基于层内层间联合全局表示的图像描述方法
文献发布时间:2023-06-19 11:02:01
技术领域
本发明涉及人工智能领域中的图像自动描述,特别是涉及一种基于图片用自然语言对图像客观内容进行描述的基于层内层间联合全局表示的图像描述方法。
背景技术
图像自动描述(Image Captioning)是近年来人工智能界提出的一个机器终极智能任务,它的任务是将于一张给定图像,用自然语言对图像客观内容进行描述。随着计算机视觉技术的发展,完成目标检测、识别、分割等任务已经不能满足人们的生产需求,对如何自动客观的对图像内容自动描述有迫切的需求。和目标检测及语义分割等任务不同,图像自动描述要将图像中的物体、属性、物体间的关系以及相应的场景等用自动语言进行整体而客观的描述,该任务是计算机视觉理解的重要方向之一,被视为人工智能的一个重要标志。
早先的图像自动描述主要采用基于模板的方法和基于检索的方法实现,直到近来受自然语言技术的启发,开始使用编码器-解码器框架,注意力机制以及以强化学习为基础的目标函数,该任务取得极大的进展。
Xu等人(Xu,K.;Ba,J.;Kiros,R.;Cho,K.;Courville,A.;Salakhudinov,R.;Zemel,R.;and Bengio,Y.2015.Show,attend and tell:Neural image captiongeneration with visual attention.In ICML)首次在图片描述任务中引入了注意力机制,用来将重要的视觉属性和场景嵌入到描述生成器中。继此之后,很多工作都对注意力机制提出了改进。例如,Chen等人(Chen,L.;Zhang,H.;Xiao,J.;Nie,L.;Shao,J.;Liu,W.;andChua,T.-S.2017b.Sca-cnn:Spatial and channel-wise attention in convolutionalnetworks for image captioning.In CVPR)提出了空间和通道注意力机制,用以选择显著的区域以及显著的语义模式;Lu等人(Lu,J.;Xiong,C.;Parikh,D.;and Socher,R.2017.Knowing when to look:Adaptive attention via a visual sentinel forimage captioning.In CVPR)提出了视觉哨兵的概念,用以决定下一步关注视觉信息还是文本信息,大大提高模型的精确度;Anderson等人(Anderson,P.;He,X.;Buehler,C.;Teney,D.;Johnson,M.;Gould,S.;and Zhang,L.2018.Bottom-up and top-downattention for image captioning and visual question answering.In CVPR)先通过预训练好的目标检测器获取区域然后将此加入到模型用以生成图像字幕。Huang等人(Huang,L.;Wang,W.;Chen,J.;andWei,X.-Y.2019.Attention on Attention for ImageCaptioning.In ICCV)则首次采用了transformer类的框架图像描述任务中,从此Transformer模型开始成为该任务的主流模型。Zhu等人(Zhu,X.;Li,L.;Liu,J.;Peng,H.;and Niu,X.2018.Captioning transformer with stacked attention modules.AppliedSciences)和Cornia等人(Cornia,M.;Stefanini,M.;Baraldi,L.;and Cucchiara,R.2020.Meshed-Memory Transformer for Image Captioning.In CVPR)都使用Transformer结构代替长短时循环网络并取得了最好性能。然而,这些模型并没有考虑如何利用全局特征来引导描述生成。
