基于多方交流的语音数据文字转化方法
文献发布时间:2023-06-19 10:58:46
技术领域
本发明涉及数字信息传输技术领域,具体地说,涉及基于多方交流的语音数据文字转化方法。
背景技术
目前,随着聊天工具的不断更新换代,已经由以前的文字聊天转换成了语音聊天,其中:
聊天工具又称IM软件或者IM工具,指的是提供基于互联网络的客户端进行实时语音、文字传输的工具,从技术上讲,主要分为基于服务器的IM工具软件和基于P2P技术的IM工具软件,这种实时传讯与电子邮件最大的不同在于不用等候,不需要每隔两分钟就按一次“传送与接收”,只要两个人都同时在线,就能像多媒体电话一样,传送文字、档案、声音、影像给对方,只要有网络,无论对方在天涯海角,或是双方隔得多远都没有距离。
因此,很多的企业开会、学校授课都应用到了这种实时传讯的数字信息传输技术,也就是通过建立群聊的方式将多个设备端进行数据传输,但现有的视频群聊、还是语音群聊都只是对交流过程中所有的语音数据进行转化,这样的文字转化并没有足够的针对性,还需要后期整理的人员对不需要转化文字进行筛选。
发明内容
本发明的目的在于提供基于多方交流的语音数据文字转化方法,以解决上述背景技术中提出的问题。
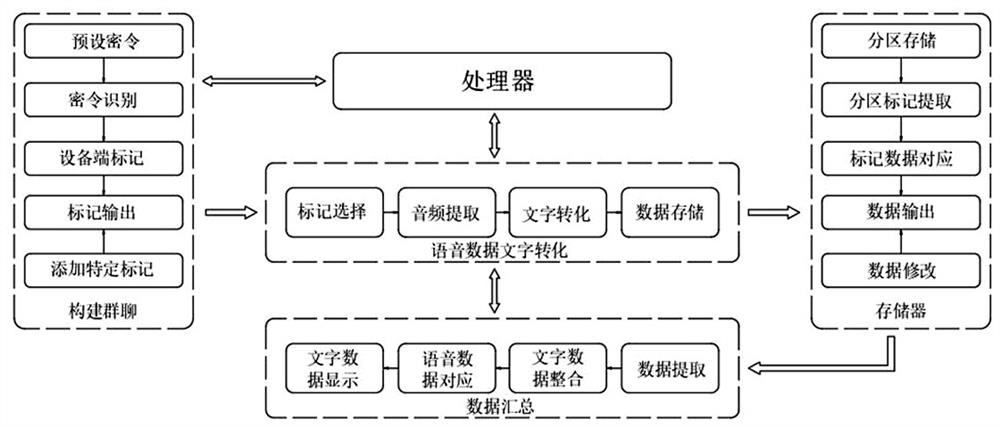
为实现上述目的,本发明提供基于多方交流的语音数据文字转化方法,包括如下方法步骤:
首先识别多方设备端输入的预设密令,其包括两种姿态:
姿态一、预设密令正确,则对该设备端进行标记,并输出各个设备端的标记,根据设备端的标记构建群聊;
姿态二、预设密令不正确,则继续弹出输入窗口;
对群聊内各个设备端交流的语音数据进行文字转化;
将语音数据以及其转化后的文字数据通过存储器进行存储;
在存储器内提取出预选标记设备端输出的语音数据以及其转化后的文字数据,然后根据提取出的文字数据识别预选标记设备端的关键数据信息,以形成关键标题,而后提取出其余标记设备端在关键标题之后下一个关键标题出现之前输出的语音数据以及其转化后的文字数据,以形成关键文字数据;
将关键文字数据和关键标题进行整合,具体的,先根据关键标题对关键文字数据进行筛选,筛选出价值文字数据,并将价值文字数据、语音数据以及设备端标记相互对应的补入在群聊的显示框内。
作为本技术方案的进一步改进,所述预选标记设备端的关键数据信息包括重点文字信息、语气助词信息和关键词提取信息。
作为本技术方案的进一步改进,所述关键数据信息提取采用加权提取算法,其算法步骤如下:
根据语音数据中的声音间隔和声音的语气进行标点符号断句,其中标点符号包括句号、问号和感叹号;
利用加权因子对预选标记设备端文字数据的词频、词长、词性、位置和词典因子进行量化处理,量化后进行权重计算,得出各个因子总权值;
利用降序排列的方式对权值相对应的词语进行排序,得出关键词列表,通过关键词列表获取关键数据信息。
作为本技术方案的进一步改进,所述因子总的权值计算公式如下:
其中,
作为本技术方案的进一步改进,所述中文字转化具体步骤如下:
首先对设备端输出的音频数据进行提取,然后利用高斯混合学习算法对音频数据进行训练;
对提取源音频输出语音的谐波加噪声模型进行分解,并利用平均基频比对分解的模型进行修正,得出相应的修正谐波幅度和相位参数,然后对谐波幅度和相位参数的特征进行提取,得出线性频谱率参数,再利用高斯混合模型对线性频谱率参数进行映射,而后融合映射后的线性频谱率参数特征;
利用修正谐波幅度和相位参数进行混合输出,然后提取源音频输出语音的文字数据。
作为本技术方案的进一步改进,所述高斯混合学习算法包括如下步骤:
首先训练源音频输出语音和目标音频输出语音,并对相应的谐波加噪声模型进行分解;
计算出两个输出语音的基频轨迹的平均基频比,同时对两个输出语音的谐波幅度和相位参数进行特征提取,得到相应的线性频谱率参数;
将得到的线性频谱率参数进行动态时间规整,再利用变分贝叶斯估计算法得出高斯混合模型。
作为本技术方案的进一步改进,所述变分贝叶斯估计算法的计算公式如下:
其中:
与现有技术相比,本发明的有益效果:
该基于多方交流的语音数据文字转化方法,通过关键标题和关键文字数据进行整合对多方交流的语音数据转化后的文字进行整合,并通过预选标记的方式将关键标题,进而解决现有技术中语音数据转换针对性不足的问题,而且整理后大大提高了后期人工筛选的效率。
附图说明
图1为本发明的整体流程图;
图2为本发明的高斯混合学习算法训练步骤流程图;
图3为本发明的高斯混合学习算法转化步骤流程图;
图4为本发明的显示框示意图其一;
图5为本发明的显示框示意图其二;
图6为本发明的VB-GMM算法和GMM算法折线示意图。
具体实施方式
实施例1
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1所示,本发明提供技术方案:
本发明提供基于多方交流的语音数据文字转化方法,包括如下方法步骤:
对群聊内各个设备端交流的语音数据进行文字转化;
将语音数据以及其转化后的文字数据通过存储器进行存储,然后将文字转化后的文字数据在显示框内显示,请参阅图4所示,通过显示的文字数据便于后期在整理会议记录或者学习笔记时进行记忆,解决了视频会议或者视频学习后无法对文字进行提取记忆的问题。
实施例2
为了提高群聊的安全性,避免非群聊人员加入到群聊内,本实施例与实施例1不同的是,首先识别多方设备端输入的预设密令,其包括两种姿态:
姿态一、预设密令正确,则对该设备端进行标记,并输出各个设备端的标记,根据设备端的标记构建群聊,从而通过标记的方式对群聊的人员进行区别划分,并通过添加特定标记的方式进行区分,例如:若群聊为企业群,这样标记的方式有“老板”和“员工”;若群聊为学习群,这样标记的方式有“老师”和学生,进而提高了群聊内成员的辨识度;
姿态二、预设密令不正确,则继续弹出输入窗口,此时预设密令不正确的设备端无法加入群聊,大大提高了群聊的安全性,解决非群聊人员加入到群聊内的问题。
实施例3
为了提高语音数据转换的针对性,本实施例与实施例2不同的是,在存储器内提取出预选标记设备端输出的语音数据以及其转化后的文字数据,然后根据提取出的文字数据识别预选标记设备端的关键数据信息,以形成关键标题,而后提取出其余标记设备端在关键标题之后下一个关键标题出现之前输出的语音数据以及其转化后的文字数据,以形成关键文字数据;
将关键文字数据和关键标题进行整合,具体的,先根据关键标题对关键文字数据进行筛选,筛选出价值文字数据,并将价值文字数据、语音数据以及设备端标记相互对应的补入在群聊的显示框内。
此外,预选标记设备端的关键数据信息包括重点文字信息、语气助词信息和关键词提取信息。
本实施例在具体使用时,本实施例以企业的会议举例说明,通过密令输入的方式构建交流群聊,假设群聊内的设备端集合S=(A,a1,a2,a3),并且标记后S=(老板A,员工a1,员工a2,员工a3),此时将“老板A”设置为预选标记,当老板A在群聊内发出“针对以上描述你们还有什么问题么”,从而得出语气助词“么”,则将“针对以上描述你们还有什么问题么”判定为关键标题,而后员工a1,a2,a3输出“问题1:如何去提高平时的工作效率”、“问题2:不知道”、“问题3:如何实现工作过程中员工的互相监督”等语音数据则被定为关键文字数据,然后将与关键标题不符合的文字数据“问题2:不知道”剔除,留下“问题1:”、“问题3”和“针对以上描述你们还有什么问题么”进行整合通过显示框的显示,请参阅图5所示,其中:
老板A:“针对以上描述你们还有什么问题么”;
员工a1:“问题1:如何去提高平时的工作效率”;
员工a3:“问题3:如何实现工作过程中员工的互相监督”。
从而通过关键标题和关键文字数据进行整合对多方交流的语音数据转化后的文字进行整合,并通过预选标记的方式将关键标题,进而解决现有技术中语音数据转换针对性不足的问题,而且整理后大大提高了后期人工筛选的效率。
实施例4
为了提高关键数据信息提取的准确性,本实施例与实施例3不同的是,关键数据信息提取采用加权提取算法,其算法步骤如下:
根据语音数据中的声音间隔和声音的语气进行标点符号断句,其中标点符号包括句号、问号和感叹号;
利用加权因子对预选标记设备端文字数据的词频、词长、词性、位置和词典因子进行量化处理,量化后进行权重计算,得出各个因子总权值;
利用降序排列的方式对权值相对应的词语进行排序,得出关键词列表,通过关键词列表获取关键数据信息。
具体的,因子总的权值计算公式如下:
其中,
过滤掉非特定词性的词语(名词、动词、形容词、成语)或者在标题句、段首、段尾均未出现且词频为1的词语。
设文章的总词数为Total,关键词的提取数目为k则k应满足:
若Total35%<20则k=Total35%;若Total35%>=20则k=20,通过以上两个步骤提取得到的k个关键词作为一级候选关键词,从而通过权重进行计算得出的关键数据信息得准确性大大提高。
实施例5
为了提高稀少数据环境下语音转化的鲁棒性,本实施例与实施例1不同的是,请参阅图2和图3所示,其中:
中文字转化具体步骤如下:
首先对设备端输出的音频数据进行提取,然后利用高斯混合学习算法对音频数据进行训练;
对提取源音频输出语音的谐波加噪声模型进行分解,并利用平均基频比对分解的模型进行修正,得出相应的修正谐波幅度和相位参数,然后对谐波幅度和相位参数的特征进行提取,得出线性频谱率参数,再利用高斯混合模型对线性频谱率参数进行映射,而后融合映射后的线性频谱率参数特征;
利用修正谐波幅度和相位参数进行混合输出,然后提取源音频输出语音的文字数据。
除此之外,高斯混合学习算法包括如下步骤:
首先训练源音频输出语音和目标音频输出语音,并对相应的谐波加噪声模型进行分解;
计算出两个输出语音的基频轨迹的平均基频比,同时对两个输出语音的谐波幅度和相位参数进行特征提取,得到相应的线性频谱率参数;
将得到的线性频谱率参数进行动态时间规整,再利用变分贝叶斯估计算法得出高斯混合模型。
具体在使用时,高斯混合模型采用VB-GMM算法,首先将源音频输出语音
值得注意的是:点(1)-(6)的符号指的是一定训练数据量下两者的最优混合度个数(标准的GMM和VB-GMM均采用同样的最优混合度),且这个最优值是根据VB-GMM算法自动获取的(对不同数量的数据,我们均初始化32个混合度,最终得到的混合度数值是VB-GMM算法自我优化的结果),从而避免产生“过拟合”的问题,进而提高稀少数据环境下语音转化的鲁棒性。
进一步的,变分贝叶斯估计算法的计算公式如下:
其中:
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的仅为本发明的优选例,并不用来限制本发明,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 基于多方交流的语音数据文字转化方法
- 基于多方交流的语音数据文字转化方法