一种票证识别的方法
文献发布时间:2023-06-19 11:02:01
技术领域
本公开涉及文本检测、文本识别与信息结构化提取技术领域,尤其涉及一种票证识别的方法。
背景技术
票证识别指的是对日常生活中常见的发票、身份证、银行卡等不同领域中含有文字信息的图像进行识别并提取其中结构化信息的技术。由于票证包含的领域众多,票证的格式繁杂,给识别与结构化提取带来了诸多困难。
票证结构化识别任务可以被细分为文本检测、文本识别等多个领域内的研究任务。当前文本检测领域的主要方法是将深度学习中目标检测或分割算法与文字检测任务相结合得到,如EAST,该算法采用了语义分割常用的FCN(Fully Convolutional Networks,全卷积网络)结构,实际上还是基于回归的思想对文字框参数进行回归,借助了FCN的架构完成特征提取和特征融合的操作,然后EAST模型在图像中的每个位置预测一组文本行的回归参数,最后使用非极大值抑制操作即可提取输入图像中的文字行。该方法极大地简化了文字检测的流程,但是目前相似的方法仍存在对长文本检测效果不佳、小文本区域检测能力差的问题,而这些问题正是票证识别中较为关键的问题。
当前文本识别领域内的方法主要有字符识别和序列识别两种。使用字符识别方法进行文字识别时,首先需要从图像中分割出单个字符,再通过分类器对单个字符图像进行分类,最后合并成文本行级别的识别结果;而基于序列识别的文本识别算法将整个文本行作为识别的最小单元,以自动对齐的方式完成对整个文字序列的识别,同时引入了自然语言处理的Seq2Seq模型和注意力机制来提高识别效果。但这两种方法都存在各自的问题,字符识别方法需要字符级别的监督信息,所以需要大量的标注工作;基于序列识别的方法的鲁棒性受训练数据的影响很大,对于背景复杂的图像和相似的字符容易出现错误识别。
因此,对于票证结构化识别的任务,当前方法没有考虑到对信息结构化的提取问题,识别得到的杂乱信息并不能直接用于后续的工作,所以针对以上问题还有待研究解决。
发明内容
本公开提供了一种票证识别的方法,其技术目的是针对票证中的图像风格不一、表格格式不统一、印刷不清晰等问题,建立一个能有效提取结构化信息的模型。
本公开的上述技术目的是通过以下技术方案得以实现的:
一种票证识别的方法,模型训练过程和文本识别过程,所述模型训练过程包括:
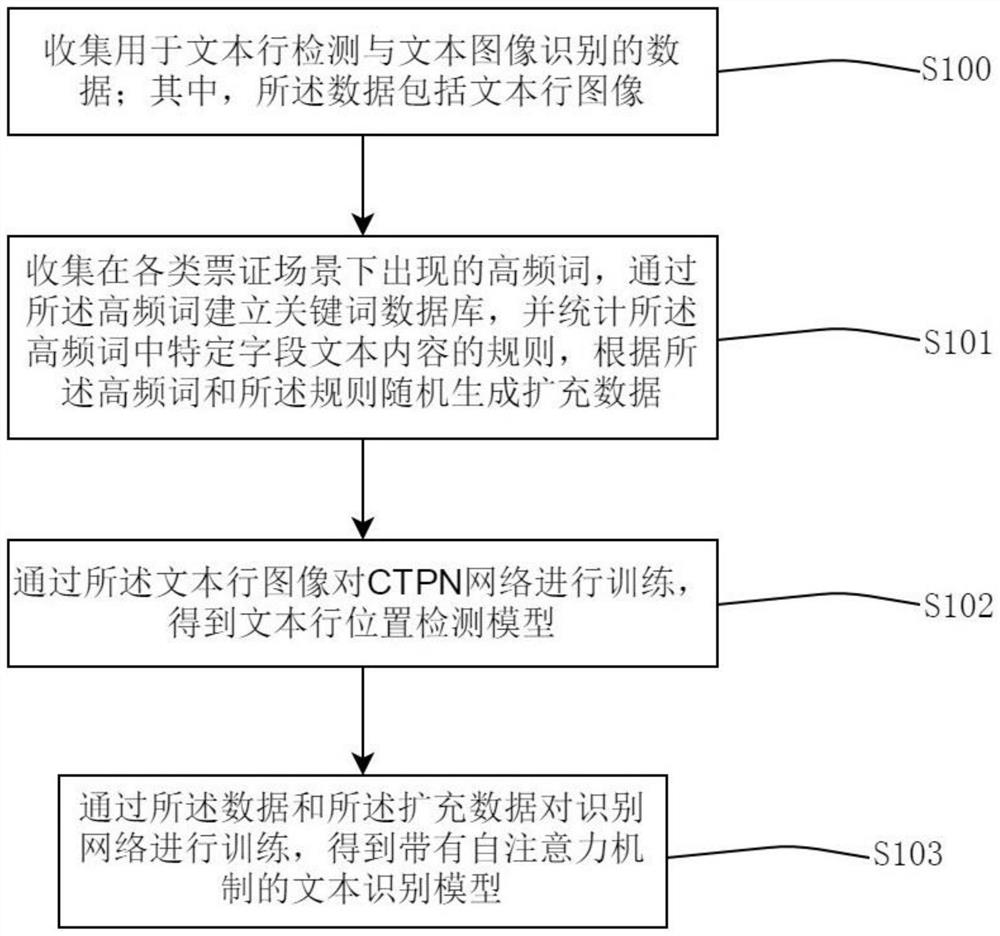
S100:收集用于文本行检测与文本图像识别的数据;其中,所述数据包括文本行图像;
S101:收集在各类票证场景下出现的高频词,通过所述高频词建立关键词数据库,并统计所述高频词中特定字段文本内容的规则,根据所述高频词和所述规则随机生成扩充数据;
S102:通过所述文本行图像对CTPN网络进行训练,得到文本行位置检测模型;
S103:通过所述数据和所述扩充数据对识别网络进行训练,得到带有自注意力机制的文本识别模型;
所述文本识别过程包括:
S200:将票证的图像输入到文本行位置检测模型,所述文本行位置检测模型对票证中的文本行位置进行检测,输出检测到文本行位置的文本图像;
