一种基于深度学习的空间车位检测方法
文献发布时间:2023-06-19 10:54:12
技术领域
本发明属于智能汽车电子领域,特别涉及一种基于深度学习的空间车位检测方法。
背景技术
随着深度学习的飞速发展,尤其是在图像处理领域,取得了巨大的成功。越来越多的领域开始引入深度学习,而智能驾驶领域也不例外。深度学习广泛应用于环境感知,运动计划和智能驾驶控制决策的各个模块中,尤其是在环境感知中。
作为智能驾驶环境感知的重要组成部分,许多研究人员还使用深度学习对停车位检测进行了研究。目前,深度学习用于停车位检测,主要分为两类:基于目标检测的停车位检测和基于语义分割的停车位检测。
在基于目标检测的停车位检测方面,Lin Z等人提出了一种基于深度卷积神经网络DCNN的停车位检测方法DeepPS,此方法将全景环绕视图作为输入来检测输入图像并对所有标记点和由标记点形成的部分图像图案进行分类以检测停车位(Lin Z,Junhao H,Xiyuan Li,et al.Vision-Based Parking-Slot Detection:A DCNN-Based Approach anda Large-Scale Benchmark Dataset[J].IEEE Transactions on Image Processing,2018,27(11):5350-5364)。Zinelli等人提出了一种基于Faster R-CNN的端到端神经网络,以实现全景停车位的分类和检测(Zinelli A,Musto L,Pizzati F.A Deep-LearningApproach for Parking Slot Detection on Surround-View Images[C]//2019IEEEIntelligent Vehicles Symposium(IV),IEEE,2019:683-688.)。Yamamoto等人构造了一个卷积神经网络YOLO来检测停车位,以及一个CNN系统对停车位的几种模式进行分类,并通过仿真验证了其可行性(Yamamoto K,Watanabe K,Nagai I,Proposal of an EnvironmentalRecognition Method for Automatic Parking by an Image-based CNN[C]//2019IEEEInternational Conference on Mechatronics and Automation(ICMA),IEEE,2019:833-838)。
在基于语义分割的停车位检测方面,Wu等人提出了一种高度融合的卷积网络HFCN,以在分割停车位标记线时实现良好的性能(Wu Y,Yang T,Zhao J,et al.VH-HFCNbase Parking Slot and Lane Markings Segmentation on Panoramic Surround View[C]//2018IEEE Intelligent Vehicles Symposium(IV).IEEE,2018)。Jiang等人提出了一种基于深度学习的DFNet算法,并利用语义分割对全景停车位进行了分割,然后对停车位进行了检测,并对全景数据集进行了该方法,评估取得了良好的效果(Jiang W,Wu Y,Guan L,et al,DFNet:Semantic Segmentation on Panoramic Images with Dynamic LossWeights and Residual Fusion Block[C]//2019International Conference onRobotics and Automation(ICRA),2019:5887-5892.)。Jang等人提出了一种用于停车位标记线识别的语义分割模型,该模型可以同时检测带有停车位标记的空车位和由周围的静态障碍物产生的空车位,而无需传感器融合(Jang C,Sunwoo M.Semantic segmentation-based parking space detection with standalone around view monitoring system[J].Machine Vision and Applications,2019,30(2):309-319.)。
