一种动植物育种值预测方法及装置
文献发布时间:2023-06-19 11:05:16
技术领域
本发明涉及育种值预测技术,特别地,涉及一种动植物育种值预测方法及装置。
背景技术
育种值是指种畜的种用价值。在数量遗传学中把决定数量性状的基因加性效应值定义为育种值(BV),个体育种值的估计值叫做估计育种值(EBV)。预测动植物的育种值对于动植物育种具有重要意义,但是传统的预测方法可大体上分为直接法、间接法两类,直接法如GBLUP、ssGBLUP等,间接法如BayesA、BayesB、BayesC等。
标准GBLUP方法假定所有标记都存在效应,不对标记进行筛选,采用所有分子标记构建亲缘矩阵,进而对混合模型方程组进行求解,得到育种值的预测值。Bayes方法通过模拟抽样得到各标记的效应值,进而由标记效应值对育种值进行预测。但是,标准基因组最佳无偏线性预测(GBLUP)不能够有效的利用高密度标记信息,基因组预测准确性的提高受到限制,迭代ssGBLUP可以提高预测准确性,但缺乏高效的并行计算方法,预测速度较慢,而BayesB、BayesC、BayesR等基于贝叶斯统计的基因组预测方法需要通过抽样来估计标记效应,这个过程通常是耗时的,同时也占用大量的内存资源,并且一些研究表明这些基于贝叶斯方法的基因组预测并不总是优于标准GBLUP。
因此,现有育种值预测方法预测准确率低、计算负担大并且消耗时间长。
发明内容
为了克服现有技术的不足,本发明提供一种动植物育种值预测方法及装置,以解决现有育种值预测方法预测准确率低、计算负担大并且消耗时间长的问题。
本发明解决其技术问题所采用的技术方案是:
一方面,
一种动植物育种值预测方法,包括以下步骤:
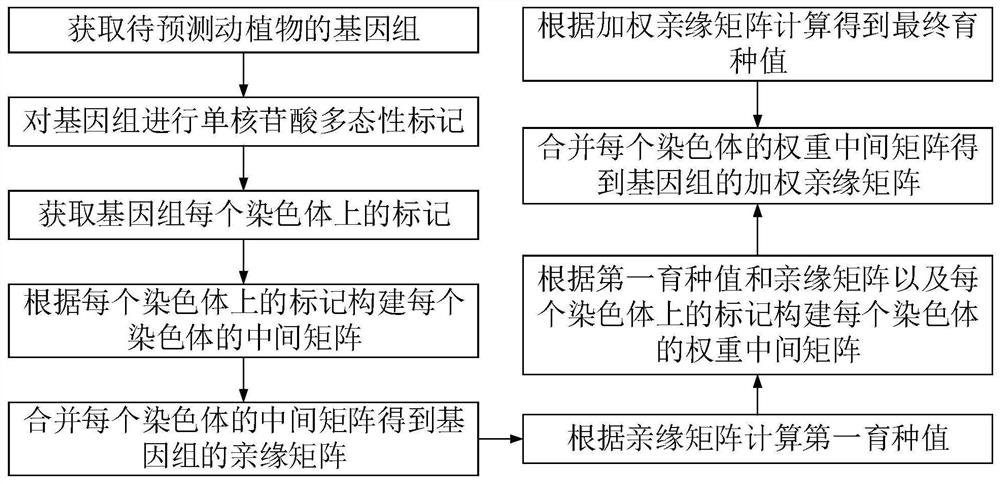
获取待预测动植物的基因组;
对所述基因组进行单核苷酸多态性标记;
获取所述基因组每个染色体上的所述标记;
根据每个染色体上的所述标记构建每个染色体的中间矩阵;
合并每个染色体的中间矩阵得到所述基因组的亲缘矩阵;
根据所述亲缘矩阵计算第一育种值;
根据所述第一育种值和所述亲缘矩阵以及每个染色体上的所述标记构建每个染色体的权重中间矩阵;
合并每个染色体的权重中间矩阵得到所述基因组的加权亲缘矩阵;
根据所述加权亲缘矩阵计算得到最终育种值。
进一步地,所述根据每个染色体上的所述标记构建每个染色体的中间矩阵包括:
将每个染色体依次分为多段,除最后一段外每段包括预设数值的所述标记;
分别依次读取每段上的标记,将依次读取的所述标记组成标记矩阵;
根据所述标记矩阵计算每段的矩阵;
将每段的矩阵相加得到所述每个染色体的中间矩阵。
进一步地,所述根据所述标记矩阵计算每段的矩阵包括:
将所述标记矩阵乘以所述标记矩阵的转置矩阵得到每段的矩阵。
进一步地,所述合并每个染色体的中间矩阵得到所述基因组的亲缘矩阵包括:
计算每个染色体的变量;
根据所述变量和所述中间矩阵计算得到所述基因组的亲缘矩阵,计算公式为:
其中,G为亲缘矩阵,n为染色体数目,B
进一步地,所述计算每个染色体的变量包括:
计算每段的变量,计算公式为:
将每段的变量相加得到每个染色体的变量。
进一步地,所述根据所述亲缘矩阵计算第一育种值包括:
根据所述亲缘矩阵和混合模型方程组计算第一育种值;其中所述混合模型为:
y=μ+F*g+e
其中,y表示表型向量,μ为整体均值,g为第一育种值EBV1,g服从正态分布:
进一步地,所述根据所述第一育种值和所述亲缘矩阵以及每个染色体上的所述标记构建每个染色体的权重中间矩阵包括:
根据所述第一育种值和所述亲缘矩阵计算向量v,计算公式为:v=G
根据所述计算向量计算每个染色体每段的标记效应a,计算公式为:a=Z′v,其中Z’为标记矩阵Z的转置矩阵;
根据所述标记效应获取对角矩阵D
根据所述对角矩阵计算得到每段的加权矩阵△P
将每段的加权矩阵和每段的加权变量计相加得到每个染色体的加权矩阵P
进一步地,所述合并每个染色体的权重中间矩阵得到所述基因组的加权亲缘矩阵包括:
对各染色体生成的W
进一步地,所述根据所述加权亲缘矩阵计算得到最终育种值包括:
根据所述加权亲缘矩阵和混合模型方程组求解最终育种值,所述混合模型为:
y=μ+F*g+e
其中,y表示表型向量,μ为整体均值,g为最终育种值EBV2,g服从正态分布:
另一方面,一种动植物育种值预测装置,包括:
基因组获取模块,用于获取待预测动植物的基因组;
基因组标记模块,用于对所述基因组进行单核苷酸多态性标记;
标记获取模块,用于获取所述基因组每个染色体上的所述标记;
中间矩阵构建模块,用于根据每个染色体上的所述标记构建每个染色体的中间矩阵;
亲缘矩阵获取模块,用于合并每个染色体的中间矩阵得到所述基因组的亲缘矩阵;
第一育种值计算模块,用于根据所述亲缘矩阵计算第一育种值;
权重中间矩阵构建模块,用于根据所述第一育种值和所述亲缘矩阵以及每个染色体上的所述标记构建每个染色体的权重中间矩阵;
加权亲缘矩阵获取模块,用于合并每个染色体的权重中间矩阵得到所述基因组的加权亲缘矩阵;
最终育种值计算模块,用于根据所述加权亲缘矩阵计算得到最终育种值。
本申请采用以上技术方案,至少具备以下有益效果:
本申请技术方案提供一种动植物育种值预测方法及装置,在获取到基因组后,对基因组进行单核苷酸多态性标记,然后获取每个染色体的标记,对每个染色体的标记构建中间矩阵,合并所有染色体的中间矩阵得到基因组的亲缘矩阵,然后由亲缘矩阵计算得到第一育种值,之后根据第一育种值和亲缘矩阵为每个染色体的标记构建权重中间矩阵,由权重中间矩阵得到基因组的加权亲缘矩阵,最后根据加权亲缘矩阵计算得到最终的育种值。本申请方案提供的预测方法,在计算得到第一育种值之后,根据第一育种值对每个染色体的标记进行加权,无需假定所有标记都存在效应,有效利用高密度标记信息,提高了最终育种值的准确率,同时计算过程简单,降低了预测时间和计算成本。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种动植物育种值预测方法流程图;
图2是本发明实施例提供的一种动植物育种值预测装置结构图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面结合附图和实施例对本发明的技术方案进行详细的描述说明。显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本申请所保护的范围。
参照图1,本发明实施例提供一种动植物育种值预测方法,包括以下步骤:
获取待预测动植物的基因组;
对基因组进行单核苷酸多态性标记;
获取基因组每个染色体上的标记;
根据每个染色体上的标记构建每个染色体的中间矩阵;
合并每个染色体的中间矩阵得到基因组的亲缘矩阵;
根据亲缘矩阵计算第一育种值;
根据第一育种值和亲缘矩阵以及每个染色体上的标记构建每个染色体的权重中间矩阵;
合并每个染色体的权重中间矩阵得到基因组的加权亲缘矩阵;
根据加权亲缘矩阵计算得到最终育种值。
