大数据可视化方法及系统
文献发布时间:2023-06-19 10:48:02
技术领域
本发明属于大数据处理技术领域,具体地说,是涉及一种大数据可视化方法及系统。
背景技术
在大数据飞速发展的背景下,2020年全球数据总量将达到40ZB;中国大数据产业未来五年复合增长率约为27.29%。人类获取的80%以上的信息均来自于视觉系统,庞大且激增的数据量为大数据末端的可视化提出了更高的要求 。
目前大数据可视化主要应用于制造和自然资源、零售和销售贸易、运输、银行和证券、通讯媒体娱乐、医疗、教育、政府和保险等多个行业,特别是金融与互联网行业;经调研发现这些行业中,实现大数据可视化前端呈现对客户提出了极高的要求,普遍以定制化实现:需了解分析所需要的专业知识与算法模型、掌握与市场需求对应的解决方案、提供与行业以及后端数据库都匹配的特征数据等。
且由于大数据可视化方法行业针对性严重、业务场景拓展性差,现有大数据控屏展示软件缺乏数据化思维的弊端严重降低了用户的操作体验感。
发明内容
本发明的目的在于提供一种大数据可视化方法及系统,通过半自助绘制及编辑算法,在用户传输数据源后,根据需求生成所需目标统计字段,根据目标统计字段生成配置图标集合,基于对Echarts的封装,实现图形可操作化的目标配置图表集,解决了现有大数据可视化需定制,用户体验感低的技术问题。
本发明采用以下技术方案予以实现:
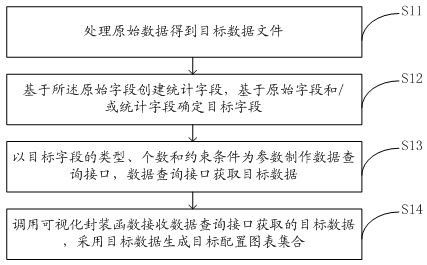
提出一种大数据可视化方法,包括:处理原始数据得到目标数据文件;所述目标数据文件包含原始字段;基于所述原始字段创建统计字段;基于所述原始字段和/或所述统计字段确定目标字段;以所述目标字段的类型、个数和约束条件为参数制作数据查询接口,所述数据查询接口获取目标数据;调用可视化封装函数接收所述数据查询接口获取的目标数据,并基于所述目标数据生成目标配置图表集合。
提出一种大数据可视化系统,包括:原始数据处理模块,用于处理原始数据得到目标数据文件;所述目标数据文件包含原始字段;统计字段创建模块,用于基于所述原始字段创建统计字段;目标字段确定模块,用于基于所述原始字段和/或所述统计字段确定目标字段;目标数据查询模块,用于以所述目标字段的类型、个数和约束条件为参数制作数据查询接口,所述数据查询接口获取目标数据;目标配置图表生成模块,用于调用可视化封装函数接收所述数据查询接口获取的目标数据,并基于所述目标数据生成目标配置图表集合。
与现有技术相比,本发明的优点和积极效果是:本发明提出的大数据可视化方法及系统中,将实时数据文件或离线数据文件进行处理得到包含原始字段的目标数据文件,根据目标配置图表的要求对原始字段采用Map-Reduce算法创建出符合用户需求的新的统计字段,进而用户可从新的统计字段和/或原始字段中选择目标统计字段,系统则基于目标统计字段的类型、个数、约束条件和设定的统计类型创建数据查询接口,从数据库获取目标数据,并传送给可视化封装函数,可视化封装函数则基于目标数据生成目标配置图表集合;基于本发明提出的大数据可视化方法及系统,在实现大数据可视化同时,通过半自助绘制及编辑的方式,解决了现有大数据可视化需定制的技术问题,提高了用户体验感。
结合附图阅读本发明实施方式的详细描述后,本发明的其他特点和优点将变得更加清楚。
附图说明
图1 为本发明提出的大数据可视化方法的流程图;
图2为本发明提出的大数据可视化系统的架构图;
图3为本发明提出的大数据可视化系统实现大数据可视化的示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步详细的说明。
本发明旨在聚焦于灵活性更高、延展性更强的算法优先模式,以半自助绘制及编辑的方式,在用户传输数据源后,可根据自身需求制定目标配置图表的内容以及可视化方式,生成用户专属配置文档,无需定制,不受业务场景限制,解决现有大数据可视化需定制、用户体验感低的问题。
结合图1和图3所示,本发明提出的大数据可视化方法,包括如下步骤:
步骤S11:处理原始数据得到目标数据文件。
原始数据的来源包括用户上传的数据文件,以及从指定数据库读取的数据文件。用户从云服务器或本地上传原始数据文档,例如如Txt文件、xlsx格式文档(Excel文件)、sav格式文档(SPSS文件)等。
