图像处理方法、障碍物检测方法、装置、介质及车辆
文献发布时间:2023-06-19 11:02:01
技术领域
本公开涉及计算机技术领域,具体地,涉及一种图像处理方法、障碍物检测方法、装置、介质及车辆。
背景技术
目前,自动驾驶技术依赖于对车辆周边障碍物的检测,对车辆周边障碍物检测的准确与否将对行车安全产生十分重要的影响。相关技术中,在自动驾驶感知领域,对于障碍物检测通常使用两种方式。第一种方式为,在图像上利用深度学习检测二维/三维边框(即,2D/3D bounding box),然而,这种方案的准确性依赖于数据集的数据量,对标注有较大依赖,并且,在实际使用时存在准确率不足的问题,无法适用于实际的使用场景。第二种方式为,利用三维重建单目恢复深度的方法,通过连续帧图像恢复出序列图像中像素级深度,但是,这种方式在识别远距离物体方面存在准确率不足的问题。
发明内容
本公开的目的是提供一图像处理方法、障碍物检测方法、装置、介质及车辆,以提升障碍物检测的准确性。
为了实现上述目的,根据本公开的第一方面,提供一种图像处理方法,所述方法包括:
获取待处理图像;
将所述待处理图像输入至预先训练的障碍物检测模型,得到所述障碍物检测模型针对所述待处理图像输出的检测结果,其中,所述障碍物检测模型包括深度估计网络和目标检测网络;所述深度估计网络用于根据所述待处理图像得到第一输出内容,所述第一输出内容能够反映所述待处理图像的深度信息;所述目标检测网络用于根据所述第一输出内容得到所述检测结果;
根据所述检测结果,确定所述待处理图像中的障碍物信息。
可选地,所述深度估计网络为单目深度估计网络,所述目标检测网络为基于三维边框的目标检测网络。
可选地,所述障碍物检测模型通过以下方式获得:
获取多组训练数据,每一组所述训练数据包括样本图像序列、所述样本图像序列对应的深度信息以及所述样本图像序列对应的障碍物信息,所述样本图像序列中包括在时间上连续的多帧图像;
构建初始检测模型,所述初始检测模型包括初始深度估计网络和初始目标检测网络;
利用所述样本图像序列和所述样本图像序列对应的深度信息,对所述初始深度估计网络进行训练,以获得训练完成的深度估计网络;
根据所述样本图像序列和训练完成的深度估计网络,获得训练完成的深度估计网络针对所述样本图像序列输出的第二输出内容;
根据所述样本图像序列和所述第二输出内容,得到训练输入数据;
利用所述训练输入数据和所述样本图像序列对应的障碍物信息,对所述初始目标检测网络进行训练,以获得训练完成的目标检测网络;
根据所述训练完成的深度估计网络和所述训练完成的目标检测网络,获得所述障碍物检测模型。
可选地,所述利用所述样本图像序列和所述样本图像序列对应的深度信息,对所述初始深度估计网络进行训练,以获得训练完成的深度估计网络,包括:
将目标样本图像序列输入至本次训练所使用的深度估计网络中,获得本次训练所使用的深度估计网络输出的第三输出内容,其中,目标样本图像序列为本次训练所使用的样本图像序列,并且,初次训练所使用的深度估计网络为所述初始深度估计网络;
根据所述第三输出内容和所述目标样本图像序列对应的深度信息,确定本次训练的第一损失值;
若不满足第一训练停止条件,利用所述第一损失值更新本次训练所使用的深度估计网络,并将更新后的深度估计网络用于下一次训练;
若满足所述第一训练停止条件,将本次训练所使用的深度估计网络作为训练完成的深度估计网络。
可选地,所述第二输出内容为所述样本图像序列中每一帧图像对应的深度图像;
所述根据所述样本图像序列和所述第二输出内容,得到训练输入数据,包括:
分别将所述样本图像序列中的每一帧图像作为目标图像,执行如下操作,以得到训练输入数据:
将所述目标图像与所述目标图像在所述第二内容中对应的深度图像进行拼接。
可选地,所述利用所述训练输入数据和所述样本图像序列对应的障碍物信息,对所述初始目标检测网络进行训练,以获得训练完成的目标检测网络,包括:
将目标训练输入数据输入至本次训练所使用的目标检测网络中,获得本次训练所使用的目标检测网络输出的第四输出内容,其中,目标训练输入数据为本次训练所使用的训练输入数据,并且,初次训练所使用的目标检测网络为所述初始目标检测网络;