S201:将所述文本图像输入到文本识别模型进行文本识别,通过文本识别模型的自注意力机制对所述文本进行识别后得到识别结果,根据所述关键词数据库对所述识别结果进行结构化提取,得到有效信息。
本公开的有益效果在于:本发明通过对CTPN网络进行训练得到文本行位置检测模型,从而对票证中的关键信息进行定位,且对各种形式(表格等)的票证具有鲁棒性;通过高频词及其中特定字段文本内容的规则合成数据,扩充了文本识别模型的训练数据,提升了识别模型的准确性;基于卷积神经网络,具有很好的并行性,可以利用高性能的GPU(Graphics Processing Unit,图形处理器)加速计算。
附图说明
图1、图2为本发明所述一种票证识别的方法模型训练过程的流程图;
图3、图4为本发明所述一种票证识别的方法文本识别过程的流程图;
图5为文本识别模型的结构图;
图6为本发明实施例提供的文本行定位、文本识别、结构化提取的流程示意图。
具体实施方式
下面将结合附图对本公开技术方案进行详细说明。在本公开的描述中,需要理解地是,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量,仅用来区分不同的组成部分。
图1、图2为本发明所述一种票证识别的方法模型训练过程的流程图,如图1和图2所示,模型训练过程包括:S100:收集用于文本行检测与文本图像识别的数据;其中,所述数据包括文本行图像。
具体地,收集用于文本行检测与文本图像识别的数据,可通过在文本检测与识别研究领域检索得到大量公开的、高精度标注的、包含多种语言的文本行检测集和文本图像识别数据集。从收集到的数据集中筛去与票证识别场景相差较大的数据,标记并剔除获取到的异常数据,将整理得到的数据用于CTPN(Connectionist Text Proposal Network,连接文本提案网络)网络和识别网络的训练。
S101:收集在各类票证场景下出现的高频词,通过所述高频词建立关键词数据库,并统计所述高频词中特定字段文本内容的规则,根据所述高频词和所述规则随机生成扩充数据。
具体地,根据所述高频词和所述规则随机生成扩充数据,包括:(1)将词频不小于预设阈值的所述高频词进行组合生成文本。(2)将所述文本组合成符合票证中文本的特定格式。(3)随机选取空白或带有噪声的图像作为背景,将符合特定格式的所述文本渲染到图像上,得到所述文本的图像,即得到所述扩充数据。
上述无论是数据还是扩充数据,实际都是图像数据,直接通过提取图像数据的特征训练CTPN网络和识别网络。
S102:通过所述文本行图像对CTPN网络进行训练,得到文本行位置检测模型。
S103:通过所述数据和所述扩充数据对识别网络进行训练,得到文本识别模型。
图3、图4为本发明所述一种票证识别的方法文本识别过程的流程图,如图3和图4所示,文本识别过程包括:S200:将票证的图像输入到文本行位置检测模型,所述文本行位置检测模型对票证中的文本行位置进行检测,输出检测到文本行位置的文本图像。
S201:将所述文本图像输入到文本识别模型进行文本识别,通过文本识别模型的自注意力机制对所述文本进行识别后得到识别结果,根据所述关键词数据库对所述识别结果进行结构化提取,得到有效信息。