发明内容
本发明的目的在于针对传统基于transformer的图像描述方法没有显性建模全局特征从而导致物体缺失和关系偏置等问题,提供通过建模一个更加综合且具有指导性的全局特征,连接不同的局部信息,从而提高生成描述准确性的基于层内层间联合全局表示的图像描述方法。
本发明包括如下步骤:
1)采用目标检测器提取待描述图像的若干个候选区及各候选区对应的特征;
2)将步骤1)提取的特征输入训练好的神经网络,从而输出待描述图像的描述结果;其中,神经网络的全局损失函数通过如下方法获得;
(1)对训练集中的文本内容进行预处理,得到句子序列;对训练集中的图像,采用目标检测器提取若干个候选区,并提取各个候选区所对应的特征V={v
(2)将特征V送入全局加强编码器,借助多头注意力机制将候选区特征进一步编码,得到对应的隐藏特征以及层内-层间联合全局特征;
(3)将前述的隐藏特征加入到自适应解码器中,同时用层内-层间联合全局特征进行跨模态特征的融合,借助多头注意力机制的特性修正多模态特征,生成当前阶段的词;
(4)迭代生成整个句子,并定义生成句子的损失函数。
在步骤1中,所述目标检测器的训练方法是:目标检测器采用Faster R-CNN框架,其骨架网络是深度卷积残差网络,首先采用端到端的方法在经典目标检测数据集PASCALVOC2007中进行训练,然后在多模态数据集Visual Genome上进一步训练微调网络参数。
在步骤(1)中,所述对训练集中的文本内容进行预处理,得到句子序列的具体过程是:首先对训练集中的文本内容进行去停用词处理,并将所有英文词汇进行小写化;然后对文本内容按空格进行分词,对于得到的若干单词,剔除数据集描述中出现次数小于阈值的单词,使用“
在步骤(2)和(3)中,所述多头注意力机制相关过程如下:
针对给定的索引Q,键K,以及值V,
MultiHead(Q,K,V)=Concat(H
H
其中,Q是一个具有n
在步骤(2)中,所述将特征V送入全局加强编码器,借助多头注意力机制将候选区特征进一步编码,得到对应的隐藏特征以及层内-层间联合全局特征的相关公式如下:
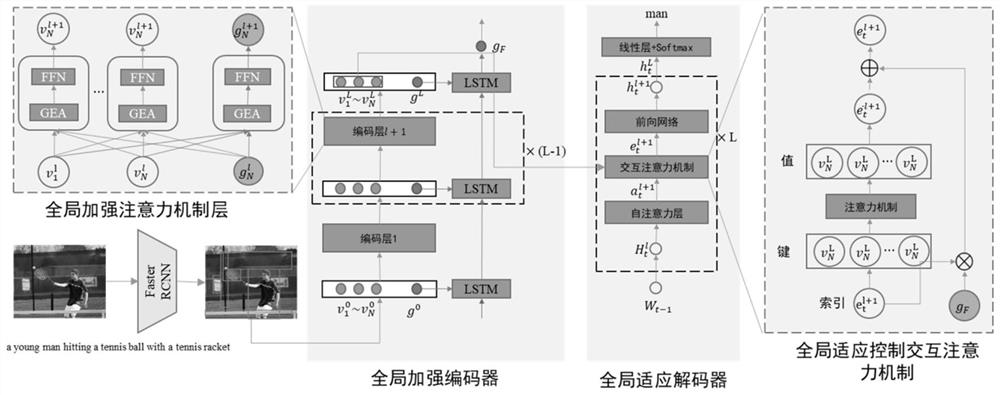
具体步骤如下:全局加强编码器由L层相同的结构组成,定义第l+1的输入为O
O
其中,GEA即为定义的全局加强的注意力机制,LayerNorm为归一化层,FFN为前馈神经网络,O
h
其中,i=1,…,L,LSTM为长短时记忆网络,由此得到了层内-层间联合全局特征g
在步骤(3)中,所述将前述的隐藏特征加入到自适应解码器中,同时用层内-层间联合全局特征进行跨模态特征的融合,借助多头注意力机制修正多模态特征,生成当前阶段的词,其具体过程可为:
首先假设t为句子序列的第t个词,W
W
与编码器相同,解码器也是由L层相同的结构组成,定义第l+1的输入为
V
其中,W
在步骤(4)中,具体过程是:
对于预测的句子Y
其中,T为句子长度;通过监督学习和强化学习两个阶段对模型进行训练;在监督学习阶段,采用交叉熵,对于给定的目标句子
在强化学习阶段,采用强化学习进行训练,其损失函数的梯度定义为:
其中,
采用上述方案后,本发明具有以下突出优点:
(1)本发明充分利用Transformer结构的特点,显式建模层内-层间联合全局特征,有效利用图片的全局特征,大大减少图像描述任务间存在的物体缺失和关系偏置,极大提升生成句子的准确性和全面性;
(2)本发明具有很强的迁移性,能够适用于任何一个基于Transformer结构的图像描述模型,改进模型的性能;
(3)本发明解决了图像描述的目标缺失和关系偏置问题,其主要应用场景在于建模全局特征,拓展复杂的多模态推理,为其自动生成描述,在图像检索,盲人导航,医疗报告自动生成和早教领域存在大量的应用前景。
附图说明
图1是本发明实施例的流程图;
图2是不同的图像描述模型生成的句子对比图;其中,Transformer是一种经典的基线方法的名称;
