图像处理方法、装置、计算机设备和存储介质
文献发布时间:2023-06-19 11:11:32
技术领域
本申请涉及人工智能技术领域,特别是涉及一种图像处理方法、装置、计算机设备和存储介质。
背景技术
随着人工智能技术的不断发展,越来越多的人工智能机器人应用于不同的技术领域中,例如应用于一些竞速类应用场景中,人工智能机器人可以通过控制该竞速类应用场景中的虚拟对象与用户或其他机器人控制的虚拟对象进行竞速。其中,该人工智能机器人内部署一个机器学习模型,在进行竞速之前,对该机器学习模型进行训练,当达到要求时投入到竞速类应用场景进行实际应用。然而,在实际应用时,若该人工智能机器人与用户或其他机器人进行一对多的竞速时,预测出来的竞速行为的准确性将会大大降低。
发明内容
基于此,有必要针对上述技术问题,提供一种图像处理方法、装置、计算机设备和存储介质,能够提高竞速行为计算的准确性。
一种图像处理方法,所述方法包括:
对不同客户端在执行竞速任务时的目标图像帧进行识别,得到图像特征;
根据所述图像特征确定各所述客户端执行所述竞速任务所得的任务激励值;
通过双强化学习模型中的第一子模型,对所述任务激励值和所述目标图像帧进行竞速行为计算,得到第一竞速行为值;
通过所述双强化学习模型中的第二子模型,对所述任务激励值、所述目标图像帧和所述第一竞速行为值进行竞速行为计算,得到第二竞速行为值;
基于所述第一竞速行为值和所述第二竞速行为值,确定目标竞速行为。
一种图像处理装置,所述装置包括:
识别模块,用于对不同客户端在执行竞速任务时的目标图像帧进行识别,得到图像特征;
第一确定模块,用于根据所述图像特征确定各所述客户端执行所述竞速任务所得的任务激励值;
第一计算模块,用于通过双强化学习模型中的第一子模型,对所述任务激励值和所述目标图像帧进行竞速行为计算,得到第一竞速行为值;
第二计算模块,用于通过所述双强化学习模型中的第二子模型,对所述任务激励值、所述目标图像帧和所述第一竞速行为值进行竞速行为计算,得到第二竞速行为值;
第二确定模块,用于基于所述第一竞速行为值和所述第二竞速行为值,确定目标竞速行为。
在其中的一个实施例中,所述图像特征包括在执行所述竞速任务时的速度值;所述第一确定模块,还用于获取不同所述客户端在执行所述竞速任务过程中的历史图像帧所对应的速度值;所述历史图像帧是在所述目标图像帧之前所获得的图像帧;根据所述目标图像帧对应的速度值和所述历史图像帧所对应的速度值,确定各所述客户端在执行所述竞速任务过程中所得的任务激励值。
在其中的一个实施例中,所述装置还包括:
第一图像处理模块,用于分别对不同所述客户端的目标图像帧进行缩放处理,得到缩放后图像帧;在所述缩放后图像帧中添加深度信息,得到深度图像帧;
所述第一计算模块,还用于将所述深度图像帧和所述任务激励值输入至双强化学习模型中的第一子模型,以使所述第一子模型基于所述任务激励值和所述深度图像帧计算竞速行为。
在其中的一个实施例中,所述第二计算模块,还用于将所述深度图像帧、所述任务激励值和所述第一竞速行为值输入至所述双强化学习模型中的第二子模型,以使所述第二子模型基于所述深度图像帧、所述任务激励值和所述第一竞速行为值计算竞速行为,得到第二竞速行为值。
在其中的一个实施例中,所述装置还包括:
发送模块,用于将所得的目标竞速行为对应的行为值分别反馈至各所述客户端;反馈的所述行为值,用于指示各所述客户端根据所述目标竞速行为执行所述竞速任务;当各所述客户端执行完所述竞速任务时,向各所述客户端发送启动指令,以使各所述客户端重新进入所述竞速任务的操作画面。
在其中的一个实施例中,所述装置还包括:
所述识别模块,还用于对不同样本客户端在执行所述竞速任务时的样本图像帧进行识别,得到训练图像特征;
所述第一确定模块,还用于根据所述训练图像特征确定各所述样本客户端的训练任务激励值;
所述第一计算模块,还用于通过训练前所述双强化学习模型中的第一子模型对所述训练任务激励值和所述样本图像帧进行竞速行为计算,得到第一训练竞速行为值;
所述第二计算模块,还用于通过训练前所述双强化学习模型中的第二子模型对所述训练任务激励值、所述样本图像帧和所述第一训练竞速行为值进行竞速行为计算,得到第二训练竞速行为值;
调整模块,用于基于所述第一训练竞速行为值和所述第二训练竞速行为值之间的损失值,分别对训练前所述双强化学习模型中的第一子模型和第二子模型进行参数调整,得到训练后的所述双强化学习模型。
在其中的一个实施例中,所述装置还包括:
分配模块,用于根据所述训练任务激励值的大小,为所述样本图像帧分配不同的优先级;
存储模块,用于将分配所述优先级的样本图像帧以及对应的所述训练任务激励值进行存储;
所述第一计算模块,还用于读取所述优先级达到预设条件的所述样本图像帧和所述训练任务激励值,通过训练前所述双强化学习模型中的第一子模型对读取的所述训练任务激励值和所述样本图像帧进行竞速行为计算。
在其中的一个实施例中,所述第一计算模块,还用于基于所述优先级确定图像帧回放概率;按照所述图像帧回放概率读取存储的所述样本图像帧和所述训练任务激励值;其中,所述图像帧回放概率大的样本图像帧被读取的概率大于所述图像帧回放概率小的样本图像帧。
在其中的一个实施例中,所述训练图像特征包括在执行所述竞速任务时的训练速度值;所述第一确定模块,还用于获取不同所述样本客户端在执行所述竞速任务过程中的历史样本图像帧所对应的训练速度值;所述历史样本图像帧是在所述样本图像帧之前所获得的图像帧;根据所述样本图像帧对应的训练速度值和所述历史样本图像帧所对应的训练速度值,确定各所述样本客户端在执行所述竞速任务时的训练任务激励值。
在其中的一个实施例中,所述训练图像特征还包括完成所述竞速任务时用于表示任务是否成功的结果信息;
所述第一确定模块,还用于根据所述结果信息确定各所述样本客户端在完成所述竞速任务时的训练任务激励值;
所述第一计算模块,还用于通过训练前所述双强化学习模型中的第一子模型,对所述样本图像帧、各所述样本客户端在执行所述竞速任务时的训练任务激励值和完成所述竞速任务时的训练任务激励值进行竞速行为计算。
