基于深度因子分解机的营销活动预测模型结构和预测方法
文献发布时间:2023-06-19 11:11:32
技术领域
本发明涉及人工智能在互联网营销的技术领域,更具体地,涉及一种基于深度因子分解机的营销活动预测模型结构和预测方法。
背景技术
因子分解机(Factorization Machines,简称FM)是一种具有二阶特征交互作用的线性模型,因其具有一定的特征交互模型且模型的计算及结构较为简单,常被用于互联网运营商大数据精准获客系统和计算广告系统做点击预估或者召回后的排序。虽然FM模型通常具有比逻辑回归更好的特征交互能力,但是由于性能的限制,FM只能够进行二阶特征交互而不具备高阶特征交互能力,因此,会丢失特征的高阶信息。
前馈神经网络(Feedforward Neural Network,简称FNN)是具有简单的计算结构和强大的特征交互能力,因此作为深度学习的一部分被广泛用于各种领域。然而,在计算广告领域,由于FNN模型的特征交互通常过于复杂,往往会丢失特征原本的低阶交互信息。
为了结合FM和FNN各自的优点,深度因子分解机(Deep Factorization Machines,简称DeepFM)被创造出来用于同时学习输入特征的高阶和低阶交互信息。原始的DeepFM是通过共享FM和FNN的嵌入层(Embedding layer)且输出结果为FM和FNN的结果之和,以此来实现对低阶和高阶特征交互的同时学习。然而,上述的做法存在如下两个问题:
①、FM的低阶特征交互,特征和特征之前可能本身根本没有关系,但是学习的时候是一起进行学习,可能会造成错误的学习结果。
②、DeepFM最终的输出结果是FM和FNN输出结果的直接加和,这相当于默认FM和FNN对最终结果各有0.5的权重,此在实际操作中不一定合理。
发明内容
本发明的目的在于克服现有技术存在的上述缺陷,提供一种基于深度因子分解机的营销活动预测模型结构和预测方法,其通过对DeepFM进行改造,利用DeepFM的思路对运营商处的数据进行合理的分区,并重新设计FM的交互,并且在结果输出前加入了一个集成网络层(Ensemble network)用来学习多个输出对于最终结果的权重。并且,该最终结果的权重是一个浅层神经网络,其参数是在学习过程中根据损失函数自动进行更新的。
为实现上述目的,本发明的技术方案如下:
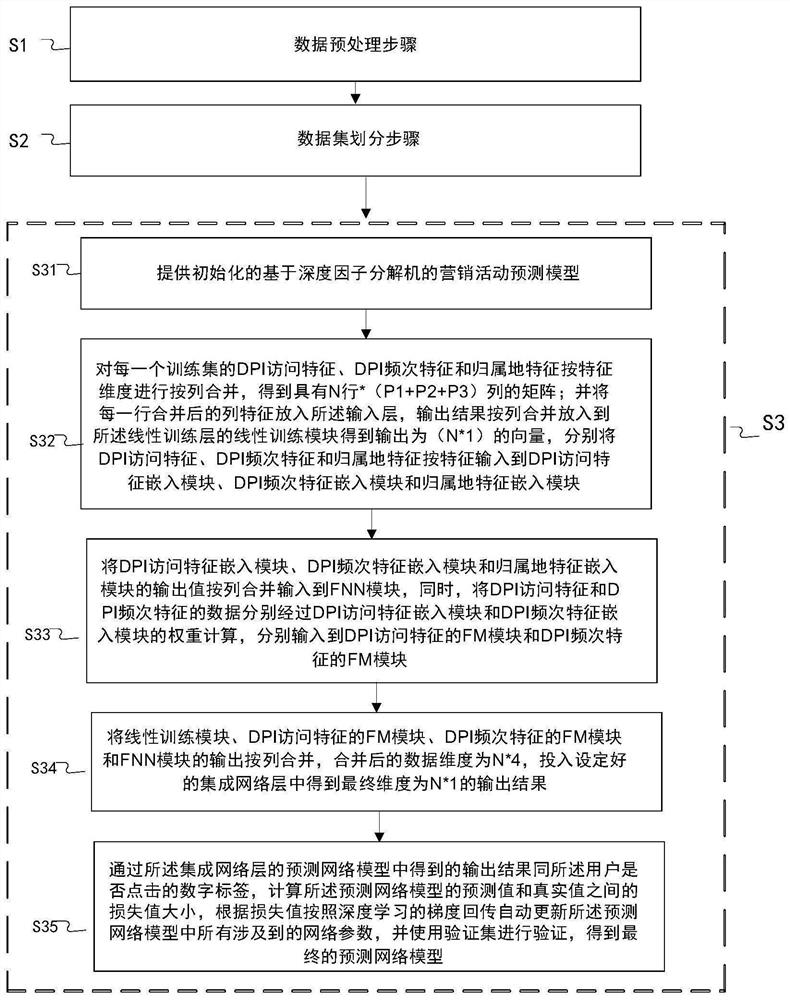
一种基于深度因子分解机的营销活动预测方法,其包括数据预处理步骤S1、训练集和验证集形成步骤S2和模型建立步骤S3;
所述数据预处理步骤S1包括如下步骤:
步骤S11:获取N个用户的原始信息,并从每一个所述用户的原始信息提取原始特征信息;其中,所述原始特征信息包括用户ID、用户手机号码归属地、任务批次号、用户访问DPI、用户访问DPI频次和用户是否点击的数字标签;其中,所述任务批次号表示一个日期时间段中用户的原始信息,所述用户访问DPI和用户访问DPI频次为每一个任务批次号为计量单位;
步骤S12:依次处理具有所述任务批次号的所有批次中的所述原始特征信息,对所述用户手机号码归属地特征进行One-hot编码处理;其中,所述One-hot编码处理包括:
依次按所述任务批次号将所有不同的用户访问DPI作为单独的特征展开,以及在所述任务批次号中将DPI访问频次也按照所有不同的用户访问DPI展开为DPI与用户访问DPI的频次的关系特征;其中,特征展开后的所述用户访问DPI的维度为P1;所述用户dpi访问频次特征为连续特征,所述用户dpi访问频次特征的维度为P2,用户手机号码归属地特征的维度为P3;
步骤S13:将所有所述任务批次号按照升序进行排序,得到所有所述任务批次号的排序;其中,所述任务批次号的升序是同日期时间的远近成正比,所述日期时间越近,所述任务批次号越大;
所述训练集和验证集形成步骤S2包括:
预处理之后,选择所述任务批次号最大的任务批次中的数据作为验证集,剩余的所述任务批次号的数据作为训练集;
所述模型建立步骤S3用于形成基于深度因子分解机的营销活动预测模型,其使用所述训练集对所述预测模型进行训练,并使用验证集进行验证,得到最终的预测模型,其包括如下步骤:
步骤S31:提供初始化的基于深度因子分解机的营销活动预测模型,其中,所述营销活动预测模型包括输入层、嵌入层、线性训练层和集成网络层;所述嵌入层包括DPI访问特征嵌入模块、DPI频次特征嵌入模块和归属地特征嵌入模块;所述线性训练层包括线性训练模块、DPI访问特征的FM模块、DPI频次特征的FM模块;所述非线性层包括FNN模块;其中,线性训练层和非线性层为并列的层,其输入均来自嵌入层,输出均发送至集成网络层;
步骤S32:对每一个训练集的DPI访问特征、DPI频次特征和归属地特征按特征维度进行按列合并,得到具有N行*(P1+P2+P3)列的矩阵;并将每一行合并后的列特征放入所述输入层,输出结果按列合并放入到所述线性训练层的线性训练模块得到输出为(N*1)的向量,分别将DPI访问特征、DPI频次特征和归属地特征按特征输入到DPI访问特征嵌入模块、DPI频次特征嵌入模块和归属地特征嵌入模块;
步骤S33:将DPI访问特征嵌入模块、DPI频次特征嵌入模块和归属地特征嵌入模块的输出值按列合并输入到FNN模块,同时,将DPI访问特征和DPI频次特征的数据分别经过DPI访问特征嵌入模块和DPI频次特征嵌入模块的权重计算,分别输入到DPI访问特征的FM模块和DPI频次特征的FM模块;
步骤S34:将线性训练模块、DPI访问特征的FM模块、DPI频次特征的FM模块和FNN模块的输出按列合并,合并后的数据维度为N*4,投入设定好的集成网络层中得到最终维度为N*1的输出结果;
步骤S35:通过所述集成网络层的预测网络模型中得到的输出结果同所述用户是否点击的数字标签,计算所述预测网络模型的预测值和真实值之间的损失值大小,根据损失值按照深度学习的梯度回传自动更新所述预测网络模型中所有涉及到的网络参数,并使用验证集进行验证,得到最终的预测网络模型。
进一步地,所述基于深度因子分解机的营销活动预测方法,其还包括营销活动预测步骤S4,所述步骤S4具体包括:
步骤S41:获取拟互联网产品营销的用户群体和所述用户群体的用户原始信息,并从所述用户原始信息提取原始特征信息;所述任务批次号表示一个日期时间段中用户的原始信息,所述用户访问DPI和用户访问DPI频次为每一个任务批次号为计量单位;
步骤S42:对所述任务批次号的所述原始特征信息,按所述用户手机号码归属地特征进行One-hot编码处理;其中,所述One-hot编码处理包括:
按所述任务批次号将所有不同的用户访问DPI作为单独的特征展开,以及在所述任务批次号中将DPI访问频次也按照所有不同的用户访问DPI展开为DPI与用户访问DPI的频次的关系特征;其中,特征展开后的所述用户访问DPI的维度为P1;所述用户dpi访问频次特征为连续特征,所述用户dpi访问频次特征的维度为P2,用户手机号码归属地特征的维度为P3;
步骤S43:提供建立好的所述预测模型,基于因子分解机,设定所述预测模型的二阶特征交互的隐向量维度,初始化所有所述原始特征信息一阶特征权重和二阶特征的隐向量,使用所述原始特征信息进行预测,得到每一个用户的预测值,从而形成N个所述用户的模型预测值集;其中,所述因子分解机在处理二分类问题时,将使用sigmoid函数将预测值的范围限定在0和1之间,即所述用户的模型预测值为所述用户的点击意愿度。
进一步地,所述模型预测步骤S4还包括:
步骤S44:根据实际投放需求,选择全部或部分所述用户的模型预测值集中点击意愿度为1的用户进行精准营销的任务。
进一步地,所述线性训练模块的输出为(N*1)的向量,即:
output=Xw+b
