基于LightGBM决策树算法的个贷类不良资产风险评级方法
文献发布时间:2023-06-19 11:08:20
技术领域
本申请涉及一种风险评级方法,具体而言,涉及一种基于LightGBM决策树算法的个贷类不良资产风险评级方法。
背景技术
个贷类不良资产属于金融不良资产,是指银行持有的次级、可疑及损失类贷款,金融资产管理公司收购或者接管的金融不良债权,以及其他非银行金融机构持有的不良债权。现有的个贷类不良资产评级主要围绕资产的价值评估,往往后续动作是通过ABS资产转包的方式进行资产处置,而以不良资产的回款可能性方面的风险评级几乎没有,评估方法大多基于个人经验、非常主观,且考虑的因素不全面。
发明内容
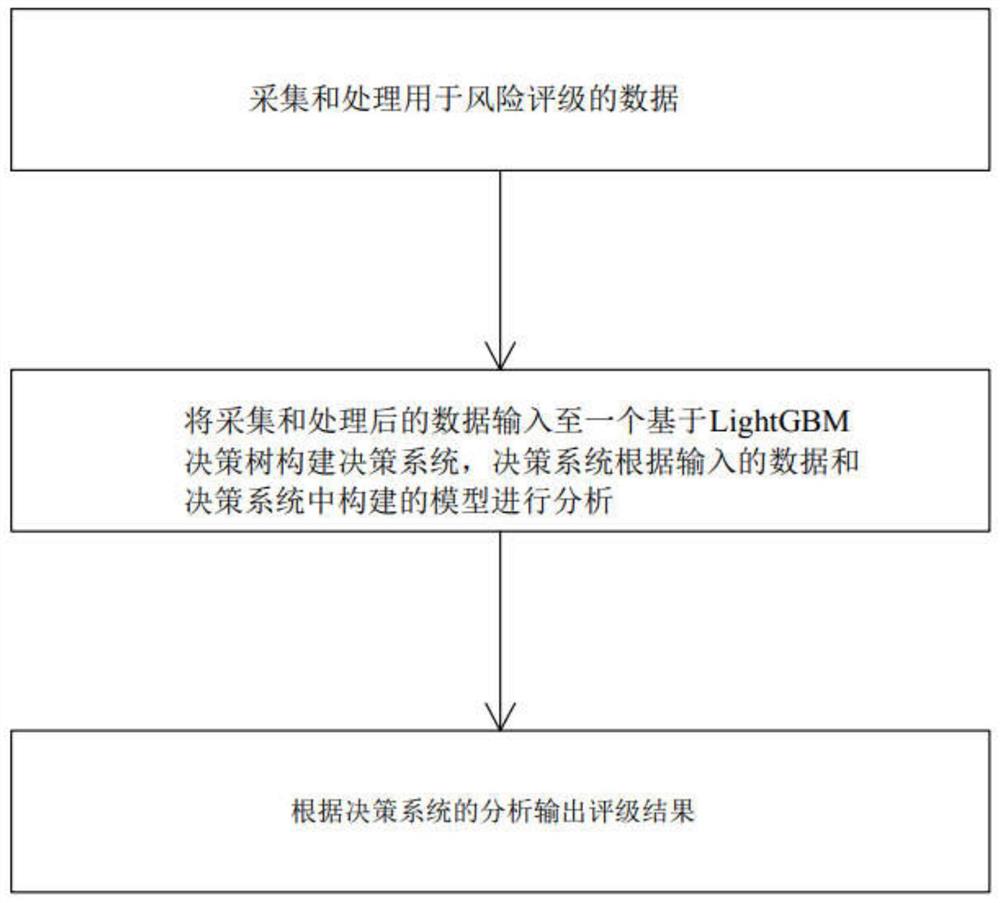
为了解决现有技术的不足之处,本申请提供一种于LightGBM决策树算法的个贷类不良资产风险评级方法包括如下步骤:采集和处理用于风险评级的数据;将采集和处理后的所述数据输入至一个基于LightGBM决策树构建决策系统,所述决策系统根据输入的所述数据和决策系统中构建的模型进行分析;根据所述决策系统的分析输出评级结果。
进一步地,所述基于LightGBM决策树算法的个贷类不良资产风险评级方法还包括如下步骤:构建基于LightGBM决策树构建决策系统的模型。
进一步地,所述构建基于LightGBM决策树构建决策系的模型统包括如下步骤:数据抽取:基于API对接的三方数据,如银联数据、人行征信数据、公积金/社保数据、运营商数据、电商交易数据,以及公开网站合规爬取的工商、法院、资讯等数据,以及不良资产用户数据,并进行数据匹配;数据打标:根据资产管理公司反馈的历史不良资产最终回款情况,进行样本打标,给定表现期三个月,三个月内回款则是好用户,否则为坏用户。
进一步地,样本增强:如果样本较少,那需要对样本进行上采样,即样本增强。可以在时间序列上通过滑动窗口,生成多个切片数据,不同切片数据相当于对原单个样本进行复制或增强。
进一步地,所述构建基于LightGBM决策树构建决策系的模型统包括如下步骤:缺失值填充:缺失比例高于80%,采用直接删除的方式;低于此比例,采用插值法进行缺失数据填充;数据集划分:数据集划分为训练集、测试集和验证集样本,样本比列为7: 2:1。
进一步地,所述构建基于LightGBM决策树构建决策系的模型统包括如下步骤:特征构建:基于用户收入、用户负债、用户信用、用户对外担保情况、用户消费、用户行踪中一个或多个梳理基础指标,并结合时间特性和常用统计量进行特征的构建;特征筛选:基于特征的重要性和相关性进行筛选。
进一步地,所述构建基于LightGBM决策树构建决策系的模型统包括如下步骤:模型构建:模型采用LightGBM-LR的架构搭建而成,其中LightGBM用来对衍生的特征映射到高维度;最终用高维向量空间的特征作为LR模型的输入来预测样本回款概率。
进一步地,所述构建基于LightGBM决策树构建决策系的模型统包括如下步骤:模型评估:将构建模型分别应用到测试集和验证集样本中,分别得出测试集样本的回款概率预测值以及验证集样本的回款概率预测值。
进一步地,所述模型评估还包括:计算测试样本集的AUC值和K-S值,如果AUC 值和K-S值本身满足预设条件且多个所述侧视样本集之间的AUC值和K-S值的差值在预设差值范围内,则认为模型有效。