图3是对解码器生成每个词时的关注区域的可视化图;
图4是三个不同层在8个头关注到每个词时关注到每个点的比例是多少其中第一列标签本方法建模的,该图显示最终每个头都实实在在关注到了全局特征;
图5是可视化高层的输出对于底层输入的相似度分析图。
具体实施方式
以下实施例将结合附图,对本发明的技术方案及有益效果进行详细说明。
本发明的目的是针对传统基于transformer的图像描述方法没有显性建模全局特征从而导致物体缺失和关系偏置的问题,提出通过建模一个更加综合且具有指导性的全局特征,连接不同的局部信息,从而提高生成描述的准确性,提供基于层内层间联合全局表示的图像描述方法。具体的方法流程如图1所示。
本发明实施例包括以下步骤:
1)对于图像库中的图像,首先使用卷积神经网络抽取相应的图像特征;
2)将特征V送入全局加强编码器,将候选区特征进一步编码,得到对应的隐藏特征以及层内-层间联合全局特征;
3)将前述的隐藏特征加入到自适应解码器中,同时用层内-层间联合全局特征进行跨模态特征的融合,修正多模态特征,生成当前阶段的词;
4)迭代生成整个句子,并定义生成句子的损失函数。
具体的每个模块如下:
1、深度卷积特征抽取与描述数据预处理
对所有训练数据中的文本内容进行去停用词处理,并将所有英文词汇进行小写化;然后对文本内容按空格进行分词,得到9487个单词,对数据集描述中出现次数小于5的单词进行了剔除,使用“
先使用预训练好的目标检测器提取36个固定的候选区,并使用残差深度卷积网络提出各个候选区相对应的特征V={v
2、全局加强编码器
首先,全局加强编码器由L层相同的结构组成,定义第l+1的输入为O
MultiHead(Q,K,V)=Concat(H
H
其中,GEA即为定义的全局加强的注意力机制,LayerNorm为归一化层,FFN为前馈神经网络,O
h
其中,i=1,…,L,LSTM为长短时记忆网络,由此得到了层内-层间联合全局特征g
3、全局适应解码器
如图1所示,首先假设t为句子序列的第t个词,W
W
与编码器相同,解码器也是由L层相同的结构组成,定义第l+1的输入为
V
4、全局损失函数构建
对于预测的句子Y
其中,T为句子长度;通过监督学习和强化学习两个阶段对模型进行训练;在监督学习阶段,采用交叉熵,对于给定的目标句子
在强化学习阶段,采用强化学习进行训练,其损失函数的梯度定义为:
其中,
为了验证本发明提出的模型的可行性和先进性,在通用数据集MSCOCO进行模型的评估。其中和最新图像自动描述方法的量化比较如表1所示,可以看到在多种评估指标上所提出的模型性能都具有很高的优势。另外,通过可视化输入图像所生成的文本描述,示例给出的描述为英文,中文描述自动生成过程同理(如图2所示),可以看到由于本发明的模型对全局信息显示建模以后,其在图像描述上取得了很明显的改进。图3对解码器关注区域的可视化,该结果表明本发明方法在全局特征的指导下,模型可以更准确的定位到要描述的区域。图4展示的是三个不同层在8个头关注到每个词时关注到每个点的比例是多少其中第一列标签本方法建模的,该图显示最终每个头都实实在在关注到了全局特征。该图展示了解码层生成词在每一层对于不同区域以及全局特征的关注度多少。其中每一行表示生成句子中对应的词语,每一列代表的是图片区域,其中第一列表示全局特征。将全局特征被关注的比例做了统计,并记录在每个头的上方。该图显示最终每个头都实实在在关注到了全局特征。图5则是可视化高层的输出对于底层输入的相似度,对角线颜色比较浓说明每个区域对应的高层隐藏特征还是与对应的底层隐藏特征最接近,表明现有Transformer的机制关注的依然是局部偏置的。图2~4中描述和词都以英文为例,但是该发明可以直接拓展到中文描述,机理相同。
表1本发明方法与当前最先进方法的比较
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 基于层内层间联合全局表示的图像描述方法
- 基于深度联合稀疏-协同表示的高光谱图像特征表示方法