其中,w为线性权重系数,(P1+P2+P3)*1的向量,b为偏置,为(N*1)的向量。
进一步地,所述DPI访问特征的FM模块和DPI频次特征的FM模块的输出为:
示i
从上述技术方案可以看出,本发明能够提前在广告投放之前就筛选出意愿较高的部分用户,并对这些用户进行营销广告的精准投放。结果表明,本算法选出的高意愿用户的点击率是低意愿用户点击率的数倍。进一步地,本发明可以将大量的低意愿用户直接从投放目标中筛出,从而节省大量的营销成本,实现利润率的增加。
附图说明
图1所示为本发明实施例中基于深度因子分解机的营销活动预测方法的流程示意图
图2所示为本发明实施例中基于深度因子分解机的营销活动预测模型的示意图
具体实施方式
下面结合附图,对本发明的具体实施方式作进一步的详细说明。
在下述的具体实施方式中,在详述本发明的实施方式时,为了清楚地表示本发明的结构以便于说明,特对附图中的结构不依照一般比例绘图,并进行了局部放大、变形及简化处理,因此,应避免以此作为对本发明的限定来加以理解。
需要说明的是,在以下本发明的具体实施方式中,该基于深度因子分解机的营销活动预测方法可以包括数据预处理步骤S1、训练集和验证集形成步骤S2和模型建立步骤S3;与传统的利用运营商数据的数据营销领域所采用的技术相比,本发明基于加入了集成网络层的深度因子分解机的营销广告点击预测模型,并通过深度因子分解机结合运营商数据进行更为精准的数据营销,其能提供用户对广告点击意愿进行直接预测的途径。
请参阅图1,图1所示为本发明实施例中基于深度因子分解机的营销活动预测方法的流程示意图。如图1所示,基于深度因子分解机的营销活动预测方法,其包括数据预处理步骤S1、训练集和验证集形成步骤S2和模型建立步骤S3。
在本发明的实施例中,数据预处理步骤非常重要,所述数据预处理步骤S1包括如下步骤:
步骤S11:获取N个用户的原始信息,并从所述用户的原始信息提取原始特征信息;其中,所述原始特征信息包括用户ID(id)、用户手机号码归属地(location)、任务批次号(batch number)、用户访问DPI(dpi)和用户访问DPI频次(dpi frequency);其中,所述任务批次号表示一个日期时间段中用户的原始信息,所述用户访问DPI和用户访问DPI频次为每一个任务批次号为计量单位。
步骤S12:依次处理具有所述任务批次号的所有批次中的所述原始特征信息,对所述用户手机号码归属地特征进行One-hot编码处理(One-hot编码是一种数据预处理常用方法,将类别特征按照不同取值进行0/1映射为新的特征);其中,所述One-hot编码处理包括:
依次按所述任务批次号将所有不同的用户访问DPI作为单独的特征展开,以及在所述任务批次号中将DPI访问频次也按照所有不同的用户访问DPI展开为DPI与用户访问DPI的频次的关系特征。
具体地,可以认为,一个任务批次号(batch number)对应一天的用户数据,用户的原始信息中同一个任务批次号(batch number)中的用户可能会有重复,因为,同一个用户可能会访问多个用户访问DPI,需要将所有不同的用户访问DPI展开作为单独的特征,因此,特征展开后的所述用户访问DPI的维度为P1;如果一个用户访问过该用户访问DPI,则在该特征下,当前用户的值为1,否则为0。
同理,将用户访问DPI访问频次也按照所有不同的用户访问DPI展开为用户访问DPI与用户访问DPI频次的关系特征,因此,所述用户DPI访问频次特征为连续特征,特征展开后的所述用户DPI访问频次特征的维度为P2;若用户访问某用户访问DPI共m次则该特征下当前用户的值为m,否则为0。
此外,用户手机号码归属地特征的维度为P3,例如P3=30。
请参阅下表1,表1为预处理过程(预处理之前的原始数据和预处理之后的数据)的表格描述,以同一批次的数据为例,可简略的表示如下:
预处理之前的原始数据:
预处理之后的数据:
步骤S13:将所有所述任务批次号按照升序进行排序,得到所有所述任务批次号的排序;其中,所述任务批次号的升序是同日期时间的远近成正比,所述日期时间越近,所述任务批次号越大。
经过上述处理后,每一个任务批次内的用户ID将是唯一值,即有N个用户;然后,将所有批次的N个用户数据都做上述处理,并按照批次进行用户方向合并,按照任务批次号(batch number)升序进行排序,任务批次的日期越新则任务批次号(batch number)越大,可以得到处理好的样本。
经过上述数据预处理步骤完成后,就可以选择最后一个批次的数据作为验证样本集来进行模型参数的选择,除此之外的所有样本组成训练样本集用来建立模型,即训练样本集为用来进行模型训练的样本集合;验证样本集为用来进行模型参数选择的样本集合。
也就是说,对处理好的数据,可以选择最后一个批次的数据作为验证样本集来进行模型参数的选择,除此之外的所有样本组成训练样本集用来建立模型。请继续参阅图1,在本发明的实施例中,所述模型建立步骤S3用于形成基于深度因子分解机的营销活动预测模型,其使用所述训练集对所述预测模型进行训练,并使用验证集进行验证,得到最终的预测模型,其包括如下步骤:
步骤S31:提供初始化的基于深度因子分解机的营销活动预测模型,其中,所述营销活动预测模型包括输入层、嵌入层、线性训练层、非线性层和集成网络层;其中,线性训练层和非线性层为并列的层,其输入均来自嵌入层,输出均发送至集成网络层。所述嵌入层包括DPI访问特征嵌入模块、DPI频次特征嵌入模块和归属地特征嵌入模块;所述线性训练层包括线性训练模块、DPI访问特征的FM模块、DPI频次特征的FM模块;所述非线性层包括FNN模块。
请参阅图2,图2所示为本发明实施例中基于深度因子分解机的营销活动预测模型的示意图。如图2所示,所述营销活动预测模型包括输入层、嵌入层、线性训练层和集成网络层(Ensemble network)。本发明通过对DeepFM进行改造,利用DeepFM的思路对运营商处的数据进行合理的分区,并重新设计FM的交互;同时,在结果输出前加入了集成网络层来学习多个输出对于最终结果的权重。
在本发明的实施例中,输入层有三个输入端口,分别用于接收用户手机号码归属地(location)、用户访问DPI和用户访问DPI频次(dpi frequency)的特征数据。所述嵌入层包括DPI访问特征嵌入模块(DPI embedding layer)、DPI频次特征嵌入模块(DPI Freqembedding layer)和归属地特征嵌入模块(Location embedding layer);所述线性训练层包括线性训练模块、DPI访问特征的FM模块、DPI频次特征的FM模块;所述非线性层包括FNN模块;其中,线性训练层和非线性层为并列的层,其输入均来自嵌入层,输出均发送至集成网络层。
在DPI访问特征嵌入模块(DPI embedding layer)、DPI频次特征嵌入模块(DPIFreq embedding layer)和归属地特征嵌入模块(Location embedding layer)中,由于DPI访问特征的FM模块和DPI频次特征的FM模块只使用了权重weight,因此,上述各模型的嵌入层仅设定权重weight而不设定偏置bias。
具体地,如果在DPI访问特征嵌入模块、DPI频次特征嵌入模块和归属地特征嵌入模块中包含的线性全连接层(只有权重weight,没有偏置bias),其一般情况下对输入数据X作Xw+b的操作,w是权重weight,b是偏置bias。其中,采用批归一化对其前面的全连接层的权重weight作归一化操作,以调整weight的分布使其更加均匀,有利于模型的收敛和预测结果的提升;并且,全连接层后需要加一个深度学习常用激活函数(非线性激活函数)使神经网络具有非线性学习能力。
