名称歧义消除模型的处理方法、系统和存储介质
文献发布时间:2023-06-19 11:05:16
技术领域
本发明涉及大数据处理技术领域,尤其是一种名称歧义消除模型的处理方法、系统和存储介质。
背景技术
作者名消歧是图书馆面临的一个难题,机构知识库(Institutional Repository,IR)的内容建设也同样面临作者名消歧的问题。IR通常会汇集不同来源的知识产出数据,由于作者署名的多样性,同一科研人员发表在不同期刊或被不同数据库收录的文章其作者姓名样式具有多样性。在检索发现某一科研人员成果,或进行机构知识资产审计分析时,都需要明确每一篇产出具体对应的科研人员。如果不能很好地解决作者名消歧问题,将不利于IR作品的统计分析,也不利于作品的传播交流。目前名称消歧的方法主要可以分为两类:基于特征的方法和基于拓扑的方法。但是,由于目前的名称消歧的方法均没有充分利用已标注数据的隐藏信息,因而导致名称歧义的消除结果精度不高。
发明内容
本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种名称歧义消除模型的处理方法、系统和存储介质,能够有效提高名称歧义消除结果的精度。
根据本发明的第一方面实施例的一种名称歧义消除模型的处理方法,包括以下步骤:
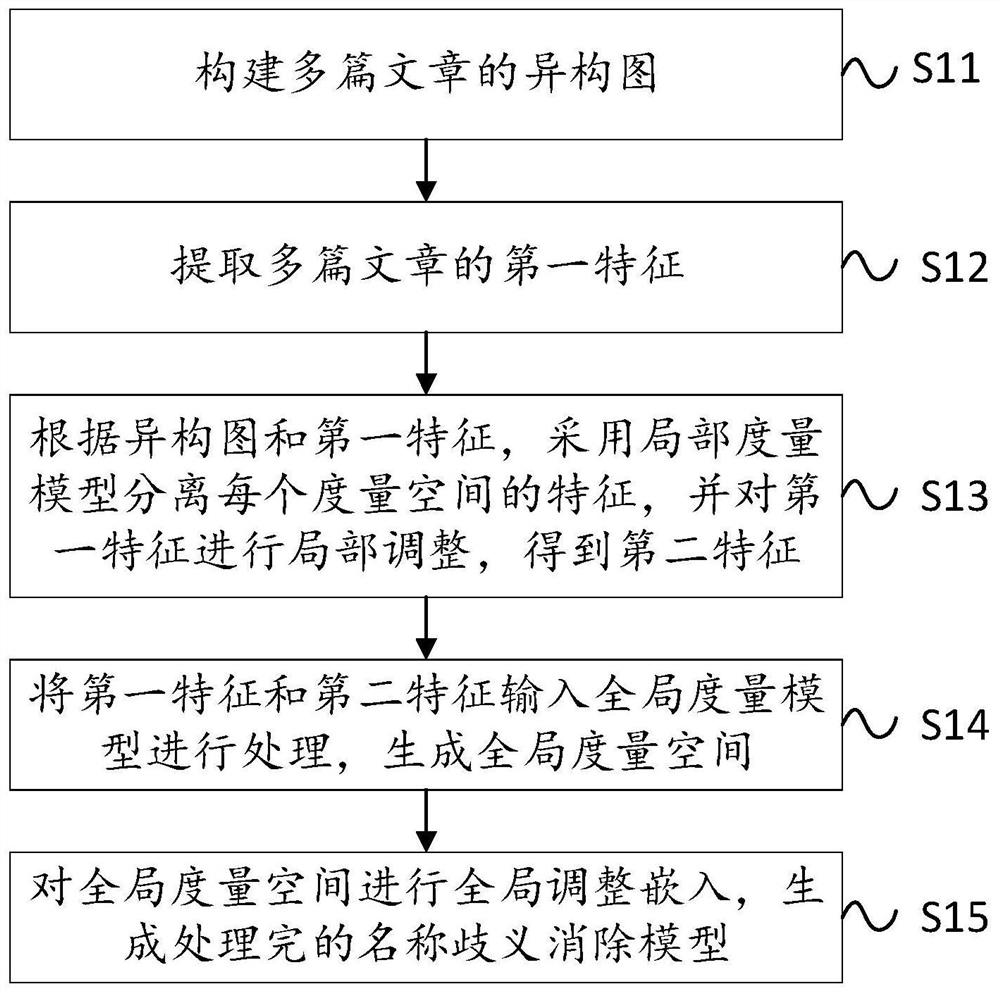
构建多篇文章的异构图;
提取多篇文章的第一特征;
根据所述异构图和所述第一特征,采用局部度量模型分离每个度量空间的特征,并对第一特征进行局部调整,得到第二特征;
将所述第一特征和所述第二特征输入全局度量模型进行处理,生成全局度量空间;
对所述全局度量空间进行全局调整嵌入,生成处理完的名称歧义消除模型。
根据本发明实施例的一种名称歧义消除模型的处理方法,至少具有如下有益效果:本实施例通过根据异构图和第一特征,采用局部度量模型分离每个度量空间的特征,并对第一特征进行局部调整,得到第二特征后,将第一特征和第二特征输入全局度量模型进行处理,生成全局度量空间,接着对全局度量空间进行全局调整嵌入,生成处理完的名称歧义消除模型,使得本实施例的名称歧义消除模型在应用过程中,能够充分利用已标注数据的隐藏信息,以有效提高名称歧义消除结果的精度。
根据本发明的一些实施例,所述异构图包括与文章相关主题连接图和与文章相似作者连接图。
根据本发明的一些实施例,所述局部度量模型包括特征感知注意子模型、语义感知注意子模型和类感知注意子模型;所述采用局部度量模型分离每个度量空间的特征,包括:
采用所述特征感知注意子模型获取所述异构图中每个节点的邻居的重要性;
采用所述语义感知注意子模型获取所述异构图中不同元路径的重要性;
采用所述类感知注意子模型计算第一特征与文章标签的语义关系。
根据本发明的一些实施例,所述特征感知注意子模型为基于邻居差异的特征感知注意子模型。
根据本发明的一些实施例,所述对第一特征进行局部调整,其具体为:
通过重要性满足要求的邻居对第一特征进行局部调整。
根据本发明的一些实施例,所述第一特征包括原始正样本、原始标记样本和原始负样本;所述第二特征包括局部正样本、局部标记样本和局部负样本。
根据本发明的一些实施例,所述将所述第一特征和所述第二特征输入全局度量模型进行处理,生成全局度量空间,包括:
通过所述第一特征和所述第二特征对所述全局度量模型进行训练,并通过损失函数确定训练进度;
在完成训练后,生成全局度量空间。
根据本发明的第二方面实施例的一种名称歧义消除模型的处理系统,包括:
构建模块,用于构建多篇文章的异构图;
提取模块,用于提取多篇文章的第一特征;
局部度量空间处理模块,用于根据所述异构图和所述第一特征,采用局部度量模型分离每个度量空间的特征,并对第一特征进行局部调整,得到第二特征;
全局度量空间处理模块,用于将所述第一特征和所述第二特征输入全局度量模型进行处理,生成全局度量空间;
生成模块,用于对所述全局度量空间进行全局调整嵌入,生成处理完的名称歧义消除模型。
根据本发明的第三方面实施例的一种名称歧义消除模型的处理系统,包括:
至少一个存储器,用于存储程序;
至少一个处理器,用于加载所述程序以执行第一方面实施例所述的名称歧义消除模型的处理方法。
根据本发明的第四方面实施例的一种存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于执行第一方面实施例所述的名称歧义消除模型的处理方法。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
下面结合附图和实施例对本发明做进一步的说明,其中:
图1为本发明实施例的一种名称歧义消除模型的处理方法的流程图;
图2为一种实施例的名称歧义消除模型的模块框图;
图3为一种实施例的局部度量模型处理流程图;
图4为一种实施例的全局度量模型的体系结构图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
在本发明的描述中,若干的含义是一个以上,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。如果有描述到第一、第二只是用于区分技术特征为目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量或者隐含指明所指示的技术特征的先后关系。
本发明的描述中,除非另有明确的限定,设置等词语应做广义理解,所属技术领域技术人员可以结合技术方案的具体内容合理确定上述词语在本发明中的具体含义。
本发明的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
参照图1,本发明实施例提供了一种名称歧义消除模型的处理方法,本实施例可应用于服务器或者各类应用平台的后台处理器。其中,名称歧义消除模型如图2所示,其包括局部度量模型、局部调整嵌入模型、全局度量模型和全局调整嵌入模型。局部度量模型用于分离每个度量空间中的特征。局部调整嵌入模型用于调整到全局层次的所有文档。全局度量模型用于同一嵌入并生成同一的全局度量空间。
在应用过程中,本实施例包括以下步骤:
S11、构建多篇文章的异构图。其中,异构图包括与文章相关主题连接图PSP和与文章相似作者连接图PAP。
S12、提取多篇文章的第一特征。具体地,第一特征包括原始正样本、原始标记样本和原始负样本,其均为多篇文字的特征。
S13、根据异构图和第一特征,采用局部度量模型分离每个度量空间的特征,并对第一特征进行局部调整,得到第二特征。局部度量模型包括特征感知注意子模型、语义感知注意子模型和类感知注意子模型。其中,特征感知注意子模型为基于邻居差异的特征感知注意子模型。第二特征包括局部正样本、局部标记样本和局部负样本。
