一种千亿级别的对象存储桶的扩容方法
文献发布时间:2023-06-19 11:08:20
技术领域
本发明涉及云存储技术领域,尤其涉及一种千亿级别的对象存储桶的扩容方法。
背景技术
由于大数据、AI技术的高速发展,对底层的存储系统也提出了更高的需求:更大的容量,更快的响应速度,更大的带宽,现有的对象存储单集群单桶数据规模超过5-10亿之后性能急剧下降,元数据存储急剧膨胀,此时单桶内的扩容带来很大挑战。
现有的对象存储单桶扩容大多数仅仅支持单个集群下的扩容,以对象存储领域两大开源存储系统(SWIFT和CEPH)为例,简单介绍一下当前对象存储单桶的扩容方法。
Swift开源对象存储桶存储引擎为sqlite数据库,一旦其索引达到5亿左右,其性能就会下降很严重,此时很难在单集群或者单桶内进行扩容。Ceph开源对象存储桶内桶索引达到亿级别规模后,可以通过元数据索引重组策略来,但是会引起大量的元数据均衡,而且一旦单桶达到几十亿后,元数据扩容重组期间会对系统的性能影响有很大挑战。
现有技术往往仅考虑单集群单桶内的元数据存储规模,其规模十分有限,如何做到对象存储单桶的规模达到千亿量级,而且保证扩容期间对业务无感知是目前亟需解决的问题。
发明内容
本发明的目的是提供一种千亿级别的对象存储桶的扩容方法,可以实现对象存储单集群单桶在海量数据下的弹性扩容,扩容期间业务无感知,底层存储无任何数据均衡操作,保证服务可用性。
本发明的目的是通过以下技术方案实现的:
一种千亿级别的对象存储桶的扩容方法,包括:构建包含虚拟映射层、元数据中心、入口组件、以及运维组件的统一管理平台;其中:
虚拟映射层:负责对象存储桶和底层多个异构的对象存储集群的映射关系;其中,用户具有一个或多个对象存储桶,每一对象存储桶中存储有一个或多个存储对象;
入口组件:负责拦截用户请求,确定用户请求所对应的对象,根据元数据中心、虚拟映射和底层的对象存储集群的实际信息,负责请求路由的转发;
元数据中心:负责记录对象在底层的对象存储集群的位置信息和持久化配置信息;
运维组件:负责平台初始化相关配置信息、以及入口组件、虚拟映射层与元数据中心的变更操作;
通过统一管理平台统一管理多个异构对象存储集群的控制面和数据面,实现扩容期间的平滑切换。
由上述本发明提供的技术方案可以看出,1)对于对象存储单桶扩容方法来说,无数据均衡,没有单集群单桶的规模风险,天生可以水平扩容;扩容期间业务无感知,热切换配置直接生效。2)对于对象存储单桶扩容方法来说,没有单集群单桶的性能瓶颈,通过接入多个异构对象存储集群和虚拟映射方法,保证对象存储服务的性能可靠性。3)对于底层对象存储集群的集群类型的要求低,可以以异构多集群方式实现底层数据存储,扩容集群只要是支持swift接口或者S3接口的对象存储集群都可以作为底层集群,加入到集群中。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
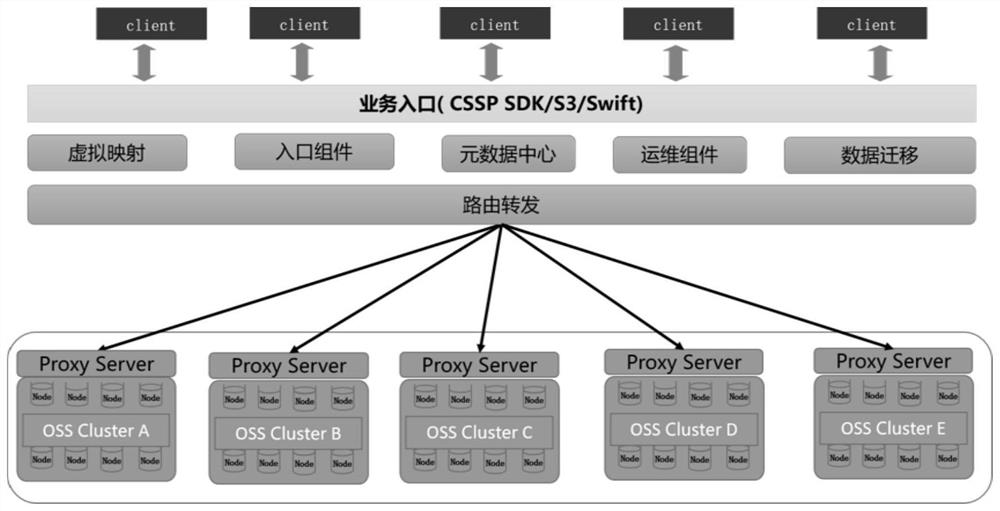
图1为本发明实施例提供的一种千亿级别的对象存储桶的扩容方法的基本架构图;
图2为本发明实施例提供的虚拟映射的逻辑图;
图3为本发明实施例提供的入口组件的结构及处理逻辑图;
图4为本发明实施例提供的元数据中心引擎与CEPH的关系图;
图5为本发明实施例提供的元数据中心的基本架构图;
图6为本发明实施例提供的元数据中心二维HASH算法的原理图;
图7为本发明实施例提供的元数据中心多版本的基本结构图。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
现有扩容方案,从业务使用视角,可以通过时间戳或者桶索引上来新建存储桶,来解决单桶的存储瓶颈,从而解决单桶存储规模的问题。还有绝大多数业务场景,业务自己维护一套全局索引DB,达到一定规模后,还需要对这个全局索引DB进行分表分库。从存储单桶底层来看,一般是通过桶内的元数据组重组来扩容,从而解决单桶内的元数据存储规模扩容问题。
但是,无论是存储单桶底层或者业务层的做法,在单桶元数据规模上应付几十亿问题不大,但是在面临是千亿量级的元数据桶,还需要解决如下关键问题:
1)如何保证元数据扩容期间,底层存储服务稳定性。
2)如何解决元数据单桶的千亿规模性问题。
3)在单个存储集群单个桶达到几亿上限后,如何平滑进行存储集群数据面的扩容。
本发明实施例提供一种千亿级别的对象存储桶的扩容方法,该方法是解决现有扩容方案在海量数据下无法弹性扩容和扩容难的痛点问题。
如图1所示,为一种千亿级别的对象存储桶的扩容方法的基本架构图,该方法中首先构建了包含虚拟映射层、元数据中心、入口组件、以及运维组件的统一管理平台;通过统一管理平台统一管理多个异构对象存储集群的控制面和数据面,实现扩容期间的平滑切换。其中:1)统一管理多个异构对象存储集群的数据面包括:通过元数据中心与虚拟映射层获取当前用户某一对象的对应对象存储集群入口,如果没有记录,则启用入口组件查询对象的对应对象存储集群入口,当查询到相关记录信息后更新到元数据中心,同时将记录信息转发到底层相应的对象存储集群。2)统一管理多个异构对象存储集群的控制面包括:当某一个默认写入对象存储集群的水位高度超过设定值时,平滑切换到新的对象存储集群中,扩容期间业务无感知,底层存储无任何数据均衡操作,保证服务可用性。
统一管理平台各个部分的介绍如下:
虚拟映射层:负责对象存储桶(用户桶)和底层多个异构的对象存储集群的映射关系;
入口组件:负责拦截用户请求,确定用户请求所对应的对象,根据元数据中心、虚拟映射和底层的对象存储集群的实际信息,负责请求路由的转发;
元数据中心:负责记录对象在底层的对象存储集群的位置信息和持久化配置信息;
运维组件:负责平台初始化相关配置信息、以及入口组件、虚拟映射层与元数据中心的变更操作。
此外,统一管理平台还设有数据迁移组件,主要负责扩容变更失败后,多个对象存储集群的回滚迁移操作。
本领域技术人员可以理解,一个用户可以有一个或多个对象存储桶,每一对象存储桶中存储有一个或多个存储对象,存储对象在本发明中简称为对象,它是本领域专用术语,表示在一个层结构中不会再有层级结构,是以扩展元数据为特征的。
为了便于理解,下面针对统一管理平台各个部分做详细的介绍。
一、虚拟映射层。
如图2所示,为虚拟映射的逻辑图。对象存储桶与底层异构的对象存储集群呈现一对多关系,相关的映射关系由虚拟映射层保存与维护;当某一个默认写入的对象存储集群(初始时刻,可以自行设定)的水位高度超过设定值时,热生效变更默认写入的对象存储集群,当前对象存储桶的写入流量转发至变更后的默认写入的对象存储集群(此处的操作即为前文所述的统一管理多个异构对象存储集群的控制面)。
虚拟映射层配合元数据中心能支撑起千亿规模,轻松实现单桶能支撑EB级别的存储需求,而且存储桶扩容热生效,无需进行数据均衡,单个对象存储集群的稳定性和规模控制在一定范围内,历史较久的数据还可以做归档处理。
二、入口组件。
如图3所示,为入口组件的结构及处理逻辑图。业务方接入协议可以采用对象存储领域通用的S3或者Swift。入口组件的工作过程主要包括:
1)拦截用户请求后,确定用户请求所对应的对象,并通过服务层鉴权用户请求中携带的用户密钥是否合法。
2)如果合法则进入路由层处理,路由层中首先确定用户请求的类型(PUT/GET/DELETE/HEAD)以及相关文件是否分片。
本领域技术人员可以理解,此处涉及的是HTTP请求方法,PUT为写入或者更新操作,GET、HEAD、DELETE分别为查询操作、读操作、删除操作。用户一次请求对应底层一个操作对象;用户可以创建多个对象存储桶;在对象存储桶内部可以创建多个对象(即object)。
3)对于非分片文件的PUT请求,通过元数据中心获取最新的记录信息。具体来说:为了加快查询速度,直接按照默认写入对象存储集群来记录,期间容易出现多个对象存储集群都存在此对象(object),元数据中心查询始终返回记录最新的,如果元数据中心没有,则通过读取对象的头部信息(object HEAD)的时间戳来区分,返回时间戳最新的记录给入口组件。