根据所述第四输出内容和所述目标训练输入数据对应的障碍物信息,确定本次训练的第二损失值;
若不满足第二训练停止条件,利用所述第二损失值更新本次训练所使用的目标检测网络,并将更新后的目标检测网络用于下一次训练;
若满足所述第二训练停止条件,将本次训练所使用的目标检测网络作为训练完成的目标检测网络。
可选地,所述样本图像序列对应的深度信息为所述样本图像序列中各帧图像对应的深度图像;
所述样本图像序列对应的障碍物信息为所述样本图像序列中各帧图像中存在的障碍物的类型信息和位置信息。
可选地,所述检测结果包括所述待处理图像中存在的障碍物的类型信息和位置信息;
所述根据所述检测结果,确定所述待处理图像中的障碍物信息,包括:
根据所述检测结果,确定所述待处理图像中指定类型的障碍物所对应的位置信息。
根据本公开的第二方面,提供一种障碍物检测方法,所述方法包括:
在车辆行驶过程中,获取车辆周边的环境图像;
根据本公开第一方面所提供的方法,确定所述环境图像对应的目标障碍物信息;
根据所述目标障碍物信息,对所述车辆进行驾驶控制。
根据本公开的第三方面,提供一种图像处理装置,所述装置包括:
第一获取模块,用于获取待处理图像;
图像处理模块,用于将所述待处理图像输入至预先训练的障碍物检测模型,得到所述障碍物检测模型针对所述待处理图像输出的检测结果,其中,所述障碍物检测模型包括深度估计网络和目标检测网络;所述深度估计网络用于根据所述待处理图像得到第一输出内容,所述第一输出内容能够反映所述待处理图像的深度信息;所述目标检测网络用于根据所述第一输出内容得到所述检测结果;
第一确定模块,用于根据所述检测结果,确定所述待处理图像中的障碍物信息。
可选地,所述深度估计网络为单目深度估计网络,所述目标检测网络为基于三维边框的目标检测网络。
可选地,所述装置通过以下模块获得所述障碍物检测模型:
第二获取模块,用于获取多组训练数据,每一组所述训练数据包括样本图像序列、所述样本图像序列对应的深度信息以及所述样本图像序列对应的障碍物信息,所述样本图像序列中包括在时间上连续的多帧图像;
初始化模块,用于构建初始检测模型,所述初始检测模型包括初始深度估计网络和初始目标检测网络;
第一训练模块,用于利用所述样本图像序列和所述样本图像序列对应的深度信息,对所述初始深度估计网络进行训练,以获得训练完成的深度估计网络;
第一中间处理模块,用于根据所述样本图像序列和训练完成的深度估计网络,获得训练完成的深度估计网络针对所述样本图像序列输出的第二输出内容;
第二中间处理模块,用于根据所述样本图像序列和所述第二输出内容,得到训练输入数据;
第二训练模块,用于利用所述训练输入数据和所述样本图像序列对应的障碍物信息,对所述初始目标检测网络进行训练,以获得训练完成的目标检测网络;
所述装置用于根据所述训练完成的深度估计网络和所述训练完成的目标检测网络,获得所述障碍物检测模型。
可选地,所述第一训练模块包括:
第一输入子模块,用于将目标样本图像序列输入至本次训练所使用的深度估计网络中,获得本次训练所使用的深度估计网络输出的第三输出内容,其中,目标样本图像序列为本次训练所使用的样本图像序列,并且,初次训练所使用的深度估计网络为所述初始深度估计网络;
第一确定子模块,用于根据所述第三输出内容和所述目标样本图像序列对应的深度信息,确定本次训练的第一损失值;
第一更新子模块,用于若不满足第一训练停止条件,利用所述第一损失值更新本次训练所使用的深度估计网络,并将更新后的深度估计网络用于下一次训练;
所述第一训练模块用于若满足所述第一训练停止条件,将本次训练所使用的深度估计网络作为训练完成的深度估计网络。
可选地,所述第二输出内容为所述样本图像序列中每一帧图像对应的深度图像;
所述第二中间处理模块用于分别将所述样本图像序列中的每一帧图像作为目标图像,执行如下操作,以得到训练输入数据:
将所述目标图像与所述目标图像在所述第二内容中对应的深度图像进行拼接。
可选地,所述第二训练模块包括:
第二输入子模块,用于将目标训练输入数据输入至本次训练所使用的目标检测网络中,获得本次训练所使用的目标检测网络输出的第四输出内容,其中,目标训练输入数据为本次训练所使用的训练输入数据,并且,初次训练所使用的目标检测网络为所述初始目标检测网络;
第二确定子模块,用于根据所述第四输出内容和所述目标训练输入数据对应的障碍物信息,确定本次训练的第二损失值;
第二更新子模块,用于若不满足第二训练停止条件,利用所述第二损失值更新本次训练所使用的目标检测网络,并将更新后的目标检测网络用于下一次训练;
所述第二训练模块用于若满足所述第二训练停止条件,将本次训练所使用的目标检测网络作为训练完成的目标检测网络。
可选地,所述样本图像序列对应的深度信息为所述样本图像序列中各帧图像对应的深度图像;
所述样本图像序列对应的障碍物信息为所述样本图像序列中各帧图像中存在的障碍物的类型信息和位置信息。
可选地,所述检测结果包括所述待处理图像中存在的障碍物的类型信息和位置信息;
所述第一确定模块用于根据所述检测结果,确定所述待处理图像中指定类型的障碍物所对应的位置信息。
根据本公开的第四方面,提供一种障碍物检测装置,所述装置包括:
第三获取模块,用于在车辆行驶过程中,获取车辆周边的环境图像;
第二确定模块,用于根据本公开第一方面所提供的方法,确定所述环境图像对应的目标障碍物信息;
控制模块,用于根据所述目标障碍物信息,对所述车辆进行驾驶控制。
根据本公开的第五方面,提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本公开第一方面所述方法的步骤,或者,该程序被处理器执行时实现本公开第二方面所述方法的步骤。
根据本公开的第六方面,提供一种车辆,包括:
存储器,其上存储有计算机程序;
处理器,用于执行所述存储器中的所述计算机程序,以实本公开第一方面所述方法的步骤,或者,实现本公开第二方面所述方法的步骤。
通过上述技术方案,获取待处理图像,将待处理图像输入至预先训练的障碍物检测模型,得到障碍物检测模型针对待处理图像输出的检测结果,其中,障碍物检测模型包括深度估计网络和目标检测网络;深度估计网络用于根据待处理图像得到第一输出内容,第一输出内容能够反映待处理图像的深度信息;目标检测网络用于根据第一输出内容得到检测结果,以及,根据检测结果,确定待处理图像中的障碍物信息。由此,结合深度估计网络和目标检测网络进行障碍物检测,首先利用深度网络获得图像的深度信息,并将该深度信息用于目标检测网络对障碍物的检测中,这样,目标检测网络能够获得更多的图像信息,有利于目标检测网络得到更加准确的检测结果。从而,障碍物检测模型具有较好的鲁棒性,能够保证障碍物检测模型在不同场景中的检测准确性。
本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本公开的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但并不构成对本公开的限制。在附图中:
图1是根据本公开的一种实施方式提供的图像处理方法的流程图;
图2是根据本公开提供的图像处理方法中,获得障碍物检测模型的一种示例性的流程图;
图3是根据本公开的一种实施方式提供的障碍物检测方法的流程图;
图4是根据本公开的一种实施方式提供的图像处理装置的框图;
图5是根据本公开的一种实施方式提供的障碍物检测装置的框图;
图6是根据一示例性实施例示出的一种电子设备的框图。
具体实施方式
以下结合附图对本公开的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本公开,并不用于限制本公开。
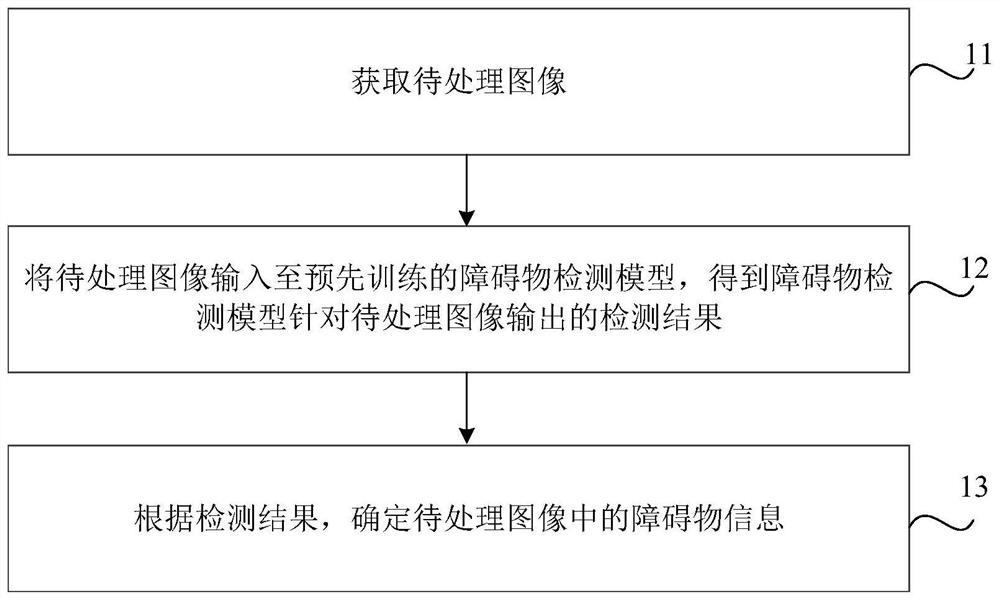
图1是根据本公开的一种实施方式提供的图像处理方法的流程图。如图1所示,该方法可以包括以下步骤:
在步骤11中,获取待处理图像;
在步骤12中,将待处理图像输入至预先训练的障碍物检测模型,得到障碍物检测模型针对待处理图像输出的检测结果;
在步骤13中,根据检测结果,确定待处理图像中的障碍物信息。