步骤采用局部度量模型分离每个度量空间的特征,其具体包括以下步骤:
采用特征感知注意子模型获取异构图中每个节点的邻居的重要性;
采用语义感知注意子模型获取异构图中不同元路径的重要性;
采用类感知注意子模型计算第一特征与文章标签的语义关系。
而步骤对第一特征进行局部调整,其具体为:通过重要性满足要求的邻居对第一特征进行局部调整。重要性满足要求的邻居是指对当前节点有意义的邻居。
S14、将第一特征和第二特征输入全局度量模型进行处理,生成全局度量空间。
在一些实施例中,步骤S14可通过以下方式实现:
通过第一特征和所述第二特征对全局度量模型进行训练,并通过损失函数确定训练进度;并在完成训练后,生成全局度量空间。
S15、对全局度量空间进行全局调整嵌入,生成处理完的名称歧义消除模型。
具体地,上述实施例可分为局部度量模型处理过程和全局度量模型处理过程。
其中,局部度量模型处理过程为:
在全局度量模型的统一和聚合之前,设定D
特征感知注意子模型注意到每篇论文的邻居扮演不同的角色,并且对于微调的特征表现出不同的重要性。为了计算每篇论文中邻居的重要性,引入了基于邻居差异的特征感知注意。随着节点的发散,聚集有意义邻居的表示来微调嵌入。给定一个通过元路径Φ连接的纸对(i,j),特征感知注意力可以了解重要性
att
通过隐藏注意将结构信息注入到模型中,这意味着只计算节点
然后,基于元路径的文章i的嵌入可以通过具有公式3所示的相应系数的邻居的投影特征来聚集:
由于异构图呈现无标度特性,图数据的方差很大。为了应对上述挑战,将特征感知注意力扩展到多头注意力,以使训练过程更加稳定。具体来说,重复特征感知注意K次,并将学习到的嵌入连接为语义特定的嵌入,其具体公式4所示:
给定元集合{PAP,PSP},在将节点特征输入特征感知注意后,我们可以获得语义特定的嵌入,表示为{Z
语义级注意通常,异构图中的每篇文章都包含多种类型的语义信息。为了学习更全面的论文嵌入,需要融合多个语义,这些语义可以通过元路径来揭示。在本实施例中,引入了一个语义级的注意机制来自动学习不同元路径的重要性,并将它们融合以进行语义感知嵌入。将从特征感知注意中学习到的嵌入作为输入,通过非线性变换对嵌入进行变换。然后,将语义特定嵌入的重要性度量为转换嵌入与语义级关注向量q的相似性。每个元路径的重要性表示为
W为权重矩阵,b为偏向向量,q为语义层面的注意向量。v表示顶点数。
为了进行有意义的比较,上面的所有参数对于所有元路径和语义特定的嵌入都是共享的。在获得每个元路径的重要性之后,通过softmax函数对它们进行规范化。元路径φ
在本实施例中,通过引入了一种注意机制来发现论文与其类的综合特征关系。具体来说,通过两个向量的点积来度量它们之间的相容性。给定的类上下文向量是每个类的中心
softmax操作用于归一化所有类别上的文章语义关系,并用于估计特征与其标签的语义关系,即标签的正确程度。
局部度量学习最后,整合由等式计算的配对权重。公式7进入传统的对比损失来制定本实施例的如给那个是8所示的加权对比损失:
L
全局度量模型处理过程为:
在用拓扑信息微调特征后,每个候选集的嵌入变得更有区别。然而,每个候选的嵌入是由不同的度量空间来度量的。为了解决这个问题,提出了一个如图4所示的全局度量模型来生成一个全局度量空间,并将不同的候选集嵌入到一个统一的空间中。
首先,引入一个变换函数f:X
具体地,每个训练示例由两组组成。一种是三元组原始嵌入,另一种是三元组局部嵌入。f1和F2是密集布局以生成全局度量空间和局部统一度量空间。f3将全局度量空间与局部统一度量空间混合。
其中T是训练集中所有可能的三元组的集合,m是在正对和负对之间强制的余量。定义损失函数L
m分别表示节点i和节点i对应的正标签之间的loss-与节点i和节点j对应负标签之间的loss+的边界或阈值;L
L
其中,w
综上,本实施例提出了一个度量学习框架的名称歧义消除模型来度量相似样本并生成一个度量空间。该名称歧义消除模型由局部度量模型和全局度量模型组成。在局部度量模型中,提出了一个层次图注意力网络和一个基于注意力的度量学习损失,以生成更全面和有区别的嵌入。在全局度量模型中,提出了一个统一的模型来统一嵌入和生成度量空间。最后,将提出的框架与一些著名的度量学习方法和一些最先进的名字消歧方法进行了比较可知,本实施例能取得较好的性能。
本发明实施例提供了一种名称歧义消除模型的处理系统,包括:
构建模块,用于构建多篇文章的异构图;
提取模块,用于提取多篇文章的第一特征;
局部度量空间处理模块,用于根据所述异构图和所述第一特征,采用局部度量模型分离每个度量空间的特征,并对第一特征进行局部调整,得到第二特征;
全局度量空间处理模块,用于将所述第一特征和所述第二特征输入全局度量模型进行处理,生成全局度量空间;
生成模块,用于对所述全局度量空间进行全局调整嵌入,生成处理完的名称歧义消除模型。
本发明方法实施例的内容均适用于本系统实施例,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法达到的有益效果也相同。
本发明实施例提供了一种名称歧义消除模型的处理系统,包括:
至少一个存储器,用于存储程序;
至少一个处理器,用于加载所述程序以执行如图1所示的名称歧义消除模型的处理方法。
本发明方法实施例的内容均适用于本系统实施例,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法达到的有益效果也相同。
本发明实施例提供了一种存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于执行如图1所示的名称歧义消除模型的处理方法。
本发明实施例还公开了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存介质中。计算机设备的处理器可以从存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行图1所示的方法。
上面结合附图对本发明实施例作了详细说明,但是本发明不限于上述实施例,在所属技术领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。此外,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。
- 名称歧义消除模型的处理方法、系统和存储介质
- 一种利用个人词向量消除关键词歧义的个性化搜索模型