一种融合题目难度的知识追踪方法及系统
文献发布时间:2023-06-19 11:02:01
技术领域
本发明属于知识追踪技术领域,更具体地,涉及一种融合题目难度的知识追踪方法及系统。
背景技术
知识追踪(Knowledge Tracing)的目的是表示学习者的知识掌握状态。而当前的知识追踪模型主要根据学习者历史的题目回答记录,建模学习者的知识学习过程,预测学习者未来回答题目的表现。其输入一般是学习者的题目回答记录,输出是学习者正确回答下一题目的概率。
可以看出,当前的知识追踪模型将“学习者正确回答下一题目的概率”视为学习者的知识掌握状态。显然,仅仅使用“学习者正确回答下一题目的概率”作为学习者的知识掌握状态并不完善,它仅能对学习者的表现进行结果预测,而没有对学习者回答题目的过程进行判断。本发明引入题目难度表示,使知识追踪模型在预测学习者表现的同时,预测题目对学习者的难度,增强当前知识追踪模型在表示学习者知识掌握状态的表示。
知识追踪领域有多个经典的模型,例如深度知识跟踪模型(Deep KnowledgeTracing,DKT)、卷积知识追踪模型(Convolutional Knowledge Tracing,CKT)、动态关键值记忆网络知识追踪模型(Dynamic Key-Value Memory Networks,DKVMN)。
其中,DKVMN模型在引入题目难度方面进行了初步的探索,但是其直接使用题目的嵌入表示k
发明内容
针对现有技术的至少一个缺陷或改进需求,本发明提供了一种融合题目难度的知识追踪方法及系统,使知识追踪模型在预测学习者表现的同时,预测题目对学习者的难度,增强当前知识追踪模型在表示学习者知识掌握状态的表示。
为实现上述目的,按照本发明的第一方面,提供了一种融合题目难度的知识追踪方法,包括步骤:
获取t时刻学习者回答的题目q
获取概念矩阵M
根据交互信息计算题目难度d
将题目q
计算获得学习者对题目q
将总体掌握程度ks
训练预测模型,训练的目标是最小化预测正确率pr
优选的,所述交互信息包括学习者回答题目q
优选的,还包括步骤:根据题目q
优选的,所述对掌握程度矩阵
将题目q
qd
其中D
根据题目q
将题目q
qr
其中D
根据题目q
优选的,所述根据交互信息计算题目难度d
d
N(o
优选的,w
其中,
优选的,ks
其中N为所有概念的总数量。
优选的,预测正确率pr
[pr
其中
按照本发明的第二方面,提供了一种融合题目难度的知识追踪方法,包括步骤:
获取学习者要回答的题目,将要回答的题目输入到训练好的预测模型,输出学习者回答该题目的预测正确率以及该题目对学习者的预测难度,所述预测模型的训练采用上述任一项所述的方法得到。
按照本发明的第三方面,提供了一种融合题目难度的知识追踪系统,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。
总体而言,本发明与现有技术相比,具有有益效果:
(1)使知识追踪模型在预测学习者正确率的同时,预测题目对学习者的难度,增强当前知识追踪模型在学习者知识掌握状态方面的表示,进而可以提升知识追踪技术在各项应用中的价值。
(2)在预测正确率和题目难度时,创造性地提出根据历史数据中的题目、答案和回答时交互信息来进行预测,能够提升预测的精确度。
(3)在对表示学习者记忆状态的概念掌握程度矩阵进行更新时,根据题目、答案和交互信息三者进行更新,即同时考虑了题目难度对概念掌握程度矩阵的作用,以及题目答案正确与否对概念掌握程度矩阵的作用。
附图说明
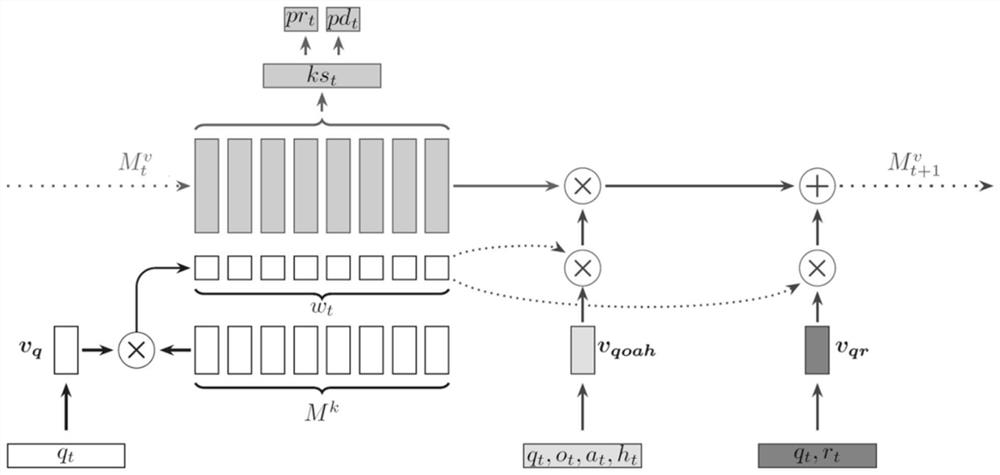
图1是本发明实施例的融合题目难度的知识追踪方法的原理示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明实施例的一种融合题目难度的知识追踪方法,包括步骤:
S1,获取t时刻学习者回答的题目q
知识追踪是根据学习者的历史记录,建模学习者的知识学习过程,预测学习者未来回答题目的表现。
将历史记录中t时刻学习者所要回答的题目记作q
以下实施例中以交互信息包括(o
S2,获取概念矩阵M
假设,学习者要回答的题目总数记作Q;所有题目中涉及到的概念记作{c
S3,定义题目难度,根据交互信息计算题目难度d
问答题目过程所用的总时间o
d
N(o
题目难度的定义并非固定的,可以根据需要灵活调整。
S4,相关权重定义,计算相关权重。
题目q
其中
S5,计算获得学习者对题目q
当学习者回答题目q
其中,
S6,将总体掌握程度ks
使用一个全连接层输出学习者的表现pr
[pr
其中
S7,训练预测模型,训练的目标是最小化预测正确率pr
优选的,损失函数为:
S8.题目难度作用过程。
学习者回答q
由嵌入矩阵
qd
其中D
题目难度对概念的掌握程度矩阵
S9.题目答案作用过程。元组(q
qr
其中R
学习者题目答案正确与否将对概念的掌握程度矩阵
采用上述知识追踪方法获取的预测模型进行知识追踪,获取学习者要回答的下一个题目,将要回答的下一个题目输入到训练好的预测模型,输出学习者回答该题目的预测正确率以及该题目对学习者的预测难度。在六个benchmark数据集上,本发明实施例(DFKT)与三个现有模型(DKT、DKVMN、SAKT)的实验结果对比如下表所示。
本实施例还提供了一种融合题目难度的知识追踪系统,其包括至少一个处理器、以及至少一个存储器,其中,存储器中存储有计算机程序,当计算机程序被处理器执行时,使得处理器执行上述实施例任一知识追踪方法的步骤,此处不再赘述;本实施例中,处理器和存储器的类型不作具体限制,例如:处理器可以是微处理器、数字信息处理器、片上可编程逻辑系统等;存储器可以是易失性存储器、非易失性存储器或者它们的组合等。
必须说明的是,上述任一实施例中,方法并不必然按照序号顺序依次执行,只要从执行逻辑中不能推定必然按某一顺序执行,则意味着可以以其他任何可能的顺序执行。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种融合题目难度的知识追踪方法及系统
- 一种基于协同嵌入增强题目表示的知识追踪方法及系统