FNN模块(FNN part)可以包括3个隐藏层和1个输出层,对于隐藏层1中的线性全连接层(权重weight和偏置bias都有),FNN part的隐藏层1里的全连接层为正常的全连接层,因此,权重weight和偏置bias都有批归一化层和随机丢弃层,随机丢弃层是深度学习常用组件,作用是将其前面的全连接层的权重weight和偏置bias按照一定概率随机置0,是一种防止模型过拟合的方法,一般放在全连接层的后面,并且,全连接层后需要加一个深度学习常用激活函数(非线性激活函数ReLU)使神经网络具有非线性学习能力。同样,对于隐藏层2和隐藏层3,全连接层为正常的全连接层,因此,权重weight和偏置bias都有批归一化层和随机丢弃层,随机丢弃层是深度学习常用组件,作用是将其前面的全连接层的权重weight和偏置bias按照一定概率随机置0,是一种防止模型过拟合的方法,一般放在全连接层的后面,并且,全连接层后需要加一个深度学习常用激活函数(非线性激活函数ReLU)使神经网络具有非线性学习能力。较佳地,输出层包含随机丢弃层。
例如,FNN part可以设置为如下参数:
①、隐藏层1
神经元个数:1024
随即丢弃概率:0.1
输入数据维度N*(256+512+30),输出数据维度(N*1024)
②、隐藏层2
神经元个数:512
随即丢弃概率:0.2
输入数据维度(N*1024),输出数据维度(N*512)
③、隐藏层3
神经元个数:256
随即丢弃概率:0.1
输入数据维度(N*512),输出数据维度(N*256)
④、输出层
随即丢弃概率:0.05,输入数据维度(N*256),输出数据维度(N*1)
在本发明的实施例中,集成网络层(Ensemble network)包括1个隐藏层和1个输出层。隐藏层为线性全连接层(weight和bias都有),采用批归一化层和随机丢弃层,以及全连接层后加一个深度学习常用激活函数(非线性激活函数ReLU)使神经网络具有非线性学习能力。输出层采用Sigmoid非线性激活函数,集成网络层的输出就是模型的最终输出,因为用户是否点击是一个0-1之间的概率,所以使用Sigmoid激活函数可以将模型的输出结果限制在0-1之间。
例如,对于Ensemble network可以设置为如下参数:
隐藏层:
神经元个数:64
随即丢弃概率:0.1
输入数据维度(n*4),输出数据维度(n*64)
此外,上述模型训练超参数可以设置如下:
数据批量大小Batch size:256
训练总轮次Epochs:100
学习率:0.001
权重衰减:1e
L-1正则化系数:1e
早停机制轮次Early stopping:6
根据上述图2所示基于深度因子分解机的营销活动预测模型结构,可以使用所述训练集对所述预测模型进行训练,并使用验证集进行验证,得到最终的预测模型。
步骤S32:对每一个训练集的DPI访问特征、DPI频次特征和归属地特征按特征维度进行按列合并,得到具有N行*(P1+P2+P3)列的矩阵;并将每一行合并后的列特征放入所述输入层,输出结果按列合并放入到所述线性训练层的线性训练模块得到输出为(N*1)的向量,分别将DPI访问特征、DPI频次特征和归属地特征按特征输入到DPI访问特征嵌入模块、DPI频次特征嵌入模块和归属地特征嵌入模块。
在本发明的实施例中,所述线性训练模块的输出为(N*1)的向量,即:
output=Xw+b
其中,w为线性权重系数,(P1+P2+P3)*1的向量,b为偏置,为(N*1)的向量。
步骤S33:将DPI访问特征嵌入模块、DPI频次特征嵌入模块和归属地特征嵌入模块的输出值按列合并输入到FNN模块,同时,将DPI访问特征和DPI频次特征的数据分别经过DPI访问特征嵌入模块和DPI频次特征嵌入模块的权重计算,分别输入到DPI访问特征的FM模块和DPI频次特征的FM模块。