在其中的一个实施例中,所述装置还包括:
第二图像处理模块,用于分别对不同所述样本客户端的样本图像帧进行缩放处理,得到缩放后样本图像帧;在所述缩放后样本图像帧中添加深度信息,得到样本深度图像帧;
所述第一计算模块,还用于将所述样本深度图像帧和所述训练任务激励值输入至训练前双强化学习模型中的第一子模型,以使训练前所述双强化学习模型中的第一子模型基于所述训练任务激励值和所述样本深度图像帧计算竞速行为。
在其中的一个实施例中,所述第二计算模块,还用于将所述样本深度图像帧、所述训练任务激励值和所述第一训练竞速行为值输入至训练前所述双强化学习模型中的第二子模型,以使训练前所述双强化学习模型中的第二子模型基于所述样本深度图像帧、所述训练任务激励值和所述第一训练竞速行为值计算竞速行为,得到第二训练竞速行为值。
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
对不同客户端在执行竞速任务时的目标图像帧进行识别,得到图像特征;
根据所述图像特征确定各所述客户端执行所述竞速任务所得的任务激励值;
通过双强化学习模型中的第一子模型,对所述任务激励值和所述目标图像帧进行竞速行为计算,得到第一竞速行为值;
通过所述双强化学习模型中的第二子模型,对所述任务激励值、所述目标图像帧和所述第一竞速行为值进行竞速行为计算,得到第二竞速行为值;
基于所述第一竞速行为值和所述第二竞速行为值,确定目标竞速行为。
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
对不同客户端在执行竞速任务时的目标图像帧进行识别,得到图像特征;
根据所述图像特征确定各所述客户端执行所述竞速任务所得的任务激励值;
通过双强化学习模型中的第一子模型,对所述任务激励值和所述目标图像帧进行竞速行为计算,得到第一竞速行为值;
通过所述双强化学习模型中的第二子模型,对所述任务激励值、所述目标图像帧和所述第一竞速行为值进行竞速行为计算,得到第二竞速行为值;
基于所述第一竞速行为值和所述第二竞速行为值,确定目标竞速行为。
上述图像处理方法、装置、计算机设备和存储介质,在获取到不同客户端执行竞速任务时的目标图像帧时,识别图像特征,并根据该图像特征确定所得的任务激励值,一方面通过双强化学习模型中的第一子模型对任务激励值和目标图像帧进行竞速行为计算,可以得到准确性较高的第一竞速行为值,另一方面通过双强化学习模型中的第二子模型对任务激励值、目标图像帧和所得的第一竞速行为值再次进行竞速行为计算,得到第二竞速行为值,有效地提高竞速行为值的准确性;根据第一竞速行为值和第二竞速行为值来确定最终的目标竞速行为,可以确保所得竞速行为的准确性,从而即便在对接多个客户端时,也能够准确地预测出执行竞速任务时所采用的竞速行为,有效地提高了计算竞速行为的准确性。
附图说明
图1为一个实施例中图像处理方法的应用环境图;
图2为一个实施例中图像处理方法的流程示意图;
图3为一个实施例中赛车游戏中操作画面的示意图;
图4为另一个实施例中赛车游戏的结果页面的示意图;
图5为一个实施例中图像处理系统的结构示意图;
图6为一个实施例中赛车游戏的开始页面的示意图;
图7为一个实施例中第一子模型的结构示意图;
图8为另一个实施例中图像处理方法的流程示意图;
图9为一个实施例中对双强化学习模型进行训练步骤的流程示意图;
图10为一个实施例中图像处理装置的结构框图;
图11为另一个实施例中图像处理装置的结构框图;
图12为一个实施例中计算机设备的内部结构图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
人工智能(Artificial Intelligence,AI)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
机器学习(Machine Learning,ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、式教学习和度量学习等技术。
本申请实施例提供的方案涉及人工智能的机器学习等技术,具体通过如下实施例进行说明:
本申请提供的图像处理方法,可以应用于如图1所示的应用环境中。在该应用环境中,包括多个终端102和服务器104。
其中,终端102可以是智能手机、平板电脑、笔记本电脑、台式计算机、智能音箱、智能手表等,但并不局限于此。该终端102中可以安装用于执行竞速任务的客户端,如进行摩托车或卡丁车速度比赛的客户端。
服务器104可以是独立的物理服务器,也可以是区块链系统中的多个服务节点所组成的服务器集群,各服务节点之间形成组成点对点(P2P,Peer To Peer)网络,P2P协议是一个运行在传输控制协议(TCP,Transmission Control Protocol)协议之上的应用层协议。该服务器104中部署了双强化学习模型,通过该双强化学习模型进行两次竞速行为计算,从而得到用于控制各客户端执行竞速任务时所采用的目标竞速行为。
此外,服务器104还可以是多个物理服务器构成的服务器集群,可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、内容分发网络(Content Delivery Network,CDN)、以及大数据和人工智能平台等基础云计算服务的云服务器。
终端102与服务器104之间可以通过蓝牙、USB(Universal Serial Bus,通用串行总线)或者网络等通讯连接方式进行连接,本申请在此不做限制。
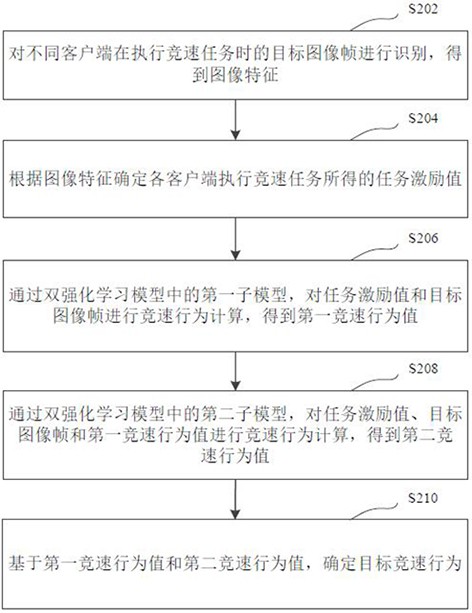
在一个实施例中,如图2所示,提供了一种图像处理方法,以该方法应用于图1中的服务器104为例进行说明,包括以下步骤:
S202,对不同客户端在执行竞速任务时的目标图像帧进行识别,得到图像特征。