但之前的停车位检测大多依赖于超声波传感器与毫米波雷达进行多传感器融合,对硬件以及信息融合方面的要求很高,尽管停车位检测的准确率非常高但是成本高且更加耗时难以达到实时性。直到近一两年才开始流行依赖纯视觉的深度学习方法,然而仍处于起步阶段,大多数方法的识别精度和速度都有待改善。本发明旨在通过改进深度学习语义分割的模型来改善分割效果,同时设计了一种新的后处理方式即基于垂直网格搜索的方法来更为准确地推断车位。
发明内容
本发明的目的在于克服现有技术的不足之处,在停车位的视觉检测中提供了一种基于深度学习的空间车位检测方法。
为实现本发明目的,本发明提供一种基于深度学习的空间车位检测方法,包括步骤:
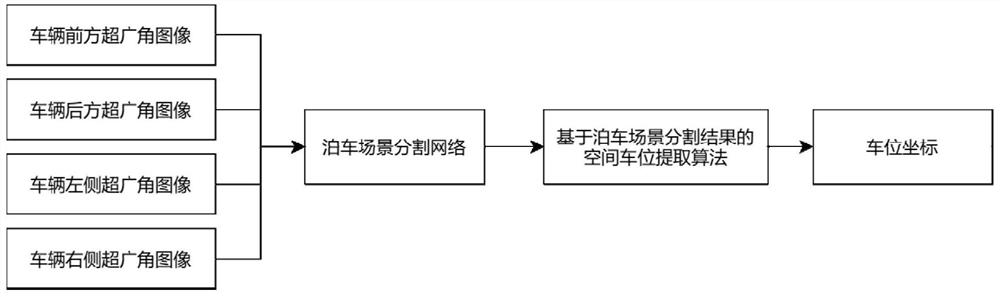
S1、通过摄像头拍摄采集车辆四周的图像,并进行畸变矫正,得到未失真图像;
S2、将所述未失真图像输入到深度学习训练的泊车场景语义分割网络,得到图像的泊车场景语义分割结果图;
S3、在语义分割结果图上通过图像处理和逻辑处理得到车位线,并映射回原图中,由此检测出车位位置。
优选的,步骤S2中,深度学习训练的泊车场景语义分割网络包括构建的带标注的车辆泊车场景图像数据集,泊车场景图像的每个像素标注为可行驶区域、车位标记线、车辆和其他物体4类。
优选的,步骤S2中,泊车场景语义分割网络为以DeepLab V3+为基础改进的神经网络,其骨干网络为ResNet50。
优选的,对DeepLab V3+的改进方式为:把解码阶段第2次4倍的上采样拆分为2次2倍的上采样,即总共有3次上采样操作;在编码阶段的第1次下采样后的信息与解码阶段第2次上采样的信息融合,之后进行第3次上采样得到输出图像。
优选的,步骤S3中得到车位线后,通过所述车位线得到车位的4个角点坐标,并将车位的角点坐标一并映射回原图。在获得车位线后,获得车位的角点坐标,并将角点坐标映射回原图,以得到角点的位置,所得到的角点位置可以作为后续自动泊车执行机构的输入。
优选的,步骤S3中所述通过图像处理和逻辑处理得到车位线,具体包括:对语义分割结果图进行独热编码;对语义分割结果图进行网格搜索;对车位标记线进行像素融合;利用约束条件对检测到的标记线配对成组,以获得车位线。
优选的,在配对成组后,还包括步骤:对配对成组后的结果进行微调优化,当未检测到标记线但是检测到车辆时,如果车辆之间的空间满足泊车的需求,那么将检测到的车辆边界用来取代未检测到的标记线,标记为车位线。
优选的,在进行微调优化,得到最终的车位线后,还包括步骤:对得到的车位线以及车位线的角点位置进行标注。
优选的,所述约束条件包括:两个连续的停车位的标记线之间的区域不能包含车辆或其他障碍物;两条标记线之间的距离必须达到停车位的大小。
优选的,在非结构化道路条件下,车位标记线像素数P无法达到阈值时,此时依据车辆、可行使区域、其他物体来确定车位。
与现有技术相比,本发明能够实现的有益效果至少如下:
(1)本发明仅需要车辆周围视野监控系统的图像输入即可完成停车位检测,并且不依赖于其他诸如超声波传感器、毫米波雷达和其他传感器数据。
(2)本发明不仅可以检测在车位标记线下的停车位,而且可以检测被车辆等静态物体包围的空的停车位。
(3)本发明使用的语义分割模型具有较高的准确性和鲁棒性。
附图说明
图1为本发明的方案流程图。
图2为原始DeepLab V3+的编码-解码结构以及本发明中对DeepLab V3+的编码-解码结构所作的改动。
图3为本发明的语义分割模型框架图。
图4为原始图像分别经过语义分割处理和垂直网格搜索后的结果图。
图5为本发明针对车位线模糊不清等极端场景的检测结果图。