其中,障碍物检测模型包括深度估计网络和目标检测网络。深度估计网络用于根据待处理图像得到第一输出内容,第一输出内容能够反映待处理图像的深度信息。目标检测网络用于根据第一输出内容得到检测结果。
示例地,深度估计网络可以为单目深度估计网络。单目深度估计网络利用三维立体视觉技术,通过优化帧与帧之间的重投影误差来重建出图片中障碍物的深度,通常不需要进行标注,而仅需输入连续帧图片,它可以做到零成本迭代,同时,由于存在立体视觉的约束,单目深度估计网络的泛化性能会比无约束的方式表现更好,特别是在近处障碍物的召回率表现上,一般不会出现漏检障碍物的问题。
深度估计网络的输出可以为热图(Heatmap,以颜色变化来显示数据的矩阵),用于表示输入至深度估计网络的图像的深度信息。相应地,第一输出内容可以为热图形式的内容,以反映待处理图像的深度信息。
示例地,目标检测网络可以为基于三维边框(3D bounding box)的目标检测网络。它可以通过预先标注图像中障碍物的方式,将图像和标注信息输入神经网络,通过反向传播算法训练出神经网络模型,训练得到的神经网络模型具备检测与输入图像(及相似场景)的障碍物检测能力。另外,目标检测网络也可以为基于二维边框(2D bounding box)的目标检测网络。
以及,若深度估计网络为单目深度估计网络,且目标检测网络为基于三维边框的目标检测网络,通过二者相结合的方式,能够在保证障碍物检测结果准确性的同时,提高障碍物检测的召回率,特别是在近距离障碍物检测场景中,从而,能够有效保证行车安全,降低行驶风险。
在一种可能的实施方式中,障碍物检测模型可以通过步骤21~步骤27获得,如图2所示:
在步骤21中,获取多组训练数据;
在步骤22中,构建初始检测模型;
在步骤23中,利用样本图像序列和样本图像序列对应的深度信息,对初始深度估计网络进行训练,以获得训练完成的深度估计网络;
在步骤24中,根据样本图像序列和训练完成的深度估计网络,获得训练完成的深度估计网络针对样本图像序列输出的第二输出内容;
在步骤25中,根据样本图像序列和第二输出内容,得到训练输入数据;
在步骤26中,利用训练输入数据和样本图像序列对应的障碍物信息,对初始目标检测网络进行训练,以获得训练完成的目标检测网络;
在步骤27中,根据训练完成的深度估计网络和训练完成的目标检测网络,获得障碍物检测模型。
根据步骤21,获取多组训练数据。其中,每一组训练数据包括样本图像序列、样本图像序列对应的深度信息以及样本图像序列对应的障碍物信息。样本图像序列对应的深度信息为样本图像序列中各帧图像对应的深度图像。样本图像序列对应的障碍物信息为样本图像序列中各帧图像中存在的障碍物的类型信息和位置信息。
样本图像序列中包括在时间上连续的多帧图像。样本图像序列对应的深度信息可以为样本图像序列中各帧图像对应的深度信息,例如,可以为样本图像序列中各帧图像对应的带有深度信息的热图。样本图像序列对应的障碍物信息可以为样本图像序列中各帧图像的障碍物信息。示例地,样本图像序列对应的障碍物信息可以为样本图像序列中各帧图像中障碍物(可以为一个或多个)对应的位置信息。再例如,样本图像序列对应的障碍物信息可以为样本图像序列中各帧图像中障碍物(可以为一个或多个)对应的类型信息和位置信息。其中,障碍物对应的类型信息可以根据经验或实际需求进行规定、设置。障碍物对应的位置信息可以为障碍物在图像中的坐标,例如,用于标识障碍物位置的边框的顶点坐标(如四边形边框的四个顶点)。
在获得训练数据之后,可以开始进行模型训练。首先,需要执行步骤22,构建初始检测模型,也就是构建合适的模型结构,并以此为基础进行训练,其中,初始检测模型包括初始深度估计网络和初始目标检测网络。本公开提供的方法是基于深度估计网络和目标检测网络共同实现的障碍物检测,因此,可以根据现有的深度估计网络的结构设置初始深度估计网络,同时,根据现有的目标检测网络的结构设置初始目标检测网络。
之后,执行步骤23,利用样本图像序列和样本图像序列对应的深度信息,对初始深度估计网络进行训练,以获得训练完成的深度估计网络。
示例地,步骤23可以通过以下方式获得训练完成的深度估计网络:
将目标样本图像序列输入至本次训练所使用的深度估计网络中,获得本次训练所使用的深度估计网络输出的第三输出内容;
根据第三输出内容和目标样本图像序列对应的深度信息,确定本次训练的第一损失值;
若不满足第一训练停止条件,利用第一损失值更新本次训练所使用的深度估计网络,并将更新后的深度估计网络用于下一次训练;
若满足第一训练停止条件,将本次训练所使用的深度估计网络作为训练完成的深度估计网络。
初次训练所使用的深度估计网络为初始深度估计网络。以及,目标样本图像序列为本次训练所使用的样本图像序列。
将目标样本图像序列输入至本次训练所使用的深度估计网络中,能够获得本次训练所使用的深度估计网络输出的第三输出内容。第三输出内容与第一输出内容所反映的信息相同,也就是说,第三输出内容用于反映目标样本图像序列的深度信息,它包括本次训练所使用的深度估计网络针对目标图像序列中每一帧图像输出的深度信息(例如,目标图像序列中每一帧图像对应的带有深度信息的热图)。
在获得第三输出内容后,第三输出内容为实际输出,目标样本图像序列对应的深度信息为期望输出,确定二者之间的差异,即本次训练的第一损失值。
若不满足第一训练停止条件,利用第一损失值更新本次训练所使用的深度估计网络,并将更新后的深度估计网络用于下一次训练,而若满足第一训练停止条件,将本次训练所使用的深度估计网络作为训练完成的深度估计网络。
在一种可能的实施例中,第一训练停止条件可以为与第一损失值相关的条件。例如,第一损失值小于第一损失阈值,则若第一损失值小于第一损失阈值,确定满足第一训练停止条件,将本次训练所使用的深度估计网络作为训练完成的深度估计网络,若第一损失值大于第一损失阈值,确定不满足第一训练停止条件,利用第一损失值更新本次训练所使用的深度估计网络,并将更新后的深度估计网络用于下一次训练。第一损失值等于第一损失阈值的情况可以根据实际的需求归入满足或不满足第一训练停止条件的任何一种情况中。其中,利用损失值更新网络参数的方式属于现有技术,此处不赘述。
在另一种可能的实施例中,第一训练停止条件也可以为与第一损失值无关的条件,例如,训练次数达到预设次数、训练时长达到预设时长等。若训练次数达到预设次数,可以确定满足第一训练停止条件,其他的情况此处不再一一列举。
需要说明的是,若第一训练停止条件为与第一损失值无关的条件,则判断是否满足第一训练停止条件可以在获得本次训练的输出结果之后、且在计算第一损失值之前进行,若本次训练满足第一训练停止条件,则无需再计算第一损失值,从而减少不必要的数据处理。
在得到训练完成的深度估计网络之后,该训练完成的深度估计网络具备了对图像进行深度估计的基本能力,后续可以以此为基础进一步训练目标检测网络。
在步骤24中,根据样本图像序列和训练完成的深度估计网络,获得训练完成的深度估计网络针对样本图像序列输出的第二输出内容。
在步骤25中,根据样本图像序列和第二输出内容,得到训练输入数据。
其中,第二输出内容为样本图像序列中每一帧图像对应的深度图像,例如,前文所述的热图。
相应地,步骤25可以包括以下步骤:
分别将样本图像序列中的每一帧图像作为目标图像,执行如下操作,以得到训练输入数据:
将目标图像与目标图像在第二内容中对应的深度图像进行拼接。
也就是说,针对样本图像序列中的每一帧图像,将该图像的原图和该图像的深度图像进行拼接,得到训练输入数据。训练输入数据包括一个样本图像序列对应的拼接图像。这样,拼接后的图像既包含有原图像的信息,又包含原图像的深度信息,这样,使得参与训练的图像具备了更多的信息,有利于目标检测网络的准确性提升。其中,原图一般为RGB图像,具有三个颜色通道的信息,拼接处理相当于将深度信息作为图像的第四通道,共同参与训练。
在步骤26中,利用训练输入数据和样本图像序列对应的障碍物信息,对初始目标检测网络进行训练,以获得训练完成的目标检测网络。
示例地,步骤26可以通过以下方式获得训练完成的目标检测网络:
将目标训练输入数据输入至本次训练所使用的目标检测网络中,获得本次训练所使用的目标检测网络输出的第四输出内容;
根据第四输出内容和目标训练输入数据对应的障碍物信息,确定本次训练的第二损失值;