对于原始数据首先解决数据源切割问题,对于Excel文件和Spss文件,可以通过读取数据所属单元格行列属性进行切割,对于Txt文件,可以用“;”或分行符等作为行分隔符,用空格等作为列分隔符进行切割,切割后的数据文件作为用户上传的目标数据文件,该目标数据文件中主要包含切割后的原始字段以及其他表征原始字段特征的信息等。
在本发明实施例中,通过可视化应用界面,用户可以预览切割后的原始字段,并进行二次编辑,完成增删数据或字段、编辑字段名称、编辑字段格式(例如文本格式、数据格式或时间格式等),编辑后的原始数据集将存储于数据库中,用于后续建立用户配置文件操作。
以XX市出租车轨迹数据文本文件为例,对于列来说,第一列是Id号,第二列是经度,其他列是车牌号、时间等,每一个字段是每一列,相当于文本文件的列是按照字段分割(列分隔符),对每一行,在行的末尾处的分隔符是行分割符,比如逗号,空格,在本发明实施例中,提供输入方式,由用户在可视化应用界面输入行列分隔符确保对文本文件准确分割;同时用户输入这些字段代表的含义及数据类型,不同的数据类型需要的查询、统计方式是不同的,经纬度可能是字符或数字,而时间就是数字。
步骤S12:基于所述原始字段创建统计字段,基于原始字段和/或统计字段确定目标字段。
在本发明一些实施例中,用户可通过可视化应用界面对原始字段进行选择确定目标字段,例如上述出租车轨迹数据中,用户可选择车牌号作为目标字段。
在本发明优选实施例中,可基于目标配置图表的要求采用Map-Reduce算法创建新的统计字段;如通过机器学习算法得到聚类求和字段或通过统计学方法得到方差、均值、离散系统、偏态系数、峰态系数等字段,使得用户可以从新的统计字段和/或原始字段中选择确定目标字段。
在具体的实施例中,可在可视化应用界面为用户提供输入设定的统计类型的控件,使得用户可以基于目标配置图表的需求,从设定的统计类型中进行选择,以得到更贴合于用户需求的统计字段。
在本发明实施例中,设定的统计类型包括目标字段属性列举和目标字段的聚合函数分析。其中,目标字段属性列举例如统计所选字段属性值、统计与所选字段属性值的相同字段等,目标字段的聚合函数分析例如输出所选字段所有内容、计算所选字段属性值的和、计算所选字段属性值的平均值、计算所选字段属性值的最大值、计算所选字段属性值的最小值等。
在用户选择了统计类型后,根据统计类型采用Map-Reduce算法创建统计字段。
在本发明的实施例中,原始数据包括实时数据和离线数据;对于实时数据,本发明实施例采用如下方式实现统计字段的输出:将实时数据文件传入Kalfka流存储器中,考虑到Spark相对于Map-Reduce更快的速度与更高的容错率,采用Spark引擎、基于Map-Reduce算法创建新的统计字段并存储于数据库中,系统前端则通过访问数据库调用统计字段来实现相应配置图表的显示。
对于离线数据,本发明实施例采用如下方式实现统计字段的输出:将离线数据文件存储至HDFS中,包含数据库表以及日志文本数据等,对于日志文本采用Map-Reduce进行处理,并将处理后数据通过Sqoop数据传递工具转化数据格式后存储至Hive数据仓库中,利用查询语句通过Map-Reduce算法创建新的统计字段并存储于数据库中,系统前端则通过访问数据库调用统计字段来实现相应配置图表的显示。
具体的系统前端访问数据库调用统计字段来实现相应配置图表的显示步骤将在下述内容中给出。
步骤S13:以目标字段的类型、个数和约束条件为参数制作数据查询接口,数据查询接口获取目标数据。
用户通过可视化应用界面从原始字段和/或统计字段中选择或输入目标字段,比如时间、经纬度等,并输入约束条件,该约束条件比如要求筛选19年5月20日13点39在运行的所有出租车的车牌号及经纬度等。
系统以目标字段的类型、个数和约束条件生成数据查询接口,该数据查询接口用于对数据库中调用目标数据的方式进行同一规范,封装后根据用户输入的目标字段从数据库抓取目标数据。
步骤S14:调用可视化封装函数接收数据查询接口获取的目标数据,采用目标数据生成目标配置图表集合。
数据查询接口与可视化封装函数衔接,接收数据查询接口获取的目标数据。
本发明实施例中,为了让用户上传数据类型与用户选择功能所需要的数据模式更匹配,基于JSP技术对Echarts生成的配置图表进行二次封装生成可视化封装函数,进而调用该可视化封装函数采用目标数据生成用户所需的图表集合。