其中,客户端可以是安装在终端上的应用程序,通过该客户端可以执行竞速任务。例如,该客户端可以是游戏客户端,通过该游戏客户端可以进行竞速类游戏。对应地,上述的竞速任务可以指竞速类游戏,如赛车游戏,具体如进行摩托车比赛或卡丁车比赛的游戏,此外还可以是跑步类(如跑酷)的游戏。
图像帧可以是客户端在执行竞速任务时所产生的图像。其中,客户端在执行竞速任务过程中,操作画面中每秒所显示图像的帧数通常是大于或等于30。目标图像帧可以是在一段时间内采集的需要进行图像识别的图像,例如,对于在一段时间内(如1秒)的各图像帧,其中的图像内容差异可能较小,从而无需对该段时间内的所有图像帧进行识别,只需要对其中的一张图像帧进行识别即可。
上述的图像特征可以包括以下至少之一:目标图像帧中的速度值和表示任务是否成功的结果信息。例如,在进行卡丁车游戏比赛时,该图像特征可以是在卡丁车游戏比赛的比赛图像帧中显示的速度大小;或者,在完成该卡丁车游戏比赛时,该图像特征可以是在结束任务的图像帧中显示的结果信息,如“挑战成功”或“挑战失败”。
在一个实施例中,服务器在获得客户端发送的目标图像帧后,可以先确定该目标图像帧是执行竞速任务过程中所产生的图像帧,还是完成竞速任务时所产生的图像帧,若是执行竞速任务过程中所产生的图像帧时,则确定图像特征所在的第一位置区域,然后对第一位置区域内的图像块进行图像识别,得到图像特征。若是完成竞速任务时所产生的图像帧时,则确定图像特征所在的第二位置区域,然后对第二位置区域内的图像块进行图像识别,得到图像特征。从而,在不同时期所得的目标图像帧中分别确定位置区域,从而可以快速查找到所要识别的区域,以便快速进行图像识别得到对应的图像特征,避免了对整个目标图像帧进行识别,提高了识别效率。
其中,第一位置区域指的是用于显示竞速任务过程中的车速值,如赛车游戏过程中,该第一位置区域用于显示虚拟赛车手的车速值。第二位置区域指的是用于显示完成竞速任务时的完成情况,如赛车游戏过程中,该第一位置区域用于显示赛车游戏的比赛结果,如是否成功完成赛车游戏中的比赛,或者在赛车游戏中是否赢得其它对手,具体显示的内容可以是“挑战成功”或“挑战失败”。
执行竞速任务的过程也可以指根据上一刻双强化学习模型预测的竞速行为控制虚拟对象进行竞速的过程。当确定目标图像帧是执行竞速任务过程中所产生的图像帧时,可以对该目标图像帧进行标记,如标记为车速任务标识(scoreTaskID),以便在计算任务激励值时,获取对应的激励函数进行计算。此外,完成竞速任务的过程也即成功完成竞速任务(winTask)或未成功完成竞速任务(loseTask)的过程,当确定目标图像帧是成功完成竞速任务产生的图像帧时,可以将该目标图像帧标记为winTaskID;当确定目标图像帧是未成功完成竞速任务产生的图像帧时,可以将该目标图像帧标记为loseTaskID,从而利用成功完成竞速任务或未成功完成竞速任务所对应的激励函数计算任务激励值。虚拟对象可以指竞速任务中进行竞速的对象,如赛车游戏中的赛车手,或赛车手及其座驾。
例如,如图3所示,在进行赛车游戏的过程中,车速值通常显示在操作画面中下部的位置,当确定目标图像帧是进行赛车游戏的过程中所产生时,服务器可以找到目标图像帧中下部的位置区域,然后对该位置区域的图像块进行图像识别,从而可以得到车速值。此外,该操作画面中还显示社交联系人或一起进行赛车游戏的好友,以便在进行赛车游戏过程中,可以与社交联系人或一起进行赛车游戏的好友进行即时通信。
又例如,如图4所示,在完成赛车游戏时,将会显示完成结果页面,该赛车游戏的结果信息通常会显示在该结果页面的左上角位置,当确定目标图像帧是完成赛车游戏所产生时,服务器可以找到目标图像帧左上角的位置区域,如图4中的虚线框的位置区域。然后,对该位置区域的图像块进行图像识别,从而可以得到结果信息,如图4虚线框内显示的“挑战成功”和“挑战失败”。
需要说明的是,对于速度值和结果信息的提取,可以通过服务器中的场景识别API(Application Programming Interface,应用程序接口)和场景识别算法对目标图像帧进行识别,其中,场景识别API是服务器中AISDK(Artificial Intelligence SoftwareDevelopment Kit,人工智能软件开发工具)中的一个模块,场景识别算法是AISDK中的一个算法程序,如图5所示。该场景识别API可以调用场景识别算法,该场景识别算法可以判断该目标图像帧属于执行竞速任务的场景,还是已经完成竞速任务的场景,然后确定需要从哪个位置区域进行识别。然后,AI算法逻辑调用图像识别模型,通过该图像识别模型确定的位置区域进行识别,从而得到车速值或结果信息。其中,AI SDK中集成了业界常用的算法,如场景识别算法和图像识别模型等,而且还集成了AI客户端,该AI客户端用于与执行竞速任务的客户端进行数据交互,组成一个稳定且可用性强的系统。
在一个实施例中,服务器还可以配置竞速任务的画面控制参数,用于能自动进入该竞速任务的操作画面,以便在该操作画面中进行竞速任务,从而无需手动操作便可自动进入操作页面以进行竞速任务,即便在完成本次竞速任务时,也可以自动进入下一次竞速任务,提高了便利性。例如,在启动赛车游戏后,服务器可以自动触发开始页面中的开始按钮,从而实现控制客户端自动进入游戏的操作页面进行赛车游戏,如图6所示,图6为赛车游戏的开始页面,服务器可以在确定客户端进入赛车游戏的开始页面时,可以触发开始页面中的“开始”按钮,从而可以自动进入赛车游戏的操作画面;该开始页面上还可以显示多个可以选择的角色(即赛车游戏中的赛车手),可以根据配置文件来选取相应的角色。此外,在完成本局赛车游戏时,不论游戏挑战成功与否,均可以触发结果页面中的再来一次按钮,从而重新进入下一局的赛车游戏。
S204,根据图像特征确定各客户端执行竞速任务所得的任务激励值。
其中,任务激励值可以是在执行竞速任务过程中所得的任务奖励分,以及执行完竞速任务时的任务奖励分。该任务激励值可以是正数或负数的值,例如,当该竞速任务挑战成功时,可以得到正数的任务激励值;当该竞速任务挑战失败时,则可以得到负数的任务激励值。举例来说,在进行赛车游戏时,若挑战成功,可以得到0.5分值的任务激励值;若挑战失败,则可以得到-0.5分值的任务激励值,具体可以参考如下表1。