具体地,所述进行结构化提取,得到有效信息,包括:计算每个所述关键词与所述识别结果的编辑距离,生成编辑距离矩阵,为每个所述关键词匹配编辑距离最小的配对识别结果,根据所述配对识别结果确定所述关键词在所述识别结果中的位置,得到所述有效信息。而当关键词没有匹配到配对识别结果时,返回缺省值;也就是说,识别率并不是100%的,当出现关键词无法匹配到编辑距离最小的配对识别结果的情况时,就会返回一个缺省值表示。将深度神经网络的输出通过最小编辑距离匹配得到关键词信息,有效的提高了结果的可靠性。
作为具体实施方案地,步骤S102包括:
S102-1:所述CTPN网络包括依次连接的卷积神经网络、LSTM(Long Short-TermMemory,长短时记忆)网络和一个1×1卷积层;每个文本行包括至少两个文本行部件,在所述卷积神经网络中预设多个宽度固定为16、高度不同的预设锚框用于定位所述文本行部件。
S102-2:所述CTPN网络训练的初始学习率为0.001,动量为0.9,将所述文本行图像投入到所述CTPN网络进行训练。
在所述CTPN网络的前向传播过程中,首先通过卷积神经网络(例如VGG16)对输入的所述文本行图像进行特征提取,得到大小为N×C×H×W的第一特征图,然后在所述第一特征图上对应每个预设锚框的位置处使用3×3卷积得到大小为N×9C×H×W的第二特征图,随后将所述第二特征图的维度变换为NH×W×9C,再将维度为NH×W×9C的第二特征图送入所述LSTM网络中学习所述第二特征图中每一行的序列特征,得到输出为NH×W×256的第三特征图,并将所述第三特征图的维度变换为N×512×H×W,最后将维度为N×512×H×W的第三特征图投入到1×1卷积层卷积后得到预测结果;其中,N表示每次处理的文本行图像的数量,H表示文本行图像的高度,W表示文本行图像的宽度,C表示文本行图像在网络前向传播中的通道数。
S102-3:得到所述预测结果后,按照第一损失函数计算CTPN网络的损失,再使用优化器SGD(stochastic gradient descent,随机梯度下降)对CTPN网络的参数进行更新,再将所述文本行图像投入到更新参数后的CTPN网络进行训练,反复重复这一过程,直至得到最佳预测结果,保存所述最佳预测结果对应的最佳模型参数,即得到所述文本行位置检测模型;
其中,所述第一损失函数为:Loss=λ
所述文本行部件在每个所述预设锚框位置处的输出结果包括:v
作为具体实施方案地,步骤S103包括:
S103-1:所述识别网络包括依次连接的特征提取网络、特征融合网络、编码网络、一层的全连接层和解码算法,如图5所示。
S103-2:所述识别网络的初始学习率为0.0001,优化器Adam的贝塔值为(0.9,0.999),将所述数据和所述扩充数据投入到所述识别网络进行训练;
在所述识别网络的前向传播过程中,将大小为H×W的图像通过所述特征提取网络进行特征提取,得到第一特征;
再通过所述特征融合网络对所述第一特征进行融合,并对融合后的所述第一特征进行采样使融合后的所述第一特征的高度为1,得到第二特征;
将所述第二特征输入到所述编码网络进行编码得到编码特征;
将所述编码特征输入到所述全连接层进行解码,得到解码结果;
最后通过所述解码算法对所述解码结果进行对齐得到识别结果;