进一步地,所述决策系统输出回款概率值,并根据回款概率值输出评估等级。
本申请的有益之处在于:提供一种从资产回款可能性角度评级而非资产本身价值进行评级的基于LightGBM决策树算法的个贷类不良资产风险评级方法。
附图说明
构成本申请的一部分的附图用来提供对本申请的进一步理解,使得本申请的其它特征、目的和优点变得更明显。本申请的示意性实施例附图及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1是根据本申请一种实施例的基于LightGBM决策树算法的个贷类不良资产风险评级方法的步骤示意图;
图2是根据本申请一种实施例的基于LightGBM决策树算法的个贷类不良资产风险评级方法中的LightGBM-LR模型原理图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
在本申请中,术语“上”、“下”、“左”、“右”、“前”、“后”、“顶”、“底”、“内”、“外”、“中”、“竖直”、“水平”、“横向”、“纵向”等指示的方位或位置关系为基于附图所示的方位或位置关系。这些术语主要是为了更好地描述本申请及其实施例,并非用于限定所指示的装置、元件或组成部分必须具有特定方位,或以特定方位进行构造和操作。
并且,上述部分术语除了可以用于表示方位或位置关系以外,还可能用于表示其他含义,例如术语“上”在某些情况下也可能用于表示某种依附关系或连接关系。对于本领域普通技术人员而言,可以根据具体情况理解这些术语在本申请中的具体含义。
此外,术语“安装”、“设置”、“设有”、“连接”、“相连”、“套接”应做广义理解。例如,可以是固定连接,可拆卸连接,或整体式构造;可以是机械连接,或电连接;可以是直接相连,或者是通过中间媒介间接相连,又或者是两个装置、元件或组成部分之间内部的连通。对于本领域普通技术人员而言,可以根据具体情况理解上述术语在本申请中的具体含义。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
参照图1和图2所示,本申请提供一种于LightGBM决策树算法的个贷类不良资产风险评级方法包括如下步骤:采集和处理用于风险评级的数据;将采集和处理后的数据输入至一个基于LightGBM决策树构建决策系统,决策系统根据输入的数据和决策系统中构建的模型进行分析;根据决策系统的分析输出评级结果。
作为具体方案,本发明方法包括以下步骤:
步骤一:数据抽取。基于API对接的三方数据,如银联数据、人行征信数据、公积金/社保数据、运营商数据、电商交易数据,以及公开网站合规爬取的工商、法院、资讯等数据,以及不良资产用户数据,并进行数据匹配。
步骤二:数据打标。根据资产管理公司反馈的历史不良资产最终回款情况,进行样本打标,给定表现期三个月,三个月内回款则是好用户,否则为坏用户。
步骤三:样本增强。如果样本较少,那需要对样本进行上采样,即样本增强。可以在时间序列上通过滑动窗口,生成多个切片数据,不同切片数据相当于对原单个样本进行复制或增强。
步骤四:缺失值填充。缺失比例高于80%,采用直接删除的方式;低于此比例,采用插值法进行缺失数据填充,常用的插值法包括平均值法、众数等。缺失值本身有重要含义,那么可以将单独作为一类,用一个离散值进行替代。
步骤五:数据集划分。数据集划分为训练集、测试集和验证集样本,样本比列为7:2: 1