表1
在一个实施例中,当图像特征为在执行竞速任务时的速度值,S204具体可以包括:服务器获取不同客户端在执行竞速任务过程中的历史图像帧所对应的速度值;根据目标图像帧对应的速度值和历史图像帧所对应的速度值,确定各客户端在执行竞速任务过程中所得的任务激励值,从而实现在执行竞速任务过程中计算任务激励值,以便利用该任务激励值和目标图像帧计算竞速行为。
其中,该历史图像帧是在目标图像帧之前所获得的图像帧,例如,假设一秒内共有40帧,若目标图像帧是第二秒中的第10个图像,那么历史图像帧可以是第一秒中的第10个图像。
在执行竞速任务的过程中,若速度值在提升(即客户端执行竞速任务时控制的虚拟对象在提速),此时会得到正数的任务激励值,具体计算方式包括:服务器将当前的目标图像帧对应的速度值与历史图像帧所对应的速度值作差,得到一个正数的差值;然后利用激励系数与该差值进行相乘,从而可以得到正数的任务激励值,此时表明客户端在执行竞速任务时得到任务奖励。为了避免任务激励值过大而影响竞速行为计算的准确性,可以设置一个最大任务激励值,当计算出来的任务激励值小于设置的最大任务激励值时,则取计算出来的任务激励值;当计算出来的任务激励值大于设置的最大任务激励值时,则取该最大任务激励值作为的任务激励值。其中,虚拟对象可以是竞速任务中与其它虚拟对手进行竞速的对象,如竞速类游戏中虚拟的赛车和赛车手。
此外,在执行竞速任务的过程中,若速度值在变小(即客户端执行竞速任务时控制的虚拟对象在减速),此时会得到负数的任务激励值,具体计算方式包括:服务器将当前的目标图像帧对应的速度值与历史图像帧所对应的速度值作差,得到一个负数的差值;然后利用激励系数与该差值进行相乘,从而可以得到负数的任务激励值,此时表明客户端在执行竞速任务时得到任务惩罚。为了避免任务激励值过小而影响竞速行为计算的准确性,可以设置一个最小任务激励值,当计算出来的任务激励值大于设置的最小任务激励值时,则取计算出来的任务激励值;当计算出来的任务激励值小于设置的最小任务激励值时,则取该最小任务激励值作为的任务激励值。
在一个实施例中,当图像特征为完成竞速任务时的结果信息,S204具体可以包括:服务器确定该结果信息为挑战成功时,则获取与该挑战成功所对应的分值作为任务激励值;服务器确定该结果信息为挑战失败时,则获取与该挑战失败所对应的分值作为任务激励值。例如,通过客户端进行赛车游戏,若挑战成功,则得到+0.5分值的任务激励值;若挑战失败,则得到-0.5分值的任务激励值。
S206,通过双强化学习模型中的第一子模型,对任务激励值和目标图像帧进行竞速行为计算,得到第一竞速行为值。
其中,双强化学习模型(Double Deep Q Network,DDQN)中集成了两个子模型,即第一子模型和第二子模型,而第一子模型和第二子模型可以是相同的网络模型,如均可以是强化Q网络模型或其它强化学习模型,用于学习在执行竞速任务过程中执行哪种竞速行为,以便得到最大的任务激励值。其中,第一子模型和第二子模型的网络模型结构可以包括三个卷积层、用于进行扁平化处理的扁平化层和四个线性变换层,参考图7。上述的扁平化处理可以指将特征进行降维处理,如将矩阵转换为向量。
此外,需要指出的是,双强化学习模型是基于不同样本客户端在执行所述竞速任务时的样本图像帧进行训练所得的,由于该双强化学习模型对接了多个样本客户端进行训练,不仅提高了训练速度,而且也能够准确地预测出多个客户端执行竞速任务时所采用的竞速行为,有效地提高了竞速行为的准确性。
竞速行为可以指:在执行竞速任务过程中,对虚拟对象进行控制所采用的竞速动作,如左移动、右移动、漂移和无操作。竞速行为值可以指用于表示竞速行为的数值,例如:1表示左移动,2表示右移动,3表示漂移,4表示无操作。
在一个实施例中,S206具体可以包括:服务器将任务激励值和目标图像帧输入至双强化学习模型中的第一子模型,从而第一子模型对该目标图像帧进行特征提取,得到己方控制的虚拟对象在目标图像帧中所处的位置特征,根据该位置特征和任务激励值计算竞速行为,如虚拟对象所在位置为操作画面右侧,若此时有个右弯道,此时可以选择减速并由转弯或右漂移,若选择减速并由转弯的激励值为负数,而右漂移的激励值为正数,此时第一子模型最终可以确定右漂移。其中,己方控制的虚拟对象指的是通过强化学习模型预测的目标竞速行为进行竞速的虚拟对象,如赛车游戏中,己方控制的虚拟对象即为通过强化学习模型预测的赛车行为(也即赛车动作)进行赛车的赛车手。
在进行位置特征提取过程中,其提取方式可以参考图7,具体如下:将任务激励值和目标图像帧输入至双强化学习模型中的第一子模型,通过第一子模型中的至少三个卷积层依次进行卷积计算,然后将最后一层卷积层的输出结果转换成向量特征;将该向量特征分别输入并行的线性变换层,通过该并行的线性变换层对向量特征进行线性变换得到两组特征,然后将这两组特征进行组合,从而得到位置特征。最后,服务器根据该位置特征和任务激励值计算竞速行为,得到相应的竞速行为值。
服务器将任务激励值和目标图像帧输入至第一子模型之前,还可以在目标图像帧中添加深度信息,得到深度图像帧,然后将任务激励值和深度图像帧输入至第一子模型,从而第一子模型对该深度图像帧进行特征提取,得到己方控制的虚拟对象在该深度图像帧中所处的位置特征,由于添加了深度信息,因此所得的位置特征将更加准确反映虚拟对象与其它虚拟对象和物体之间的相对位置,从而根据该位置特征和任务激励值计算所得的竞速行为更加准确。其中,深度信息用于表示虚拟摄像头到拍摄物之间的距离,如通过虚拟摄像头拍摄图像得到目标图像帧的过程中,可以计算该虚拟摄像头至拍摄物之间的距离,从而得到深度信息。虚拟摄像头可以是竞速任务中配置于虚拟对象上的摄像头,如赛车游戏,虚拟摄像头可以是置于赛车手上的摄像头。