在本发明的实施例中,DPI访问特征嵌入模块的神经元个数可以选256,其输入数据维度为N*P1,输出数据维度为N*256;DPI频次特征嵌入模块的神经元个数可以选512,其输入数据维度为N*P2,输出数据维度为N*512;归属地特征嵌入模块的神经元个数可以是128,其输入数据维度为N*P3,输出数据维度为N*128。
具体地,所述DPI访问特征的FM模块和DPI频次特征的FM模块的输出可以为:
示i
步骤S34:将线性训练模块、DPI访问特征的FM模块、DPI频次特征的FM模块和FNN模块的输出按列合并,合并后的数据维度为N*4,投入设定好的集成网络层中得到最终维度为N*1的输出结果。
也就是说,将合并后的数据维度为N*4投入设定好的集成网络层中得到最终的输出结果,集成网络层中的输出是线性训练模块、DPI访问特征的FM模块、DPI频次特征的FM模块和FNN模块输出结果的集成,表示三个模块对用户是否点击的预测的非线性加权结果,维度为N*1。
集成网络层的输出结果和用户数据的真实点击标签都是N*1的列向量,二者根据交叉熵损失函数(用户是否点击为二分类问题,故使用交叉熵损失函数计算模型预测和真实值之间的损失值)可以计算模型预测值和真实值之间的损失值大小,根据损失值按照深度学习的梯度回传自动更新模型中所有涉及到的网络参数,以此训练模型即可。
步骤S35:通过所述集成网络层的预测网络模型中得到的输出结果同所述用户是否点击的数字标签,计算所述预测网络模型的预测值和真实值之间的损失值大小,根据损失值按照深度学习的梯度回传自动更新所述预测网络模型中所有涉及到的网络参数,并使用验证集进行验证,得到最终的预测网络模型。
完成上述模型训练后,就可采用所述基于深度因子分解机的营销活动预测方法,进行营销活动预测步骤S4,所述步骤S4具体包括:
步骤S41:获取拟互联网产品营销的用户群体和所述用户群体的用户原始信息,并从所述用户原始信息提取原始特征信息;所述任务批次号表示一个日期时间段中用户的原始信息,所述用户访问DPI和用户访问DPI频次为每一个任务批次号为计量单位;
步骤S42:对所述任务批次号的所述原始特征信息,按所述用户手机号码归属地特征进行One-hot编码处理;其中,所述One-hot编码处理包括:
按所述任务批次号将所有不同的用户访问DPI作为单独的特征展开,以及在所述任务批次号中将DPI访问频次也按照所有不同的用户访问DPI展开为DPI与用户访问DPI的频次的关系特征;其中,特征展开后的所述用户访问DPI的维度为P1;所述用户dpi访问频次特征为连续特征,所述用户dpi访问频次特征的维度为P2,用户手机号码归属地特征的维度为P3;
步骤S43:提供建立好的所述预测模型,基于因子分解机,设定所述预测模型的二阶特征交互的隐向量维度,初始化所有所述原始特征信息一阶特征权重和二阶特征的隐向量,使用所述原始特征信息进行预测,得到每一个用户的预测值,从而形成N个所述用户的模型预测值集;其中,所述因子分解机在处理二分类问题时,将使用sigmoid函数将预测值的范围限定在0和1之间,即所述用户的模型预测值为所述用户的点击意愿度。
所述模型预测步骤S4还包括:
步骤S44:根据实际投放需求,选择全部或部分所述用户的模型预测值集中点击意愿度为1的用户进行精准营销的任务。
综上所述,本发明能够提前在广告投放之前就筛选出意愿较高的部分用户,并对这些用户进行营销广告的精准投放。结果表明,本算法选出的高意愿用户的点击率是低意愿用户点击率的数倍。进一步地,本发明可以将大量的低意愿用户直接从投放目标中筛出,从而节省大量的营销成本,实现利润率的增加。
以上所述的仅为本发明的优选实施例,所述实施例并非用以限制本发明的专利保护范围,因此凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
- 基于深度因子分解机的营销活动预测模型结构和预测方法
- 一种基于因子分解机的营销活动预测模型结构和预测方法