本发明实施例提供的一种动植物育种值预测方法及装置,在获取到基因组后,对基因组进行单核苷酸多态性标记,然后获取每个染色体的标记,对每个染色体的标记构建中间矩阵,合并所有染色体的中间矩阵得到基因组的亲缘矩阵,然后由亲缘矩阵计算得到第一育种值,之后根据第一育种值和亲缘矩阵为每个染色体的标记构建权重中间矩阵,由权重中间矩阵得到基因组的加权亲缘矩阵,最后根据加权亲缘矩阵计算得到最终的育种值。本发明实施例提供的预测方法,在计算得到第一育种值之后,根据第一育种值对每个染色体的标记进行加权,无需假定所有标记都存在效应,有效利用高密度标记信息,提高了最终育种值的准确率,同时计算过程简单,降低了预测时间和计算成本。
作为对上述实施例的补充说明,首先需要解释的是,单核苷酸多态性(singlenucleotide polymorphism,SNP),主要是指在基因组水平上由单个核苷酸的变异所引起的DNA序列多态性。它是人类可遗传的变异中最常见的一种。占所有已知多态性的90%以上。SNP在人类基因组中广泛存在,平均每500~1000个碱基对中就有1个,估计其总数可达300万个甚至更多。SNP适于快速、规模化筛查。
组成DNA的碱基虽然有4种,但SNP一般只有两种碱基组成,所以它是一种二态的标记,即二等位基因(biallelic)。由于SNP的二态性,非此即彼,在基因组筛选中SNPs往往只需+/-的分析,而不用分析片段的长度,这就利于发展自动化技术筛选或检测SNPs。采用单核苷酸多态性标记是数量遗传学中常用的技术手段,在此不在赘述。
一些可选实施例中,根据每个染色体上的标记构建每个染色体的中间矩阵包括:
将每个染色体依次分为多段,除最后一段外每段包括预设数值的标记;分别依次读取每段上的标记,将依次读取的标记组成标记矩阵;根据标记矩阵计算每段的矩阵;具体地,将标记矩阵乘以标记矩阵的转置矩阵得到每段的矩阵;最终将每段的矩阵相加得到每个染色体的中间矩阵。
作为本发明实施例一种可选的实现方式,合并每个染色体的中间矩阵得到基因组的亲缘矩阵包括:
计算每个染色体的变量;具体地,计算每段的变量,计算公式为:
其中,G为亲缘矩阵,n为染色体数目,B
作为本发明实施例一种可选的实现方式,根据亲缘矩阵计算第一育种值包括:根据亲缘矩阵和混合模型方程组计算第一育种值;其中混合模型为:
y=μ+F*g+e
其中,y表示表型向量,μ为整体均值,g为第一育种值EBV1,g服从正态分布:
得到第一育种值后,根据第一育种值和亲缘矩阵计算向量v,计算公式为:v=G
将每段的加权矩阵和每段的加权变量计相加得到每个染色体的加权矩阵P
进一步地,对各染色体生成的W
最后,根据加权亲缘矩阵和混合模型方程组求解最终育种值,混合模型为:
y=μ+F*g+e
其中,y表示表型向量,μ为整体均值,g为最终育种值EBV2,
示例性的,(1)将全基因组SNP标记按染色体进行切分,即按照每个染色体的标记进行统计。
(2)对各染色体分别构建中间矩阵G
(3)对各染色生成的中间G
(4)由亲缘矩阵G及混合模型方程组求解育种值EBV1。所用模型为:
y=μ+F*g+e
y表示表型向量,μ为整体均值,g为加性遗传效应即育种值EBV1,
(5)由育种值EBV1及基因组亲缘矩阵G及各染色SNP标记计算各标记权重,根据权重构建中间矩阵W
(6)对各染色体生成的W
(7)由加权亲缘矩阵W及混合模型方程组求解育种值EBV2,作为最终的育种值。所用模型为:
y=μ+F*g+e
y表示表型向量,μ为整体均值,g为加性遗传效应即育种值EBV2,