此外,服务器在目标图像帧添加深度信息之前,还可以分别对不同客户端的目标图像帧进行缩放处理,得到缩放后图像帧,该缩放后图像帧的尺寸(或分辨率)小于目标图像帧的尺寸(或分辨率);然后,在该缩放后图像帧中添加深度信息,得到深度图像帧;最后将任务激励值和深度图像帧输入至第一子模型进行竞速行为计算,具体计算过程可以参考上述实施例。通过对目标图像帧进行缩放处理,可以降低图像帧的尺寸或分辨率,从而可以降低计算量,提高计算速度。
S208,通过双强化学习模型中的第二子模型,对任务激励值、目标图像帧和第一竞速行为值进行竞速行为计算,得到第二竞速行为值。
在一个实施例中,S208具体可以包括:服务器将任务激励值、目标图像帧和第一竞速行为值输入至双强化学习模型中的第二子模型,从而第二子模型对该目标图像帧进行特征提取,得到己方控制的虚拟对象在目标图像帧中所处的位置特征,根据该位置特征、任务激励值和第一竞速行为值计算竞速行为,得到第二竞速行为值。由于在计算竞速行为过程中,添加了第一竞速行为值作为参考值或影响因子,从而可以有利于提升第二竞速行为值的准确性。
服务器将任务激励值、目标图像帧和第一竞速行为值输入至第二子模型之前,还可以在目标图像帧中添加深度信息,得到深度图像帧,然后将任务激励值、深度图像帧和第一竞速行为值输入至第二子模型,从而第二子模型对该深度图像帧进行特征提取,得到己方控制的虚拟对象在该深度图像帧中所处的位置特征,由于添加了深度信息,因此所得的位置特征将更加准确反映虚拟对象与其它虚拟对象和物体之间的相对位置,从而根据该位置特征和任务激励值计算所得的竞速行为更加准确。
此外,服务器在目标图像帧添加深度信息之前,还可以分别对不同客户端的目标图像帧进行缩放处理,得到缩放后图像帧,该缩放后图像帧的尺寸(或分辨率)小于目标图像帧的尺寸(或分辨率);然后,在该缩放后图像帧中添加深度信息,得到深度图像帧;最后将任务激励值、深度图像帧和第一竞速行为值输入至第二子模型进行竞速行为计算,具体计算过程可以参考上述实施例。通过对目标图像帧进行缩放处理,可以降低图像帧的尺寸或分辨率,从而可以降低计算量,提高计算速度。
S210,基于第一竞速行为值和第二竞速行为值,确定目标竞速行为。
其中,该目标竞速行为可以是各客户端下一步所要实施的竞速行为,如双强化学习模型根据各客户端的目标图像帧和图像特征确定出需要左移动时,各客户端可以将虚拟对象(如赛车游戏中的赛车手和赛车)向左进行移动。
在一个实施例中,服务器可以对第一竞速行为值和第二竞速行为值进行加权求和,然后将求和的结果计算平均值,得到加权平均值;基于该加权平均值确定目标竞速行为。根据加权平均值确定最终的目标竞速行为,可以确保所得竞速行为的准确性,从而即便在对接多个客户端时,也能够准确地预测出执行竞速任务时所采用的竞速行为,有效地提高了计算竞速行为的准确性。
在一个实施例中,服务器获取分别与第一子模型和第二子模型对应的第一加权系数和第二加权系数,然后基于第一加权系数和第二加权系数依次对各客户端对应的第一竞速行为值和第二竞速行为值进行加权求和,然后对求和所得的和值计算平均值,得到加权平均值。其中,不同的加权平均值对应不同的目标竞速行为,因此基于该加权平均值确定用于控制各客户端执行竞速任务时的目标竞速行为。例如,加权平均值为1时,服务器从而可以确定目标竞速行为为左移动。通过对第一竞速行为值和第二竞速行为值进行加权求平均,从而可以避免因单个强化学习模型在进行竞速行为计算时出现竞速行为值偏高的问题,有利于提高确定目标竞速行为的准确性。
其中,第一加权系数可以小于第二加权系数,且第一加权系数和第二加权系数之和等于1。假设第一加权系数为
在一个实施例中,当服务器确定出目标竞速行为时,可以获取该目标竞速行为对应的行为值,然后将该目标竞速行为对应的行为值分别反馈至各客户端;各客户端在接收到服务器反馈的行为值时,各客户端根据所接收到的目标竞速行为执行竞速任务,如目标竞速行为为漂移时,则客户端则会在赛车游戏中对赛车进行漂移操作。
此外,由于服务器配置了竞速任务的画面控制参数,当各客户端执行完竞速任务时,服务器可以通过配置的画面控制参数触发完成页面中的继续按钮(如图4中的再来一次按钮),生成启动指令,然后向各客户端发送启动指令,以使各客户端重新进入竞速任务的操作画面。从而,服务器在通过预测目标竞速行为控制客户端执行竞速任务的过程中,在每完成一局竞速任务时,均会自动进入下一句的竞速任务,从而避免需要人工辅助,提高了竞速任务切换的便利性。
为了更加直观理解上述实施例的方案,这里结合赛车应用场景对上述实施例的方案进行描述。在进行描述之前,需要指出的是,在赛车应用场景中,上述的竞速任务为赛车游戏,目标图像帧为需要进行图像识别的赛车图像帧。接下来对结合赛车应用场景对上述实施例的方案进行描述,如图8所示,具体内容如下:
S802,赛车游戏客户端在进行赛车游戏过程中,将赛车图像帧发送给服务器。
S804,服务器对赛车图像帧进行识别,得到图像特征。
参考图5,赛车游戏客户端首先将赛车图像帧发送给服务器中的AI客户端,然后AI客户端将赛车图像帧传输给AISDK中的场景识别API,场景识别API调用场景识别算法识别该赛车图像帧是在赛车游戏过程中的图像帧,还是完成赛车游戏时的图像帧,从而可以确定待识别的位置区域,如图3和图4所示。当确定出待识别的位置区域时,触发AI算法逻辑,调用图像识别模型按照确定的位置区域对赛车图像帧的图像块进行识别,从而得到图像特征。
S806,服务器根据图像特征确定赛车游戏客户端在赛车游戏过程中所得的游戏任务激励值。
S808,服务器通过DDQN中的第一子模型对游戏激励值和赛车图像帧进行竞速行为计算,得到第一赛车行为值。
S810,服务器通过DDQN中的第二子模型对游戏激励值、赛车图像帧和第一赛车行为值进行竞速行为计算,得到第二赛车行为值。
S812,服务器基于第一赛车行为值和第二赛车行为值之间的加权平均值,确定目标赛车行为。
S814,服务器将目标赛车行为的行为值发送给赛车游戏客户端。
S816,赛车游戏客户端根据该行为值来进行赛车游戏。