其中,所述特征提取网络为Resnet50网络,所述特征融合网络为FPEM(FeaturePyramid Enhancement Module,特征金字塔增强模块)网络,所述编码网络为Encoder网络,所述解码算法为CTC(ConnectionistTemporal Classification,连接时序分类)算法,所述CTC算法的损失函数为
Resnet50网络为提取图像视觉特征的残差网络,FPEM网络为将多阶段图像视觉特征进行融合的卷积网络,通过融合多阶段特征可以增大模型的感受野从而提升模型的准确性。Encoder网络为基于自注意力机制的特征编码网络,采用自注意力机制可以使得模型更准确的提取特征中的有效消息,从而提升文本识别模型的鲁棒性。CTC算法为输出序列的解码算法,例如输出序列为“cccaaat”,经过CTC算法对齐后就是“cat”。
Encoder网络为同时在自然语言处理与计算机视觉领域广泛应用的模型Transformer中的编码器部分,该部分模型得益于可叠加的编码模块拥有优秀的特征捕捉性能,编码模块包含Multi-Head Attention(多头注意力)和Feed Forward(前馈)两个部分,其中的Multi-Head Attention部分数学表示如下:
Multi-Head Attention(x)=x+Self-Attention(FC(x),FC(x),FC(x));
其中Encoder的输入分别经过3层全连接层FC后作为Q,K,V输入Self-Attention(自注意力)模块中,d
S103-3:得到所述识别结果后,通过所述CTC算法的损失函数计算所述识别网络的损失,再使用优化器Adam对识别网络的参数进行更新,再将所述数据和所述扩充数据投入到更新参数后的识别网络进行训练,反复重复这一过程,直至得到最佳识别结果,保存所述最佳识别结果对应的最佳模型参数,即得到所述文本识别模型。
图6为本发明实施例提供的文本行定位、文本识别、结构化提取的流程示意图,将单幅票证图像输入加载了最佳参数的文本行位置检测模型(CTPN模型)中,得到文本行检测结果,并通过置信度阈值过滤掉多余的文本框,得到图像上关键区域的文本定位框。
对文本行内容进行识别时,一般将文本行图像的高度调至32像素再送入所述文本识别模型进行识别,具体包括:(1)将文本行图像保持原长宽比进行缩放,缩放后图像高度h'=32,图像宽度w'=w×(h'/h),其中w,h为图像原宽度和高度。(2)将单张图像输入加载了最佳参数的文本识别模型中,得到识别向量。(3)通过CTC解码算法对识别向量进行处理,得到置信度最高的文本序列。
然后进行结构化提取,获取有效信息,包括:(1)计算各个关键词与文本识别结果的编辑距离,编辑距离越大,匹配度越低;(2)生成编辑距离矩阵,为每个关键词找到编辑距离最小的配对;(3)根据配对确定关键词在识别结果中的位置,获得文本内容。最后将定位到关键信息提取并按照对应的类型组织成结构化数据输出,若未匹配到关键词则使用统计得到的缺省值补充。
以上为本公开示范性实施例,本公开的保护范围由权利要求书及其等效物限定。
- 一种基于人脸识别的票证识别闸机
- 一种票证识别的方法