步骤六:特征构建。基于业务专家经验,影响不良资产回款的主要维度有:用户收入、用户负债、用户信用、用户对外担保情况、用户消费、用户行踪等。根据这些维度,梳理基础指标,并结合时间特性,基于均值、方差、比值等统计量进行特征衍生。构造出当日前一月平均值、后一月平均值、前一月均值与后一月均值的比值、差值、趋势等统计量,共计 8000+维特征。
步骤七:特征筛选。特征筛选包括基于特征重要性筛选和基于特征相关性筛选。
1)基于特征重要性筛选。从数据角度而言,特征重要性越高,说明该特征所包含的有效信息越多,对于结果的预测也越重要。而为了模型的泛化能力,特征数量不宜过多。因此模型根据特征的重要性排序对其进行筛选。
利用LightGBM对这些特征的训练集数据进行初步训练,以获得所有特征的重要性。筛选出其中重要性大于0的特征,如图2所示。
2)基于特征相关性筛选。由于特征间相关性过高会影响模型的稳定性,因此对于相关性过高的特征需要进一步筛选。
计算特征相关系数矩阵,对于相关系数绝对值大于0.5且业务逻辑类似的特征,选择其中一个进行保留(图1中标注灰色的是根据相关性删除的特征)。
步骤八:模型构建。在完成特征筛选后,模型采用LightGBM-LR的架构搭建而成。其中 LightGBM用来对衍生的特征映射到高维度;最终用高维向量空间的特征作为LR模型的输入来预测样本回款概率。
模型构建过程如下:
1)构建10棵决策树,每棵树128个叶子节点的LightGBM模型,用以将特征映射到1280 维(128*10)的向量空间;
2)每条日志数据作为一个x输入,前期构造的43维特征,经过LightGBM模型转化为1280维向量空间,新生成的向量采用one-hot编码;
3)用这1280维向量空间作为LR模型的输入来预测样本嫌疑度,判断是否窃电。为防止过拟合,LR模型增加L2正则。
最终模型预测该不良资产的回款概率
步骤九:模型评估与优化。基于步骤八预测出的模型参数,分别应用到测试集和验证集样本中,分别得出测试集样本的回款概率预测值以及验证集样本的回款概率预测值。最终计算三个样本集的AUC值和K-S值,如果KS>=0.3和AUC>0.7,且三个样本集的AUC和KS相差不多,那说明模型稳定且有效,可以应用;否则需要优化,重新到步骤八进行调参。
步骤十:不良资产评级,基于模型预测的回款概率值,对于概率大于0.5的进行评级映射,如0.9-1.0为A级0.8-0.9为B级0.7-0.8为C级0.6-0.7为D级0.5-0.6为E级0.5 以下为F级。
本申请的不良资产风险评级方法是基于大数据,并采用LightGBM的算法,无需依赖人的主观经验,最终会输出不良资产的风险评级结果。另外,本申请的技术方案1.不良资产评级从资产回款可能性角度评级而非资产本身价值进行评级。不良资产评级方法采用大数据的方式,且算法采用的是LightGBM,该算法优点是高效快捷。模型生成了10棵决策树,128个叶子节点,1280维向量空间,信息得到了充分利用。最终的评级结果根据回款概率进行转化,划为ABCDEF等7个级别。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 基于LightGBM决策树算法的个贷类不良资产风险评级方法
- 基于校准曲线的钢铁中硫化锰类夹杂物的分析评级方法