例如,假设上述的第一赛车行为值和第二赛车行为值均为左移动的行为值,从而加权平均值对应的也是左移动的行为值,因此目标赛车行为即为左移动,此时,赛车游戏客户端在进行赛车游戏时,可以控制赛车进行左移动。
上述实施例中,在获取到不同客户端执行竞速任务时的目标图像帧时,识别图像特征,并根据该图像特征确定所得的任务激励值,一方面通过双强化学习模型中的第一子模型对任务激励值和目标图像帧进行竞速行为计算,可以得到准确性较高的第一竞速行为值,另一方面通过双强化学习模型中的第二子模型对任务激励值、目标图像帧和所得的第一竞速行为值再次进行竞速行为计算,得到第二竞速行为值,有效地提高竞速行为值的准确性;根据第一竞速行为值和第二竞速行为值来确定最终的目标竞速行为,可确保所得竞速行为的准确性,从而即便在对接多个样本客户端时,也能够准确地预测出执行竞速任务时所采用的竞速行为,有效地提高了竞速行为的准确性。
在一个实施例中,在确定竞速行为之前,还可以对双强化学习模型进行训练。如图9所示,训练的步骤具体可以包括:
S902,对不同样本客户端在执行竞速任务时的样本图像帧进行识别,得到训练图像特征。
其中,样本客户端指的是在模型训练过程中所对接的客户端。在训练过程中,一个部署双强化学习模型的服务器可以同时对接多个客户端进行模型训练,有利于提高训练的并发速度,缩短训练时间。
训练图像特征可以指在训练过程中所获得的图像特征,包括在执行竞速任务时的训练速度值和完成竞速任务时用于表示任务是否成功的结果信息。该训练速度值指的是训练过程中虚拟对象的速度值,如赛车游戏中摩托车的速度值。
上述S902的详细步骤可以参考图1实施例中的S202,这里不再进行叙述。
S904,根据训练图像特征确定各样本客户端的训练任务激励值。
其中,训练任务激励值指的是在训练过程中所获得的任务激励值,该任务激励值也即为执行任务过程中的奖励值或惩罚值。在计算训练任务激励值时,可以利用激励函数进行计算,具体可以参考表1的激励函数计算训练任务激励值。在表1中,设置了最大值(maxRunningReward)为0.5,也设置了最小值(minRunningReward)为-0.5,从而车速值发生激烈变化时,防止训练任务激励值过大或过小而影响双强化学习模型训练的精度。需要指出的是,上述maxRunningReward和minRunningReward也可以设置其它固定的值。
在一个实施例中,当训练图像特征为在执行竞速任务时的训练速度值时,S904具体可以包括:服务器获取不同样本客户端在执行竞速任务过程中的历史样本图像帧所对应的训练速度值;历史样本图像帧是在样本图像帧之前所获得的图像帧;根据样本图像帧对应的训练速度值和历史样本图像帧所对应的训练速度值,确定各样本客户端在执行竞速任务时的训练任务激励值。
其中,该历史样本图像帧是在样本图像帧之前所获得的图像帧,如样本图像帧是第二秒中的第10个图像,那么历史样本图像帧可以是第一秒中的第10个图像。
在执行竞速任务的过程中,若训练速度值在提升,此时会得到正数的训练任务激励值,具体计算方式包括:服务器将当前的样本图像帧对应的训练速度值与历史样本图像帧所对应的训练速度值作差,得到一个正数的差值;然后利用激励系数与该差值进行相乘,从而可以得到正数的训练任务激励值,此时表明客户端在执行竞速任务时得到任务奖励。为了避免训练任务激励值过大,当计算出来的训练任务激励值小于设置的最大任务激励值时,则取计算出来的训练任务激励值;当计算出来的训练任务激励值大于设置的最大任务激励值时,则取该最大任务激励值作为的训练任务激励值。
此外,在执行竞速任务的过程中,若训练速度值在变小(即客户端执行竞速任务时控制的虚拟对象在减速),此时会得到负数的训练任务激励值,具体计算方式包括:服务器将当前的样本图像帧对应的训练速度值与历史样本图像帧所对应的训练速度值作差,得到一个负数的差值;然后利用激励系数与该差值进行相乘,从而可以得到负数的训练任务激励值,此时表明客户端在执行竞速任务时得到任务惩罚。为了避免训练任务激励值过小,当计算出来的训练任务激励值大于设置的最小任务激励值时,则取计算出来的训练任务激励值;当计算出来的训练任务激励值小于设置的最小任务激励值时,则取该最小任务激励值作为的训练任务激励值。
在另一个实施例中,当训练图像特征为完成竞速任务时用于表示任务是否成功的结果信息时,服务器根据结果信息确定各样本客户端在完成竞速任务时的训练任务激励值;S904具体可以包括:通过训练前双强化学习模型中的第一子模型,对样本图像帧、各样本客户端在执行竞速任务时的训练任务激励值和完成竞速任务时的训练任务激励值进行竞速行为计算。例如,通过客户端进行赛车游戏,若挑战成功,则得到+0.5分值的任务激励值;若挑战失败,则得到-0.5分值的任务激励值。
S906,通过训练前双强化学习模型中的第一子模型对训练任务激励值和样本图像帧进行竞速行为计算,得到第一训练竞速行为值。
其中,训练前双强化学习模型指的是训练之前的双强化学习模型。
在一个实施例中,分别对不同样本客户端的样本图像帧进行缩放处理,得到缩放后样本图像帧;在缩放后样本图像帧中添加深度信息,得到样本深度图像帧;S906具体可以包括:服务器将样本深度图像帧和训练任务激励值输入至训练前双强化学习模型中的第一子模型,以使训练前双强化学习模型中的第一子模型基于训练任务激励值和样本深度图像帧计算竞速行为。上述S906的竞速行为计算过程,可以参考图1实施例中的S206,这里不再进行叙述。
S908,通过训练前双强化学习模型中的第二子模型对训练任务激励值、样本图像帧和第一训练竞速行为值进行竞速行为计算,得到第二训练竞速行为值。
在一个实施例中,S908具体可以包括:服务器将样本深度图像帧、训练任务激励值和第一训练竞速行为值输入至训练前双强化学习模型中的第二子模型,以使训练前双强化学习模型中的第二子模型基于样本深度图像帧、训练任务激励值和第一训练竞速行为值计算竞速行为,得到第二训练竞速行为值。
上述S908的竞速行为计算,可以参考图2实施例中的S208,这里不再进行详细描述。
