将人物行为转化为虚拟动画的系统及方法
文献发布时间:2023-06-19 11:06:50
技术领域
本发明涉及虚拟现实技术领域,具体涉及一种将人物行为转化为虚拟动画的系统及方法。
背景技术
虚拟现实(VR)是指借助计算机系统及传感器技术人为创造一个三维场景,在这个人造的三维场景中,每个物体相对于系统的坐标系都有一个位置与姿态,用户看到的景象是由用户的位置和头(眼)的方向来确定的。虚拟现实创造出一种崭新的人机交互状态,通过调动用户所有的感官(视觉、听觉、触觉、嗅觉等),带来更加真实的、身临其境的体验,广泛应用于媒体、社交、教育等领。
目前,虚拟现实教学广泛应用于在线课程教学中,学生通过观看虚拟现实课堂就能够在沉浸式的环境同时进行知识课程的学习,这不仅有利于提高学生的学习兴趣,并且还有助于改善学生的学习效率。
现有的未来课堂动画生成方式需要单独建立模型、单独绘制动作和单独配音,工作量大,效率低,成本高,不利于大范围推广,并且模型动作简单,声音没有立体感,使用者代入感低,学习效率低。
发明内容
针对现有技术的不足,本发明的目的在于提供一种虚拟现实技术的场景拼装系统及方法,解决现有技术用户使用时代入感低的问题。
为实现上述目的,本发明提供如下技术方案:一种将人物行为转化为虚拟动画的系统,其特征在于,包括:
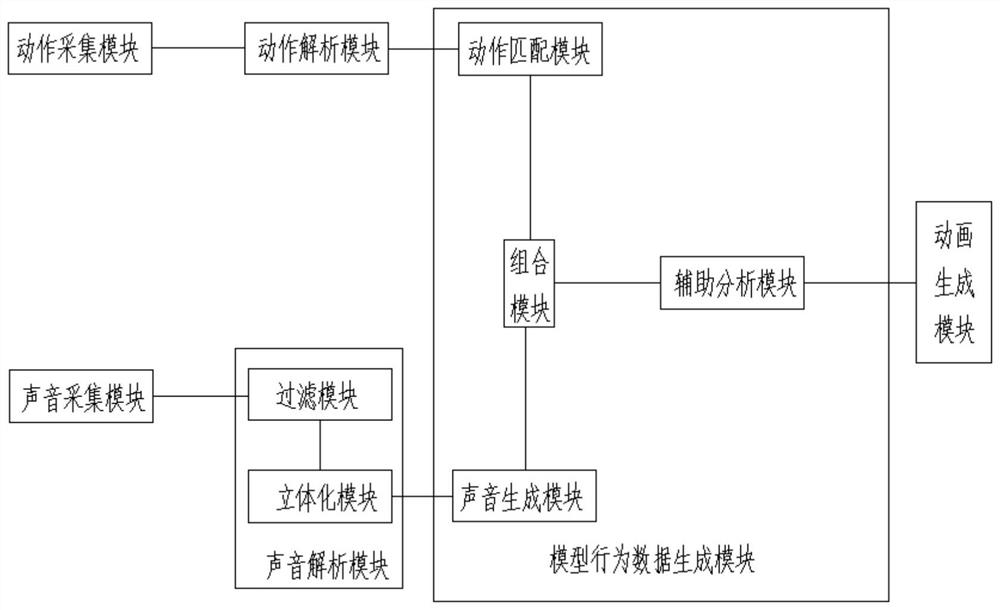
关联模块:用于将人物与资源库中的模型绑定,所述模型拥有多个属性数据;
动作采集模块:用于采集人物的实时动作信息;
声音采集模块:用于采集人物的实时声音信息;
信息解析模块:用于对实时动作信息和实时声音信息进行解析,生成实时动作参数信息和多方位声音信息;
模型行为数据生成模块:用于将实时动作参数信息与模型的属性数据进行匹配,得到虚拟动作数据;将多方位声音信息进行处理生成虚拟声音数据;同时将虚拟声音数据与虚拟动作数据组合生成模型行为数据;
动画生成模块:用于根据模型行为数据生成与人物行为一致的虚拟动画。
进一步限定,所述信息解析模块具体包括:
动作解析模块:用于将实时动作信息解析为实时动作参数信息,所述实时动作参数信息包括动作部位信息、位移信息和角度信息,所述属性数据包括骨骼信息、动画信息和边缘信息;
声音解析模块:用于将实时声音信息处理为多个不同方位的声音信息,生成多方位声音信息;
所述模型行为数据生成模块具体包括:
匹配模块具体为将动作部位信息与模型的骨骼信息绑定,同时将单个位移信息和单个角度信息与模型的单个动画信息进行匹配,得到单个虚拟动作数据;
声音生成模块:用于将多方位声音信息进行编码生成虚拟声音数据;
组合模块:用于将单个虚拟动作数据与虚拟声音数据组合,生成模型行为数据。
进一步限定,所述声音解析模块具体包括:
过滤模块:用于将实时声音信息滤波降噪处理,得到降噪声音数据;
立体化模块:用于将降噪声音数据进行多方位处理,生成多方位声音信息。
进一步限定,所述模型行为数据生成模块还包括:
动作融合模块:用于将多组单个虚拟动作数据进行融合,得到同步动作的组合虚拟动作数据;
所述组合模块具体为:用于将单个虚拟动作数据或组合虚拟动作数据和与之对应的虚拟声音数据组合,生成模型行为数据。
进一步限定,所述模型行为数据生成模块还包括:
辅助分析模块:用于将模型行为数据与模型的边缘信息进行对比分析,判断模型行为数据与所要发生的空间域是否有冲突;若有,则发出提醒并拦截模型行为数据;若无,则传输至动画生成模块。
一种将人物行为转化为虚拟动画的方法,其特征在于,所述方法包括以下步骤:
1)将人物与资源库中的模型绑定,所述模型拥有多个属性数据;