若不满足第二训练停止条件,利用第二损失值更新本次训练所使用的目标检测网络,并将更新后的目标检测网络用于下一次训练;
若满足第二训练停止条件,将本次训练所使用的目标检测网络作为训练完成的目标检测网络。
初次训练所使用的目标检测网络为初始目标检测网络,以及,目标训练输入数据为本次训练所使用的训练输入数据。
将目标训练输入数据输入至本次训练所使用的目标检测网络中,能够获得本次训练所使用的目标检测网络输出的第四输出内容。第四输出内容用于反映目标训练输入数据的障碍物信息,它包括本次训练所使用的目标检测网络针对目标图像序列中每一帧图像输出的障碍物信息。
在获得第四输出内容后,第四输出内容为实际输出,目标训练输入数据对应的障碍物信息为期望输出,确定二者之间的差异,即本次训练的第二损失值。
若不满足第二训练停止条件,利用第二损失值更新本次训练所使用的目标检测网络,并将更新后的目标检测网络用于下一次训练,而若满足第二训练停止条件,将本次训练所使用的目标检测网络作为训练完成的目标检测网络。
在一种可能的实施例中,第二训练停止条件可以为与第二损失值相关的条件。例如,第二损失值小于第二损失阈值,则若第二损失值小于第二损失阈值,确定满足第二训练停止条件,将本次训练所使用的目标检测网络作为训练完成的目标检测网络,若第二损失值大于第二损失阈值,确定不满足第二训练停止条件,利用第二损失值更新本次训练所使用的目标检测网络,并将更新后的目标检测网络用于下一次训练。第二损失值等于第二损失阈值的情况可以根据实际的需求归入满足或不满足第二训练停止条件的任何一种情况中。其中,利用损失值更新网络参数的方式属于现有技术,此处不赘述。
在另一种可能的实施例中,第二训练停止条件也可以为与第二损失值无关的条件,例如,训练次数达到预设次数、训练时长达到预设时长等。若训练次数达到预设次数,可以确定满足第二训练停止条件,其他的情况此处不再一一列举。
需要说明的是,若第二训练停止条件为与第二损失值无关的条件,则判断是否满足第二训练停止条件可以在获得本次训练的输出结果之后、且在计算第二损失值之前进行,若本次训练满足第二训练停止条件,则无需再计算第二损失值,从而减少不必要的数据处理。
在步骤27中,根据训练完成的深度估计网络和训练完成的目标检测网络,获得障碍物检测模型。
在获得训练完成的深度估计网络和训练完成的目标检测网络,可以根据二者得到障碍物检测模型。其中,障碍物检测模型可以依次由训练完成的深度估计网络、图像拼接处理网络和训练完成的目标检测网络构成。
参见图1,在步骤13中,根据检测结果,确定待处理图像中的障碍物信息。
在一种可能的实施例中,检测结果可以包括待处理图像中存在的障碍物的类型信息和位置信息,相应地,步骤13可以包括以下步骤:
根据检测结果,确定待处理图像中指定类型的障碍物所对应的位置信息。
这样,可以根据检测结果确定待处理图像中同类型障碍物对应的位置信息。
通过上述技术方案,获取待处理图像,将待处理图像输入至预先训练的障碍物检测模型,得到障碍物检测模型针对待处理图像输出的检测结果,其中,障碍物检测模型包括深度估计网络和目标检测网络;深度估计网络用于根据待处理图像得到第一输出内容,第一输出内容能够反映待处理图像的深度信息;目标检测网络用于根据第一输出内容得到检测结果,以及,根据检测结果,确定待处理图像中的障碍物信息。由此,结合深度估计网络和目标检测网络进行障碍物检测,首先利用深度网络获得图像的深度信息,并将该深度信息用于目标检测网络对障碍物的检测中,这样,目标检测网络能够获得更多的图像信息,有利于目标检测网络得到更加准确的检测结果。从而,障碍物检测模型具有较好的鲁棒性,能够保证障碍物检测模型在不同场景中的检测准确性。
图3是根据本公开的一种实施方式提供的障碍物检测方法的流程图。如图3所示,该方法可以包括以下步骤:
在步骤31中,在车辆行驶过程中,获取车辆周边的环境图像;
在步骤32中,根据本公开提供的图像处理方法,确定环境图像对应的目标障碍物信息;
在步骤33中,根据目标障碍物信息,对车辆进行驾驶控制。
在车辆行驶过程中,可以通过设置于车身的摄像头获取车辆周边的环境图像,例如,车辆前方的环境图像、车辆后方的环境图像等。