S910,基于第一训练竞速行为值和第二训练竞速行为值之间的损失值,分别对训练前双强化学习模型中的第一子模型和第二子模型进行参数调整,得到训练后的双强化学习模型。
其中,上述的损失值可以是第一训练竞速行为值和第二训练竞速行为值之间的差值、平方损失值、指数损失值、对数损失值和交叉熵损失值等中的任一种。
例如,对于平方损失值,服务器可以采用平方损失函数
在一个实施例中,服务器在计算出损失值之和,将给损失值分别输入至训练前双强化学习模型中的第一子模型和第二子模型中进行反向传播,在反向传播过程中根据该损失值分别计算第一子模型和第二子模型中各模型参数的梯度,根据该梯度分别调整第一子模型和第二子模型中的模型参数,直至模型收敛,从而得到训练后的双强化学习模型。
上述实施例中,通过与不同样本客户端进行对接,得到各样本客户端在执行竞速任务时的样本图像帧,然后对该样本图像帧进行识别,并利用识别所得的训练图像特征计算训练任务激励值,采用训练任务激励值和样本图像帧对训练前的双强化学习模型进行训练,从而在训练过程中,实现一个双强化学习模型对接多个样本客户端,可以有效提高训练速度,缩短训练时间,从而提高了模型训练效率。此外,通过对双强化学习模型进行训练,可以有效地提高了双强化学习模型的预测精度,从而可以提高竞速行为预测的准确性。
在一个实施例中,服务器考虑到各样本客户端的样本图像帧之间存在差异性,可以为样本客户端的样本图像帧配置不同的优先级,以便进行优先化经验回放(Prioritizedexperience replay);其中,优先化经验回放可以指更频繁地读取更有价值的样本帧图像进行训练,以提高模型的精度。具体地,服务器根据训练任务激励值的大小,为样本图像帧分配不同的优先级;将分配优先级的样本图像帧以及对应的训练任务激励值进行存储;S906具体可以包括:读取优先级达到预设条件的样本图像帧和训练任务激励值,通过训练前双强化学习模型中的第一子模型对读取的训练任务激励值和样本图像帧进行竞速行为计算。通过按照优先级来读取更有价值的样本图像帧和对应的训练任务激励值进行模型训练,可以提高双强化学习模型的算法精度,有利于提高确定竞速行为的准确性。
具体地,在读取样本图像帧和训练任务激励值的过程中,具体读取步骤可以包括:服务器基于优先级确定图像帧回放概率;按照图像帧回放概率读取存储的样本图像帧和训练任务激励值;其中,图像帧回放概率大的样本图像帧被读取的概率大于图像帧回放概率小的样本图像帧。从而,对于更有价值的样本图像帧和训练任务激励值,可以较大概率的读取出来进行模型训练,可以提高双强化学习模型的算法精度,有利于提高确定竞速行为的准确性。
应该理解的是,虽然图2、8、9的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图2、8、9中的至少一部分步骤可以包括多个步骤或者多个阶段,这些步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤中的步骤或者阶段的至少一部分轮流或者交替地执行。
在一个实施例中,如图10所示,提供了一种图像处理装置,该装置可以采用软件模块或硬件模块,或者是二者的结合成为计算机设备的一部分,该装置具体包括:识别模块1002、第一确定模块1004、第一计算模块1006、第二计算模块1008和第二确定模块1010,其中:
识别模块1002,用于对不同客户端在执行竞速任务时的目标图像帧进行识别,得到图像特征;
第一确定模块1004,用于根据图像特征确定各客户端执行竞速任务所得的任务激励值;
第一计算模块1006,用于通过双强化学习模型中的第一子模型,对任务激励值和目标图像帧进行竞速行为计算,得到第一竞速行为值;
第二计算模块1008,用于通过双强化学习模型中的第二子模型,对任务激励值、目标图像帧和第一竞速行为值进行竞速行为计算,得到第二竞速行为值;
第二确定模块1010,用于基于第一竞速行为值和第二竞速行为值之间的加权平均值,确定目标竞速行为。
在其中的一个实施例中,图像特征包括在执行竞速任务时的速度值;第一确定模块1004,还用于获取不同客户端在执行竞速任务过程中的历史图像帧所对应的速度值;历史图像帧是在目标图像帧之前所获得的图像帧;根据目标图像帧对应的速度值和历史图像帧所对应的速度值,确定各客户端在执行竞速任务过程中所得的任务激励值。
在其中的一个实施例中,如图11所示,该装置还包括:
第一图像处理模块1012,用于分别对不同客户端的目标图像帧进行缩放处理,得到缩放后图像帧;在缩放后图像帧中添加深度信息,得到深度图像帧;
第一计算模块1006,还用于将深度图像帧和任务激励值输入至双强化学习模型中的第一子模型,以使第一子模型基于任务激励值和深度图像帧计算竞速行为。
在其中的一个实施例中,第二计算模块1008,还用于将深度图像帧、任务激励值和第一竞速行为值输入至双强化学习模型中的第二子模型,以使第二子模型基于深度图像帧、任务激励值和第一竞速行为值计算竞速行为,得到第二竞速行为值。
在其中的一个实施例中,如图11所示,该装置还包括:
发送模块1014,用于将所得的目标竞速行为对应的行为值分别反馈至各客户端;反馈的行为值,用于指示各客户端根据目标竞速行为执行竞速任务;当各客户端执行完竞速任务时,向各客户端发送启动指令,以使各客户端重新进入竞速任务的操作画面。
上述实施例中,在获取到不同客户端执行竞速任务时的目标图像帧时,识别图像特征,并根据该图像特征确定所得的任务激励值,一方面通过双强化学习模型中的第一子模型对任务激励值和目标图像帧进行竞速行为计算,可以得到准确性较高的第一竞速行为值,另一方面通过双强化学习模型中的第二子模型对任务激励值、目标图像帧和所得的第一竞速行为值再次进行竞速行为计算,得到第二竞速行为值,有效地提高竞速行为值的准确性;根据第一竞速行为值和第二竞速行为值来确定最终的目标竞速行为,可确保所得竞速行为的准确性,从而即便在对接多个客户端时,也能够准确地预测出执行竞速任务时所采用的竞速行为,有效地提高了竞速行为的准确性。
在其中的一个实施例中,装置还包括:
识别模块1002,还用于对不同样本客户端在执行竞速任务时的样本图像帧进行识别,得到训练图像特征;
第一确定模块1004,还用于根据训练图像特征确定各客户端的训练任务激励值;
第一计算模块1006,还用于通过训练前双强化学习模型中的第一子模型对训练任务激励值和样本图像帧进行竞速行为计算,得到第一训练竞速行为值;
第二计算模块1008,还用于通过训练前双强化学习模型中的第二子模型对训练任务激励值、样本图像帧和第一训练竞速行为值进行竞速行为计算,得到第二训练竞速行为值;
调整模块1016,用于基于第一训练竞速行为值和第二训练竞速行为值之间的损失值,分别对训练前双强化学习模型中的第一子模型和第二子模型进行参数调整,得到训练后的双强化学习模型。
在其中的一个实施例中,如图11所示,该装置还包括:
分配模块1018,用于根据训练任务激励值的大小,为样本图像帧分配不同的优先级;
存储模块1020,用于将分配优先级的样本图像帧以及对应的训练任务激励值进行存储;
第一计算模块1006,还用于读取优先级达到预设条件的样本图像帧和训练任务激励值,通过训练前双强化学习模型中的第一子模型对读取的训练任务激励值和样本图像帧进行竞速行为计算。
在其中的一个实施例中,第一计算模块1006,还用于基于优先级确定图像帧回放概率;按照图像帧回放概率读取存储的样本图像帧和训练任务激励值;其中,图像帧回放概率大的样本图像帧被读取的概率大于图像帧回放概率小的样本图像帧。
在其中的一个实施例中,训练图像特征包括在执行竞速任务时的训练速度值;第一确定模块1004,还用于获取不同样本客户端在执行竞速任务过程中的历史样本图像帧所对应的训练速度值;历史样本图像帧是在样本图像帧之前所获得的图像帧;根据样本图像帧对应的训练速度值和历史样本图像帧所对应的训练速度值,确定各样本客户端在执行竞速任务时的训练任务激励值。
在其中的一个实施例中,训练图像特征还包括完成竞速任务时用于表示任务是否成功的结果信息;
第一确定模块1004,还用于根据结果信息确定各样本客户端在完成竞速任务时的训练任务激励值;
第一计算模块1006,还用于通过训练前双强化学习模型中的第一子模型,对样本图像帧、各样本客户端在执行竞速任务时的训练任务激励值和完成竞速任务时的训练任务激励值进行竞速行为计算。
在其中的一个实施例中,如图11所示,该装置还包括:
第二图像处理模块1022,用于分别对不同样本客户端的样本图像帧进行缩放处理,得到缩放后样本图像帧;在缩放后样本图像帧中添加深度信息,得到样本深度图像帧;
第一计算模块1006,还用于将样本深度图像帧和训练任务激励值输入至训练前双强化学习模型中的第一子模型,以使训练前双强化学习模型中的第一子模型基于训练任务激励值和样本深度图像帧计算竞速行为。
在其中的一个实施例中,第二计算模块1008,还用于将样本深度图像帧、训练任务激励值和第一训练竞速行为值输入至训练前双强化学习模型中的第二子模型,以使训练前双强化学习模型中的第二子模型基于样本深度图像帧、训练任务激励值和第一训练竞速行为值计算竞速行为,得到第二训练竞速行为值。
上述实施例中,通过与不同样本客户端进行对接,得到各样本客户端在执行竞速任务时的样本图像帧,然后对该样本图像帧进行识别,并利用识别所得的训练图像特征计算训练任务激励值,采用训练任务激励值和样本图像帧对训练前的双强化学习模型进行训练,从而在训练过程中,实现一个双强化学习模型对接多个样本客户端,可以有效提高训练速度,缩短训练时间,从而提高了模型训练效率。此外,通过对双强化学习模型进行训练,可以有效地提高了双强化学习模型的预测精度,从而可以提高竞速行为预测的准确性。
关于图像处理装置的具体限定可以参见上文中对于图像处理方法的限定,在此不再赘述。上述图像处理装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
在一个实施例中,提供了一种计算机设备,该计算机设备可以是服务器,其内部结构图可以如图12所示。该计算机设备包括通过系统总线连接的处理器、存储器和网络接口。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于存储图像帧、图像特征和任务激励值等数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种图像处理方法。
本领域技术人员可以理解,图12中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
在一个实施例中,还提供了一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,该处理器执行计算机程序时实现上述各方法实施例中的步骤。
在一个实施例中,提供了一种计算机可读存储介质,存储有计算机程序,该计算机程序被处理器执行时实现上述各方法实施例中的步骤。
在一个实施例中,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述各方法实施例中的步骤。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和易失性存储器中的至少一种。非易失性存储器可包括只读存储器(Read-Only Memory,ROM)、磁带、软盘、闪存或光存储器等。易失性存储器可包括随机存取存储器(Random Access Memory,RAM)或外部高速缓冲存储器。作为说明而非局限,RAM可以是多种形式,比如静态随机存取存储器(Static Random Access Memory,SRAM)或动态随机存取存储器(Dynamic Random Access Memory,DRAM)等。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 图像处理方法及装置、图像采集装置、可读存储介质和计算机设备
- 图像处理方法、装置、计算机设备及计算机可读存储介质