需要说明的是,本发明实施例提供的预测方法在计算得到第一育种值之后,根据第一育种值计算标记的权重,然后得到最终育种值,在实际应用过程中,还可以再次根据最终育种值计算标记的权重,重复得到育种值,但是多次计算标记权重预测的准确率并不一定比本发明实施例采用的方法预测的准确率高;而且,没有多次计算标记权重,会加大计算成本,降低预测速度,因此一般都只计算一次标记的权重。
一个实施例中,本发明实施例提供一种动植物育种值预测装置,如图2所示,包括:
基因组获取模块21,用于获取待预测动植物的基因组;
基因组标记模块22,用于对基因组进行单核苷酸多态性标记;
标记获取模块23,用于获取基因组每个染色体上的标记;
中间矩阵构建模块24,用于根据每个染色体上的标记构建每个染色体的中间矩阵;具体地,中间矩阵构建模块将每个染色体依次分为多段,除最后一段外每段包括预设数值的标记;分别依次读取每段上的标记,将依次读取的标记组成标记矩阵;根据标记矩阵计算每段的矩阵,即将标记矩阵乘以标记矩阵的转置矩阵得到每段的矩阵;将每段的矩阵相加得到每个染色体的中间矩阵。
亲缘矩阵获取模块25,用于合并每个染色体的中间矩阵得到基因组的亲缘矩阵;具体地,亲缘矩阵获取模块计算每个染色体的变量;进一步地,计算每段的变量,计算公式为:
其中,G为亲缘矩阵,n为染色体数目,B
第一育种值计算模块26,用于根据亲缘矩阵计算第一育种值;具体地,第一育种值计算模块根据亲缘矩阵和混合模型方程组计算第一育种值;其中混合模型为:
y=μ+F*g+e
其中,y表示表型向量,μ为整体均值,g为第一育种值EBV1,g服从正态分布:
权重中间矩阵构建模块27,用于根据第一育种值和亲缘矩阵以及每个染色体上的标记构建每个染色体的权重中间矩阵;具体地,权重中间矩阵构建模块根据第一育种值和亲缘矩阵计算向量v,计算公式为:v=G
加权亲缘矩阵获取模块28,用于合并每个染色体的权重中间矩阵得到基因组的加权亲缘矩阵;具体地,加权亲缘矩阵获取模块对各染色体生成的W
最终育种值计算模块29,用于根据加权亲缘矩阵计算得到最终育种值。具体地,最终育种值计算模块根据加权亲缘矩阵和混合模型方程组求解最终育种值,混合模型为:
y=μ+F*g+e
其中,y表示表型向量,μ为整体均值,g为最终育种值EBV2,
本发明实施例提供的一种动植物育种值预测装置,基因组获取模块获取待预测动植物的基因组;基因组标记模块对基因组进行单核苷酸多态性标记;标记获取模块获取基因组每个染色体上的标记;中间矩阵构建模块根据每个染色体上的标记构建每个染色体的中间矩阵;亲缘矩阵获取模块合并每个染色体的中间矩阵得到基因组的亲缘矩阵;第一育种值计算模块根据亲缘矩阵计算第一育种值;权重中间矩阵构建模块根据第一育种值和亲缘矩阵以及每个染色体上的标记构建每个染色体的权重中间矩阵;加权亲缘矩阵获取模块合并每个染色体的权重中间矩阵得到基因组的加权亲缘矩阵;最终育种值计算模块根据加权亲缘矩阵计算得到最终育种值。本发明实施例提供的预测装置,通过分段计算,加快计算效率,同时在计算得到第一育种值后,根据第一育种值计算标记的权重,重新得到最终育种值,使预测得到的最终育种值准确率大大提高。
为了更清楚的说明本申请的方案,本发明实施例提供一组实验。包括以下步骤:
