一种基于车联网下驾驶行为分析方法
文献发布时间:2023-06-19 10:54:12
技术领域
本发明涉及交通安全技术领域,具体的说是一种基于车联网下驾驶行为分析方法。
背景技术
随着我国车辆的保有量不断增加,给交通安全和社会带了一系列的问题。车联网和管理部门对驾驶安全的关注度也越来越高。而车联网技术的是解决这些问题的有效途径。车联网系统,是指利用先进传感技术、网络技术、计算技术、控制技术、智能技术,对道路和交通进行全面感知,实现多个系统间大范围、大容量数据的交互,对每一辆汽车进行交通全程控制,对每一条道路进行交通全时空控制,以提供交通效率和交通安全为主的网络与应用。
在车联网环境下有着海量数据,这样对挖掘分析车辆驾驶行为、特征有着特殊的意义与价值。通过挖掘车辆速度、急加速等行驶数据有助于研究车辆驾驶人员的驾驶行为,有利于规范驾驶人员的驾驶行为,同时可优化和提升对车辆的智能化管理。但目前仍缺少如何提取和利用这些行驶数据,来规范车辆驾驶人员的驾驶行为。
发明内容
本发明的目的在于提供一种基于车联网下驾驶行为分析方法,该基于车联网下驾驶行为分析方法可通过挖掘车辆速度、急加速等行驶数据分析车辆驾驶人员的驾驶行为,有利于规范驾驶人员的驾驶行为,同时优化和提升对车辆的智能化管理。
为实现上述目的,本发明采用以下技术方案:
一种基于车联网下驾驶行为分析方法,包括如下步骤:
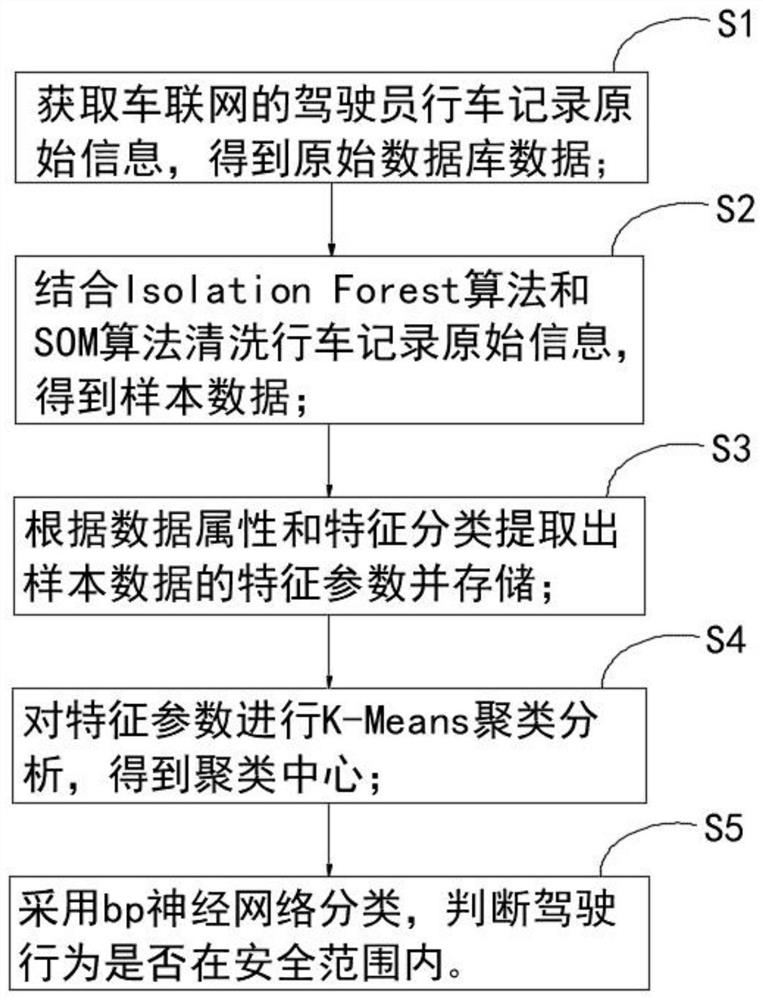
S1:获取车联网的驾驶员行车记录原始信息,得到原始数据库数据;
S2:结合Isolation Forest算法和SOM算法清洗行车记录原始信息,得到样本数据;
S3:根据数据属性和特征分类提取出样本数据的特征参数并存储;
S4:对特征参数进行K-Means聚类分析,得到聚类中心;
S5:采用bp神经网络分类,判断驾驶行为是否在安全范围内。
优选地,步骤S2的具体方法为:
S21:采用IsolationForest算法从训练数据中随机选择样本点作为subsample,放入树的根节点;
S22:随机指定一个维度attribute,在当前节点数据中随机产生一个切割点p,切割点p产生于当前节点数据中指定维度的最大值和最小值之间;
S23:以切割点p生成一个超平面,再将当前节点数据空间划分为2个子空间:把指定维度里小于切割点p的数据放在当前节点的左孩子,把大于等于切割点p的数据放在当前节点的右孩子;
S24:在孩子节点中递归步骤S22和S23,不断构造新的孩子节点,直到孩子节点中只有一个无法再继续切割的数据或孩子节点已到达限定高度,并获得t个iTree,iForest训练结束;
S25:用生成的iForest评估测试数据,将异常数据剔除后,得到初筛数据并存储至数据库;
S26:采用SOM算法对初筛数据进行二次筛选和异常数据清理,若无异常数据,则输出正常数据并存储至数据库;若仍存在异常数据,则重复执行步骤S21至S26,直至异常数据被完全剔除。
优选地,步骤S25中所述iForest评估测试数据的具体方法为:
S251:将各个测试数据分别遍历每一棵iTree;
S252:计算各个测试数据最终落在各棵树的层数,并分别计算各个测试数据在森林中的高度平均值;
S253:获得每个测试数据的平均路径长度,其中平均路径长度低于阈值的测试数据为异常数据,并将异常数据剔除。
优选地,步骤S26输出的正常数据还经过冗余检查处理,所述冗余检查处理的具体方法为:Python数据清洗使用duplicated方法对正常数据作重复性判断,返回一个与原数据行数相同的序列,若数据行没有重复,则对应false,否则对应true;再使用any方法,序列中只要存在一个true,则返回true再次清理。
优选地,所述冗余检查处理后的正常数据还经过数据修正,所述数据修正包括数据缺失补充、数据混乱修正和数据重复删除,最终得到健壮可行的样本数据。