2)采集人物的实时动作信息和人物的实时声音信息;
3)对实时动作信息和实时声音信息进行解析,生成实时动作参数信息和多方位声音信息;
4)将实时动作参数信息与模型的属性数据进行匹配,得到虚拟动作数据;将多方位声音信息进行处理生成虚拟声音数据;同时将虚拟声音数据与虚拟动作数据组合生成模型行为数据;
5)根据模型行为数据生成与人物行为一致的虚拟动画。
进一步限定,所述步骤3)和步骤4)具体分别为:
3)将实时动作信息解析为实时动作参数信息,实时动作参数信息包括动作部位信息、位移信息和角度信息,属性数据包括骨骼信息、动画信息和边缘信息;将实时声音信息处理为多个不同方位的声音信息,生成多方位声音信息;
4)将动作部位信息与模型的骨骼信息绑定,同时将单个位移信息和单个角度信息与模型的单个动画信息进行匹配,得到单个虚拟动作数据;将多方位声音信息进行编码生成虚拟声音数据;将单个虚拟动作数据与虚拟声音数据组合,生成模型行为数据。
进一步限定,所述步骤3)中将多方位声音信息进行编码生成虚拟声音数据具体为:
将实时声音信息滤波降噪处理,得到降噪声音数据;将降噪声音数据进行多方位处理,得到多方位声音信息。
进一步限定,所述步骤4)还包括:
4)将动作部位信息与模型的骨骼信息绑定,同时将多个位移信息和多个角度信息与模型的多个动画信息进行匹配,得到多个虚拟动作数据,将多个虚拟动作数据进行融合得到同步动作的组合虚拟动作数据;将多方位声音信息进行编码生成虚拟声音数据;将单个虚拟动作数据或组合虚拟动作数据和与之对应的虚拟声音数据组合,生成模型行为数据。
进一步限定,所述步骤4)还包括:
4)将模型行为数据与模型的边缘信息进行对比分析,判断模型行为数据与所要发生的空间域是否有冲突;若有,则发出提醒并拦截模型行为数据;若无,则执行步骤5)。
本发明的有益效果在于:通过将实时采集的动作与声音信息与模型固有属性进行匹配,得到虚拟动画,提高动画的多样性,同时提高虚拟动画制作的简易型,降低难度,提高工作效率;通过将声音进行立体化处理,使得动画更立体,用户代入感更强,从而提高用户的工作效率。
附图说明
图1为单个虚拟动作数据的动画生成系统示意图;
图2为多个虚拟动作数据的动画生成系统示意图;
图3为单个虚拟动作数据的动画生成方法流程图;
图4为多个虚拟动作数据的动画生成方法流程图。
具体实施方式
实施例1
参考图1和图2,本发明涉及一种将人物行为转化为虚拟动画的系统,包括
关联模块:用于将人物与资源库中的模型绑定,所述模型拥有多个属性数据;
动作采集模块:用于采集人物的实时动作信息;
声音采集模块:用于采集人物的实时声音信息;
信息解析模块:用于对实时动作信息和实时声音信息进行解析,生成实时动作参数信息和多方位声音信息,具体包括动作解析模块和声音解析模块;
动作解析模块:用于将实时动作信息解析为实时动作参数信息,所述实时动作参数信息包括动作部位信息、位移信息和角度信息,所述属性数据包括骨骼信息、动画信息和边缘信息;
声音解析模块:用于将实时声音信息处理为多个不同方位的声音信息,生成多方位声音信息,具体包括过滤模块和立体化模块;
过滤模块:用于将实时声音信息滤波降噪处理,得到降噪声音数据;
立体化模块:用于将降噪声音数据进行多方位处理,生成多方位声音信息;
模型行为数据生成模块:用于将实时动作参数信息与模型的属性数据进行匹配,得到虚拟动作数据;将多方位声音信息进行处理生成虚拟声音数据;同时将虚拟声音数据与虚拟动作数据组合生成模型行为数据,具体包括匹配模块、声音生成模块、组合模块和动作融合模块;
