基于RGB室外道路场景图像的红绿灯识别方法