优选地,步骤S3的特征参数包括疲劳驾驶、超速、急加速和急减速的占比、急变道;
所述疲劳驾驶以车载终端中采集的时间序列数据分析,根据数据特征,将车辆的在途时间分为行驶时间和停止时间,分段区间分析,如果司机连续行驶4个小时,没有停车休息20分钟或以上,由此判定当天的疲劳驾驶次数增加1次;
所述超速根据不同车型、高速的速度限制,如果超出交规规定10%的比例,按超速处理;
所述急加速和急减速的占比先求每辆车的急加速和急减速次数,再除以车辆的数据量得到百分比;
所述急变道车辆变道时间在总体上固定,最小变道持续时间为1.0s,最大的变道持续时间为16.5s,在此范围内表示车辆在较稳定状态行驶。
优选地,步骤S4的K-Means聚类方法具体为:
S41:确定一个k值,将样本数据经过聚类方法得到k个集合;
S42:从样本数据中随机选择k个数据点作为质心;
S43:对样本数据中每一个点,计算点与每一个质心的距离,离哪个质心近,就将该点划分到那个质心所属的集合;
S44:把所有样本数据归好集合后,共有k个集合,再重新计算每个集合的质心,重复执行步骤S41至S43;
S45:直至新计算出来的质心和原来的质心之间的距离小于阈值,则聚类已经达到期望的结果,算法终止。
优选地,步骤S5中所述bp神经网络由输入层、隐含层和输出层组成;步骤S5的具体方法为:
S51:以急加速、急减速、超速、急变道和疲劳驾驶5个标签维度作为输入,输入对应的特征向量;所述隐含层由10个神经元组成;所述输出层对应分类的结果,分类的结果为驾驶员对应的类别;
S52:将典型的样本聚类结果归一化作为训练样本,将样本数据进行分配,设置最大训练次数和目标误差,以此来训练bp神经网络,得到驾驶员驾驶行为的bp神经网络分类器,再以bp神经网络分类器来判断驾驶行为是否安全。
优选地,步骤S52中所述bp神经网络的训练参数为:将样本数据按8:2分配,设置最大训练次数5000,目标误差为0.001。
采用上述技术方案后,本发明具有如下有益效果:
本发明一种基于车联网下驾驶行为分析方法,以车联网数据为基础,使用IsolationForest算法能快速、有效进行异常检值的筛查和剔除,再结合SOM算法可视化进行修正和补充,可通过两种算法的交叉配合清洗原始数据,以精确有效的将异常值剔除,并筛选出正常的可用的样本数据,可通过挖掘疲劳驾驶、超速、急加速和急减速的占比、急变道等行驶数据分析车辆驾驶人员的驾驶行为,有利于规范驾驶人员的驾驶行为,同时优化和提升对车辆的智能化管理。
附图说明
图1为本发明的流程框图;
图2为本发明步骤S2的具体方法的流程框图;
图3为本发明步骤S25中iForest评估测试数据的具体方法的流程框图;
图4为本发明的行车记录原始信息的清洗流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例
请参阅图1至图4,一种基于车联网下驾驶行为分析方法,包括如下步骤:
S1:获取车联网的驾驶员行车记录原始信息,得到原始数据库数据;
S2:结合Isolation Forest算法和SOM算法清洗行车记录原始信息,得到样本数据;
步骤S2的具体方法为:
S21:采用IsolationForest算法从训练数据中随机选择样本点作为subsample,放入树的根节点;IsolationForest是一种高效的异常检测算法,如果一些数据指标很快就到达了叶子节点,即叶子到根的距离d很短,那么就被认为很有可能是异常点;
S22:随机指定一个维度attribute,在当前节点数据中随机产生一个切割点p,切割点p产生于当前节点数据中指定维度的最大值和最小值之间;