在获取到环境图像之后,根据本公开任意实施例提供的图像处理方法,可以确定出环境图像对应的目标障碍物信息。其中,目标障碍物信息至少包括障碍物的位置信息。可选地,目标障碍物信息还可以包括障碍物的类型信息,也就是,车辆周边的障碍物是何种障碍物。障碍物的类型可以根据实际的需求预先规定,例如,障碍物可以分为静态障碍物(例如,路标)、动态障碍物等(例如,其他车辆、行人等)。
在获得目标障碍物信息后,可以根据目标障碍物信息,对车辆进行驾驶控制。例如,上述步骤可以应用于车辆的自动驾驶场景中。
通过上述技术方案,在车辆行驶过程中,获取车辆周边的环境图像,根据本公开提供的图像处理方法,确定环境图像对应的目标障碍物信息,根据目标障碍物信息,对车辆进行驾驶控制。由于本公开提供的图像处理方法能够有效提升障碍物检测的准确性,从而,在行车场景中,能够有效提升行车安全。
图4是根据本公开的一种实施方式提供的图像处理装置的框图,如图4所示,所述装置40包括:
第一获取模块41,用于获取待处理图像;
图像处理模块42,用于将所述待处理图像输入至预先训练的障碍物检测模型,得到所述障碍物检测模型针对所述待处理图像输出的检测结果,其中,所述障碍物检测模型包括深度估计网络和目标检测网络;所述深度估计网络用于根据所述待处理图像得到第一输出内容,所述第一输出内容能够反映所述待处理图像的深度信息;所述目标检测网络用于根据所述第一输出内容得到所述检测结果;
第一确定模块43,用于根据所述检测结果,确定所述待处理图像中的障碍物信息。
可选地,所述深度估计网络为单目深度估计网络,所述目标检测网络为基于三维边框的目标检测网络。
可选地,所述装置40通过以下模块获得所述障碍物检测模型:
第二获取模块,用于获取多组训练数据,每一组所述训练数据包括样本图像序列、所述样本图像序列对应的深度信息以及所述样本图像序列对应的障碍物信息,所述样本图像序列中包括在时间上连续的多帧图像;
初始化模块,用于构建初始检测模型,所述初始检测模型包括初始深度估计网络和初始目标检测网络;
第一训练模块,用于利用所述样本图像序列和所述样本图像序列对应的深度信息,对所述初始深度估计网络进行训练,以获得训练完成的深度估计网络;
第一中间处理模块,用于根据所述样本图像序列和训练完成的深度估计网络,获得训练完成的深度估计网络针对所述样本图像序列输出的第二输出内容;
第二中间处理模块,用于根据所述样本图像序列和所述第二输出内容,得到训练输入数据;
第二训练模块,用于利用所述训练输入数据和所述样本图像序列对应的障碍物信息,对所述初始目标检测网络进行训练,以获得训练完成的目标检测网络;
所述装置40用于根据所述训练完成的深度估计网络和所述训练完成的目标检测网络,获得所述障碍物检测模型。
可选地,所述第一训练模块包括:
第一输入子模块,用于将目标样本图像序列输入至本次训练所使用的深度估计网络中,获得本次训练所使用的深度估计网络输出的第三输出内容,其中,目标样本图像序列为本次训练所使用的样本图像序列,并且,初次训练所使用的深度估计网络为所述初始深度估计网络;
第一确定子模块,用于根据所述第三输出内容和所述目标样本图像序列对应的深度信息,确定本次训练的第一损失值;
第一更新子模块,用于若不满足第一训练停止条件,利用所述第一损失值更新本次训练所使用的深度估计网络,并将更新后的深度估计网络用于下一次训练;
所述第一训练模块用于若满足所述第一训练停止条件,将本次训练所使用的深度估计网络作为训练完成的深度估计网络。
可选地,所述第二输出内容为所述样本图像序列中每一帧图像对应的深度图像;
所述第二中间处理模块用于分别将所述样本图像序列中的每一帧图像作为目标图像,执行如下操作,以得到训练输入数据:
将所述目标图像与所述目标图像在所述第二内容中对应的深度图像进行拼接。
可选地,所述第二训练模块包括:
第二输入子模块,用于将目标训练输入数据输入至本次训练所使用的目标检测网络中,获得本次训练所使用的目标检测网络输出的第四输出内容,其中,目标训练输入数据为本次训练所使用的训练输入数据,并且,初次训练所使用的目标检测网络为所述初始目标检测网络;