1采用软件QMSim模拟基因组数据与表型数据。共模拟5条染色体,每条染色体长度为100cM,每条染色体标记数量为400k,为便于描述将遗传距离转化为物理距离1cM=1e6bp,bp(base paire)是指DNA序列的基本组成单位。通过400个世代的随机交配构建历史群体,在第1世代(历史群体)有效群体大小为1000,从第1世代到第300世代有效群体数量下降为300,从300世代到400世代有效群体下降为200。从第400世代中随机选取20个雄性,100个雌性为G0代,随机交配20个世代,每组交配产生的子代数量为20,保留G18~G20代个体基因型,以G18,G19为训练群体,以G20为预测群体。对三种类型的性状进行模拟(遗传力分别为0.1,0.3,0.5),每种类型重复10次。
2 SNP标记按染色体切分及过滤
将SNP标记按染色体进行切分并对标记进行过滤,过滤掉等位基因频率小于1e-5的标记。
3对各染色体分别构建中间矩阵G
对各染色,分别顺次读取N个(N为任意正整数,N大于标记数目时,将读取整个文件)SNP标记,计算矩阵A
4对各染色生成的中间G
5由亲缘矩阵G及混合模型方程组求解育种值EBV1。所用模型为:
y=μ+F*g+e
y表示表型向量,μ为整体均值,g为加性遗传效应即育种值EBV1,
6由育种值EBV1及基因组亲缘矩阵G及各染色SNP标记计算各标记权重,根据权重构建中间矩阵W
7对各染色体生成的W
8由加权亲缘矩阵W及混合模型方程组求解育种值EBV2,作为最终的育种值。所用模型为:
y=μ+F*g+e
y表示表型向量,μ为整体均值,g为加性遗传效应即育种值EBV2,
9预测准确性
预测准确性采用训练群体预测育种值与真实育种值的相关系数来进行评价。对遗传力为0.1、0.3、0.5的三种类型性状,EBV1的准确性分别为0.76648、0.89863、0.93105,EBV2的准确性分别为0.78166、0.91179、0.94244,EBV2较EBV1准确性分别提高2.2%、1.5%、1.2%。
10时间、内存消耗
通过分段并行计算,总的时间消耗可降低为非并行计算的1/k(理想状态,各分块标记数目近似),k为分段数目。当标记总数远大于样本个数时,通过分段读取,可显著降低内存消耗,约为非分段读取的V/U,V为个体数目,U为标记数目。
可以理解的是,上述各实施例中相同或相似部分可以相互参考,在一些实施例中未详细说明的内容可以参见其他实施例中相同或相似的内容。
需要说明的是,在本申请的描述中,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本申请的描述中,除非另有说明,“多个”的含义是指至少两个。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本申请的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本申请的实施例所属技术领域的技术人员所理解。
应当理解,本申请的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(PGA),现场可编程门阵列(FPGA)等。
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
此外,在本申请各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
上述提到的存储介质可以是只读存储器,磁盘或光盘等。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本申请的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施例进行变化、修改、替换和变型。
- 一种动植物育种值预测方法及装置
- 一种估计基因组育种值的方法及装置