S23:以切割点p生成一个超平面,再将当前节点数据空间划分为2个子空间:把指定维度里小于切割点p的数据放在当前节点的左孩子,把大于等于切割点p的数据放在当前节点的右孩子;
S24:在孩子节点中递归步骤S22和S23,不断构造新的孩子节点,直到孩子节点中只有一个无法再继续切割的数据或孩子节点已到达限定高度,并获得t个iTree,iForest训练结束;
S25:用生成的iForest评估测试数据,将异常数据剔除后,得到初筛数据并存储至数据库;
步骤S25中所述iForest评估测试数据的具体方法为:
S251:将各个测试数据分别遍历每一棵iTree;
S252:计算各个测试数据最终落在各棵树的层数,即该层数为测试数据在树的高度,并分别计算各个测试数据在森林中的高度平均值;
S253:获得每个测试数据的平均路径长度,其中平均路径长度低于阈值的测试数据为异常数据,并将异常数据剔除;
S26:采用SOM算法对初筛数据进行二次筛选和异常数据清理,若无异常数据,则输出正常数据并存储至数据库;若仍存在异常数据,则重复执行步骤S21至S26,直至异常数据被完全剔除;
步骤S26输出的正常数据还经过冗余检查处理,所述冗余检查处理的具体方法为:Python数据清洗使用duplicated方法对正常数据作重复性判断,返回一个与原数据行数相同的序列,若数据行没有重复,则对应false,否则对应true;再使用any方法,序列中只要存在一个true,则返回true再次清理;
所述冗余检查处理后的正常数据还经过数据修正,所述数据修正包括数据缺失补充、数据混乱修正和数据重复删除,最终得到健壮可行的样本数据;
S3:根据数据属性和特征分类提取出样本数据的特征参数并存储;
步骤S3的特征参数包括疲劳驾驶、超速、急加速和急减速的占比、急变道;
所述疲劳驾驶以车载终端中采集的时间序列数据分析,根据数据特征,将车辆的在途时间分为行驶时间和停止时间,分段区间分析,如果司机连续行驶4个小时,没有停车休息20分钟或以上,由此判定当天的疲劳驾驶次数增加1次;
所述超速根据不同车型、高速的速度限制,如果超出交规规定10%的比例,按超速处理;
所述急加速和急减速的占比先求每辆车的急加速和急减速次数,再除以车辆的数据量得到百分比;
所述急变道车辆变道时间在总体上固定,最小变道持续时间为1.0s,最大的变道持续时间为16.5s,在此范围内表示车辆在较稳定状态行驶;
S4:对特征参数进行K-Means聚类分析,得到聚类中心;
步骤S4的K-Means聚类方法具体为:
S41:确定一个k值,将样本数据经过聚类方法得到k个集合;
S42:从样本数据中随机选择k个数据点作为质心;
S43:对样本数据中每一个点,计算点与每一个质心的距离,离哪个质心近,就将该点划分到那个质心所属的集合;
S44:把所有样本数据归好集合后,共有k个集合,再重新计算每个集合的质心,重复执行步骤S41至S43;
S45:直至新计算出来的质心和原来的质心之间的距离小于阈值,则聚类已经达到期望的结果,算法终止
S5:采用bp神经网络分类,判断驾驶行为是否在安全范围内;
步骤S5中所述bp神经网络由输入层、隐含层和输出层组成;步骤S5的具体方法为:
S51:以急加速、急减速、超速、急变道和疲劳驾驶5个标签维度作为输入,输入对应的特征向量;所述隐含层由10个神经元组成;所述输出层对应分类的结果,分类的结果为驾驶员对应的类别;
S52:将典型的样本聚类结果归一化作为训练样本,将样本数据按8:2分配,设置最大训练次数5000,目标误差为0.001,以此来训练bp神经网络,得到驾驶员驾驶行为的bp神经网络分类器,再以bp神经网络分类器来判断驾驶行为是否安全。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 一种基于车联网下驾驶行为分析方法
- 一种基于车联网的危险驾驶行为检测方法