4)对于非分片文件的GET请求、HEAD请求或者DELETE请求,发送RPC请求服务(RPC是一种网络通讯协议,内部组件使用)给元数据中心,查看元数据中心是否有该object(即发送请求的对象的)记录信息,如果命中,直接转入相应底层的对象存储集群,如果不命中,通过兜底Object HEAD(读取对象的头部信息)请求查询每一个底层的对象存储集群,并把查询到的数据写回元数据中心,然后转发到相应底层的对象存储集群。
5)对于分片文件,由于分片文件是由多个文件组织在一起,因此尽量保证写入时在同一个对象存储集群,因此,需要先查文件第一块分片的位置信息,通过元数据中心和Object HEAD(对象的读操作)检查双重保证(也即,先到元数据中心查询,如果有直接返回;并继续通过对象的读操作查询),其他操作与普通文件(非分片文件)处理类似。
同时,工作过程中所有操作日志都写入日志收索引擎,并由APM系统监控入口组件的工作状态,保证入口组件服务的可靠性。
三、元数据中心。
元数据中心是统一管理平台核心引擎,基于CEPH Rados分布式存储网关自研一套针对千亿量级的对象存储桶索引。除去元数据中心引擎与CEPH的关系如图4所示,CEPH底层采用Bluestore分布式存储引擎,元数据引擎访问采用librados接口进行key-value的读写。元数据中心对外采用RPC接口(RPC服务实现),内部实现二维HASH算法和多版本弹性扩容功能(OSS Index Metadata实现)。
如图5所示,为元数据中心的基本架构。元数据中心的底层接入多个存储资源池,包含桶虚拟映射资源池(RAODS MD Cluster)和对象索引资源池(md_index_pool);其中对象索引资源池能够进行跨集群资源池扩容,用来满足元数据规模化平滑扩容处理,同时在单个对象存储集群内能够通过多组资源池(多个磁盘组成的分布式块存储资源)进行初始化。
如图6所示,为元数据中心二维HASH算法的原理图。二维HASH算法包括:分别计算对象的行哈希和列哈希(具体是根据对象的名字计算行哈希和列哈希),得到行模值和列模值;根据行模值和列模值命中二维HASH矩阵中的位置信息;命中到同一个位置内采用B+tree插入排序方法,key为对象名字,val为对应对象存储集群的信息。每个坐标内部的key值数目控制在6万-10万以内,保证整个排序查询和插入的效率。
如图7所示,为元数据中心多版本的基本结构图。对于写入数据请求,默认写入最新版本,所述版本是指对象元数据的头部信息;对于查询请求,从高版本到低版本逐步查询;在多版本扩容中,还增加了HASH模值的调整,一方面应付单个版本桶的规模化调整,一方面避免版本过多导致查询性能下降。
本领域技术人员可以理解,HASH模值的调整为HASH取模参数的调整,可通过常规技术实现。
四、运维组件与数据迁移组件。
运维组件重点负责入口组件、虚拟映射层、以及元数据中心的变更操作;数据迁移组件用来支撑多个对象存储集群之间的平滑数据迁移。
本发明实施例上述方案,主要获得如下有益效果:
1)对于对象存储单桶扩容方法来说,无数据均衡,没有单集群单桶的规模风险,天生可以水平扩容;扩容期间业务无感知,热切换配置直接生效。
2)对于对象存储单桶扩容方法来说,没有单集群单桶的性能瓶颈,通过接入多个异构对象存储集群和虚拟映射方法,保证对象存储服务的性能可靠性。
3)对于底层对象存储集群的集群类型的要求低,可以以异构多对象存储集群方式实现底层数据存储,扩容对象存储集群只要是支持swift接口或者S3接口的对象存储集群都可以作为底层对象存储集群,加入到集群中。
4)元数据中心充分利用应用场景的特性,设计时重点考虑元数据中心的规模化和后期扩容难的问题,通过多版本+多个存储资源池来实现单桶千亿的元数据存储规模。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例可以通过软件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,上述实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将系统的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 一种千亿级别的对象存储桶的扩容方法
- 分布式对象存储集群及其扩容方法、装置及电子设备