具体实施方式
为了便于理解,下面结合附图和实施例来对本发明做进一步说明。
本实施例提供的一种基于深度学习的空间车位检测方法,过程中使用的算法主要由语义分割网络和网格搜索后处理推断所组成。先将环视图像作为语义分割网络的输入,可以获取四类对象的分割结果。然后在分割图的基础上采用网格搜索法来推断车位,包括确定成组的车位线以及得到车位的4个角点坐标,并映射回原图中,由此检测出车位位置。具体包括以下步骤:
步骤S1、通过摄像头拍摄采集车辆四周的图像,并进行畸变矫正,得到未失真图像。
通过车载的前后左右4个鱼眼摄像头拍摄采集获得四幅超广角图像,根据该四幅超广角图像生成全景环视图像,对全景环视图像进行畸变矫正后输入语义分割网络。
步骤S2、将步骤S1得到的未失真图像输入到深度学习训练的泊车场景语义分割网络,得到图像的泊车场景语义分割结果图。
基于语义分割的模型非常多,包括FCN、Mask-RCNN、DeepLab系列等,其中最新最前沿的便是DeepLab V3+。本实施例采用的正是DeepLab V3+作为语义分割网络的基础,同时鉴于原始网络中的骨干网络使用的Xception引入的计算量和复杂度较大,对计算平台的要求较高,这里使用了更轻量化的ResNet50模型来替代原始的Xception作为DeepLab V3+的骨干网络,进一步提高了语义分割网络的运行速度。
在语义分割模型中,针对车位线这种细小物体的分割检测,本实施例还对DeepLabV3+原始的采样方式进行了改进。如图2中的左图所示,在原始模型中的编码阶段依次使用了4次2倍的下采样,然后在解码阶段依次经过2次4倍的上采样得到输出结果,其中第1次上采样后的信息与编码阶段第2次下采样后的信息进行融合后才进行第2次上采样。这样的方式对小物体的识别缺乏一定的准确性,因此,如图2的右图所示,本实施例做出以下改进:首先把解码阶段第2次4倍的上采样拆分为2次2倍的上采样,即总共变为了3次上采样。然后在编码阶段的第1次下采样后的信息与解码阶段第2次上采样的信息融合,之后进行第3次上采样得到输出图像。改进之后的好处在于充分利用到了浅层信息而不是丢弃,从而更好地获取车位线的空间信息。
改进完毕的语义分割网络如图3所示。整个网络分为编码与解码两部分。编码阶段采用ResNet50作骨干网络来提取特征,并分别输出2倍、4倍、16倍下采样后的特征图。其中得到的16倍下采样特征图后进行ASPP多孔空间金字塔池化处理,具体包括1×1卷积、3次3×3空洞卷积和池化处理。解码阶段对ASPP处理的特征图进行4倍上采样,并与编码阶段输出的4倍下采样后的特征图进行通道拼接融合,随后经过3×3卷积操作实现2倍上采样;其结果再与编码阶段输出的2倍下采样后的特征图进行通道拼接融合,最后经过3×3卷积和2倍上采样,即可输出预测结果。
进行深度网络训练需要大量的数据来供神经网络学习。本实施例使用公开的开源数据集来训练,其中标注部分为可行驶区域、车位标记线、车辆和其他物体4类对象,分别用蓝色、白色、黑色和红色来显示其轮廓。还包括对数据集进行数据增强,利用图像旋转、变形、翻转和缩放等方式扩充了数据,有利于神经网络更好地学习特征。
在训练模型时,还需要对损失函数进行定义。鉴于在一幅图中所需要的可行驶区域、车位标记线、车辆和其他物体这4类对象的占比不均衡的问题,本实施例选用动态损失函数。在训练过程中,对于每个迭代周期,依据不同的小批次来计算每一类别的损失权重。计算公式如下:
其中,w
经过训练得到最终的泊车场景语义分割网络。将步骤1得到的图像输入训练后得到的泊车场景语义分割网络中,可以得到图像的泊车场景语义分割结果图,在语义分割结果图中可以将可行驶区域、车位标记线、车辆和其他物体分别识别出来。
本实施例得到的语义分割结果图是一个尺度为W*H*C的三维向量,H、W分别为语义分割结果图的长和宽,C为通道数且恒为5,因为包含背景与4种需要分割的前景对象。
步骤S3、在语义分割结果图上通过图像处理和逻辑处理得到车位线,通过所述车位线得到车位的4个角点坐标,并映射回原图中,由此检测出车位位置。