在本发明一些实施例中,用户也可以通过查看图表与字段的对应关系继续编辑数据文件,用户可从目标配置图表集合内选择配置图表,并对选择的配置图表进行编辑,包含但不限定于:编辑图表样式、修改图表标题、修改数据标签、颜色、尺寸等、修改图表图例等,最终得到一个用户专属的配置图表;重复上述操作后,可以得到最终的配置图表结果集。
为提升用户前端操作体验,在本发明一些实施例中,还根据目标字段的内容提供可编辑的功能型图表供用户配置,例如图片说明型图表、文本说明型图标、字段筛选型图标和/或字段查询型图标;其中,文本说明型图表可以作为标题或说明内容去美化页面布局并起到配置图表的功能、内容解释说明的作用;字段筛选型图表和字段查询型图标与配置图表关联实现数据交互,提供图表交互功能,提高用户操作体验感。
在本发明一些实施例中,集合所有目标配置图表和功能型图表形成仪表盘,仪表盘作为各图表的载体,各目标配置图表和功能型图表可在仪表盘内拖拽、调整尺寸并进行图表间的关联。
基于上述提出的大数据可视化方法,本发明还提出一种大数据可视化系统,如图2所示,包括原始数据处理模块21、统计字段创建模块22、目标字段确定模块23、目标数据查询模块24和目标配置图表生成模块25。
原始数据处理模块21用于处理原始数据得到目标数据文件,该目标数据文件包含原始字段;统计字段创建模块22用于基于原始字段创建统计字段;目标字段确定模块23用于基于原始字段和/或统计字段确定目标字段;目标数据查询模块24用于以目标字段的类型、个数和约束条件为参数制作数据查询接口,数据查询接口获取目标数据;目标配置图表生成模块25用于调用可视化封装函数接收数据查询接口获取的目标数据,并基于目标数据生成目标配置图表集合。。
在本发明一些实施例中,统计字段确定模块22包括Map-Reduce算法执行单元221,用于基于目标配置图表的要求采用Map-Reduce算法创建统计字段。
在本发明一些实施例中,统计字段创建模块22还包括统计类型设定单元222和统计类型选择单元223;统计类型设定单元222用于设定统计类型;其中,设定的统计类型包括目标字段属性列举和目标字段的聚合函数分析;统计类型选择单元223基于目标配置图表的要求对设定的统计类型进行选择;则Map-Reduce算法执行单元221用于根据选择的统计类型采用Map-Reduce算法创建统计字段。
在本发明实施例中,原始数据包括实时数据和离线数据;则统计字段创建模块22还包括实时数据处理单元224和离线数据处理单元225;其中,实时数据处理单元224用于将实时数据文件传入Kalfka流存储器中,采用Spark引擎、基于Map-Reduce算法创建统计字段并存储于数据库中;离线数据处理单元225用于将离线数据文件存储至HDFS中,采用Map-Reduce进行处理,并将处理后数据通过Sqoop数据传递工具转化数据格式后存储至Hive数据仓库中,利用查询语句通过Map-Reduce算法创建统计字段并存储于数据库中。
在本发明一些实施例中,提出的大数据可视化系统还包括目标配置图表编辑模块26,和/或,功能型图标配置模块27和关联模块28;目标配置图表编辑模块26用于对目标配置图表集合内的配置图表进行编辑得到配置图表结果集;功能型图表配置模块27用于根据目标字段的内容,提供可编辑的图片说明型图表、文本说明型图标、字段筛选型图标和/或字段查询型图标;关联模块28用于将字段筛选型图表和字段查询型图标与配置图表关联以实现数据交互。
具体的大数据可视化系统实现可视化的方法已经在上述的大数据可视化方法中详述,此处不予赘述。
上述本发明提出的大数据可视化方法及系统,在实现大数据可视化后,还可通过创建数据接口的方式实现大屏小屏互动,将上述大数据可视化系统在大屏和小屏之间实现数据和控制上的互联,同步在大屏和小屏上实现对配置图表的编辑、仪表盘的编辑等,对于实现的技术手段本发明不予具体限定。
上述本发明提出的大数据可视化方法及系统,提出一种“用算法普适化打破系统定制化”的思想,破除了行业内定制化思维,聚焦于灵活性更高、延展性更强的算法优先模式,通过半自助半编辑算法,提供用户自主配置,自主定制服务,以多风格按需展示,解决了现有大数据可视化需定制,用户体验感低的技术问题。
应该指出的是,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的普通技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 一种投资组合的大数据可视化系统与方法
- 大数据可视化展示的方法、系统、电子装置和存储介质