匹配模块:具体为将动作部位信息与模型的骨骼信息绑定,同时将单个位移信息和单个角度信息与模型的单个动画信息进行匹配,得到单个虚拟动作数据;
声音生成模块:用于将多方位声音信息进行编码生成虚拟声音数据;
动作融合模块:用于将多组单个虚拟动作数据进行融合,得到同步动作的组合虚拟动作数据;
组合模块:用于将单个虚拟动作数据或组合虚拟动作数据和与之对应的虚拟声音数据组合,生成模型行为数据;
辅助分析模块:用于将模型行为数据与模型的边缘信息进行对比分析,判断模型行为数据与所要发生的空间域是否有冲突;若有,则发出提醒并拦截模型行为数据;若无,则传输至动画生成模块;
动画生成模块:用于根据模型行为数据生成与人物行为一致的虚拟动画。
实施例2
参考图3和图4,本发明涉及一种将人物行为转化为虚拟动画的方法,包括以下步骤:
1)将人物与资源库中的模型绑定,所述模型拥有多个属性数据,例如将人物与模型库中的卡通教师模型绑定;
2)采集人物的实时动作信息和人物的实时声音信息,例如抬胳膊和抬腿的动作以及讲解的声音;
3)将实时动作信息解析为实时动作参数信息,实时动作参数信息包括动作部位信息、位移信息和角度信息,属性数据包括骨骼信息、动画信息和边缘信息;将实时声音信息滤波降噪处理,得到降噪声音数据;将降噪声音数据进行多方位处理,得到多方位声音信息,例如将抬胳膊和抬腿的动作解析为胳膊和腿部动作部位的信息、胳膊和腿位移信息以及胳膊和腿转动角度的信息,将讲解声音中的噪音进行滤除,得到降噪声音数据,从而提高声音的清晰度,将降噪声音数据进行多方位处理,得到多个不同方位的多方位声音信息,并且符合近大远小的公知常识;
4)将动作部位信息与模型的骨骼信息绑定,同时将单个位移信息和单个角度信息与模型的单个动画信息进行匹配,得到单个虚拟动作数据,例如将人物的胳膊与模型的胳膊骨骼信息绑定,人物的腿与模型的腿部骨骼信息绑定,同时将抬胳膊的位移信息和角度信息与模型的抬胳膊动画信息匹配,将抬腿的位移信息和角度信息与模型的抬腿动画信息匹配,得到抬胳膊和抬腿依次进行的虚拟动作数据;
当动画信息为多组同时进行的,则将动作部位信息与模型的骨骼信息绑定,同时将多个位移信息和多个角度信息与模型的多个动画信息进行匹配,得到多个虚拟动作数据,将多个虚拟动作数据进行融合得到同步动作的组合虚拟动作数据,例如抬腿与抬胳膊是同时进行的,则将生成的抬胳膊虚拟动作数据和抬腿虚拟动作数据进行融合,得到抬腿与抬胳膊同步动作的组合虚拟动作数据;
将多方位声音信息进行编码生成虚拟声音数据,例如将讲解声音的多个不同方位的多方位声音信息进行编码生成具有立体感的虚拟声音数据;
将单个虚拟动作数据或组合虚拟动作数据和与之对应的虚拟声音数据组合,生成模型行为数据将单个虚拟动作数据与虚拟声音数据组合,生成模型行为数据,将上述生成的抬胳膊和抬腿依次进行的虚拟动作数据或抬腿与抬胳膊同步动作的组合虚拟动作数据与虚拟声音数据组合,生成模型行为数据;
将模型行为数据与模型的边缘信息进行对比分析,判断模型行为数据与所要发生的空间域是否有冲突;若有,则发出提醒并拦截模型行为数据;若无,则执行步骤5),例如将抬胳膊与抬腿的虚拟动作与模型的边缘信息对比分析,判断抬胳膊和抬手的动作是否与所在空间有重叠或交叉造成视觉干扰,如果有,就进行提醒并且模型行为数据不进行下一步步骤,如果没有就执行下一步步骤;
5)根据模型行为数据生成与人物行为一致的虚拟动画,例如模型行为数据解码生成与人物行为一致的抬胳膊和胎腿的动作,同时讲解声音同步进行。
- 将人物行为转化为虚拟动画的系统及方法
- 实现源数据实时转化为虚拟机镜像的系统及方法