本步骤中具体包括:
第一,对语义分割结果图进行one-hot独热编码以方便后续的检测处理,其结果为二维矩阵W*H,并对背景和四种对象进行类型编号,本实施例中采用0、1、2、3、4五个值分别代表背景、可行驶区域、车位标记线、车辆和其他物体;
第二,利用宽度和长度为w*h的垂直网格从左到右进行逐像素搜索,当当前搜索网格和预设网格的IOU大于给定阈值时就记录当前网格的中心坐标;
第三,因为标记线存在一定宽度,即在不同的搜索网格中可能搜索到同一条标记线,因此需要对车位标记线进行像素融合,来处理多个网格搜索到同一标记线的问题,具体做法为,把第二步得到的各个网格的中心坐标从左至右连续地融合即为具有一定宽度的车位线的区域,从而实现像素融合。
第四,只有成对的标记线才能构成候选车位,利用约束条件对检测到的标记线配对成组,以将各车位的车位线识别出来。
本步骤中,利用两个连续的停车位标记线之间的区域不能包含车辆或其他障碍物以及其次两条标记线之间的距离必须达到停车位的大小这两个约束条件,对标记线进行配对成组。
第五,对结果优化微调,以保证所有的车位的车位线都尽可能地被识别出来,提高识别精度。
如在未检测到标记线但是检测到车辆时,如果车辆之间的空间足够大能够满足泊车的需求,那么检测到的车辆边界可以用来取代未检测到的标记线。
第六、通过以上步骤将车位的车位线识别出来后,对得到的车位线以及车位线的角点位置进行标注。
本实施例中,用黄色标出车位线以及用绿色标出角点的位置。
第七、将得到的车位线以及车位线的角点位置映射回原图中,从而检测出车位的位置,而得到的角点位置可以作为后续自动泊车执行机构的输入。
一、下面通过语义分割评价实验来对本实施例提供的语义分割网络进行验证:
在利用训练集对改进的DeepLab V3+语义分割模型进行训练完毕后,使用共计677张图像的测试集进行测试。结果显示:预测对的样本占总样本数的比例即准确率为97.21%,预测为正的样本占真正的正样本数的比例即精确率为97.37%,样本中被预测正确的正例即召回率为97.21%。
实验与Jang等人采用的数据集相同,因此可以进行评价指标的对比。在4类对象的分割结果上,本发明对车位标记线的分类精度达到了83.97%,相比于Jang等人的方法提高了10.16%,将会大大提高后续停车位的检测精度。另外其余3类对象的分割精度也有所提升,比较结果如表1所示:
表1
二、下面通过车位检测评价实验来对本实施例的车位检测结果进行验证
车位检测是建立在语义分割的基础上实现的,因此非常依赖语义分割网络的结果。而本发明的语义分割网络对车位标记线的分类精度非常高,最后经过基于垂直网格搜索的过程,可以准确地推断出候选车位出来。如图4中(a)、(b)、(c)中最左侧的图,通过本实施例提供的语义分割网络相应得到的语义分割结果如中间的图所示,最后通过图像处理和逻辑处理得到车位线标注结果如最右侧的图所示。可以看到,通过本实施例提供的车位检测方法可以清洗准确地将车位和车位的角点位置识别出来。
为了进一步验证算法的鲁棒性,本发明特意选择了一些停车位标志线不清楚,甚至无法识别的场景。如图5所示(a)、(b)左侧为模糊的车位线以及该区域局部放大的图像,(a)、(b)右侧为最终检测结果。可以看出,在这些标记线模糊的场景中,由于本实施例精确的语义分割模型和停车位检测方法,可以很好地将停车位检测出来。
本实施例提供的方法检测得到的车位和角点位置,可以为自动泊车系统提供泊车时的具体车位信息。本方法可以减少车位检测过程中因为其他噪声造成的检测不准的影响,提高车位检测系统的鲁棒性;在保证车位检测准确率的情况下,尽量提高车位检测速度。
上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明主要技术方案的精神实质所做的修饰,都应涵盖在本发明的保护范围之内。
- 一种基于深度学习的空间车位检测方法
- 一种基于深度学习的车位检测方法