第二确定子模块,用于根据所述第四输出内容和所述目标训练输入数据对应的障碍物信息,确定本次训练的第二损失值;
第二更新子模块,用于若不满足第二训练停止条件,利用所述第二损失值更新本次训练所使用的目标检测网络,并将更新后的目标检测网络用于下一次训练;
所述第二训练模块用于若满足所述第二训练停止条件,将本次训练所使用的目标检测网络作为训练完成的目标检测网络。
可选地,所述样本图像序列对应的深度信息为所述样本图像序列中各帧图像对应的深度图像;
所述样本图像序列对应的障碍物信息为所述样本图像序列中各帧图像中存在的障碍物的类型信息和位置信息。
可选地,所述检测结果包括所述待处理图像中存在的障碍物的类型信息和位置信息;
所述第一确定模块43用于根据所述检测结果,确定所述待处理图像中指定类型的障碍物所对应的位置信息。
图5是根据本公开的一种实施方式提供的障碍物检测装置的框图,如图5所示,所述装置50包括:
第三获取模块51,用于在车辆行驶过程中,获取车辆周边的环境图像;
第二确定模块52,用于根据本公开第一方面所提供的方法,确定所述环境图像对应的目标障碍物信息;
控制模块53,用于根据所述目标障碍物信息,对所述车辆进行驾驶控制。
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
本公开还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本公开任意实施例所提供的图像处理方法的步骤,或者,该程序被处理器执行时实现本公开任意实施例所提供的障碍物检测方法的步骤。
本公开还提供一种车辆,包括:
存储器,其上存储有计算机程序;
处理器,用于执行所述存储器中的所述计算机程序,以实本公开任意实施例所提供的图像处理方法的步骤,或者,实现本公开任意实施例所提供的障碍物检测方法的步骤。
图6是根据一示例性实施例示出的一种电子设备1900的框图。例如,电子设备1900可以被提供为一服务器。参照图6,电子设备1900包括处理器1922,其数量可以为一个或多个,以及存储器1932,用于存储可由处理器1922执行的计算机程序。存储器1932中存储的计算机程序可以包括一个或一个以上的每一个对应于一组指令的模块。此外,处理器1922可以被配置为执行该计算机程序,以执行上述的图像处理方法或障碍物检测方法。
另外,电子设备1900还可以包括电源组件1926和通信组件1950,该电源组件1926可以被配置为执行电子设备1900的电源管理,该通信组件1950可以被配置为实现电子设备1900的通信,例如,有线或无线通信。此外,该电子设备1900还可以包括输入/输出(I/O)接口1958。电子设备1900可以操作基于存储在存储器1932的操作系统,例如WindowsServer
在另一示例性实施例中,还提供了一种包括程序指令的计算机可读存储介质,该程序指令被处理器执行时实现上述的图像处理方法或障碍物检测方法的步骤。例如,该计算机可读存储介质可以为上述包括程序指令的存储器1932,上述程序指令可由电子设备1900的处理器1922执行以完成上述的图像处理方法或障碍物检测方法。
在另一示例性实施例中,还提供一种计算机程序产品,该计算机程序产品包含能够由可编程的装置执行的计算机程序,该计算机程序具有当由该可编程的装置执行时用于执行上述的图像处理方法或障碍物检测方法的代码部分。
以上结合附图详细描述了本公开的优选实施方式,但是,本公开并不限于上述实施方式中的具体细节,在本公开的技术构思范围内,可以对本公开的技术方案进行多种简单变型,这些简单变型均属于本公开的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本公开对各种可能的组合方式不再另行说明。
此外,本公开的各种不同的实施方式之间也可以进行任意组合,只要其不违背本公开的思想,其同样应当视为本公开所公开的内容。
- 图像处理方法、障碍物检测方法、装置、介质及车辆
- 障碍物检测方法、装置、车辆、计算机设备和存储介质